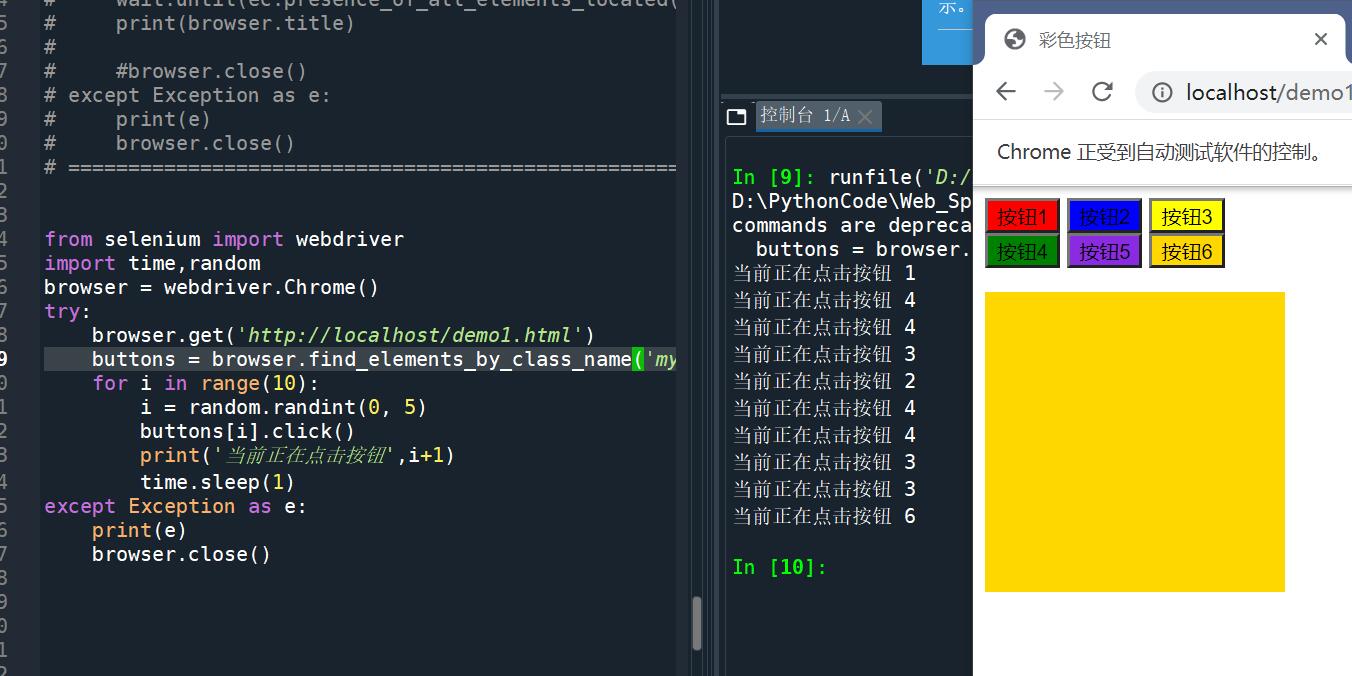
节点互动案例代码和运行结果截图
from selenium import webdriver
import time,random
# 设置浏览器隐藏
# option = webdriver.ChromeOptions()
# option.add_argument("--headless")
browser = webdriver.Chrome()
try:
browser.get('http://localhost/demo1.html')
buttons = browser.find_elements_by_class_name('mybutton')
for i in range(10):
i = random.randint(0, 5)
buttons[i].click()
print('当前正在点击按钮',i+1)
time.sleep(1)
except Exception as e:
print(e)
browser.close()
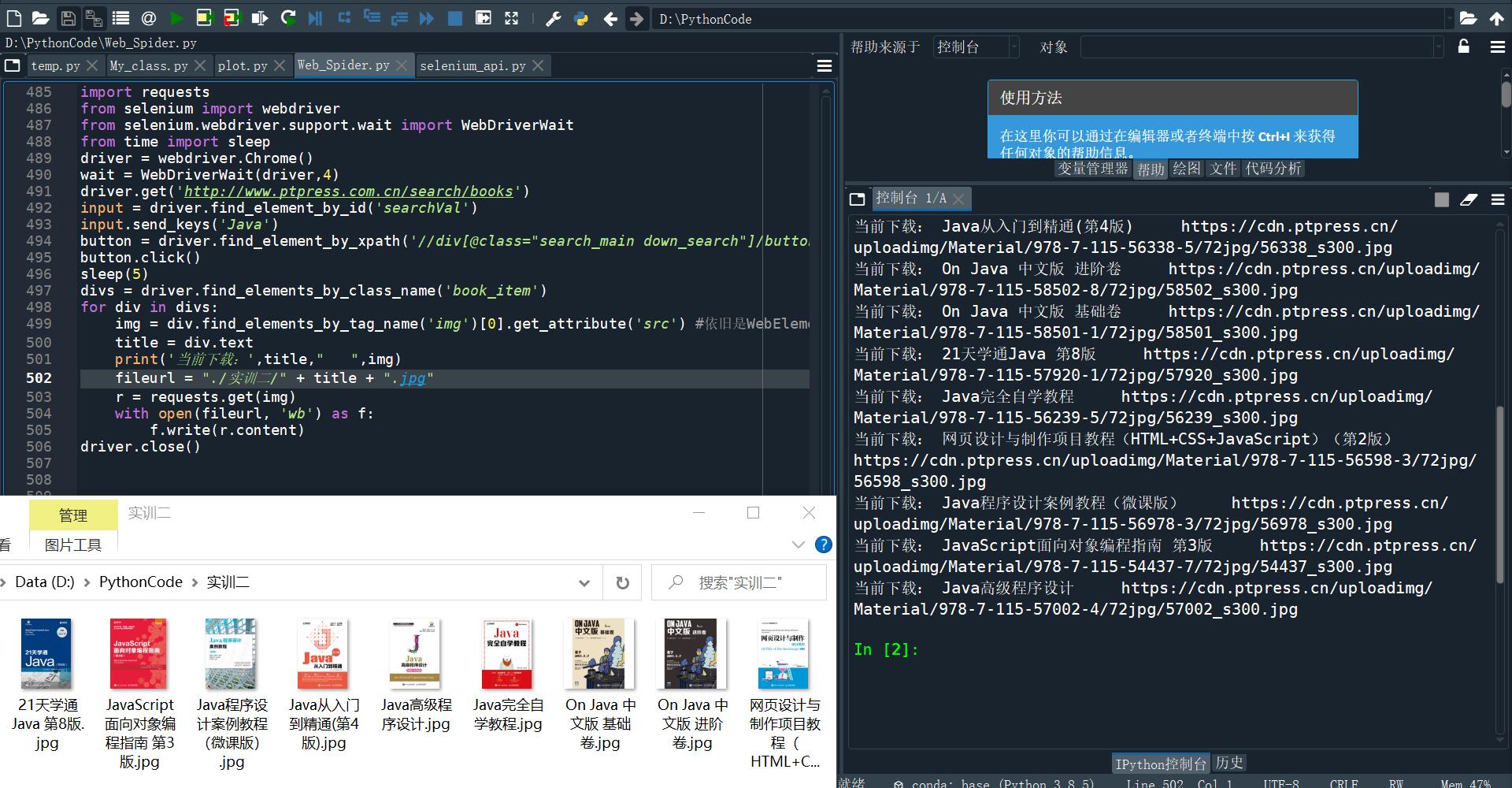
爬取网页Java图书信息
import requests
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from time import sleep
