

torch导出onnx示例-yolo
onnx导出示例
yolov5
yolov5是一种目标检测算法,通过使用深度学习算法,可以通过输入图像,输出图像中存在的目标的种类和位置等信息。yolov5 onnx则是在此基础上,通过使用onnx技术,将yolov5模型导出为onnx格式,方便在不同的平台上使用,同时提高了算法的效率和准确度。
导出源码
def export_onnx(model, im, file, opset, dynamic, simplify, prefix=colorstr('ONNX:')):
# YOLOv5 ONNX export
check_requirements('onnx')
import onnx
LOGGER.info(f'\n{prefix} starting export with onnx {onnx.__version__}...')
f = file.with_suffix('.onnx')
output_names = ['output0', 'output1'] if isinstance(model, SegmentationModel) else ['output0']
if dynamic:
dynamic = {'images': {0: 'batch', 2: 'height', 3: 'width'}} # shape(1,3,640,640)
if isinstance(model, SegmentationModel):
dynamic['output0'] = {0: 'batch', 1: 'anchors'} # shape(1,25200,85)
dynamic['output1'] = {0: 'batch', 2: 'mask_height', 3: 'mask_width'} # shape(1,32,160,160)
elif isinstance(model, DetectionModel):
dynamic['output0'] = {0: 'batch', 1: 'anchors'} # shape(1,25200,85)
torch.onnx.export(
model.cpu() if dynamic else model, # --dynamic only compatible with cpu
im.cpu() if dynamic else im,
f,
verbose=False,
opset_version=opset,
do_constant_folding=True,
input_names=['images'],
output_names=output_names,
dynamic_axes=dynamic or None)
# Checks
model_onnx = onnx.load(f) # load onnx model
onnx.checker.check_model(model_onnx) # check onnx model
# Metadata
d = {'stride': int(max(model.stride)), 'names': model.names}
for k, v in d.items():
meta = model_onnx.metadata_props.add()
meta.key, meta.value = k, str(v)
onnx.save(model_onnx, f)
# Simplify
if simplify:
try:
cuda = torch.cuda.is_available()
check_requirements(('onnxruntime-gpu' if cuda else 'onnxruntime', 'onnx-simplifier>=0.4.1'))
import onnxsim
LOGGER.info(f'{prefix} simplifying with onnx-simplifier {onnxsim.__version__}...')
model_onnx, check = onnxsim.simplify(model_onnx)
assert check, 'assert check failed'
onnx.save(model_onnx, f)
except Exception as e:
LOGGER.info(f'{prefix} simplifier failure: {e}')
return f, model_onnx
导出参数
(mmcv) root@gpu:/data/yolov5-7.0# python export.py --weights yolov5s.pt --img-size 640 --batch-size 1 --dynamic --include onnx
export: data=data/coco128.yaml, weights=['yolov5s.pt'], imgsz=[640], batch_size=1, device=cpu, half=False, inplace=False, keras=False, optimize=False, int8=False, dynamic=True, simplify=False, opset=12, verbose=False, workspace=4, nms=False, agnostic_nms=False, topk_per_class=100, topk_all=100, iou_thres=0.45, conf_thres=0.25, include=['onnx']
YOLOv5 🚀 dfb9f6d Python-3.8.12 torch-1.13.0+cu116 CPU
Fusing layers...
YOLOv5s summary: 213 layers, 7225885 parameters, 0 gradients
PyTorch: starting from yolov5s.pt with output shape (1, 25200, 85) (14.1 MB)
ONNX: starting export with onnx 1.13.1...
