yolox 主体结构
yolox 主体结构-Darknet53
概要:
详细解读可参考:https://jishuin.proginn.com/p/763bfbd628ce
源码对应的文件是yolo_fpn中类YOLOFPN 该模型结构中没有 Focus 结构
除此之外还有一个文件模型 yolo_pafpn 中的 YOLOPAFPN 包含是一个 CSPDarknet 的模型结构
Yolox-Darknet53整体的改进思路
在Yolov3_spp结构,并添加一些常用的改进方式
- 基准模型:Yolov3_spp
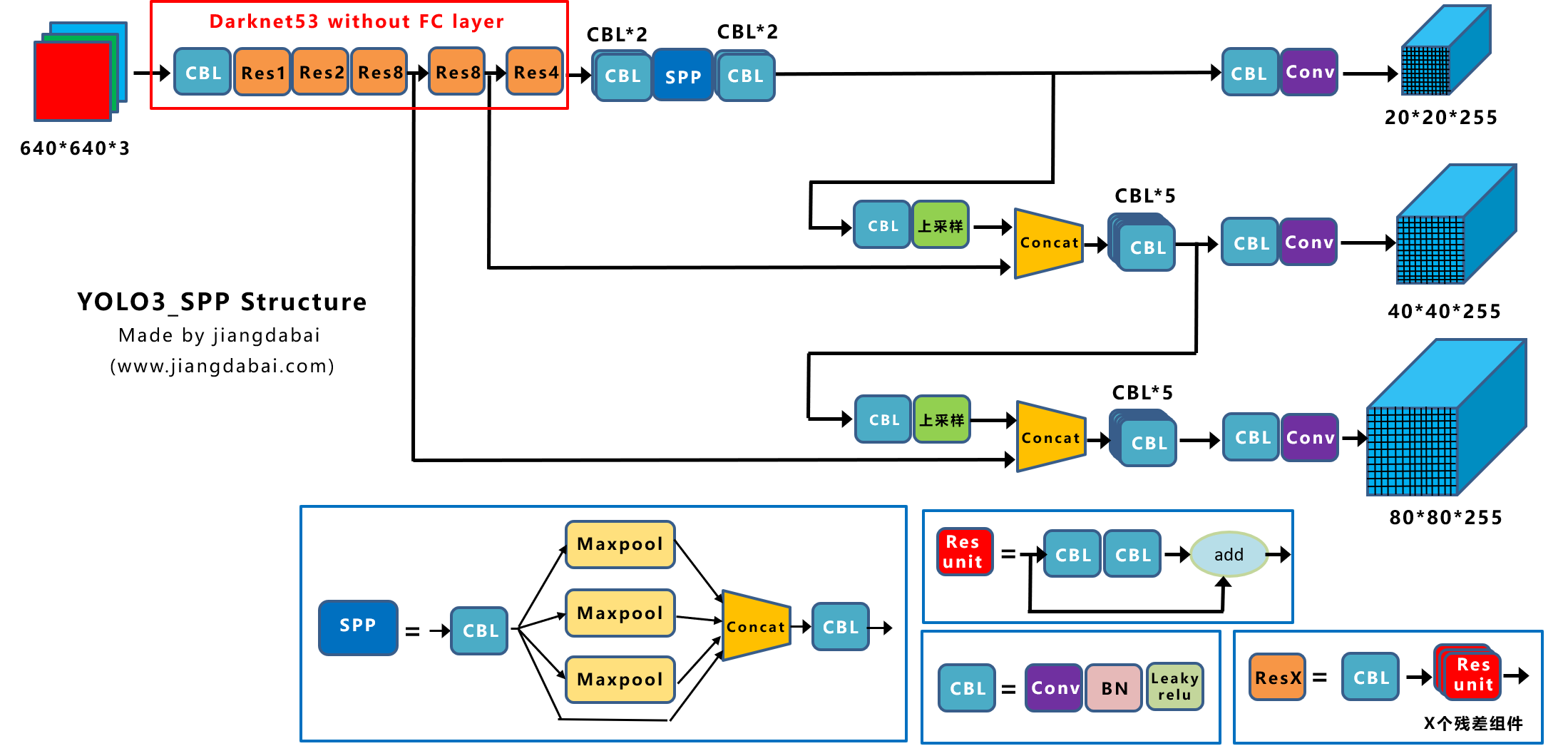
- Yolox模型结构,并添加一些常用的改进方式
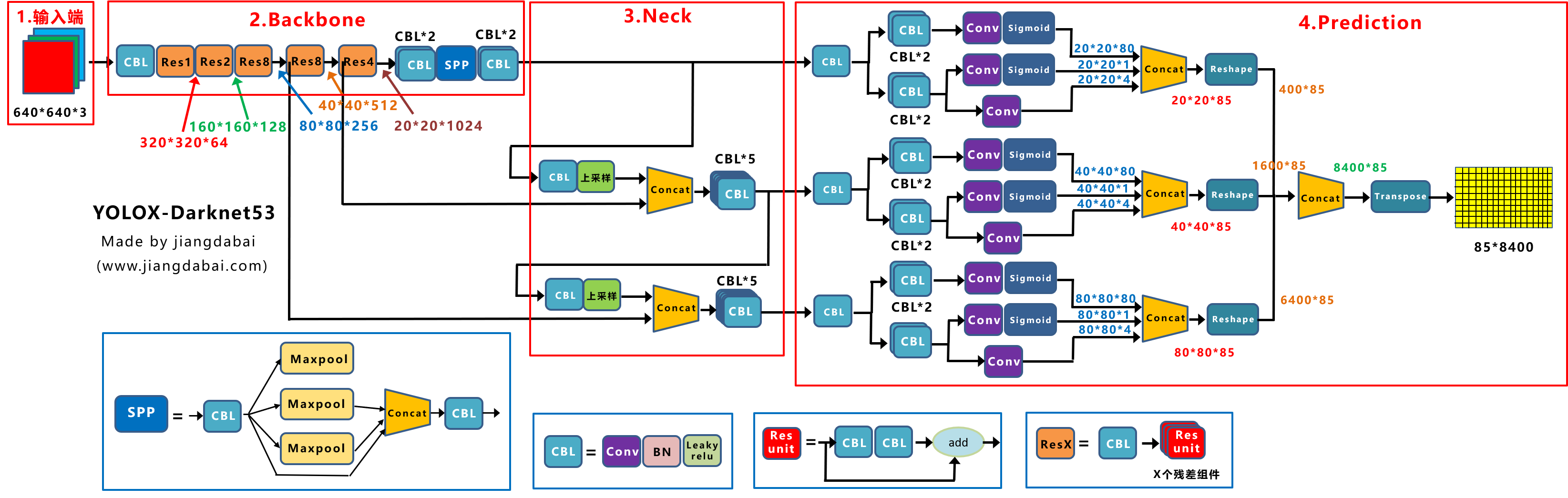
本文只介绍backbone模块
- 该模型结构中没有
Focus结构
backbone模块
主网络为Darknet21 或者 Darknet53
参考文献:https://blog.csdn.net/jizhidexiaoming/article/details/119760198
激活函数
代码位置:network_blocks.py
def get_activation(name="silu", inplace=True):
if name == "silu":
module = nn.SiLU(inplace=inplace)
elif name == "relu":
module = nn.ReLU(inplace=inplace)
elif name == "lrelu":
module = nn.LeakyReLU(0.1, inplace=inplace)
else:
raise AttributeError("Unsupported act type: {}".format(name))
return module
CBL模块
代码位置:network_blocks.py
即Conv + BN + LeakyReLU的缩写,在BaseConv中实现。
不改变特征图的HW。图像大小不变,图像深度变化
- Conv
- BN
- LeakyReLU
class BaseConv(nn.Module):
"""A Conv2d -> Batchnorm -> silu/leaky relu block"""
def __init__(
self, in_channels, out_channels, ksize, stride, groups=1, bias=False, act="silu"):
super().__init__()
# same padding
pad = (ksize - 1) // 2
self.conv = nn.Conv2d(
in_channels,
out_channels,
kernel_size=ksize,
stride=stride,
padding=pad,
groups=groups,
bias=bias,
)
self.bn = nn.BatchNorm2d(out_channels)
self.act = get_activation(act, inplace=True)
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
ResUnit单个残差块
代码位置:network_blocks.py
典型的沙漏型残差块,通道数2C -> C -> 2C
在类ResLayer中实现,不改变特征图的CHW。图像深度不变
- 先用1x1的卷积,将通道减半;
- 然后接个BaseConv,将通道数复原,得到一个结果;
- 把上面的结果和输入相加conCat,即可。
class ResLayer(nn.Module):
"Residual layer with `in_channels` inputs."
