

Mysql的MVCC
基本原理
MVCC的实现,通过保存数据在某个时间点的快照来实现的。这意味着一个事务无论运行多长时间,在同一个事务里能够看到数据一致的视图。根据事务开始的时间不同,同时也意味着在同一个时刻不同事务看到的相同表里的数据可能是不同的。
基本特征
- 每行数据都存在一个版本,每次数据更新时都更新该版本。
- 修改时Copy出当前版本随意修改,各个事务之间无干扰。
- 保存时比较版本号,如果成功(commit),则覆盖原记录;失败则放弃copy(rollback)
InnoDB存储引擎MVCC的实现策略
在每一行数据中额外保存两个隐藏的列:当前行创建时的版本号和删除时的版本号。这里的版本号并不是实际的时间值,而是系统版本号。每开始新的事务,系统版本号都会自动递增。事务开始时刻的系统版本号会作为事务的版本号,用来和查询每行记录的版本号进行比较。
每个事务又有自己的版本号,这样事务内执行CRUD操作时,就通过版本号的比较来达到数据版本控制的目的。
我们来具体看看是如何实现的。
版本链
我们先来理解一下版本链的概念。在InnoDB引擎表中,它的聚簇索引记录中有两个必要的隐藏列:
trx_id这个id用来存储的每次对某条聚簇索引记录进行修改的时候的事务id。
roll_pointer每次对哪条聚簇索引记录有修改的时候,都会把老版本写入undo日志中。这个roll_pointer就是存了一个指针,它指向这条聚簇索引记录的上一个版本的位置,通过它来获得上一个版本的记录信息。(注意插入操作的undo日志没有这个属性,因为它没有老版本)
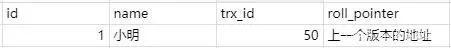
比如现在有个事务id是60的执行的这条记录的修改语句
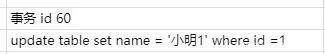
此时在undo日志中就存在版本链

ReadView
说了版本链我们再来看看ReadView。已提交读和可重复读的区别就在于它们生成ReadView的策略不同。
举个例子 ,在已提交读隔离级别下:
比如此时有一个事务id为100的事务,修改了name,使得的name等于小明2,但是事务还没提交。则此时的版本链是

那此时另一个事务发起了select 语句要查询id为1的记录,那此时生成的ReadView 列表只有[100]。那就去版本链去找了,首先肯定找最近的一条,发现trx_id是100,也就是name为小明2的那条记录,发现在列表内,所以不能访问。
这时候就通过指针继续找下一条,name为小明1的记录,发现trx_id是60,小于列表中的最小id,所以可以访问,直接访问结果为小明1。
那这时候我们把事务id为100的事务提交了,并且新建了一个事务id为110也修改id为1的记录,并且不提交事务
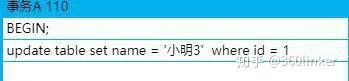
这时候版本链就是
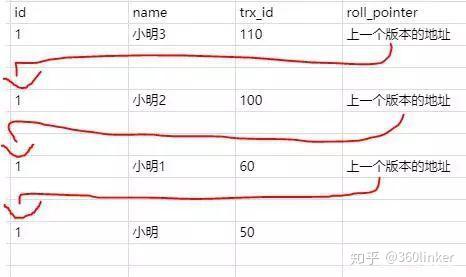
这时候之前那个select事务又执行了一次查询,要查询id为1的记录。
如果你是已提交读隔离级别,这时候你会重新生成一个ReadView,那你的活动事务列表中的值就变了,变成了[110]。
按照上的说法,你去版本链通过trx_id对比查找到合适的结果就是小明2。
如果你是可重复读隔离级别,这时候你的ReadView还是第一次select时候生成的ReadView,也就是列表的值还是[100]。所以select的结果是小明1。所以第二次select结果和第一次一样,所以叫可重复读!
也就是说已提交读隔离级别下的事务在每次查询的开始都会生成一个独立的ReadView,而可重复读隔离级别则在第一次读的时候生成一个ReadView,之后的读都复用之前的ReadView。
关于Mysql中MVCC的总结
客观上,我们认为他就是乐观锁的一整实现方式,就是每行都有版本号,保存时根据版本号决定是否成功。但由于Mysql的写操作会加排他锁(前文有讲),如果锁定了还算不算是MVCC?了解乐观锁的小伙伴们,都知道其主要依靠版本控制,即消除锁定,二者相互矛盾,so从某种意义上来说,Mysql的MVCC并非真正的MVCC,他只是借用MVCC的名号实现了读的非阻塞而已。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通