ONNX: export success ✅ 0.6s, saved as yolov5s.onnx (27.6 MB)
Export complete (1.1s)
Results saved to /data/persist/tzxa/enncv_tzx/yolov5-7.0
Detect: python detect.py --weights yolov5s.onnx
Validate: python val.py --weights yolov5s.onnx
PyTorch Hub: model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5s.onnx')
Visualize: https://netron.app
模型可视化
onnx模型可视化,看出输出部分进行的处理如下:三输出模型的输出结果是 tx ty tw th 和 t0,即下图中sigmoid之前的参数,单输出的模型直接输出的是 bx by bw bh 和 score,即直接对应到原图中的坐标参数。
输入格式:1x3x640x640,3是RGB三通道,总体是 Batch Channel H W。
输出有三层,分别在三个不同的位置,有不同的格式。
标准的 yolov5 的 输出 有 三个 ,
分别是 1x255x80x80 1x255x40x40 1x255x20x20 其中这里的255是85*3,80×80、40×40 和 20×20 是特征图分辨率
85是指5+80=85,其中80是类别数量,每个类别数量对应一个label score,一共80个label score,而5是指box的四个坐标加一个box score.
当输入图像是 640×640 时,输出数据是 (1, 25200, 4+1+class):4+1+class 是检测框的坐标、大小 和 分数。
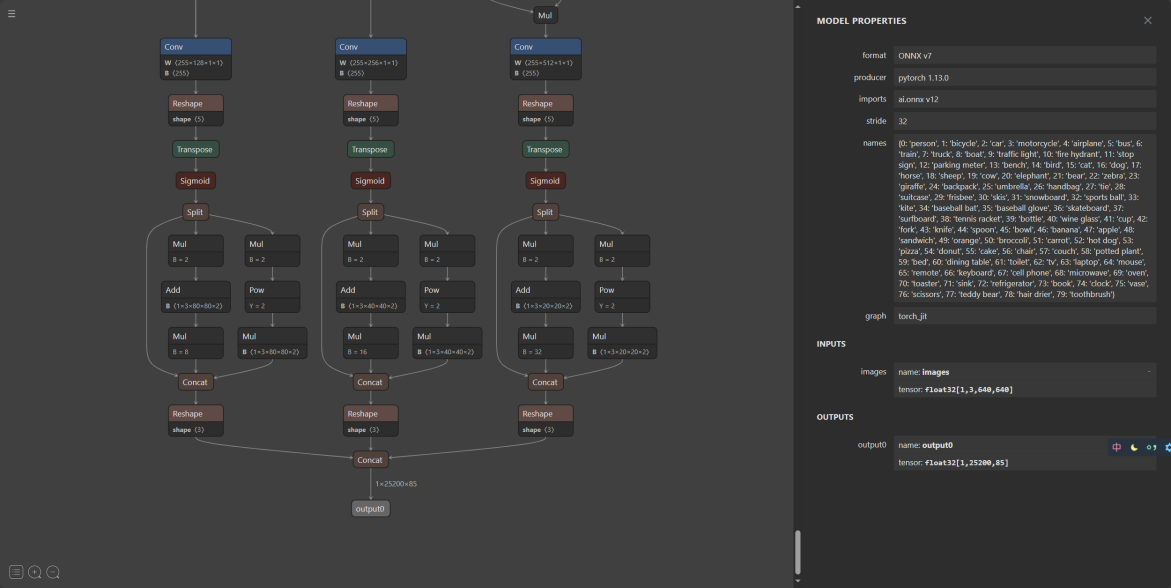
onnx推理
import onnxruntime
import cv2
import numpy as np
onnx_model = onnx.load("yolov5s.onnx")
onnx.checker.check_model(onnx_model)
ort_session = onnxruntime.InferenceSession("yolov5s.onnx")
def to_numpy(tensor):
return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()
def predict(image):
image = cv2.resize(image, (640, 640))
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB).astype(np.float32)
image /= 255
image = np.transpose(image, [2, 0, 1])
image = np.expand_dims(image, axis=0)
ort_inputs = {ort_session.get_inputs()[0].name: to_numpy(image)}
ort_outputs = ort_session.run(None, ort_inputs)
return ort_outputs
image = cv2.imread("test.jpg")
outputs = predict(image)
print(outputs)
# 完整的yolv5 推理
import onnx
import onnxruntime
import numpy as np
import cv2
import sys
CLASSES = ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear',
'hair drier', 'toothbrush'] # coco80类别
# 自定义标签获取
# meta = sess.get_modelmeta().custom_metadata_map
# print( meta )
def load_onnx(onnx_path):
"""检查onnx模型并初始化onnx"""
onnx_model = onnx.load(onnx_path)
try:
onnx.checker.check_model(onnx_model)
except Exception:
print("Model incorrect")
else:
print("Model correct")
options = onnxruntime.SessionOptions()
sess = onnxruntime.InferenceSession(onnx_path,
providers=['CPUExecutionProvider'])
# 'CUDAExecutionProvider',
input_name = sess.get_inputs()[0].name
output_name = sess.get_outputs()[0].name
print(input_name,output_name)
return sess,input_name,output_name
def onnx_inference(sess,input_name,output_name,data):
pred_onnx = sess.run([output_name], {input_name: data})
return pred_onnx
def letterbox(im, new_shape=(640, 640), color=(114, 114, 114), auto=True, scaleFill=False, scaleup=True, stride=32):
# Resize and pad image while meeting stride-multiple constraints
shape = im.shape[:2] # current shape [height, width]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
# Scale ratio (new / old)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
if not scaleup: # only scale down, do not scale up (for better val mAP)
r = min(r, 1.0)
# Compute padding
ratio = r, r # width, height ratios
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
