神经网络梯度爆炸和消失
神经网络梯度爆炸和消失
层数比较多的神经网络模型在训练的时候会出现梯度消失(gradient vanishing problem)和梯度爆炸(gradient exploding problem)问题。梯度消失问题和梯度爆炸问题一般会随着网络层数的增加变得越来越明显。
现象说明
梯度消失:
反向传播过程中需要对激活函数求导。
梯度消失是因为随着网络深度的加深,网络反向传播过,由于导数小于1。经过逐层累积而导致其越靠近输入层,其值越小。
因此靠近输入层的权值更新就会非常缓慢甚至停滞不前,那么网络深度的加深就失去了其意义,网络只等价于后面基层浅层网络的学习。
梯度爆炸:
梯度爆炸一般出现深层网络和权值初始化值太大的情况下。随着网络的深度的加深,由于导数大于1。经过逐层累积,变得非常大,梯度值太大,会导致权值瞬间跳跃,指向不应该指向的位置,导致训练收敛缓慢,甚至陷入局部最小值。
产生原因
梯度消失、梯度爆炸的原因
反向传播 在网络较深时出现梯度累积,激活函数的导数,权重初始化参数过小或过大。
1、神经网络层数过深。隐藏层的层数过多
不同的层学习的速度差异很大,表现为网络中靠近输出的层学习的情况很好,靠近输入的层学习的很慢,有时甚至训练了很久,前几层的权值和刚开始随机初始化的值差不多。因此,梯度消失、爆炸,其根本原因在于在于反向传播算法的不足。多个隐藏层的网络可能比单个隐藏层的更新速度慢了几个个数量级。
2、采用了不合适的激活函数
在反向传播的链式求导过程中,如果权重乘以激活函数导数这部分大于1,随着层数加深时,梯度更新会以指数的形式增加,则会梯度爆炸;如果这部分小于1,随着层数加深,梯度会指数衰减,则会出现梯度消失。
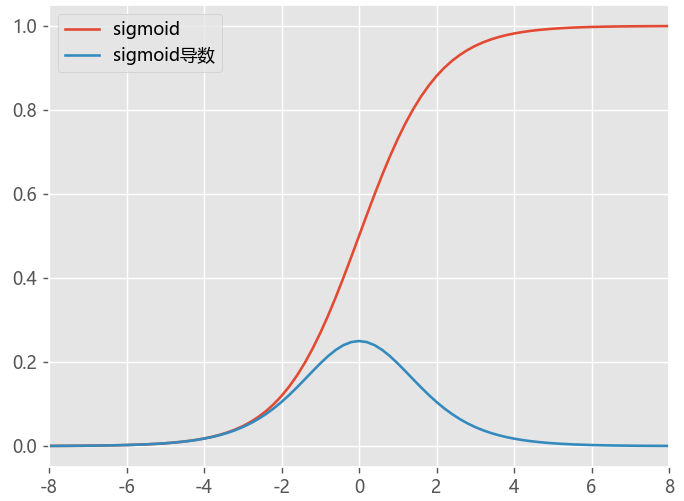
以Sigmoid激活函数
观察Sigmoid函数曲线,可以知道其输出分布在[0,1]区间,而且在输入值较大和较小的情况,其输出值变化都会比较小,仅仅当输入值接近为0时,它们才对输入强烈敏感。sigmoid导数的图像,最大值0.25,如果使用sigmoid作为激活函数,其梯度是不可能超过0.25的,这样经过反向传播的链式求导之后,很容易发生梯度消失。
3、权重的初始化值不合理
权重初始值:一般会使用均值为0方差为1的高斯分布初始化参数,这种方式使得权重集中在-1到1之间,因此很容易出现梯度消失。如果初始化的值很大,就会出现梯度爆炸。
解决方法
梯度消失和梯度爆炸问题都是因为网络太深,网络权值更新不稳定造成的,本质上是因为梯度反向传播中的连乘效应
优化激活函数
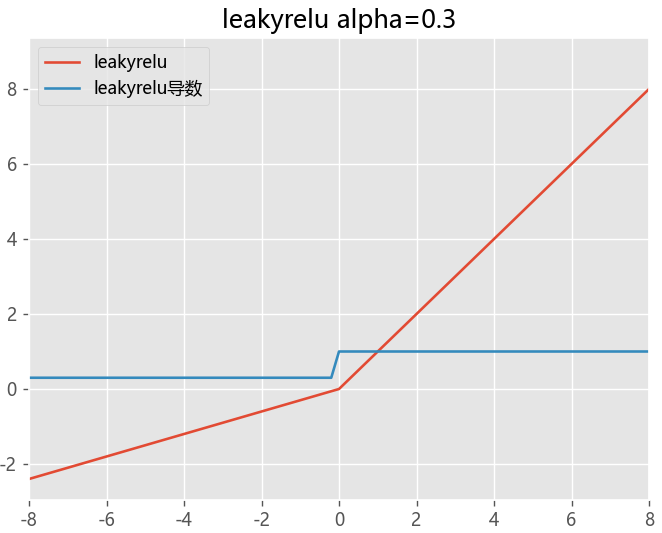
换用 Relu、LeakyRelu、Elu 等激活函数
Relu激活函数,其导数为1,每层网络都尽量获得相同的更新速度。缓解梯度消失和梯度爆炸
权重初始化和正则化
权重初始化
可以采用好的参数初始化方法,比如 He方法,对梯度爆炸和梯度消失都有作用.
