数据分析实训
代入感很强,我已经是大数据分析工程师了。
#数据进行预处理,python,pandas
import pandas as pd
import numpy as np
df = pd.read_csv('./kc_house_data.csv')
df.head(10)
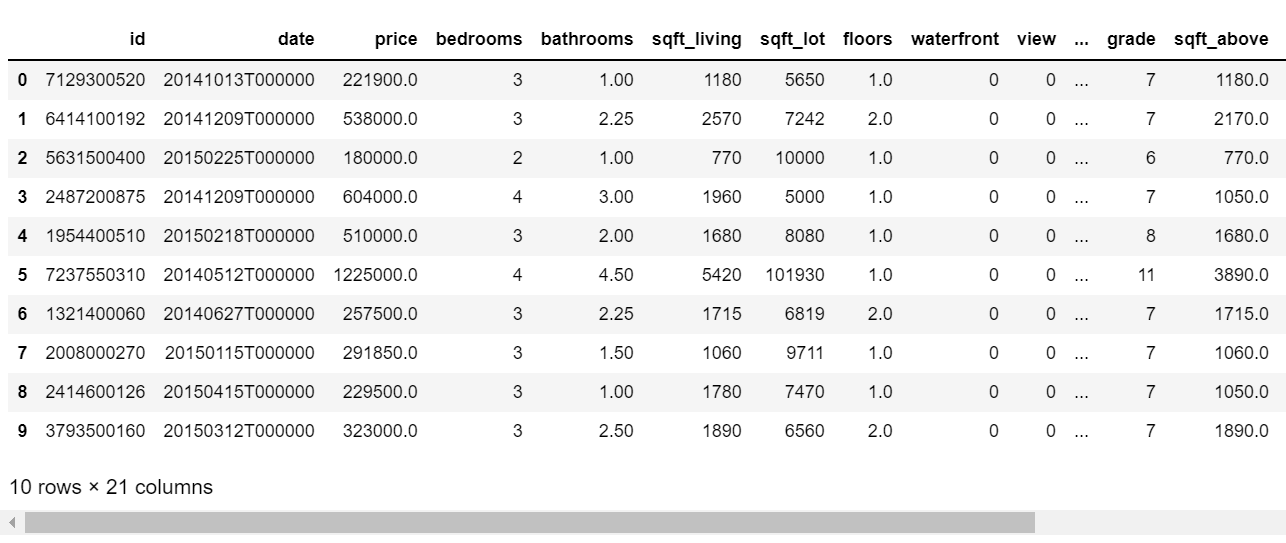
df.shape
(21613, 21)
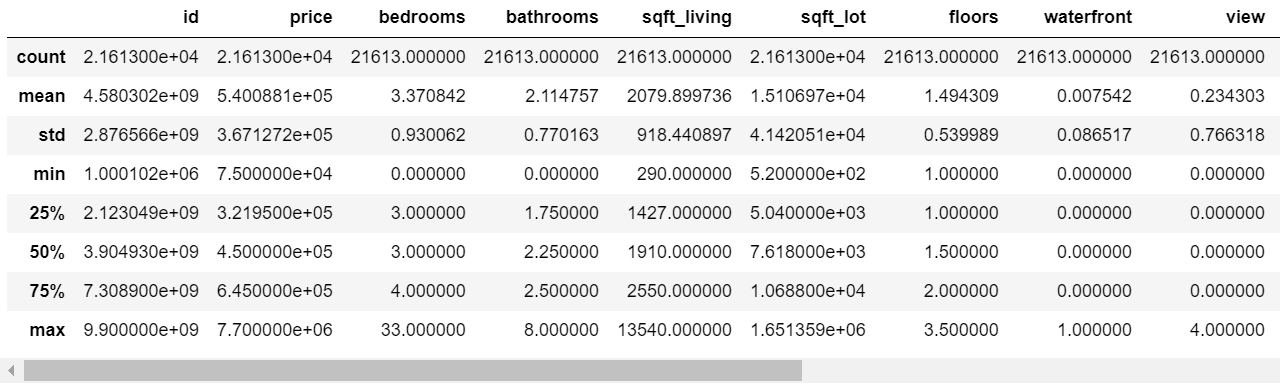
df.describe()
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 21613 entries, 0 to 21612
Data columns (total 21 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 21613 non-null int64
1 date 21613 non-null object
2 price 21613 non-null float64
.. ...... ..... ........ ....