def __init__(self, in_channels: int):
super().__init__()
mid_channels = in_channels // 2
self.layer1 = BaseConv(
in_channels, mid_channels, ksize=1, stride=1, act="lrelu")
self.layer2 = BaseConv(
mid_channels, in_channels, ksize=3, stride=1, act="lrelu")
def forward(self, x):
out = self.layer2(self.layer1(x))
out = x + out
return out
Resx模块
代码位置:darknet.py
多个残差块组成。残差块的个数分别是1,2,8,8,4。后面5个模块都可以作为输出层。这里是后面三个作为输出层。
实现上,这里把Darknet53分成了5部分,如下。
Res1,Res2,Res8,Res8,Res4
通用组件
## num_blocks 为残差重复的次数
## depth2blocks = {21: [1, 2, 2, 1], 53: [2, 8, 8, 4]}
## Darknet21 重复的次数分别为[1,2,2,1,]
## Darknet53 重复的次数分别为[2,8,8,4,]
def make_group_layer(self, in_channels: int, num_blocks: int, stride: int = 1):
"starts with conv layer then has `num_blocks` `ResLayer`"
return [
BaseConv(in_channels, in_channels * 2, ksize=3, stride=stride, act="lrelu"),
*[(ResLayer(in_channels * 2)) for _ in range(num_blocks)],
]
核心 Resx
# Darknet 类中
def forward(self, x):
outputs = {}
x = self.stem(x)
outputs["stem"] = x
x = self.dark2(x)
outputs["dark2"] = x
x = self.dark3(x)
outputs["dark3"] = x
x = self.dark4(x)
outputs["dark4"] = x
x = self.dark5(x)
outputs["dark5"] = x
return {k: v for k, v in outputs.items() if k in self.out_features}
self.stem(x
self.stem(x) 包含两个部分 CBL , Res1
self.stem = nn.Sequential(
BaseConv(in_channels, stem_out_channels, ksize=3, stride=1, act="lrelu"),
*self.make_group_layer(stem_out_channels, num_blocks=1, stride=2),)
self.dark2
self.dark2 包含了 Res2
self.dark2 包含了 Res2
num_blocks = Darknet.depth2blocks[depth]
self.dark2 = nn.Sequential(
*self.make_group_layer(in_channels, num_blocks[0], stride=2),)
self.dark3
self.dark3 包含了 Res3 的部分
self.dark4 包含了 Res4 的部分
in_channels *= 2 # 128
self.dark3 = nn.Sequential(
*self.make_group_layer(in_channels, num_blocks[1], stride=2))
in_channels *= 2 # 256
self.dark4 = nn.Sequential(
*self.make_group_layer(in_channels, num_blocks[2], stride=2))
self.dark4
self.dark4 包含了 Res4, 2 * CBL+SPP+2 * CBL.
