sql计算连带率时的踩坑经历
反思与总结:
- 多找角度去核对数据,保证最后结果的准确性
- 当结果不符合真实意思表示时:
- 首先,一定要明确,正确的结果应该是什么,即必须找到一个参照物
- 其次,从粗颗粒度往下或者最细颗粒度往上,定位是哪个维度出现了偏差
- 最后,划定一个较小的数据条目范围,可视化增加某逻辑前后的变化情况
业务背景:
某客户想了解旗下各品类对其他品类的连带率,比如某一个品类A的订单量是100,其中既有品类A又有品类X的订单是50个,那么A对X的连带率是50%。
客户提供过来的基础数据中,有很多维度比如城市、商圈、大仓等,但订单量和共同订单量这两个指标的主键是这几个:

客户的目的是品类之间的连带情况,因此,需要group by 日期、品类1 和品类2去做品类1订单和共同订单的sum聚合,理想的输出形式应该是👇🏻
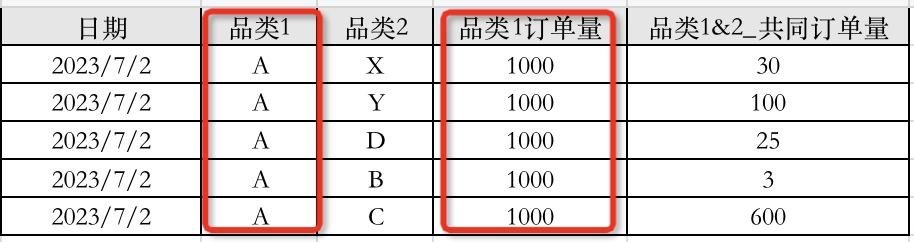
即日期一致的情况下,所有品类1相同的条目中,"品类1订单量"字段应该是相等的(因为这些条目都表示某日某品类的订单量)。
但具体实施后发现并非如此,即出现了下面这种情况:
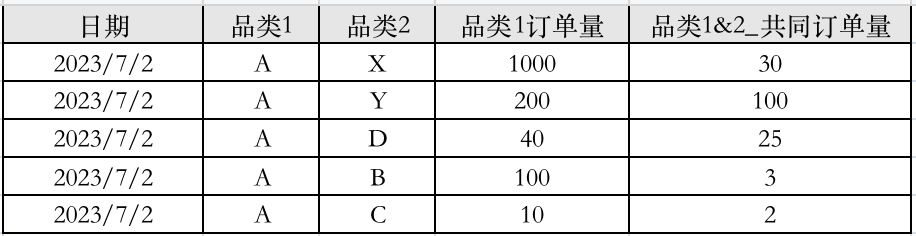
上面的数据,7月2号,A品类的订单量理应是相等的数值,但却出现了不一样的情况。
经过排查后发现:
客户提供的数据,没有问题。但是,在计算连带率时,需要做一个数据填充的步骤(思想类似于做lag之前必须保证时间序列是完整的)。
该场景下,数据填充,填充的是什么呢?
-- 是缺失的维度
举个例子:
这是不做填充时的基础数据和sum之后的:
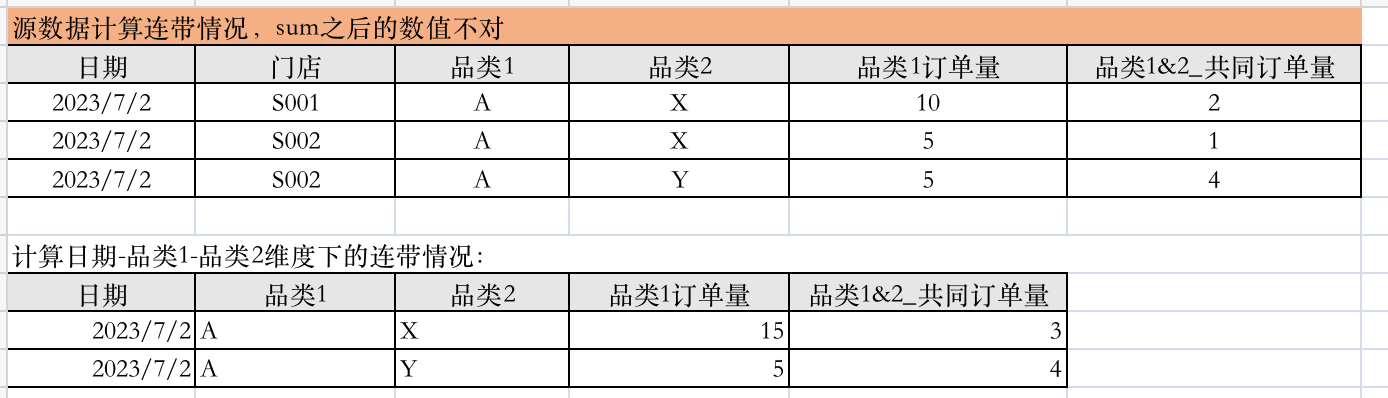
有没有发现,2023年7月2号,S001门店卖了10笔品类A的订单,S002门店卖了5笔品类A的订单,其实2号这一天A的订单量应该是15,而SUM之后的表中,A和Y维度下品类A的订单量是5。
最主要的原因是:S001门店漏了一条维度是A-Y的数据,尽管当天A-Y连带品类的订单量是0.
