

Conv层与BN层融合
Conv层与BN层融合
简介
当前CNN卷积层的基本组成单元标配:Conv + BN +ReLU 三剑客,可以将BN层的运算融合到Conv层中,把三层减少为一层
减少运算量,加速推理。本质上是修改了卷积核的参数,在不增加Conv层计算量的同时,适用于模型推理。
BN(批归一化)层常用于在卷积层之后,对feature maps进行归一化,从而加速网络学习,也具有一定的正则化效果。训练时,BN需要学习一个minibatch数据的均值、方差,然后利用这些信息进行归一化。而在推理过程,通常为了加速,都会把BN融入到其上层卷积中,这样就将两步运算变成了一步,也就达到了加速目的。
要求
融合BN与卷积要求BN层位于卷积之后
且融合后的卷积层参数convolution_param中的bias_term必须为true。
原理
BN层参数
nn.Conv2d参数:
滤波器权重, W:conv.weight
bias, b:conv.bias
nn.BatchNorm2d参数:
scaling, γ:bn.weight
shift, β:bn.bias
mean estimate,μ: bn.running_mean
variance estimate,σ^2 :bn.running_var
ϵ (for numerical stability): bn.eps
BN层计算公式
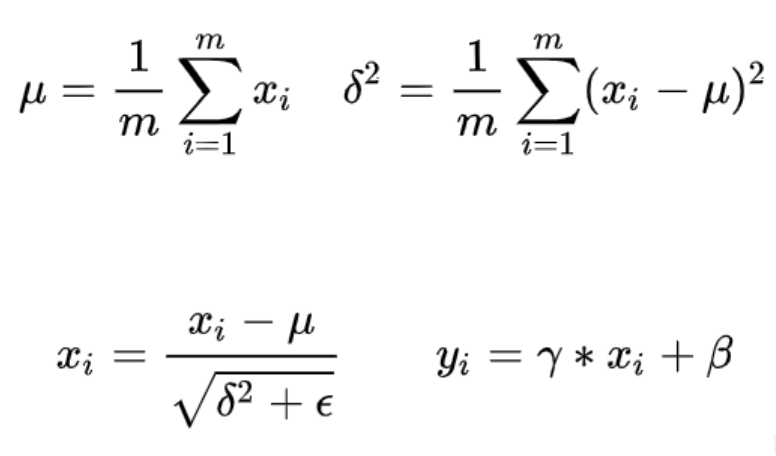
在训练的时候,均值 \(\mu\) 、方差 $ \sigma^2$ 、 \(\gamma\) 、 \(\beta\) 是一直在更新的,在推理的时候,以上四个值都是固定了的,也就是推理的时候,均值和方差来自训练样本的数据分布。
因此,在推理的时候,上面BN的计算公式可以变形
\[{y}_{i}=\gamma \frac{x_{i}-\mu}{\sqrt{\sigma^{2}+\epsilon}}+\beta=\frac{\gamma x_{i}}{\sqrt{\sigma^{2}+\epsilon}}+(\beta-\frac{\gamma \mu}{\sqrt{\sigma^{2}+\epsilon}})
\]
上面公式可以等价于
\[y_i=ax_i+b
\]
\[a=\frac{\gamma}{\sqrt{\sigma^{2}+\epsilon}}\quad \quad b= (\beta-\frac{\gamma \mu}{\sqrt{\sigma^{2}+\epsilon}})
\]
$ \mu , \sigma^2 $ 为这个batch上计算得到的均值和方差(在B,H,W维度上计算,每个channel单独计算),而 \(\epsilon\) 是防止除零所设置的一个极小值, \(\gamma\) 是比例参数,而 \(\beta\) 是平移系数。
此时,BN层转换成Conv层
Conv和BN计算合并
\[Y=\gamma \frac{(W*X+B)-\mu}{\sqrt{\sigma^{2}+\epsilon}}+\beta
\]
合并后
\[Y=\frac{ \gamma *W}{\sqrt{\sigma^{2}+\epsilon}} *X + \frac{\gamma*(B-\mu)}{\sqrt{\sigma^{2}+\epsilon}}+\beta
\]
\[W_{merged}=\frac{\gamma}{\sqrt{\sigma^{2}+\epsilon}}* W = W*a \quad \quad B_{merged}= \frac{\gamma*(B-\mu)}{\sqrt{\sigma^{2}+\epsilon}}+\beta = (B- \mu)*a+ \beta
\]
1.首先我们将测试阶段的BN层(一般称为frozen BN)等效替换为一个1x1卷积层
2.将卷积层与归一化层融合
pytorch-BN融合
import torch
import torchvision
def fuse(conv, bn):
fused = torch.nn.Conv2d(
conv.in_channels,
conv.out_channels,
kernel_size=conv.kernel_size,
stride=conv.stride,
padding=conv.padding,
bias=True
)
# setting weights
w_conv = conv.weight.clone().view(conv.out_channels, -1)
w_bn = torch.diag(bn.weight.div(torch.sqrt(bn.eps+bn.running_var)))
fused.weight.copy_( torch.mm(w_bn, w_conv).view(fused.weight.size()) )
# setting bias
if conv.bias is not None:
b_conv = conv.bias
else:
b_conv = torch.zeros( conv.weight.size(0) )
b_bn = bn.bias - bn.weight.mul(bn.running_mean).div(
torch.sqrt(bn.running_var + bn.eps)
)
fused.bias.copy_( b_conv + b_bn )
return fused
# Testing
# we need to turn off gradient calculation because we didn't write it
torch.set_grad_enabled(False)
x = torch.randn(16, 3, 256, 256)
resnet18 = torchvision.models.resnet18(pretrained=True)
# removing all learning variables, etc
resnet18.eval()
model = torch.nn.Sequential(
resnet18.conv1,
resnet18.bn1
)
f1 = model.forward(x)
fused = fuse(model[0], model[1])
f2 = fused.forward(x)
d = (f1 - f2).mean().item()
print("error:",d)
ONNX-BN融合
import onnx
import os
from onnx import optimizer
# Preprocessing: load the model contains two transposes.
# model_path = os.path.join('resources', 'two_transposes.onnx')
# original_model = onnx.load(model_path)
original_model = onnx.load("resne18.onnx")
# Check that the IR is well formed
onnx.checker.check_model(original_model)
print('The model before optimization:\n\n{}'.format(onnx.helper.printable_graph(original_model.graph)))
# A full list of supported optimization passes can be found using get_available_passes()
all_passes = optimizer.get_available_passes()
print("Available optimization passes:")
for p in all_passes:
print('\t{}'.format(p))
print()
# Pick one pass as example
passes = ['fuse_add_bias_into_conv']
# Apply the optimization on the original serialized model
optimized_model = optimizer.optimize(original_model, passes)
print('The model after optimization:\n\n{}'.format(onnx.helper.printable_graph(optimized_model.graph)))
# save new model
onnx.save(optimized_model, "newResnet18.onnx")
参考资料
https://www.cnblogs.com/nowgood/p/juan-ji-ceng-he-liang-hua-ceng-rong-he.html?ivk_sa=1024320u
