
SAM-FastSAM-MobileSAM
SAM-FastSAM-MobileSAM
SAM:
构建了一个大型分割数据集,包含 1100w 图像10 亿 masks
模型结构上,包含三个部分图像编码器,灵活的提示编码器和快速的掩码解码器。建立在Transformer视觉模型之上。
image encoder 采用 VITDet 中的 backbone,它是一个经过 MAE 初始化的 VIT-H/16
prompt encoder 包含三种方式, point prompt,box prompt,text prompt

FastSAM:
整个FastSAM分为两部分:全景分割和提示分割
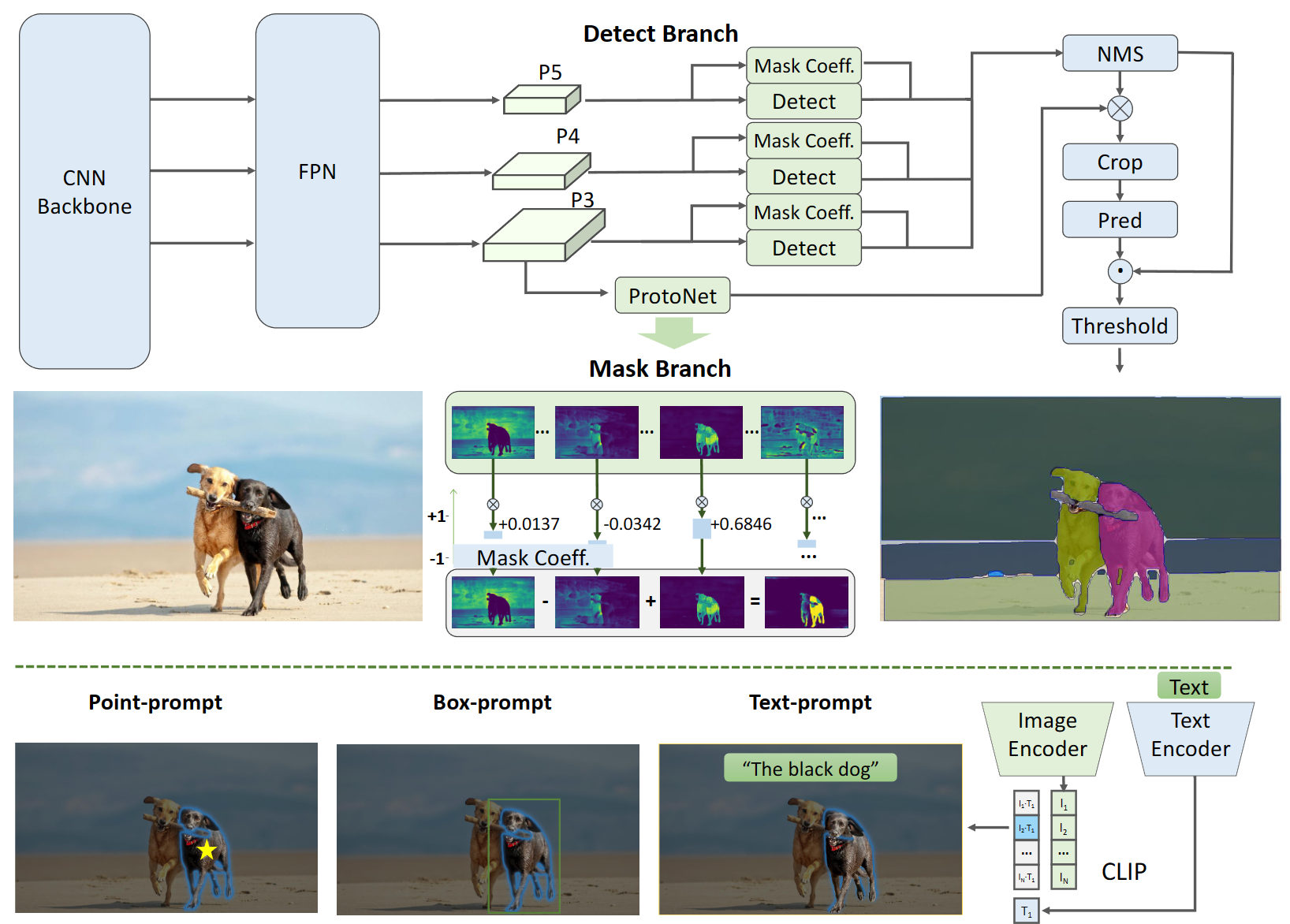
全景分割的模型是基于YOLOv8-seg,YOLOv8-Seg非常适用于分割任何物体的任务,该任务旨在准确检测和分割图像中的每个对象或区域,而不考虑对象的类别。直接使用YOLOv8-seg方法进行全实例分割阶段。
提示分割
点提示:通过使用一组前景/背景点,在感兴趣区域内选择多个掩码。这些掩码将合并为一个单独的掩码,并利用形态学操作来改善掩码合并的性能。
提示框提示:所选框和来自第一阶段的各种掩码对应的边界框之间进行交并比(IoU)匹配。确定与所选框具有最高IoU得分的掩码,并选择感兴趣的对象。
文本提示: 也是基于CLIP做的。
实现了利用 1/50 of SA-1B 的数据达到了与 SAM 相似的性能,且速度比 SAM 快 50 倍。
MobileSAM
核心是将 SAM 的 VIT-H 蒸馏到一个更轻量的 image encoder 中