19 sqft_living15 21613 non-null int64
20 sqft_lot15 21613 non-null int64
dtypes: float64(6), int64(14), object(1)
memory usage: 3.5+ MB
df.isnull()

import missingno as miss #预处理可视化库
miss.bar(df)
#查看缺失值
df.isnull().sum()
id 0
... .
sqft_above 2
... .
sqft_lot15 0
dtype: int64
# 缺失值处理 均值填充
df['sqft_above']=df['sqft_above'].fillna(df['sqft_above'].mean())
df.isnull().sum()
id 0
... .
sqft_above 0
... .
sqft_lot15 0
dtype: int64
# 异常值的处理 3σ原则 箱线图
# 异常值处理都是针对列属性
price = df['price']
price_mean=price.mean()
# 每一个值和均值的差值的绝对值
price_abs=list(np.abs(price-price_mean))
# 标准差
std3=np.std(price)*3
# 计算是不是大于三倍的标准差
# 如果是,就认为这个数据是异常值,如果不是,就认为这个数据是正常值
for x in range(0,21613):
if price_abs[x]>std3:
if x < 1000:
print('index:',x,' unnormal value:',price[x])
#均值替换
price[x] == price_mean
index: 21 unnormal value: 2000000.0
index: 153 unnormal value: 2250000.0
index: 246 unnormal value: 2400000.0
index: 269 unnormal value: 2900000.0
index: 282 unnormal value: 2050000.0
index: 300 unnormal value: 3075000.0
index: 312 unnormal value: 2384000.0
index: 518 unnormal value: 2250000.0
index: 540 unnormal value: 2125000.0
index: 556 unnormal value: 1950000.0
index: 656 unnormal value: 3070000.0
index: 779 unnormal value: 2250000.0
index: 814 unnormal value: 2400000.0
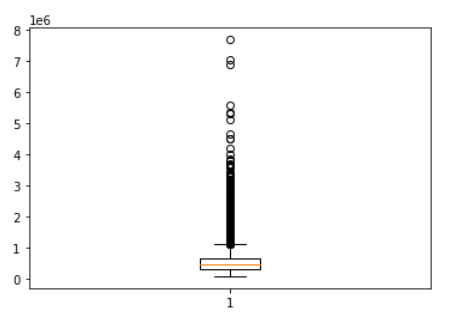
#箱线图法 可视化
import matplotlib.pyplot as plt
plt.boxplot(df['price'])
plt.show()
#Pandas对数据进行切块 字典
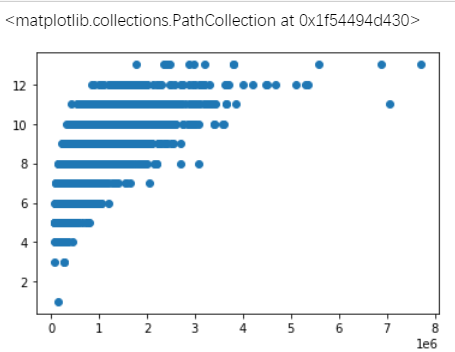
price = np.array(list(df['price']))
grade = np.array(list(df['grade']))
# 他们差不多有线性关系
plt.figure()
plt.scatter(price,grade)
# numpy库求相关系数
cordata=np.corrcoef(price,grade)
print(cordata)
[[1. 0.66743426]
[0.66743426 1. ]]
# Pandas实现
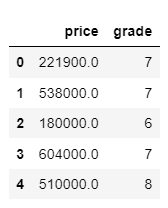
# 给Pandas数据分片
test=df.loc[:,['price','grade']]
test.head(5)
a=test.corr(method='pearson')
print(a)
| price | grade | |
|---|---|---|
| price | 1.000000 | 0.667434 |
| grade | 0.667434 | 1.000000 |
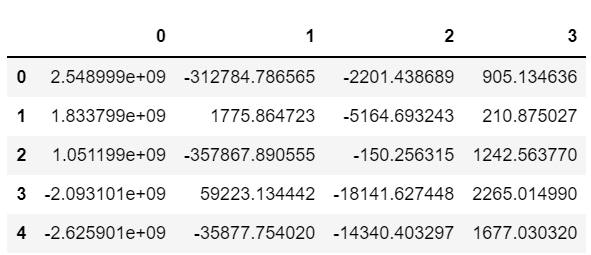
#PCA 主成分分析法
df1 = df
del df1['date']
from sklearn.decomposition import PCA
# 定义空模型
model_pca=PCA(4) # 空的 # 4 #有了一个小孩
data_pca=model_pca.fit_transform(df1)
pd.DataFrame(data_pca).head()
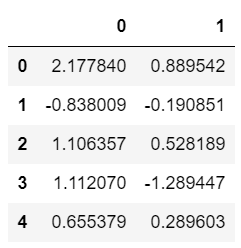
# LDA算法
X = df1[[col for col in df1.columns if col!='price']] # 数据 #题
Y = df1['grade'] # 标签 #答案
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
# 定义空模型
model_lda = LinearDiscriminantAnalysis(n_components=2)
df_lda = model_lda.fit_transform(X,Y)
df_lda = pd.DataFrame(data=df_lda)
df_lda.head()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号