正确的填充后,数据是这样的:
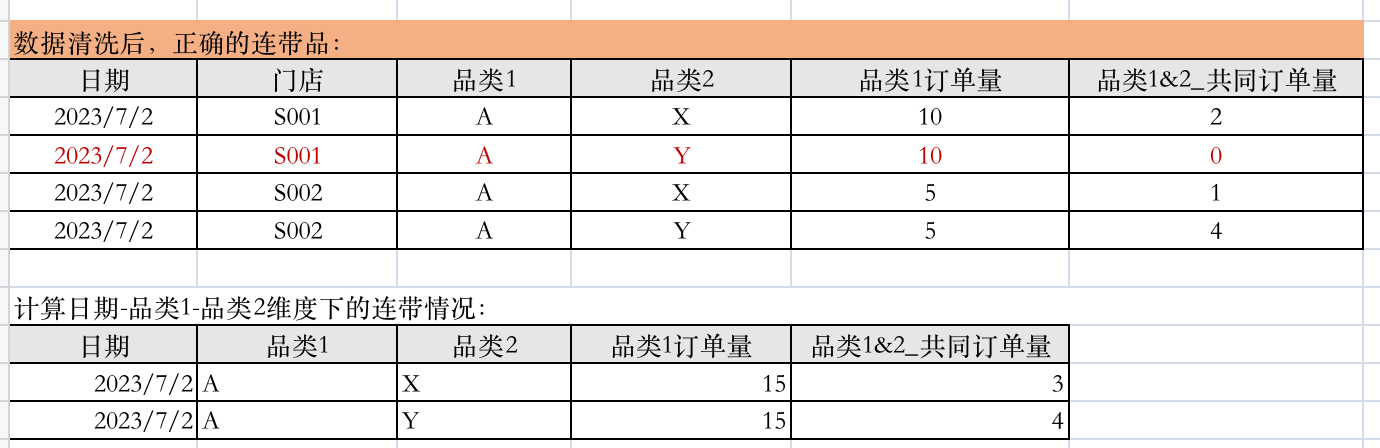
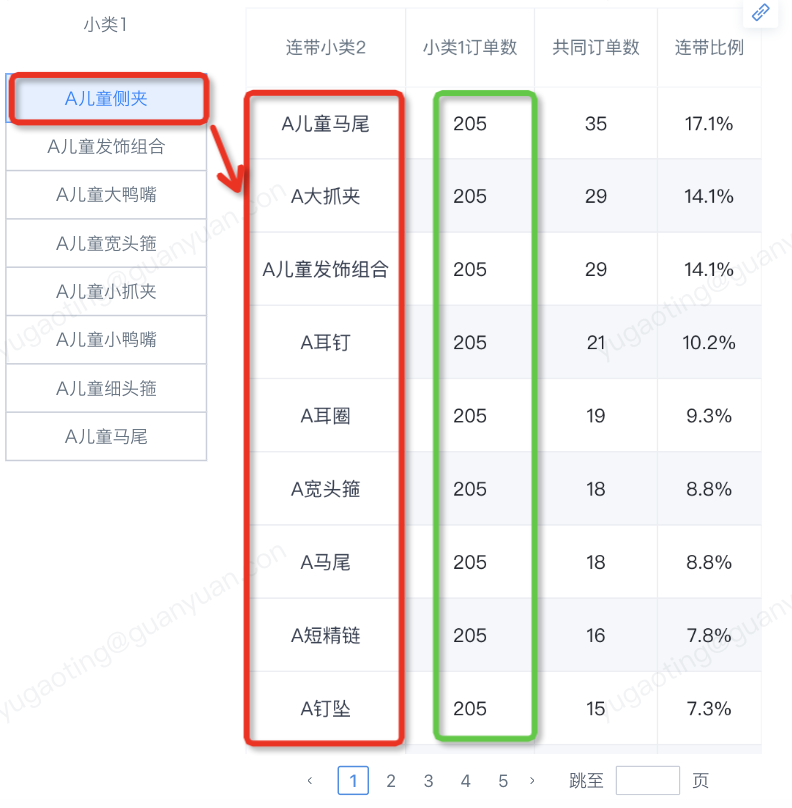
客户数据实施完的效果: