
GLIP:Grounded Language-Image Pre-training
Grounded Language-Image Pre-training
GLIPv1: Grounded Language-Image Pre-training
GLIPv2: Unifying Localization and VL Understanding
代码地址: https://github.com/microsoft/GLIP
论文地址1: https://paperswithcode.com/paper/grounded-language-image-pre-training
论文地址2:https://arxiv.org/abs/2206.05836
翻译1 https://zhuanlan.zhihu.com/p/638842771
简介
CLIP利用image-text对进行训练,从而使得模型可以根据文字prompt识别任意类别。
CLIP适用于分类任务,而GLIP尝试将这一技术应用于目标检测等更加复杂的任务中。
在本文中,提出了phrase grounding的概念,利用指定描述的语句进行标定图片中所显示的物体),属于visual grounding(视觉基础训练)的一种。phrase grounding的任务是输入句子和图片,对于给定的sentence,要定位其中提到的全部物体然后框出来。
标准的 object detection 模型只能推理固定的对象类别,如COCO,而这种人工标注的数据扩展成本很高。GLIP将 object detection 定义为 phrase grounding,可以推广到任何目标检测任务。
CLIP和ALIGN在大规模图像-文本对上进行跨模态对比学习,可以直接进行开放类别的图像分类。GLIP继承了这一研究领域的语义丰富和语言感知的特性,实现了SoTA对象检测性能,并显著提高了对下游检测任务的可迁移能力。
摘要
本文提出了一种基础语言图像预训练(GLIP)模型,用于学习对象级、语言感知和语义丰富的视觉表示。 GLIP 统一了预训练的对象检测和短语基础。这种统一带来了两个好处:1)它允许 GLIP 从检测和接地数据中学习,以改进这两项任务并引导一个良好的接地模型; 2)GLIP可以通过以自我训练的方式生成接地框来利用大量的图像文本对,使学习到的表示具有丰富的语义。在我们的实验中,我们在 2700 万个基础数据上预训练 GLIP,其中包括 300 万个人工注释和 2400 万个网络抓取的图像文本对。学习到的表征展示了对各种对象级识别任务的强大的零样本和少样本可迁移性。 1) 当直接在 COCO 和 LVIS 上进行评估时(在预训练期间没有在 COCO 中看到任何图像),GLIP 分别达到 49.8 AP 和 26.9 AP,超越了许多监督基线。1 2) 在 COCO 上进行微调后,GLIP在 val 上达到 60.8 AP,在 test-dev 上达到 61.5 AP,超过了之前的 SoTA。 3) 当转移到 13 个下游目标检测任务时,1-shot GLIP 可以与完全监督的动态头相媲美。
Introduction
视觉识别模型通常被训练来预测一组固定的预先确定的对象类别,这限制了它们在实际应用中的可用性,因为需要额外的标记数据来概括新的视觉概念和领域。
CLIP模型证明了,可以在大量的原始图像-文本对上有效地学习图像级视觉表示。因为配对文本包含的视觉概念集比任何预定义的概念池都多。预训练的CLIP模型语义丰富,可以很容易地转移到下游的图像分类和文本图像检索任务中。
对于复杂的任务,如目标检测、图像分割、人体姿势估计、场景理解、动作识别、视觉语言理解,要获得对图像的细粒度理解,非常需要object-level的视觉表示。
GLIP模型,采用phrase grounding,即识别句子中的短语与图像中的object(或region)之间的细粒度对应关系的任务。统一了phrase grounding和object detection任务,object detection可以被转换为上下文无关的phrase grounding,而phrase grounding可以被视为置于context背景下的的object detection任务。
1、将object detection 表述成 grounding, 统一了detection与grounding 模型不仅仅接受图像输入,还要描述检测目标的text prompt
2、 结构和CLIP相似,为双编码器结构。在最后一点乘融合时不同。 GLIP采用的是深度跨模态融合
3、使用大量的图像-文本数据扩展,现通过教师模型 自动为大量图像-文本配对数据生成grounding boxes来增强GLIP预训练数据
4、迁移学习:GLIP可以在很少甚至不需要人工注释的情况下转移到各种任务中。
统一的损失函数
其中, 是分类损失,是定位损失, 其中分类损失:图文匹配上的尽可能为1,匹配不上去为0
其中,是输入图像的特征,是二阶段分类头的权重,是输出的分类概率,是一个表示目标匹配结果的数据结构或矩阵
通过模型获取图片特征O,进而通过与权重矩阵W做点积得到S(cls)为输出logit结果,最后再与真实标签及坐标T(NxC)做损失函数进行拟合
grounding模型中的对齐分数
P来自语言编码器的上下文word/token特征其作用类似于权重W矩阵,是图像区域与提示符中的单词之间的对齐分数
对于混合模型,一方面基于视觉模型获取图片特征O,另一方面基于nlp模型获取文本特征P,再将文本特征与图片特征对应的区域做匹配得分S(ground),因为在提示词中,由于有以下多种原因造成模型输出的特征维度大于真实目标维度,使得S(ground)(NxM)的维度大于T(NxC)的维度。M((sub-word tokens数量)总是大于短语数c,原因有四:
- 一个短语总是包含很多单词
- 一个单词可以分成几个子词,比如toothbrush分成了 tooth#, #brush
- 还有一些添加词added tokens,像是“Detect:”,逗号等,或者是语言模型中的特殊token
- tokenized序列末尾会加入token
[NoObj]
V2版本的损失函数
- 与V1的区别,v1的负样本在同一张图片中
- V2 正负样本跨图片进行
- 扩大的数据集
方法
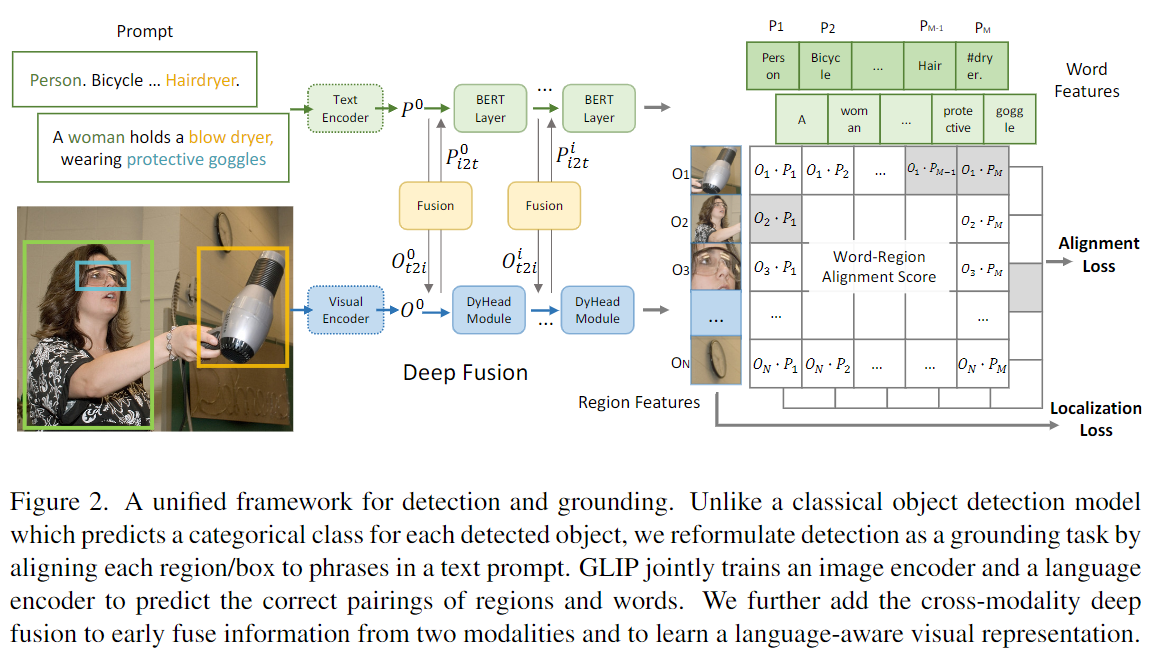
和CLIP双encoder结构,差异是增加了深度跨模态前融合(这个对学习到高质量语言对齐的视觉表征很重要)