if auto: # minimum rectangle
dw, dh = np.mod(dw, stride), np.mod(dh, stride) # wh padding
elif scaleFill: # stretch
dw, dh = 0.0, 0.0
new_unpad = (new_shape[1], new_shape[0])
ratio = new_shape[1] / shape[1], new_shape[0] / shape[0] # width, height ratios
dw /= 2 # divide padding into 2 sides
dh /= 2
if shape[::-1] != new_unpad: # resize
im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
return im, ratio, (dw, dh)
def box_iou(box1, box2, eps=1e-7):
(a1, a2), (b1, b2) = box1.unsqueeze(1).chunk(2, 2), box2.unsqueeze(0).chunk(2, 2)
inter = (np.min(a2, b2) - np.max(a1, b1)).clamp(0).prod(2)
return inter / ((a2 - a1).prod(2) + (b2 - b1).prod(2) - inter + eps)
def xywh2xyxy(x):
# Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
# isinstance 用来判断某个变量是否属于某种类型
y = np.copy(x)
y[..., 0] = x[..., 0] - x[..., 2] / 2 # top left x
y[..., 1] = x[..., 1] - x[..., 3] / 2 # top left y
y[..., 2] = x[..., 0] + x[..., 2] / 2 # bottom right x
y[..., 3] = x[..., 1] + x[..., 3] / 2 # bottom right y
return y
def nms_boxes(boxes, scores):
x = boxes[:, 0]
y = boxes[:, 1]
w = boxes[:, 2] - boxes[:, 0]
h = boxes[:, 3] - boxes[:, 1]
areas = w * h
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x[i], x[order[1:]])
yy1 = np.maximum(y[i], y[order[1:]])
xx2 = np.minimum(x[i] + w[i], x[order[1:]] + w[order[1:]])
yy2 = np.minimum(y[i] + h[i], y[order[1:]] + h[order[1:]])
w1 = np.maximum(0.0, xx2 - xx1 + 0.00001)
h1 = np.maximum(0.0, yy2 - yy1 + 0.00001)
inter = w1 * h1
ovr = inter / (areas[i] + areas[order[1:]] - inter)
inds = np.where(ovr <= 0.45)[0]
order = order[inds + 1]
keep = np.array(keep)
return keep
def non_max_suppression(
prediction,
conf_thres=0.25,
iou_thres=0.45,
classes=None,
agnostic=False,
multi_label=False,
labels=(),
max_det=300,
nm=0, # number of masks
):
"""Non-Maximum Suppression (NMS) on inference results to reject overlapping detections
Returns:
list of detections, on (n,6) tensor per image [xyxy, conf, cls]
"""
# Checks
assert 0 <= conf_thres <= 1, f'Invalid Confidence threshold {conf_thres}, valid values are between 0.0 and 1.0'
assert 0 <= iou_thres <= 1, f'Invalid IoU {iou_thres}, valid values are between 0.0 and 1.0'
if isinstance(prediction, (list, tuple)): # YOLOv5 model in validation model, output = (inference_out, loss_out)
prediction = prediction[0] # select only inference output
bs = prediction.shape[0] # batch size
nc = prediction.shape[2] - nm - 5 # number of classes
xc = prediction[..., 4] > conf_thres # candidates
# Settings
max_wh = 7680 # (pixels) maximum box width and height
max_nms = 30000 # maximum number of boxes into torchvision.ops.nms()
redundant = True # require redundant detections
multi_label &= nc > 1 # multiple labels per box (adds 0.5ms/img)
merge = False # use merge-NMS
mi = 5 + nc # mask start index
output = [np.zeros((0, 6 + nm))] * bs
for xi, x in enumerate(prediction): # image index, image inference
x = x[xc[xi]] # confidence
if labels and len(labels[xi]):
lb = labels[xi]
v = np.zeros(len(lb), nc + nm + 5)
v[:, :4] = lb[:, 1:5] # box
v[:, 4] = 1.0 # conf
v[range(len(lb)), lb[:, 0].long() + 5] = 1.0 # cls
x = np.concatenate((x, v), 0)
# If none remain process next image
if not x.shape[0]:
continue
x[:, 5:] *= x[:, 4:5] # conf = obj_conf * cls_conf
# Box/Mask
box = xywh2xyxy(x[:, :4]) # center_x, center_y, width, height) to (x1, y1, x2, y2)
mask = x[:, mi:] # zero columns if no masks
# Detections matrix nx6 (xyxy, conf, cls)
if multi_label:
i, j = (x[:, 5:mi] > conf_thres).nonzero(as_tuple=False).T
x = np.concatenate((box[i], x[i, 5 + j, None], j[:, None].float(), mask[i]), 1)
else: # best class only
conf = np.max(x[:, 5:mi], 1).reshape(box.shape[:1][0], 1)
j = np.argmax(x[:, 5:mi], 1).reshape(box.shape[:1][0], 1)
x = np.concatenate((box, conf, j, mask), 1)[conf.reshape(box.shape[:1][0]) > conf_thres]
# Filter by class
if classes is not None:
x = x[(x[:, 5:6] == np.array(classes, device=x.device)).any(1)]
# Check shape
n = x.shape[0] # number of boxes
if not n: # no boxes
continue
index = x[:, 4].argsort(axis=0)[:max_nms][::-1]
x = x[index]
# Batched NMS
c = x[:, 5:6] * (0 if agnostic else max_wh) # classes
boxes, scores = x[:, :4] + c, x[:, 4] # boxes (offset by class), scores
i = nms_boxes(boxes, scores)
i = i[:max_det] # limit detections
# 用来合并框的
if merge and (1 < n < 3E3): # Merge NMS (boxes merged using weighted mean)
iou = box_iou(boxes[i], boxes) > iou_thres # iou matrix
weights = iou * scores[None] # box weights
x[i, :4] = np.multiply(weights, x[:, :4]).float() / weights.sum(1, keepdim=True) # merged boxes
if redundant:
i = i[iou.sum(1) > 1] # require redundancy
output[xi] = x[i]
return output
def clip_boxes(boxes, shape):
# Clip boxes (xyxy) to image shape (height, width)
boxes[..., [0, 2]] = boxes[..., [0, 2]].clip(0, shape[1]) # x1, x2
boxes[..., [1, 3]] = boxes[..., [1, 3]].clip(0, shape[0]) # y1, y2
def scale_boxes(img1_shape, boxes, img0_shape, ratio_pad=None):
# Rescale boxes (xyxy) from img1_shape to img0_shape
if ratio_pad is None: # calculate from img0_shape
gain = min(img1_shape[0] / img0_shape[0], img1_shape[1] / img0_shape[1]) # gain = old / new
pad = (img1_shape[1] - img0_shape[1] * gain) / 2, (img1_shape[0] - img0_shape[0] * gain) / 2 # wh padding
else:
gain = ratio_pad[0][0]
pad = ratio_pad[1]
boxes[..., [0, 2]] -= pad[0] # x padding
boxes[..., [1, 3]] -= pad[1] # y padding
boxes[..., :4] /= gain
clip_boxes(boxes, img0_shape)
return boxes
def draw(image, box_data):
# 取整,方便画框
# -------------------------------------------------------
boxes = box_data[..., :4].astype(np.int32) # x1 x2 y1 y2
scores = box_data[..., 4]
classes = box_data[..., 5].astype(np.int32)
for box, score, cl in zip(boxes, scores, classes):
top, left, right, bottom = box
print('class: {}, score: {}'.format(CLASSES[cl], score))
print('box coordinate left,top,right,down: [{}, {}, {}, {}]'.format(top, left, right, bottom))
cv2.rectangle(image, (top, left), (right, bottom), (255, 0, 0), 2)