提出一种"解耦蒸馏"方案对SAM的ViT-H解码器进行蒸馏,同时所得轻量级编码器可与SAM的解码器 无缝兼容,主要困难在于: Encoder与Decoder的耦合优化,两者存在互依赖,本质上将整个知识蒸馏过程拆解为Encoder蒸馏+Decoder微调,该方案称之为半耦合蒸馏(Semi-coupled Distillation)
将默认的图像编码器ViT-H的知识蒸馏到一个小型ViT模型中,之后可以微调原始SAM中的分割掩码解码器,使其与蒸馏后的图像编码器更好地对齐。
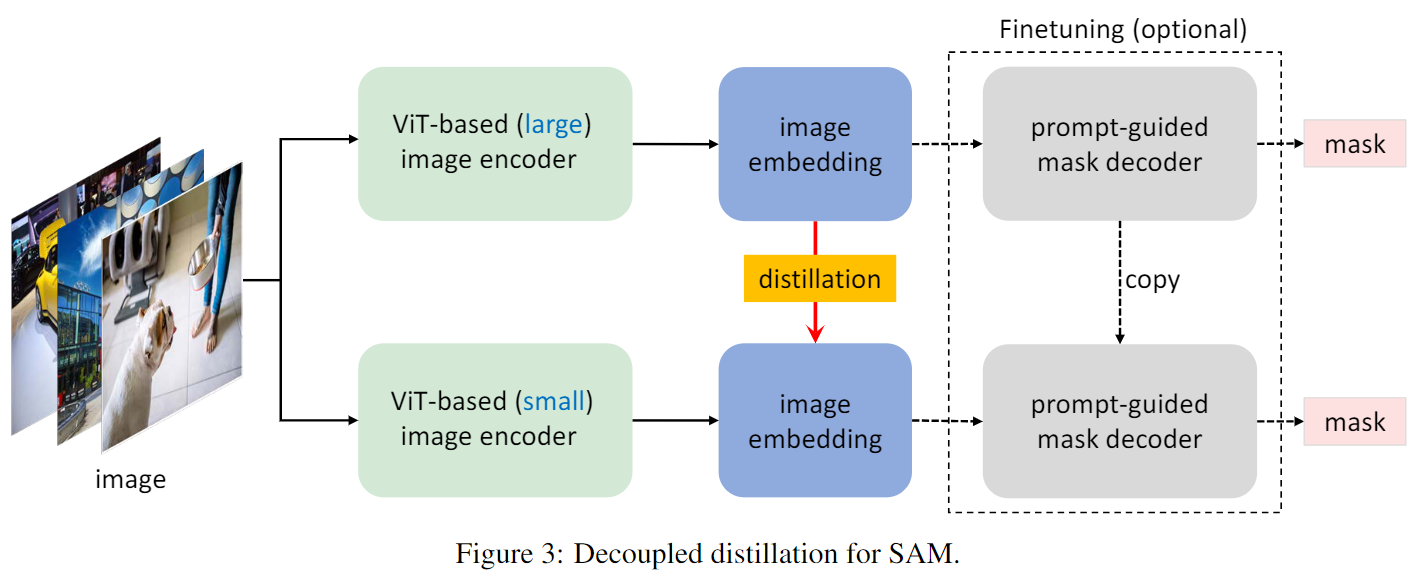
Mobile SAM 就是通过蒸馏将原来的 VIT-H 蒸馏成了一个VIT-T,使用了单张 3090 再SA-1B 的 1%的数据上训练了 8 epochs,达到了与 SAM 相似的分割效果。
Mobile SAM 同样不支持 text prompt。
在与 SAM 效果相似的情况下推理速度比 SAM 快 60 倍,模型大小比 Fast SAM 小 7 倍,推理速度比 Fast SAM 快 4 倍。
根据mobilesam论文
分别对比vit-h,fastsam,mobilesam在图片所有实例分割的结果,如下图所示,mobilesam和原生的vit-h更接近,优于fastsam,fastsam有些物体检测不到,且边界不够平滑。

参考资料
https://zhuanlan.zhihu.com/p/641169810 (建议学习,详细的要多)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律