
JVM学习(1)——通过实例总结Java虚拟机的运行机制
俗话说,自己写的代码,6个月后也是别人的代码……复习!复习!复习!涉及到的知识点总结如下:
- JVM的历史
- JVM的运行流程简介
- JVM的组成(基于 Java 7)
- JVM调优参数:-Xmx和-Xms
- 逃逸分析(DoEscapeAnalysis )的概念——JVM栈上分配实验
- JVM中client模式(-client)和server模式(-server)的区别
- 查看GC日志的方法
- 使用idea对JVM进行参数输入
- Java栈,Java堆和方法区的交互原理
-
为了能让递归方法调用的次数更多一些,应该怎么做?
- 1996年 SUN JDK 1.0 Classic VM——纯解释运行,使用外挂进行JIT
- 1997年 JDK1.1 发布——AWT、内部类、JDBC、RMI、反射
- 1998年 JDK1.2 Solaris Exact VM
- JIT 解释器 混合
- Accurate Memory Management 精确内存管理,数据类型敏感
- 提升 GC 性能
- JDK1.2开始称为Java 2,导致了J2SE J2EE J2ME 的出现
- 加入Swing Collections
- 2000年 JDK 1.3 Hotspot (HotSpot 为Longview Technologies开发 被SUN收购)作为默认虚拟机发布——加入JavaSound API
- 2002年 JDK 1.4 Classic VM退出历史舞台(1996年推出的 Classic VM 到2002年出 JDK 1.4 方才退出)——Assert、正则表达式、NIO、IPV6、日志API、加密类库……
- 2004年 JDK1.5 即 JDK5 、J2SE 5 、Java 5 发布了(很重要的一版),是Java语言的发展史上的又一里程碑事件。为了表示这个版本的重要性,JDK 1.5 更名为 5.0
- 泛型
- 注解
- 装箱
- 枚举
- 可变长参数
- Foreach
- 2005年 Java SE 6、JDK 1.6、JDK 6 发布,JavaOne 大会召开,SUN 公司公开 Java SE 6 此时 Java 的各种版本已经更名以取消其中的数字“2”——J2EE更名为Java EE, J2SE更名为Java SE,J2ME更名为Java ME。
- 脚本语言支持
- JDBC 4.0
- Java编译器 API
- 2006年11月13日,SUN 公司宣布 Java 全线采纳 GNU General Public License Version 2,从而公开了 Java 的源代码,并建立OpenJDK——HotSpot 成为Sun JDK 和 OpenJDK 中所带的虚拟机。
- 2008 年 Oracle 收购 BEA——得到JRockit VM。
- 2010 年 Oracle 收购 Sun——得到Hotspot,Oracle 宣布在 JDK 8 时整合 JRockit 和 Hotspot,优势互补,在Hotspot基础上,移植JRockit优秀特性。
- 2011年 JDK 7 发布,延误项目推到JDK 8
- G1
- 动态语言增强
- 64位系统中的压缩指针
- NIO 2.0
- 2014年 JDK 8 发布
- Lambda 表达式
- 语法增强
- Java类型注解
- 2016年 JDK 9 发布——模块化
Java的两大基石:Java 语言规范和 JVM 规范
- –Groovy
- –Clojure
- –Scala
JVM的启动过程是怎样的?