cv2.putText(image, '{0} {1:.2f}'.format(CLASSES[cl], score),
(top, left),
cv2.FONT_HERSHEY_SIMPLEX,
0.6, (0, 0, 255), 2)
return image
def main():
onnx_path = "assets\weights\yolov5s.onnx"
img_path = "assets\images\car.jpg"
sess,input_name,output_name = load_onnx(onnx_path)
imgsz = (640, 640)
img = cv2.imread(img_path)
print(img.shape)
# preprocess
im = letterbox(img, new_shape=imgsz, auto=False)[0] # padded resize
im = im.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
im = np.ascontiguousarray(im) # contiguous
im = im.astype(np.float32)
im /= 255 # 0 - 255 to 0.0 - 1.0
if len(im.shape) == 3:
im = np.expand_dims(im, axis=0)
# im = im.reshape(1, 3, 640, 640).astype(np.float32)
pred = onnx_inference(sess,input_name,output_name, im)
# NMS
conf_thres = 0.25 # confidence threshold
iou_thres = 0.45 # NMS IOU threshold
max_det = 1000 # maximum detections per image
classes = None # filter by class: --class 0, or --class 0 2 3
agnostic_nms = False # class-agnostic NMS
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
# Process predictions
seen = 0
for i, det in enumerate(pred): # per image
seen += 1
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_boxes(im.shape[2:], det[:, :4], img.shape).round()
# print(pred)
outputs = pred[0][:, :6]
draw(img,outputs)
cv2.imwrite('assets/outputs/res.jpg', img)
return
if __name__ == "__main__":
main()
yolov8
导出源码
def export_onnx(self, prefix=colorstr('ONNX:')):
"""YOLOv8 ONNX export."""
requirements = ['onnx>=1.12.0']
if self.args.simplify:
requirements += ['onnxsim>=0.4.33', 'onnxruntime-gpu' if torch.cuda.is_available() else 'onnxruntime']
check_requirements(requirements)
import onnx # noqa
opset_version = self.args.opset or get_latest_opset()
LOGGER.info(f'\n{prefix} starting export with onnx {onnx.__version__} opset {opset_version}...')
f = str(self.file.with_suffix('.onnx'))
output_names = ['output0', 'output1'] if isinstance(self.model, SegmentationModel) else ['output0']
dynamic = self.args.dynamic
if dynamic:
dynamic = {'images': {0: 'batch', 2: 'height', 3: 'width'}} # shape(1,3,640,640)
if isinstance(self.model, SegmentationModel):
dynamic['output0'] = {0: 'batch', 2: 'anchors'} # shape(1, 116, 8400)
dynamic['output1'] = {0: 'batch', 2: 'mask_height', 3: 'mask_width'} # shape(1,32,160,160)
elif isinstance(self.model, DetectionModel):
dynamic['output0'] = {0: 'batch', 2: 'anchors'} # shape(1, 84, 8400)
torch.onnx.export(
self.model.cpu() if dynamic else self.model, # dynamic=True only compatible with cpu
self.im.cpu() if dynamic else self.im,
f,
verbose=False,
opset_version=opset_version,
do_constant_folding=True, # WARNING: DNN inference with torch>=1.12 may require do_constant_folding=False
input_names=['images'],
output_names=output_names,
dynamic_axes=dynamic or None)
# Checks
model_onnx = onnx.load(f) # load onnx model
# onnx.checker.check_model(model_onnx) # check onnx model
# Simplify
if self.args.simplify:
try:
import onnxsim
LOGGER.info(f'{prefix} simplifying with onnxsim {onnxsim.__version__}...')