driver = webdriver.Chrome()
wait = WebDriverWait(driver,4)
driver.get('http://www.ptpress.com.cn/search/books')
input = driver.find_element_by_id('searchVal')
input.send_keys('Java')
button = driver.find_element_by_xpath('//div[@class="search_main down_search"]/button')
button.click()
sleep(5)
divs = driver.find_elements_by_class_name('book_item')
for div in divs:
img = div.find_elements_by_tag_name('img')[0].get_attribute('src') #依旧是WebElement对象
title = div.text
print('当前下载:',title," ",img)
fileurl = "./实训二/" + title + ".jpg"
r = requests.get(img)
with open(fileurl, 'wb') as f:
f.write(r.content)
driver.close()
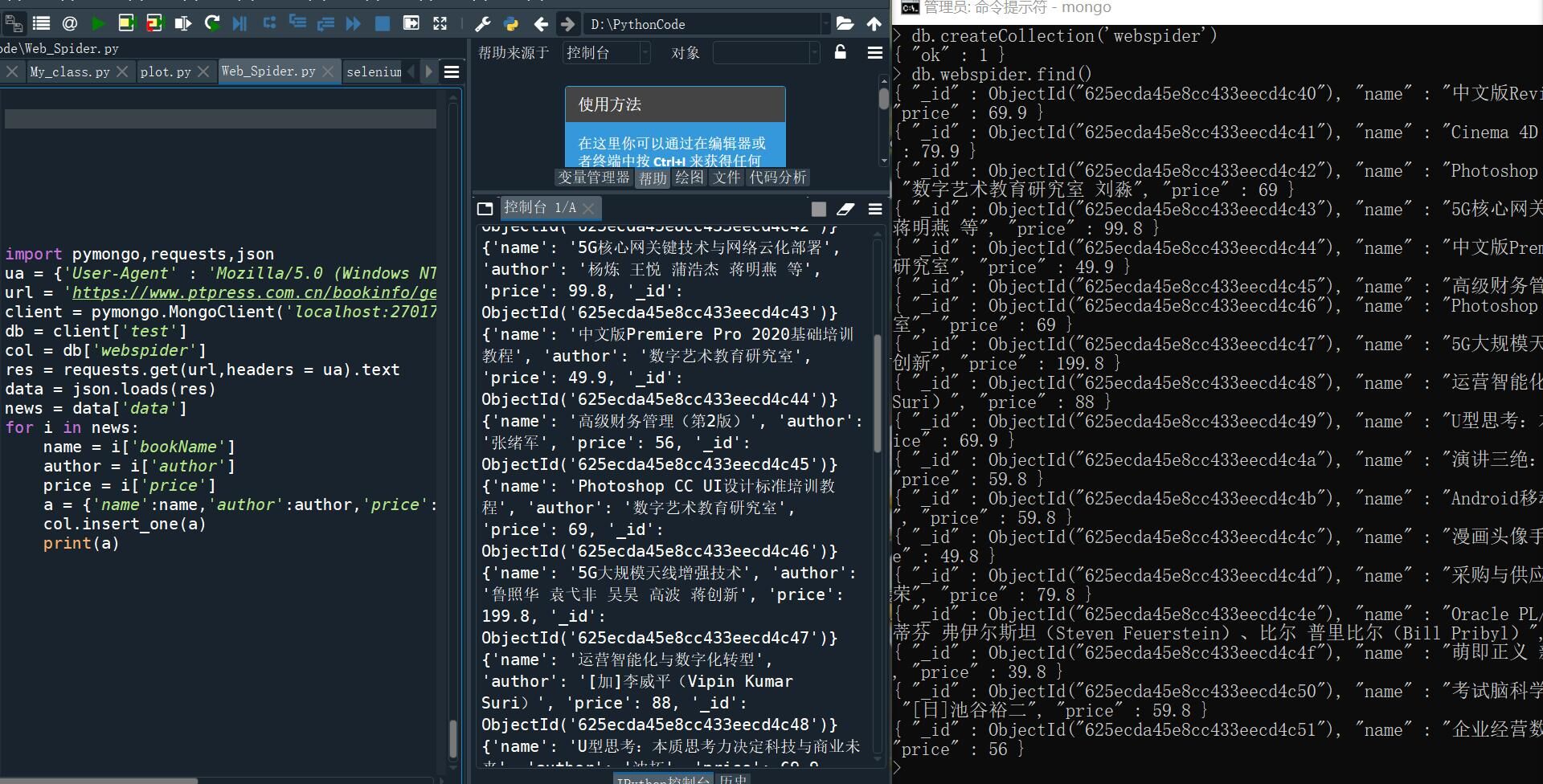
将数据存储到MongoDB数据库中
import pymongo,requests,json
ua = {'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) Chrome/65.0.3325.181'}
url = 'https://www.ptpress.com.cn/bookinfo/getBookListForWS'
client = pymongo.MongoClient('localhost:27017')
db = client['test']
col = db['webspider']
res = requests.get(url,headers = ua).text
data = json.loads(res)
news = data['data']
for i in news:
name = i['bookName']
author = i['author']
price = i['price']
a = {'name':name,'author':author,'price':price}
col.insert_one(a)
print(a)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号