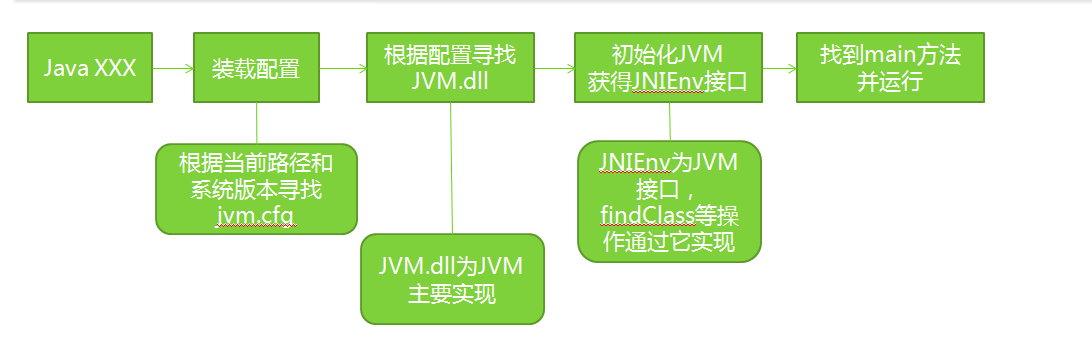
也就是说JVM是如何一步步的找到main方法的……简单总结下,Java虚拟机启动的过程:
- 首先使用 Java 命令启动JVM
- 其次进行JVM配置的装载——根据当前路径和系统的版本去寻找jvm.cfg文件,装载配置。
- 之后会根据加载的配置去寻找JVM.dll文件——JVM的主要实现文件。
- 再后,通过该文件去初始化JVM,并获得相关的接口,比如JNIEnv接口,通过该接口实现findClass操作。
- 最后,通过相关接口(JNIEnv……),找到程序里的main方法,即可进入程序……
如图:
介绍一下 JVM 的基本结构,并说出各个模块的功能?
可以结合这个网络上经典的 JVM 结构图来理解 JVM,当总结完毕,再画一个更加详细的结构图(jdk 7 规范的 JVM):

首先,要知道JVM有一个类加载系统(不然我们的类没法执行),也就是传说中的ClassLoader……Class文件(Java编译之后的)通过类加载器被加载到JVM中,而JVM的内存空间是分区的,主要有如图所示几个区:
- 方法区
- Java 堆
- Java 栈
- 本地方法栈(也就是native方法调用)
而类比物理cpu,JVM也需要一个指针来指向下一条指令的地址,就是图中的PC寄存器,紧接着是执行引擎,用来执行字节码,当然还有一个很重要的模块——GC(垃圾回收器)。下面单独总结下各个主要模块:
- PC寄存器
- 方法区
- Java堆

- Java栈

1 public class Demo {
2 public static int doStaticMethod(int i, long l, float f, Object o, byte b) {
3 return 0;
4 }
5 }
编译之后的具备变量表字节码如下:

1 LOCALVARIABLE i I L0 L1 0 2 LOCALVARIABLE l J L0 L1 1 3 LOCALVARIABLE f F L0 L1 3 4 LOCALVARIABLE o Ljava/lang/Object; L0 L1 4 5 LOCALVARIABLE b B L0 L1 5 6 MAXSTACK = 1 7 MAXLOCALS = 6
可以认为Java栈帧里的局部变量表有很多的槽位组成,每个槽最大可以容纳32位的数据类型,故方法参数里的int i 参数占据了一个槽位,而long l 参数就占据了两个槽(1和2),Object对象类型的参数其实是一个引用,o相当于一个指针,也就是32位大小。byte类型升为int,也是32位大小。如下:

相对再看看实例方法:
public int doInstanceMethod(char c, short s, boolean b) {
return 0;
}
编译之后的具备变量表字节码如下:
1 L1 2 LOCALVARIABLE this LDemo; L0 L1 0 3 LOCALVARIABLE c C L0 L1 1 4 LOCALVARIABLE s S L0 L1 2 5 LOCALVARIABLE b Z L0 L1 3 6 MAXSTACK = 1 7 MAXLOCALS = 4
实例方法的局部变量表和静态方法基本一样,唯一区别就是实例方法在Java栈帧的局部变量表里第一个槽位(0位置)存的是一个this引用(当前对象的引用),后面就和静态方法的一样了。
再看,Java栈里的方法调用组成帧栈的过程:
1 public static int doStaticMethod(int i, long l, float f, Object o, byte b) {
2 return doStaticMethod(i, l, f, o, b);
3 }
如上一个递归调用(栈的内存溢出),当类中方法(静态 or 实例)调用的时候,就会在Java栈里创建一个帧,每一次调用都会产生一个帧,并持续的压入栈顶……一直到Java栈满了,就发生了溢出!或者方法调用结束了,那么对应的Java栈帧就被移除。

注意,一个Java栈帧里除了保存局部变量表外,还会保存操作数栈,返回地址等信息。顺势我在分析下Java栈帧里的操作数栈,理解Java栈帧里的操作数栈前先知道一个结论——因为Java没有寄存器,故所有参数传递使用Java栈帧里的操作数栈。
看一个例子:
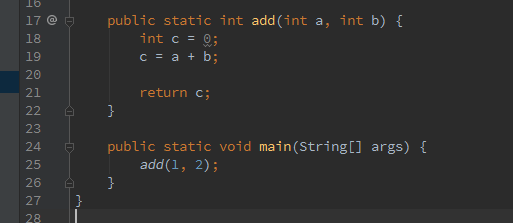
注意,对于局部变量表的槽位,按照从0开始的顺序,依次是方法参数,之后是方法内的局部变量,局部变量0就是a,1就是b,2就是c…… 编译之后的字节码为:
// access flags 0x9
public static add(II)I
L0
LINENUMBER 18 L0 // 对应源代码第18行,以此类推
ICONST_0 // 把常量0 push 到Java栈帧的操作数栈里
ISTORE 2 // 将0从操作数栈pop到局部变量表槽2里(c),完成赋值
L1
LINENUMBER 19 L1
ILOAD 0 // 将局部变量槽位0(a)push 到Java栈帧的操作数栈里
ILOAD 1 // 把局部变量槽1(b)push到操作数栈
IADD // pop出a和b两个变量,求和,把结果push到操作数栈
ISTORE 2 // 把结果从操作数栈pop到局部变量2(a+b的和给c赋值)
L2
LINENUMBER 21 L2
ILOAD 2 // 局部变量2(c)push 到操作数栈
IRETURN // 返回结果
L3
LOCALVARIABLE a I L0 L3 0
LOCALVARIABLE b I L0 L3 1
LOCALVARIABLE c I L1 L3 2
MAXSTACK = 2
MAXLOCALS = 3
发现,整个计算过程的参数传递和操作数栈密切相关!如图:
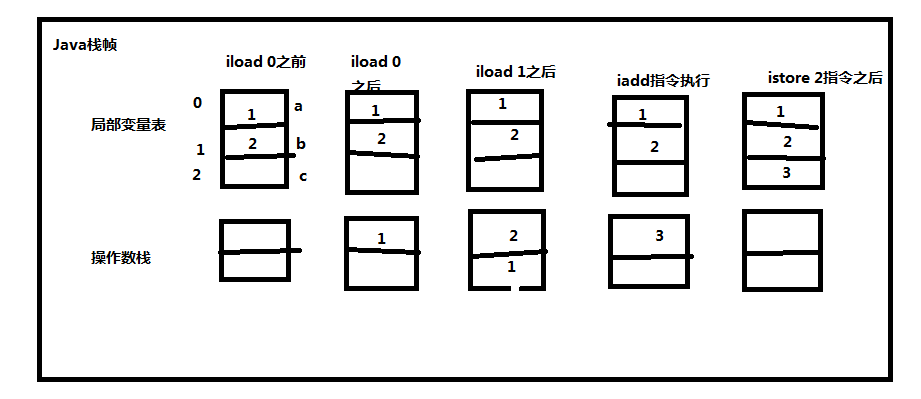
继续总结,区分Java堆上分配内存和栈上分配内存
回忆c++语言,如下代码:
 View Code
View Codenew出的对象是在堆中分配内存,每次使用完毕,必须记得手动回收该内存区域,使用了delete运算符,如果一旦这样的分配多了,那么很可能忘记删除,就可能会发生内存泄漏问题,一旦发生就很难发现和解决。如果是这样:
View Code此时就叫在栈中分配,栈上分配,函数调用完成自动清理内存,不会发生内存泄漏。而堆上分配,每次需要清理空间。
类似的原理,在Java中:
1 public class OnStackTest {
2 /**
3 * alloc方法内分配了两个字节的内存空间
4 */
5 public static void alloc(){
6 byte[] b = new byte[2];
7 b[0] = 1;
8 }
9
10 public static void main(String[] args) {
11 long b = System.currentTimeMillis();