# subprocess.run(f'onnxsim "{f}" "{f}"', shell=True)
model_onnx, check = onnxsim.simplify(model_onnx)
assert check, 'Simplified ONNX model could not be validated'
except Exception as e:
LOGGER.info(f'{prefix} simplifier failure: {e}')
# Metadata
for k, v in self.metadata.items():
meta = model_onnx.metadata_props.add()
meta.key, meta.value = k, str(v)
onnx.save(model_onnx, f)
return f, model_onnx
导出参数
import os
from ultralytics import YOLO
model = YOLO("yolov8s.yaml")
model=YOLO("weights/yolov8s.pt")
#success=model.export(format="onnx")
success=model.export(format="onnx", half=False, dynamic=False, opset=17)
相关参数如下:
Key Value Description
format 'torchscript' format to export to
imgsz 640 image size as scalar or (h, w) list, i.e. (640, 480)
keras False use Keras for TF SavedModel export
optimize False TorchScript: optimize for mobile
half False FP16 quantization
int8 False INT8 quantization
dynamic False ONNX/TF/TensorRT: dynamic axes
simplify False ONNX: simplify model
opset None ONNX: opset version (optional, defaults to latest)
workspace 4 TensorRT: workspace size (GB)
nms False CoreML: add NMS
onnx推理
import onnxruntime
import numpy as np
import cv2
import time
# 调色板
palette = np.array([[255, 128, 0], [255, 153, 51], [255, 178, 102],
[230, 230, 0], [255, 153, 255], [153, 204, 255],
[255, 102, 255], [255, 51, 255], [102, 178, 255],
[51, 153, 255], [255, 153, 153], [255, 102, 102],
[255, 51, 51], [153, 255, 153], [102, 255, 102],
[51, 255, 51], [0, 255, 0], [0, 0, 255], [255, 0, 0],
[255, 255, 255]])
# 17个关键点连接顺序
skeleton = [[16, 14], [14, 12], [17, 15], [15, 13], [12, 13], [6, 12],
[7, 13], [6, 7], [6, 8], [7, 9], [8, 10], [9, 11], [2, 3],
[1, 2], [1, 3], [2, 4], [3, 5], [4, 6], [5, 7]]
# 骨架颜色
pose_limb_color = palette[[9, 9, 9, 9, 7, 7, 7, 0, 0, 0, 0, 0, 16, 16, 16, 16, 16, 16, 16]]
# 关键点颜色
pose_kpt_color = palette[[16, 16, 16, 16, 16, 0, 0, 0, 0, 0, 0, 9, 9, 9, 9, 9, 9]]
def letterbox(im, new_shape=(640, 640), color=(114, 114, 114), scaleup=True):
''' 调整图像大小和两边灰条填充 '''
shape = im.shape[:2]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
# 缩放比例 (new / old)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
# 只进行下采样 因为上采样会让图片模糊
if not scaleup:
r = min(r, 1.0)
# 计算pad长宽
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r)) # 保证缩放后图像比例不变
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
# 在较小边的两侧进行pad, 而不是在一侧pad
dw /= 2
dh /= 2
# 将原图resize到new_unpad(长边相同,比例相同的新图)
if shape[::-1] != new_unpad: # resize
im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR)
# 计算上下两侧的padding
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
# 计算左右两侧的padding
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
# 添加灰条
im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color)
return im
def pre_process(img):
# 归一化 调整通道为(1,3,640,640)
img = img / 255.
img = np.transpose(img, (2, 0, 1))
data = np.expand_dims(img, axis=0)
return data
def xywh2xyxy(x):
''' 中心坐标、w、h ------>>> 左上点,右下点 '''
y = np.copy(x)
y[:, 0] = x[:, 0] - x[:, 2] / 2 # top left x
y[:, 1] = x[:, 1] - x[:, 3] / 2 # top left y
y[:, 2] = x[:, 0] + x[:, 2] / 2 # bottom right x
y[:, 3] = x[:, 1] + x[:, 3] / 2 # bottom right y
return y
# nms算法
def nms(dets, iou_thresh):
# dets: N * M, N是bbox的个数,M的前4位是对应的 左上点,右下点
x1 = dets[:, 0]
y1 = dets[:, 1]
x2 = dets[:, 2]
y2 = dets[:, 3]
scores = dets[:, 4]
areas = (x2 - x1 + 1) * (y2 - y1 + 1) # 求每个bbox的面积
order = scores.argsort()[::-1] # 对分数进行倒排序
keep = [] # 用来保存最后留下来的bboxx下标
while order.size > 0:
i = order[0] # 无条件保留每次迭代中置信度最高的bbox
keep.append(i)
# 计算置信度最高的bbox和其他剩下bbox之间的交叉区域
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
# 计算置信度高的bbox和其他剩下bbox之间交叉区域的面积
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
# 求交叉区域的面积占两者(置信度高的bbox和其他bbox)面积和的必烈
ovr = inter / (areas[i] + areas[order[1:]] - inter)
# 保留ovr小于thresh的bbox,进入下一次迭代。
inds = np.where(ovr <= iou_thresh)[0]
# 因为ovr中的索引不包括order[0]所以要向后移动一位
order = order[inds + 1]
output = []
for i in keep:
output.append(dets[i].tolist())
return np.array(output)
def xyxy2xywh(a):
''' 左上点 右下点 ------>>> 左上点 宽 高 '''
b = np.copy(a)
# y[:, 0] = (x[:, 0] + x[:, 2]) / 2 # x center
# y[:, 1] = (x[:, 1] + x[:, 3]) / 2 # y center
b[:, 2] = a[:, 2] - a[:, 0] # w
b[:, 3] = a[:, 3] - a[:, 1] # h
return b
def scale_boxes(img1_shape, boxes, img0_shape):
''' 将预测的坐标信息转换回原图尺度
:param img1_shape: 缩放后的图像尺度
:param boxes: 预测的box信息
:param img0_shape: 原始图像尺度
'''
# 将检测框(x y w h)从img1_shape(预测图) 缩放到 img0_shape(原图)
gain = min(img1_shape[0] / img0_shape[0], img1_shape[1] / img0_shape[1]) # gain = old / new
pad = (img1_shape[1] - img0_shape[1] * gain) / 2, (img1_shape[0] - img0_shape[0] * gain) / 2 # wh padding
boxes[:, 0] -= pad[0]
boxes[:, 1] -= pad[1]
boxes[:, :4] /= gain # 检测框坐标点还原到原图上
num_kpts = boxes.shape[1] // 3 # 56 // 3 = 18
for kid in range(2,num_kpts+1):
boxes[:, kid * 3-1] = (boxes[:, kid * 3-1] - pad[0]) / gain
boxes[:, kid * 3 ] = (boxes[:, kid * 3 ] - pad[1]) / gain
# boxes[:, 5:] /= gain # 关键点坐标还原到原图上
clip_boxes(boxes, img0_shape)
return boxes
def clip_boxes(boxes, shape):
# 进行一个边界截断,以免溢出
# 并且将检测框的坐标(左上角x,左上角y,宽度,高度)--->>>(左上角x,左上角y,右下角x,右下角y)
top_left_x = boxes[:, 0].clip(0, shape[1])
top_left_y = boxes[:, 1].clip(0, shape[0])
bottom_right_x = (boxes[:, 0] + boxes[:, 2]).clip(0, shape[1])
bottom_right_y = (boxes[:, 1] + boxes[:, 3]).clip(0, shape[0])
boxes[:, 0] = top_left_x #左上
boxes[:, 1] = top_left_y
boxes[:, 2] = bottom_right_x #右下
boxes[:, 3] = bottom_right_y
def plot_skeleton_kpts(im, kpts, steps=3):
num_kpts = len(kpts) // steps # 51 / 3 =17