引入了“深度融合”deep fusion的概念:区别于前期融合(early fusion)和后期融合(late fusion),深度融合对两个模态的特征向量计算交叉注意力(cross attention),从而让模型可以在较浅的模型阶段就开始进行跨模态的特征学习。
视觉和文本多模态多头注意力融合:
- 文本的 Q K V,视觉Q K V
- 视觉加权求和文本
- 文本加权求和视觉
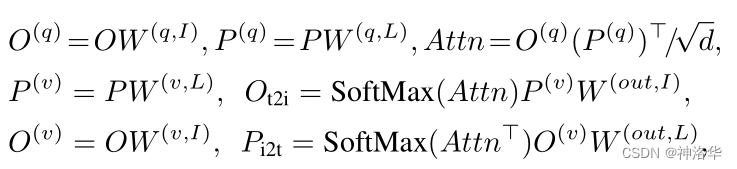
这里直接参考 https://blog.csdn.net/qq_56591814/article/details/127421979
将 object detection 定义为 phrase grounding,并短语连接到一起。
例如,COCO对象检测的文本提示 是一个由80个短语组成的文本字符串,即80个COCO对象类名称,以“.”连接。 如图。任何对象检测模型都可以通过用单词区域对齐分数替换其框分类器中的对象分类逻辑来转换为基础模型,即区域(或框)视觉特征和标记(或短语)的点积)语言特征,。语言特征是使用语言模型计算的,这为新的检测(或基础)模型提供了双编码器结构。与仅在最后点积层融合视觉和语言的 CLIP 不同,我们表明 GLIP 应用的深度跨模态融合,对于学习高质量的语言感知至关重要视觉表示并实现卓越的迁移学习性能。检测和接地的统一还允许我们使用两种类型的数据进行预训练,并且对这两项任务都有好处。在检测方面,由于基础数据,视觉概念池显着丰富。在接地方面,检测数据引入了更多的边界框注释,并帮助训练新的 SoTA 短语接地模型。
总结
-
借鉴CLIP模型,将文本和视觉统一到一个空间,本质是向量匹配,不是目标分类。
-
GLIP 创造性地将目标检测任务转换为短语定位任务。对任意一张训练图片,把标签用句号隔开,拼接成一句话。通过这种方式,所有的目标检测数据集都可转化为短语定位数据集。
-
统一的数据集和数据格式:image+box+prompt,grounding格式数据
-
没有类别概率,扩大了数据集,可以0样本学习。
-
模型结构统一,增加了深度跨模态前融合,使用DyHead作为图像编码器,BERT作为文本编码器,后续进行融合编码。
-
cv混合模型分为两部分,一部分是基于NLP模型对提示词的编码并获取提示词相应的特征(语义信息),这里的提示词可以是单个的英文单词,也可以是一整段话语,NLP模型采用主流的bert。另一部分是采用视觉模型对图片特征的提取,这里的视觉模型采用vit transformer,对图片完成编码后,进而与经过bert模型编码的提示词特征进行多层的特征融合(fusion)
-
Loss 统一,目标检测损失函数。
参考资料
https://zhuanlan.zhihu.com/p/662670305 讲解挺详细
https://zhuanlan.zhihu.com/p/638842771
https://zhuanlan.zhihu.com/p/633352647
https://blog.csdn.net/qq_40629612/article/details/132788499 讲解详细及其训练代码


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理