12
13 // 分配 100000000 个 alloc 分配的内存空间
14 for(int i = 0; i < 100000000; i++){
15 alloc();
16 }
17
18 long e = System.currentTimeMillis();
19 System.out.println(e - b);
20 }
21 }
alloc方法内的b(new)分配的内存按照之前理论,我开始认为是分到了Java堆,那么如果系统的内存空间不够,是不是会发生内存泄漏?!下面做一个实验来验证。
再实验之前先总结几个JVM调优的参数和一些需要使用的概念:
- -XX:功能开关
- -Xms:minimum memory size for pile and heap
- -Xmx:maximum memory size for pile and heap
- 打印GC日志——我还需要使用JVM的一个查看GC日志的参数:-XX:+PrintGC(当GC发生时打印信息)
- JVM的server模式和client模式
- 逃逸分析
举例:对JVM堆内存进行基本的配置可以使用哪个命令参数?
-Xms 10m,表示JVM Heap(堆内存)最小尺寸10MB,最开始只有 -Xms 的参数,表示 `初始` memory size(m表示memory,s表示size),属于初始分配10m,-Xms表示的 `初始` 内存也有一个 `最小` 内存的概念(其实常用的做法中初始内存采用的也就是最小内存)。
-Xmx 10m,表示JVM Heap(堆内存)最大允许的尺寸10MB,按需分配。如果 -Xmx 不指定或者指定偏小,也许出现java.lang.OutOfMemory错误,此错误来自JVM不是Throwable的,无法用try...catch捕捉。
JVM的server模式和client模式的区别是什么?
-client,-server 两个参数可以设置JVM使用何种运行模式,client模式启动较快,但运行性能和内存管理效率不如server模式,通常用于客户端程序。相反server模式启动比client慢,但可获得更高的运行性能,常用语服务器程序。
windows上,缺省的虚拟机类型为client模式(使用java -verson命令查看),如果要使用server模式,就需要在启动虚拟机时加-server参数,以获得更高性能,对服务器端应用,推荐采用server模式,尤其是多个CPU的系统。
在Linux,Solaris上缺省采用server模式。
官方这样介绍:JVM Server模式与client模式启动,最主要的差别在于:-Server模式启动时,速度较慢,但是一旦运行起来后,性能将会有很大的提升。JVM工作在Server模式可以大大提高性能,但应用的启动会比client模式慢大概10%。当该参数不指定时,虚拟机启动检测主机是否为服务器,如果是,则以Server模式启动,否则以client模式启动,Java 5.0检测的根据是至少2个CPU和最低2GB内存。
综上,当JVM用于启动GUI界面的交互应用时适合于使用client模式,当JVM用于运行服务器后台程序时建议用Server模式。
JVM在client模式默认-Xms是1M,-Xmx是64M;
JVM在Server模式默认-Xms是128M,-Xmx是1024M。可以通过运行:java -version来查看jvm默认工作在什么模式。
什么是JVM 的逃逸分析(Escape Analysis)?
所谓逃逸分析,是JVM的一种内存分配的优化方式,一些参考书上这样写到:在编程语言的编译优化原理中,分析指针动态范围的方法称之为逃逸分析。通俗一点讲,就是当一个对象的指针被多个方法或线程引用时,我们称这个指针发生了逃逸。而用来分析这种逃逸现象的方法,就称之为逃逸分析。
我们知道java对象是在堆里分配的,在Java栈帧中,只保存了对象的指针。当对象不再使用后,需要依靠GC来遍历引用树并回收内存,如果对象数量较多,将给GC带来较大压力,也间接影响了应用的性能。减少临时对象在堆内分配的数量,无疑是最有效的优化方法,接下来,举一个场景来阐述。
假设在方法体内,声明了一个局部变量,且该变量在方法执行生命周期内未发生逃逸(在方法体内,未将引用暴露给外面)。按照JVM内存分配机制,首先会在堆里创建变量类的实例,然后将返回的对象指针压入调用栈,继续执行。这是优化前,JVM的处理方式。
逃逸分析优化 – 栈上分配,优化原理:JVM分析找到未逃逸的变量(在方法体内,未将引用暴露给外面),将变量类的实例化内存直接在栈里分配(无需进入堆),分配完成后,继续在调用栈内执行,最后线程结束,栈空间被回收,局部变量也被回收。这是优化后的处理方式,对比可以看出,主要区别在栈空间直接作为临时对象的存储介质。从而减少了临时对象在堆内的分配数量。
如下例子是发生了逃逸的局部对象变量:
View Code记住一个结论:启用逃逸分析的运行性能6倍于未启用逃逸分析的程序。逃逸分析是JVM层面的工作,JVM做了逃逸分析,这样没有逃逸的对象就可以被优化,从而减少堆的大小并减少GC。如果JVM没有加逃逸分析,就算自己优化了代码,也不会有效果。
JVM中启用逃逸分析需要安装jdk1.6.0_14+版本,运行java时传递jvm参数 -XX:+DoEscapeAnalysis,取消逃逸分析把+改为-。
下面回到之前的实验代码,如下:
View Code我启用逃逸分析(可以看出b引用的对象没有逃逸),并设置在服务端模式下运行程序(性能较高),修改JVM堆内存最小(初始化)为10m,最大可用也为10m,且打印GC作为实验结果。如下在idea设置JVM参数:
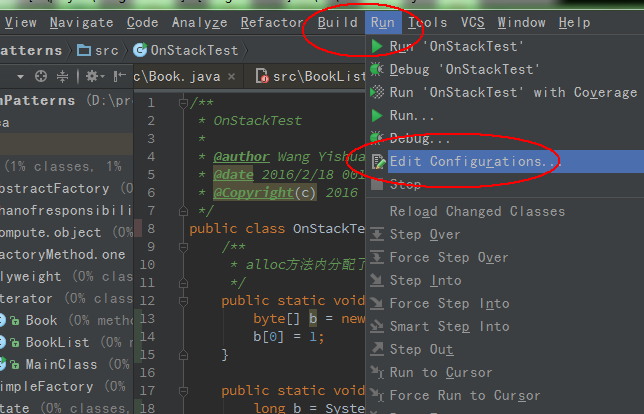
进入菜单之后,在如下地方填写JVM参数,在JVM启动时,传递给jvm
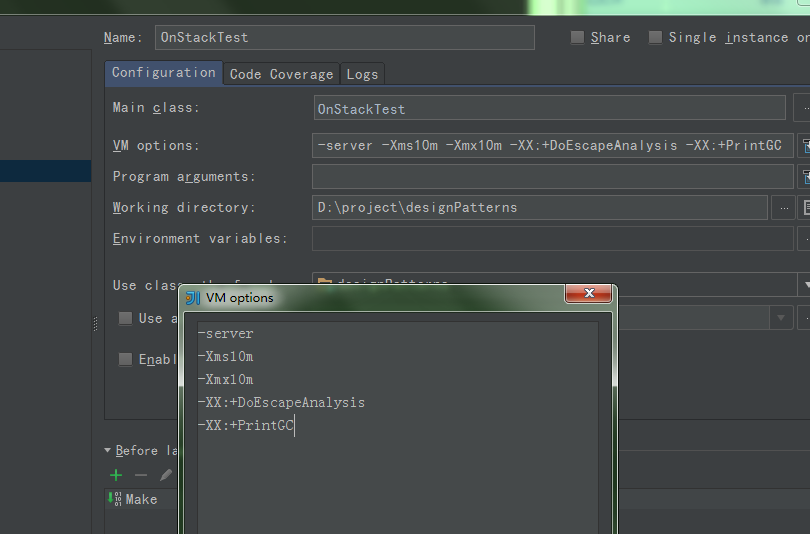
运行结果:
[GC (Allocation Failure) 2816K->727K(9984K), 0.0049897 secs]
23
Process finished with exit code 0
得知,运行了23ms,没有GC发生。作为对比,我不用任何参数配置,也不进行逃逸分析,且本机在win下,默认是客户端模式运行程序如下结果:

发现运行了1285ms!间接的证明了之前的理论是有效果的。
再进行实验,只是取消逃逸分析,其他不变,如下:
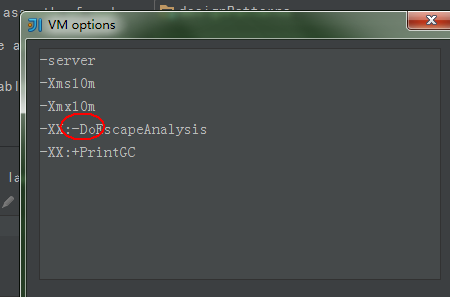
运行结果:(数据很多……)
View Code果不其然,不仅运行速度慢了很多,且可以推断出变量b指向的对象在Java堆里分配内存了。就如之前理论,逃逸分析是JVM层面的工作,如果JVM不进行逃逸分析,那么即使优化了代码,也是在堆中分配内存(因为发生了大量的GC日志记录~!),而之前的进行逃逸分析运行不仅速度很快,且没有任何GC记录,说明逃逸分析之后b是在Java栈帧里分配的内存,方法调用完毕自动清理内存,不会发生内存泄漏,也不GC!
对Java栈——栈上分配优化的小结:
-
必须是小对象(一般几十个bytes),且必须是在没有逃逸的情况下,如果JVM使用了逃逸分析优化,则该小对象可以直接分配在栈上,因为栈的空间不大(一般也就到1m封顶了),更没有堆大。
-
直接分配在栈上,方法调用完毕,Java栈帧就立即被移除,故内存可以自动回收,减轻GC压力。
- 大对象(栈的空间不允许)或者逃逸的对象无法在栈上分配(即使启动了JVM的逃逸分析优化,且因为Java栈是线程私有的,不共享,局部对象变量被其他线程或者方法引用了肯定不能在栈分配内存)
总结到这里不禁有一个疑问,为什么方法调用(包括其他编程语言的函数调用等)需要使用栈?
占坑,留在下一个单元进行总结。
对JVM基本结构的小结,再次回忆上文提到的JVM的基本结构:
现在单独拿出红色框里的方法区,Java堆,Java栈区,来看看三者之间如何交互。
且前面也说了Java堆是全局共享的,几乎所有的对象都保存到了Java堆,堆是发生GC的主要区域。
而Java栈是线程私有的,且每个线程启动都会创建一个Java栈,栈内还有帧,Java栈中的每个帧都保存一个方法调用的局部变量、操作数栈、指向常量池的指针等,且每一次方法调用都会创建一个帧,并压栈。
还有方法区,它是保存JVM装载的类的信息的,比如类型的常量池、类中的字段,类中的方法信息、方法的字节码(bytecode)等,注意这不是绝对的!比如:JDK 6 时,String等字符串常量的信息是置于方法区中的,但是到了JDK 7 时,已经移动到了Java堆。
所以,方法区也好,Java堆也罢,到底保存了什么,其实没有具体定论,要结合不同的JVM版本来分析,因为技术是发展的!不过一般认为,方法区就是保存了JVM装载的类的信息。
下面再看一个(网上找的)更加细致的JVM内存结构图(以后会经常看到):
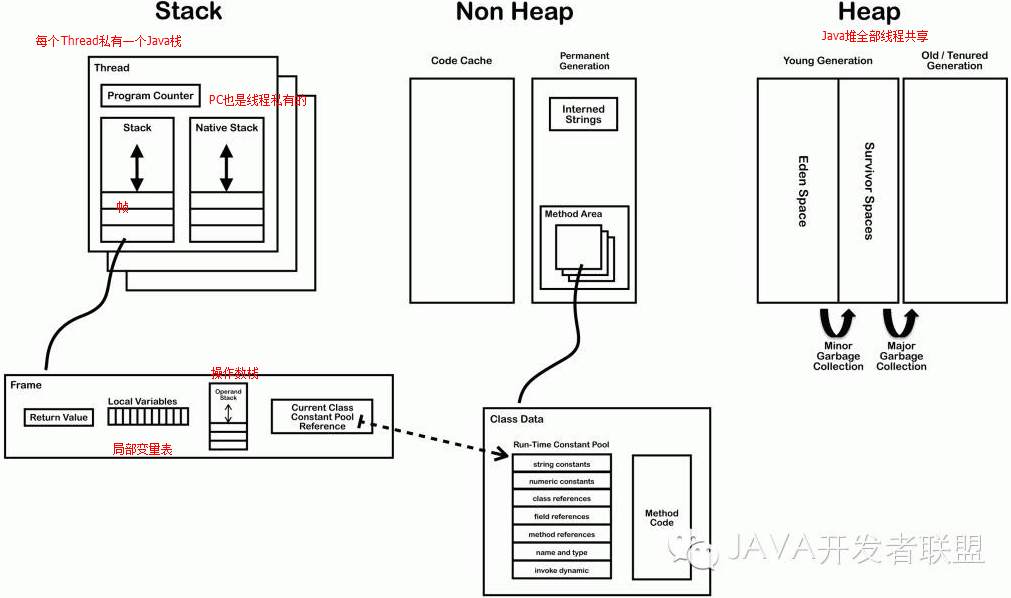
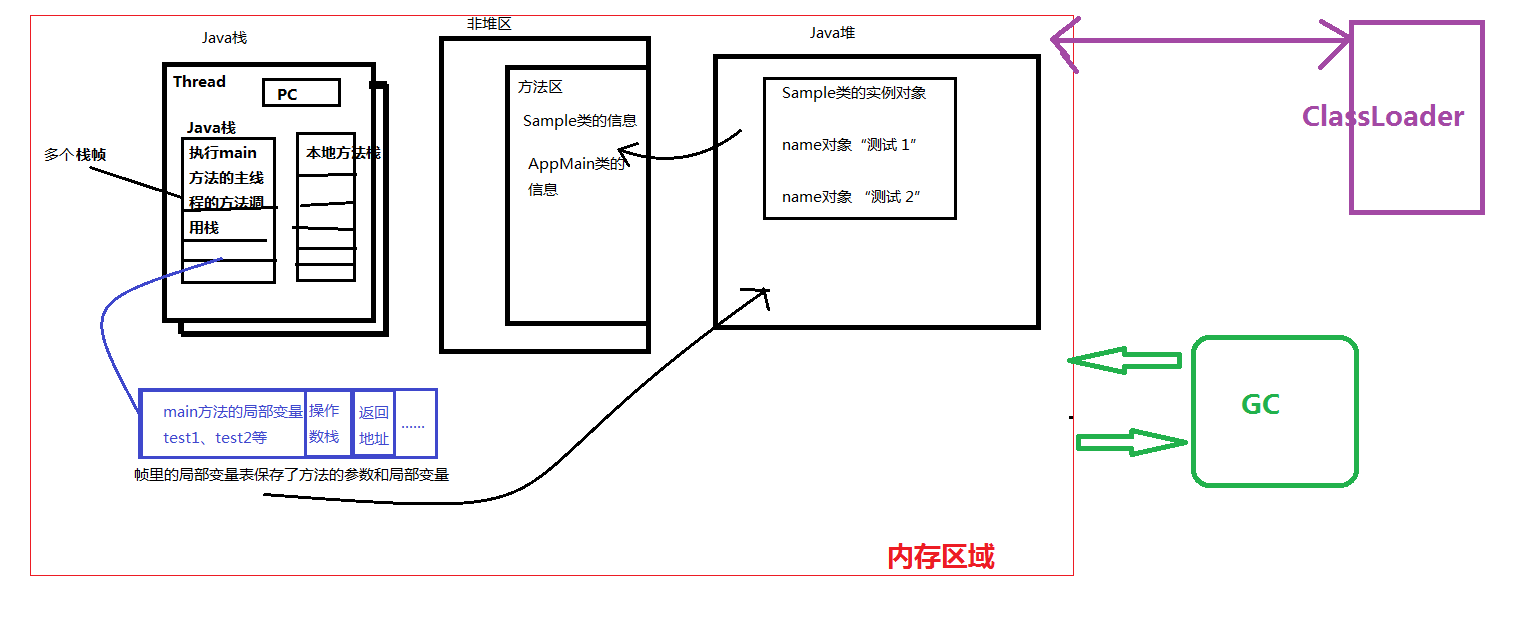
进阶:实例说明JVM的栈、堆、和方法区的交互
看上图有些复杂,下面用一个例子(来源于互联网)帮助总结他们三者之间的交互原理。
View Code众所周知,通常Java程序都要从main方法进入,故一般情况下Java程序都有一个main方法,而它本身也是一个线程(主线程),自然就对应一个Java栈,main方法也就对应一个Java的栈帧了。而根据之前JVM结构的分析,我们知道类会被JVM装载,那么JVM装载的类的信息放在了方法区里(包括字段信息,方法本身的字节码等,当然main方法也不例外),而方法体内的局部变量(包括形参),本例是对象的引用,统一放到Java栈帧里。而对象本身存放到了Java堆。如下注释:
View Code画成图就是这样:类中方法本身(字节码)存放在方法区,Java栈里的对象引用指向了Java堆里的对象,之后堆里的对象需要的类的信息要去方法区里(非堆区)读取。
问题:为了能让递归方法调用的次数更多一些,应该怎么做呢?
众所周知,递归是指函数直接或间接地调用自己,传统地递归过程就是函数调用,涉及返回地址、函数参数、寄存器值等压栈(在x86-64上通常用寄存器保存函数参数),这样做的缺点有二:
- 效率低,占内存
- 如果递归链过长,可能会statck over flow(栈区的空间通常是OS设定好的,通常只有几M)
View Code使用递归实现:
View Code后来人们发现,对于该递归而言,一些压栈操作并无必要,递归中的子问题规模几乎不变,每次只减去了1或者2。如果画一个递归树,会发现很多相同的子树!!!说明该实现浪费了很多内存和时间,当解决Fn-1问题时,计算了Fn-2和Fn-3,解决Fn问题时,计算了Fn-1和Fn-2,实际上我只需要计算一次Fn-2就ok了。优化——使用自底向上的算法:线性递归
View Code依次计算Fn,F0、F1、F2、F3……Fn,花费线性时间,因为我的输入是线性的。不过还不是更好的,线性递归每次调用时,针对上一次调用的结果,它不进行收集(保存),只能依靠顺次的展开,这样也很消耗内存。下面引出一个概念——尾递归:尾递归,它比线性递归多一个参数,这个参数是上一次调用函数得到的结果,尾递归每次调用都在收集结果,避免了线性递归不收集结果只能依次展开,消耗内存的坏处。如下:
View Code尾递归的情况是下层计算结果对上层“无用”(上一层运算已经做完,不依赖后续的递归),为了效率,直接将下一层需要的空间覆盖在上一层上,尾递归和一般的递归不同在对内存的占用,普通递归创建stack累积而后计算收缩,尾递归只会占用恒量的内存(和迭代一样)。通俗的说,尾递归是把变化的参数传递给递归函数的变量了。
怎么写尾递归?形式上只要最后一个return语句是单纯函数就可以。如:
return tailrec(x+1);
而
return tailrec(x+1) + x;
则不可以。因为无法更新tailrec()函数内的实际变量,只是新建一个栈。
View Code尾递归:
View Code综上,可以尽可能高效的利用栈空间,增加递归调研数。