具体来说,使得前向传播时,每一层卷积计算结果的方差为1.在反向传播时,每一层向前传的梯度方差为1。
希望初始化后正向传播时,状态值方差保持不变,反向时,关于下一层激活值的梯度方差保持不变。
权重正则化
权重正则化:损失函数中加入网络参数权重的惩罚项
当梯度爆炸发生时,惩罚项(通常是L1范数或L2范数)的值会变得很大,从而抑制(或者反向)参数的更新强度(或者方向)
以此来抑制惩罚项(也可以说是正则化项)的大小,从而在一定程度上限制梯度爆炸的发生。
采用权重正则化主要目的是限制过拟合,但也可以抑制梯度爆炸,比较常见的是L1正则,L2正则;
BN归一化操作
Batch Normalization具有加速网络收敛速度, 升训练稳定性的效果,BN本质上是解决反向传播过程中的梯度问题。
BN全名是Batch Normalization,简称BN,即批规范化,通过规范化操作将输出信号x规范化保证网络的稳定性。
反向传播式子中有w的存在,所以w的大小影响了梯度的消失和爆炸,BN就是通过对每一层的输出规范为均值和方差一致的方法,消除了w带来的放大缩小的影响,进而解决梯度消失和爆炸的问题,或者可以理解为BN将输出从饱和区拉倒了非饱和区。
- Batch Normalization作用
(1)允许较大的学习率
(2)减弱对初始化的强依赖性
(3)保持隐藏层中数值的均值、方差不变,让数值更稳定,为后面网络提供坚实的基础
(4)有轻微的正则化作用(相当于给隐藏层加入噪声,类似Dropout)
使用残差结构
残差可以很轻松的构建几百层,一千多层的网络而不用担心梯度消失过快的问题,原因就在于残差的捷径(shortcut)部分
从正向来看,残差连接将浅层特征共享到深层网络中,有利于整体神经网络特征的稳定性;
从反向来看,引入深层反向的短梯度,有效地保留了更新的效果(避免梯度消失。)
详解残差网络:https://zhuanlan.zhihu.com/p/42706477
梯度裁剪
梯度裁剪解决梯度爆炸的一种高效的方法,
梯度裁剪设置一个梯度剪切阈值,将梯度强制限制在范围内。
如果更新梯度时,梯度超过了这个阈值,则利用上界将梯度限制在正常范围内
简单理解就是当其小于C时不变;当其大于C时,进行裁剪。
预训练+微调
本质上是优化权重初始化的过程
逐层训练
boosting的实现思想,通过单层单层的训练来达到不考虑梯度累计
参考资料
https://blog.csdn.net/weixin_39910711/article/details/114849349 相关现象和解释
https://zhuanlan.zhihu.com/p/483651927
https://juejin.cn/post/6857811313809162254?searchId=202311121617012F828693E829A87C46A4

 浙公网安备 33010602011771号
浙公网安备 33010602011771号