大数据体系名词了解
Flume 是一个分布式、可靠、和高可用的海量日志采集、聚和和传输的系统。可以理解为一个Agent,分为 source、channel、sink 三部分,将 数据源 通过 管道 下沉到 目的地。
Kafka 是一个分布式事件流平台,用于数据 采集 与 下沉 之间的缓冲,是基于 发布/订阅 的 消息队列,可以实现缓冲、消峰、解耦、异步通信...
Flink 是一个 框架 和 分布式 处理引擎,对标spark。spark做的是批处理,Flink做的的是流处理。
-
Source部分 数据获取:
- 厂区发货中心数据、厂区数据库
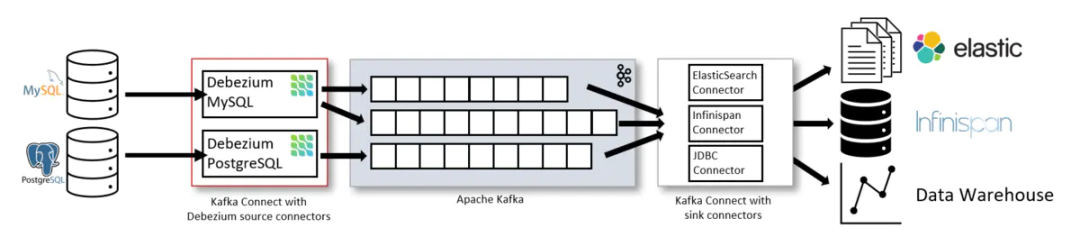
- FlinkCDC(Change Data Capture 变更数据获取, 数据准实时复制 )
是一个可以直接__从__MySQL、PostgreSQL等__数据库__直接__读取全量__数据和__增量变更__数据的 source 组件。
工作原理:监测捕获__数据库的变动(包括数据 或 数据表的__插入INSERT、更新UPDATE、删除DELETE 等),将这些变更 按 发生的 顺序 完整 记录 下来,__写入到消息中间件中__以供其他服务进行订阅及消费。
- 总部库存中心数据
- Canal
基于 MySQL 数据库 增量日志 解析,提供增量数据订阅和消费 。可理解为__仅同步无操作__。
工作原理:将自己伪装成 MySQL slave 获取日志,解析后再存储至下一环节。
- Canal
- 总部销售数据
- Debezium
支持多__数据源,需要kafka connect依赖,构建在kafka上,提供Kafka连接器监视特定的数据库管理。可将现有的数据库转换为事件流、查看并立即响应数据库中的每个行级更改。可理解为__同步且可操作。一样是通过__抽取数据库日志__来获取变更。与Canal相比功能强大但较为复杂。
- Debezium
- 物联网数据
- 集团数据
- RabbitMQ(MQ == 消息队列)
实现了高级消息队列协议, 是一个面向消息的中间件。用途是在消息传输过程中保存消息的容器 。
-
Channel部分 数据缓冲:
-
Kafka(消息总线)
是一个分布式事件流平台,用于数据 采集 与 下沉 之间的 中间件 ,是基于 发布/订阅 的 消息队列。
应用场景:实现消息的__缓冲__、消峰、解耦、异步通信...
可以想象成微信公众号平台,将发布者发布的各种信息整合分类存储,发送给有需要的订阅者。
-
FlinkETL (物理机更新)
Flink对 数据流 做流处理。类似Spark,Flink也是一个计算框架。
应用场景:包括事件驱动型应用、数据分析应用和数据流水线应用。
基于Flink的ETL(数据抽取、转换、加载)可以将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据。
-
Flume
分布式、可靠、和高可用的海量日志采集、聚和和传输的系统。可以理解为一个Agent,将 数据源 通过 管道 下沉到 目的地。架构中各个组件可以动态配置,而无须启停服务。
应用场景:需要可靠、高效的传输的Hadoop系统中。
-
-
Sink部分 数据下沉:
- CDH(一个大数据平台,数据中心管理工具)
提供开箱即用的企业使用所需的一切。通过将Hadoop与十几个其他关键的开源项目集成,Cloudera创建了一个功能先进的系统,可帮助您执行端到端的大数据工作流程。
简单来说:CDH 是一个拥有集群自动化安装、中心化管理、集群监控、报警功能的一个工具(软件),使得集群的安装可以从几天的时间缩短为几个小时,运维人数也会从数十人降低到几个人,极大的提高了集群管理的效率。
-
Mysql (物理机更新)
传统关系型数据库。
-
Redis
key-value__类型的__NOSQL__数据库,数据大小受到内存限制、读写快速、支持类型丰富、异步复制可能丢失数据。与Hbase较为相似,应用场景常用作__缓存。
-
Hive (物理机更新)
本身并非数据库,只是基于Hadoop的数仓工具,将结构化的数据文件映射为一张数据库表,存储在关系型数据库中,并提供类SQL查询功能。
工作原理: 将结构化的数据文件映射为一张数据库表,能__将SQL语句转变成MapReduce任务__来执行。通过类SQL语句实现快速MapReduce统计,使MapReduce编程变得更加简单易行。
应用场景:建立在Hadoop上,可以看HDFS中的数据,作为Hadoop的一个__数仓管理工具__。
-
MinIO (物理机更新)
应用场景:主要应用在__微服务系统__中的__分布式文件系统__(管理的资源可能只通过网络相连),是开源的高可用分部署对象存储服务组件。极简高性能__对象存储__(可以快速存储/读取大容量的非结构化数据 ),高性能基础架构。
特点:轻量、高性能、可扩容、云原生、Amazon S3兼容、可对接后端存储、SDK支持、Lambda计算。
-
KUDU
中和 HDFS无法实时动态读取数据 与 Hbase批量读取性能差的折中产物,架构原理上结合了HDFS与Hbase的特性。
应用场景:高写入吞吐、能快速查询返回明细数据的存储引擎。
-
MDM(主数据管理平台)
用于对主数据的集中管控、监控分析、共享服务。
-
实时/离线计算部分:
-
DataWorks (数据工场,原大数据开发套件)
是一个基于MaxCompute计算引擎的__一站式开发工场__。可以对数据进行传输、转换和集成等操作,从不同的数据存储引入数据,并进行转化和开发,最后将处理好的数据同步至其它数据系统。
应该是个Kettle一样的IDE
-
MaxCompute
适用于数据分析场景的企业级SaaS(软件即服务)模式云__数据仓库__,服务于批量结构化数据的存储和计算,可以提供海量数据仓库的解决方案以及针对大数据的分析建模服务。
-
Presto
分布式SQL查询引擎,适用于交互式分析查询。支持跨数据源的级联查询。
特点:支持多源数据、大数据,低延迟高并发、
应用场景:需要实时查询的工具上、ETL中、实时数据流分析,MPP(大规模并行处理)
-
Flink 实时计算 (物理机更新)
基于计算框架Flink对数据流进行实时计算。
应用场景:包括事件驱动型应用、数据分析应用和数据流水线应用。
-
-
OLAP(联机分析处理)
-
Hologres
__实时数仓__产品。支持海量数据实时写入、实时更新、实时分析,支持标准SQL。支持PB级数据多维分析(OLAP)与即席分析(Ad Hoc),支持高并发低延迟的在线数据服务(Serving),与MaxCompute、Flink、DataWorks深度融合,提供企业级离在线一体化全栈数仓解决方案。
-
Doris
__数据分析__产品。仅需亚秒级响应时间即可获得查询结果,有效地支持实时数据分析。分布式架构非常简洁,易于运维。
-
-
数据应用部分:
ADS层,提供给:实时大屏、数据应用、报表、数据服务、FineBI。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号