in_channels *= 2 # 512
self.dark5 = nn.Sequential(
*self.make_group_layer(in_channels, num_blocks[3], stride=2),
*self.make_spp_block([in_channels, in_channels * 2], in_channels * 2),
)
# spp 的实现
def make_spp_block(self, filters_list, in_filters):
m = nn.Sequential(
*[
BaseConv(in_filters, filters_list[0], 1, stride=1, act="lrelu"),
BaseConv(filters_list[0], filters_list[1], 3, stride=1, act="lrelu"),
SPPBottleneck(
in_channels=filters_list[1],
out_channels=filters_list[0],
activation="lrelu",
),
BaseConv(filters_list[0], filters_list[1], 3, stride=1, act="lrelu"),
BaseConv(filters_list[1], filters_list[0], 1, stride=1, act="lrelu"),
]
)
return m
SPPBottleneck 模块
代码位置:network_blocks.py
给定三种尺度的最大池化(5,9,13),核心的函数nn.MaxPool2d。
class SPPBottleneck(nn.Module):
"""Spatial pyramid pooling layer used in YOLOv3-SPP"""
def __init__(
self, in_channels, out_channels, kernel_sizes=(5, 9, 13), activation="silu"
):
super().__init__()
hidden_channels = in_channels // 2
self.conv1 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=activation)
self.m = nn.ModuleList(
[
nn.MaxPool2d(kernel_size=ks, stride=1, padding=ks // 2)
for ks in kernel_sizes
]
)
conv2_channels = hidden_channels * (len(kernel_sizes) + 1)
self.conv2 = BaseConv(conv2_channels, out_channels, 1, stride=1, act=activation)
def forward(self, x):
x = self.conv1(x)
x = torch.cat([x] + [m(x) for m in self.m], dim=1)
x = self.conv2(x)
return x
Neck模块
在Neck结构中,Yolox-Darknet53和Yolov3 baseline的Neck结构,也是一样的,都是采用FPN的结构进行融合。
FPN自顶向下,将高层的特征信息,通过上采样的方式进行传递融合,得到进行预测的特征图。

代码位置: yolox/models/yolo_fpn.py
self.in_features=["dark3", "dark4", "dark5"],
self.backbone = Darknet(depth)
def forward(self, inputs):
"""
Args:
inputs (Tensor): input image.
Returns:
Tuple[Tensor]: FPN output features..
"""
# 先经过 backbone 获得图像特征
out_features = self.backbone(inputs)
# 获得指定层的图像特征 ["dark3", "dark4", "dark5"]
x2, x1, x0 = [out_features[f] for f in self.in_features]
# 最内层 dark5和dark4合并
# yolo branch 1
x1_in = self.out1_cbl(x0)
x1_in = self.upsample(x1_in)
x1_in = torch.cat([x1_in, x1], 1)
out_dark4 = self.out1(x1_in)
# 中间层 dark4和dark3合并
# yolo branch 2
x2_in = self.out2_cbl(out_dark4)
x2_in = self.upsample(x2_in)
x2_in = torch.cat([x2_in, x2], 1)
out_dark3 = self.out2(x2_in)
# 最外层 dark3,dark4,dark5合并
outputs = (out_dark3, out_dark4, x0)
return outputs
细节问题
self.out1_cbl = self._make_cbl(512, 256, 1)
self.out1 = self._make_embedding([256, 512], 512 + 256)
# out 2
self.out2_cbl = self._make_cbl(256, 128, 1)
self.out2 = self._make_embedding([128, 256], 256 + 128)
# upsample
self.upsample = nn.Upsample(scale_factor=2, mode="nearest")
def _make_cbl(self, _in, _out, ks):
return BaseConv(_in, _out, ks, stride=1, act="lrelu")
def _make_embedding(self, filters_list, in_filters):
m = nn.Sequential(
*[
self._make_cbl(in_filters, filters_list[0], 1),
self._make_cbl(filters_list[0], filters_list[1], 3),
self._make_cbl(filters_list[1], filters_list[0], 1),
self._make_cbl(filters_list[0], filters_list[1], 3),
self._make_cbl(filters_list[1], filters_list[0], 1),
]
)
return m
