

如何保障消息中间件 100% 消息投递成功?如何保证消息幂等性?
- 一、前言
- 二、分析问题
- 三、持久化
- 四、confirm机制
- 五、消息提前持久化 + 定时任务
- 六、幂等含义
- 6.1、为什么要有幂等这种场景?
- 6.2、乐观锁方案
- 6.3、唯一ID + 指纹码
- 6.4、Redis原子操作
- 《Java 2019 超神之路》
- 《Dubbo 实现原理与源码解析 —— 精品合集》
- 《Spring 实现原理与源码解析 —— 精品合集》
- 《MyBatis 实现原理与源码解析 —— 精品合集》
- 《Spring MVC 实现原理与源码解析 —— 精品合集》
- 《Spring Boot 实现原理与源码解析 —— 精品合集》
- 《数据库实体设计合集》
- 《Java 面试题 —— 精品合集》
- 《Java 学习指南 —— 精品合集》
一、前言
我们小伙伴应该都听说够消息中间件MQ,如:RabbitMQ,RocketMQ,Kafka等。引入中间件的好处可以起到抗高并发,削峰,业务解耦的作用。

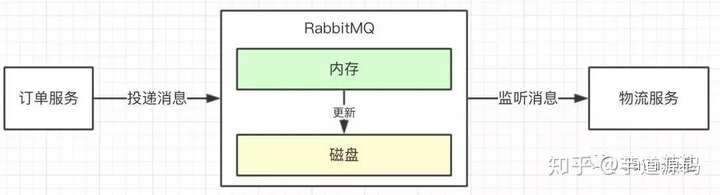
如上图:
(1)订单服务投递消息给MQ中间件
(2)物流服务监听MQ中间件消息,从而进行消费
我们这篇文章讨论一下,如何保障订单服务把消息成功投递给MQ中间件,以RabbitMQ举例。
二、分析问题
小伙伴们对此会有些疑问,订单服务发起消息服务,返回成功不就成功了吗?如下面的伪代码:

上面代码中,一般发送消息就是这么写的,小伙伴们觉得有什么问题吗?
下边说一个场景,如果MQ服务器突然宕机了会出现什么情况?是不是我们订单服务发过去的消息全部没有了吗?是的,一般MQ中间件为了提高系统的吞吐量会把消息保存在内存中,如果不作其他处理,MQ服务器一旦宕机,消息将全部丢失 。这个是业务不允许的,造成很大的影响。
三、持久化
有经验的小伙伴会说,我知道一个方法就是把消息持久化,RabbitMQ中发消息的时候会有个durable参数可以设置,设置为true,就会持久化。
这样的话MQ服务器即使宕机,重启后磁盘文件中有消息的存储,这样就不会丢失了吧 。是的这样就一定概率的保障了消息不丢失。
但还会有个场景,就是消息刚刚保存到MQ内存中,但还没有来得及更新到磁盘文件中,突然宕机了 。(我靠,这个时间这么短,也会出现,概率太低了吧),这个场景在持续的大量消息投递的过程中,会很常见。
那怎么办?我们如何作才能保障一定会持久化到磁盘上面呢?
四、confirm机制
上面问题出现在,没有人告诉我们持久化是否成功。好在很多MQ有回调通知的特性,RabbitMQ就有confirm机制来通知我们是否持久化成功?
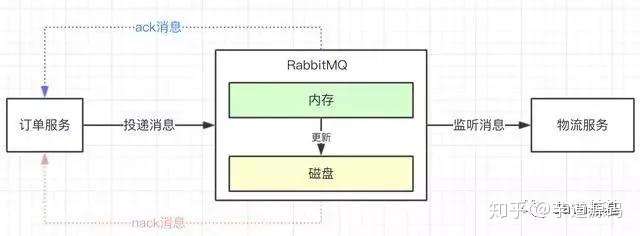
confirm机制的原理:
(1)消息生产者把消息发送给MQ,如果接收成功,MQ会返回一个ack消息给生产者;
(2)如果消息接收不成功,MQ会返回一个nack消息给生产者;
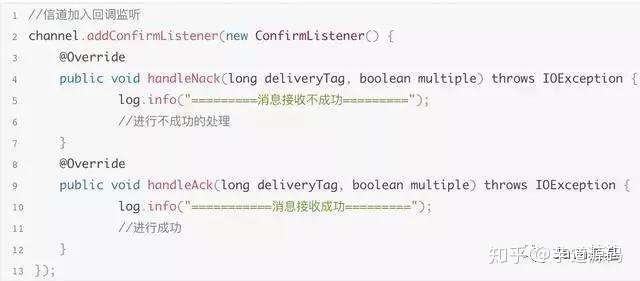
上面的伪代码,有两个处理消息方式,就是ack回调和nack回调。
这样是不是就可以保障100%消息不丢失了呢?
我们看一下confirm的机制,试想一下,如果我们生产者每发一条消息,都要MQ持久化到磁盘中,然后再发起ack或nack的回调。这样的话是不是我们MQ的吞吐量很不高,因为每次都要把消息持久化到磁盘中。 写入磁盘这个动作是很慢的。这个在高并发场景下是不能够接受的,吞吐量太低了。
所以MQ持久化磁盘真实的实现,是通过异步调用处理的,他是有一定的机制,如:等到有几千条消息的时候,会一次性的刷盘到磁盘上面。而不是每来一条消息,就刷盘一次。
所以comfirm机制其实是一个异步监听的机制 ,是为了保证系统的高吞吐量 ,这样就导致了还是不能够100%保障消息不丢失,因为即使加上了confirm机制,消息在MQ内存中还没有刷盘到磁盘就宕机了,还是没法处理。
说了这么多,还是没法确保,那怎么办呢???
五、消息提前持久化 + 定时任务
其实本质的原因是无法确定是否持久化?那我们是不是可以自己让消息持久化呢?答案是可以的,我们的方案再一步的演化。
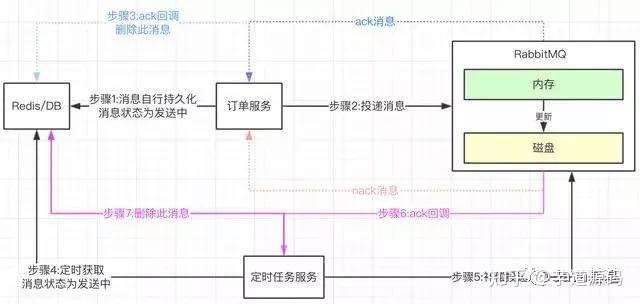
上图流程:
(1)订单服务生产者再投递消息之前,先把消息持久化到Redis或DB中,建议Redis,高性能。消息的状态为发送中。
(2)confirm机制监听消息是否发送成功?如ack成功消息,删除Redis中此消息。
(3)如果nack不成功的消息,这个可以根据自身的业务选择是否重发此消息。也可以删除此消息,由自己的业务决定。
(4)这边加了个定时任务,来拉取隔一定时间了,消息状态还是为发送中的,这个状态就表明,订单服务是没有收到ack成功消息。
(5)定时任务会作补偿性的投递消息。这个时候如果MQ回调ack成功接收了,再把Redis中此消息删除。
这样的机制其实就是一个补偿机制 ,我不管MQ有没有真正的接收到,只要我的Redis中的消息状态也是为【发送中】,就表示此消息没有正确成功投递。再启动定时任务去监控,发起补偿投递。
当然定时任务那边我们还可以加上一个补偿的次数,如果大于3次,还是没有收到ack消息 ,那就直接把消息的状态设置为【失败】,由人工去排查到底是为什么?
这样的话方案就比较完美了,保障了100%的消息不丢失 (当然不包含磁盘也坏了,可以做主从方案)。
不过这样的方案,就会有可能发送多次相同的消息 ,很有可能MQ已经收到了消息,就是ack消息回调时出现网络故障,没有让生产者收到。
那就要要求消费者一定在消费的时候保障幂等性!
六、幂等含义
我们先了解一下什么叫幂等?在分布式应用中,幂等是非常重要的,也就是相同条件下对一个业务的操作,不管操作多少次,结果都是一样。
6.1、为什么要有幂等这种场景?
为什么要有幂等这种场景?因为在大的系统中,都是分布式部署,如:订单业务 和 库存业务有可能都是独立部署的,都是单独的服务。用户下订单,会调用到订单服务和库存服务。
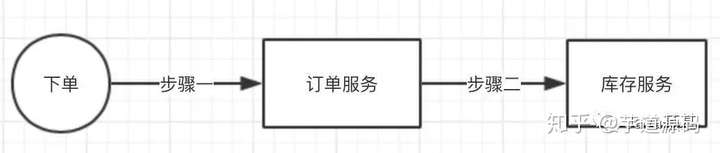
因为分布式部署,很有可能在调用库存服务时,因为网络等原因,订单服务调用失败,但其实库存服务已经处理完成,只是返回给订单服务处理结果时出现了异常。这个时候一般系统会作补偿方案,也就是订单服务再此放起库存服务的调用,库存减1。

这样就出现了问题,其实上一次调用已经减了1,只是订单服务没有收到处理结果。现在又调用一次,又要减1,这样就不符合业务了,多扣了。
幂等这个概念就是,不管库存服务在相同条件下调用几次,处理结果都一样。这样才能保证补偿方案的可行性。
6.2、乐观锁方案
借鉴数据库的乐观锁机制,如:
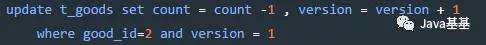
根据version版本,也就是在操作库存前先获取当前商品的version版本号,然后操作的时候带上此version号。我们梳理下,我们第一次操作库存时,得到version为1,调用库存服务version变成了2;但返回给订单服务出现了问题,订单服务又一次发起调用库存服务,当订单服务传如的version还是1,再执行上面的sql语句时,就不会执行;因为version已经变为2了,where条件就不成立。这样就保证了不管调用几次,只会真正的处理一次。
6.3、唯一ID + 指纹码
原理就是利用数据库主键去重,业务完成后插入主键标识

- 唯一ID就是业务表的唯一的主键,如商品ID
- 指纹码就是为了区别每次正常操作的码,每次操作时生成指纹码;可以用时间戳+业务编号的方式。
上面的sql语句:
- 返回如果为0 表示没有操作过,那业务操作后就可以insert into t_check(唯一ID+指纹码)
- 返回如果大于0 表示操作过,就直接返回
好处:实现简单
坏处:高并发下数据库瓶颈
解决方案:根据ID进行分库分表进行算法路由
6.4、Redis原子操作
利用redis的原子操作,做个操作完成的标记。这个性能就比较好。但会遇到一些问题。
第一:我们是否需要把业务结果进行数据落库,如果落库,关键解决的问题时数据库和redis操作如何做到原子性?
这个意思就是库存减1了,但redis进行操作完成标记时,失败了怎么办?也就是一定要保证落库和redis 要么一起成功,要么一起失败
第二:如果不进行落库,那么都存储到缓存中,如何设置定时同步策略?
这个意思就是库存减1,不落库,直接先操作redis操作完成标记,然后由另外的同步服务进行库存落库,这个就是增加了系统复杂性,而且同步策略如何设置
以上我们结束了幂等相关的解决方案,以后文章中我们会重点介绍方案的实现。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
2015-01-13 微软企业库DBBA的研究