# 画点
for kid in range(num_kpts):
r, g, b = pose_kpt_color[kid]
x_coord, y_coord = kpts[steps * kid], kpts[steps * kid + 1]
conf = kpts[steps * kid + 2]
if conf > 0.5: # 关键点的置信度必须大于 0.5
cv2.circle(im, (int(x_coord), int(y_coord)), 10, (int(r), int(g), int(b)), -1)
# 画骨架
for sk_id, sk in enumerate(skeleton):
r, g, b = pose_limb_color[sk_id]
pos1 = (int(kpts[(sk[0]-1)*steps]), int(kpts[(sk[0]-1)*steps+1]))
pos2 = (int(kpts[(sk[1]-1)*steps]), int(kpts[(sk[1]-1)*steps+1]))
conf1 = kpts[(sk[0]-1)*steps+2]
conf2 = kpts[(sk[1]-1)*steps+2]
if conf1 >0.5 and conf2 >0.5: # 对于肢体,相连的两个关键点置信度 必须同时大于 0.5
cv2.line(im, pos1, pos2, (int(r), int(g), int(b)), thickness=2)
class Keypoint():
def __init__(self,modelpath):
# self.session = onnxruntime.InferenceSession(modelpath, providers=['CUDAExecutionProvider','CPUExecutionProvider'])
self.session = onnxruntime.InferenceSession(modelpath, providers=['CUDAExecutionProvider'])
self.input_name = self.session.get_inputs()[0].name
self.label_name = self.session.get_outputs()[0].name
def inference(self,image):
img = letterbox(image)
data = pre_process(img)
# 预测输出float32[1, 56, 8400]
pred = self.session.run([self.label_name], {self.input_name: data.astype(np.float32)})[0]
# [56, 8400]
pred = pred[0]
# [8400,56]
pred = np.transpose(pred, (1, 0))
# 置信度阈值过滤
conf = 0.7
pred = pred[pred[:, 4] > conf]
if len(pred) == 0:
print("没有检测到任何关键点")
return image
else:
# 中心宽高转左上点,右下点
bboxs = xywh2xyxy(pred)
# NMS处理
bboxs = nms(bboxs, iou_thresh=0.6)
# 坐标从左上点,右下点 到 左上点,宽,高.
bboxs = np.array(bboxs)
bboxs = xyxy2xywh(bboxs)
# 坐标点还原到原图
bboxs = scale_boxes(img.shape, bboxs, image.shape)
# 画框 画点 画骨架
for box in bboxs:
# 依次为 检测框(左上点,右下点)、置信度、17个关键点
det_bbox, det_scores, kpts = box[0:4], box[4], box[5:]
# 画框
cv2.rectangle(image, (int(det_bbox[0]), int(det_bbox[1])), (int(det_bbox[2]), int(det_bbox[3])),
(0, 0, 255), 2)
# 人体检测置信度
if int(det_bbox[1]) < 30 :
cv2.putText(image, "conf:{:.2f}".format(det_scores), (int(det_bbox[0]) + 5, int(det_bbox[1]) +25),
cv2.FONT_HERSHEY_DUPLEX, 0.8, (0, 0, 255), 1)
else:
cv2.putText(image, "conf:{:.2f}".format(det_scores), (int(det_bbox[0]) + 5, int(det_bbox[1]) - 5),
cv2.FONT_HERSHEY_DUPLEX, 0.8, (0, 0, 255), 1)
# 画点 连线
plot_skeleton_kpts(image, kpts)
return image
if __name__ == '__main__':
modelpath = 'weights/yolov8s-pose.onnx'
# 实例化模型
keydet = Keypoint(modelpath)
# 两种模式 1为图片预测,并显示结果图片;2为摄像头检测,并实时显示FPS
# 输入图片路径
for i in range(10):
image = cv2.imread('assets/person-pose.jpg')
start = time.time()
image = keydet.inference(image)
end = time.time()
det_time = (end - start) * 1000
print("推理时间为:{:.2f} ms".format(det_time))
print("图片完成检测")
cv2.imwrite('runs/res.jpg',image)

