Scrapy使用request对象来爬取web站点。
request对象由spiders对象产生,经由Scheduler传送到Downloader,Downloader执行request并返回response给spiders。
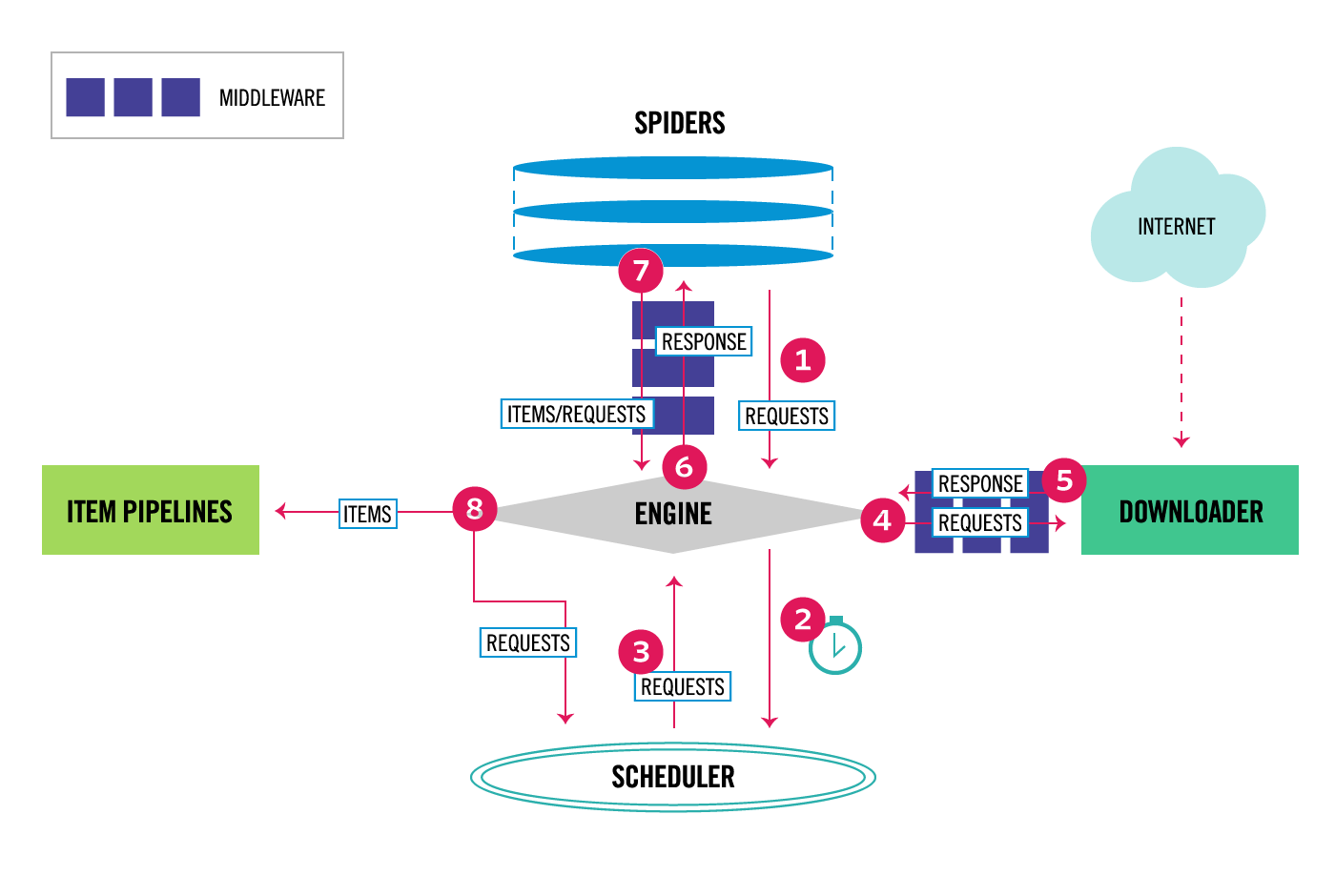
Scrapy架构:
1、Request objects
class scrapy.http.Request(url[, callback, method='GET', headers, body, cookies, meta, encoding='utf-8', priority=0, dont_filter=False, errback])
一个request对象代表一个HTTP请求,通常有Spider产生,经Downloader执行从而产生一个Response。
Paremeters: url(string): 用于请求的URL
callback(callable):指定一个回调函数,该回调函数以这个request是的response作为第一个参数。如果未指定callback,
则默认使用spider的parse()方法。
method(string):HTTP请求的方法,默认为GET(看到GET你应该明白了,过不不明白建议先学习urllib或者requets模块)
meta(dict):指定Request.meta属性的初始值。如果给了该参数,dict将会浅拷贝。(浅拷贝不懂的赶紧回炉)
body(str):the request body.(这个没有理解,若有哪位大神明白,请指教,谢谢)
headers(dict):request的头信息。
cookies(dict or list):cookie有两种格式。
1、使用dict:
request_with_cookies = Request(url="http://www.example.com", cookies={'currency': 'USD', 'country': 'UY'})
2、使用字典的list
request_with_cookies = Request(url="http://www.example.com", cookies=[{'name': 'currency', 'value': 'USD', 'domain': 'example.com', 'path': '/currency'}])
后面这种形式可以定制cookie的domain和path属性,只有cookies为接下来的请求保存的时候才有用。
当网站在response中返回cookie时,这些cookie将被保存以便未来的访问请求。这是常规浏览器的行为。如果你想避免修改当前
正在使用的cookie,你可以通过设置Request.meta中的dont_merge_cookies为True来实现。
request_with_cookies = Request(url="http://www.example.com", cookies={'currency': 'USD', 'country': 'UY'}, meta={'dont_merge_cookies': True})
encoding(string):请求的编码, 默认为utf-8
priority(int):请求的优先级
dont_filter(boolean):指定该请求是否被 Scheduler过滤。该参数可以是request重复使用(Scheduler默认过滤重复请求)。谨慎使用!!
errback(callable):处理异常的回调函数。
属性和方法:
url: 包含request的URL的字符串
method: 代表HTTP的请求方法的字符串,例如'GET', 'POST'...
headers: request的头信息
body: 请求体
meta: 一个dict,包含request的任意元数据。该dict在新Requests中为空,当Scrapy的其他扩展启用的时候填充数据。dict在传输是浅拷贝。
copy(): 拷贝当前Request
replace([url, method, headers, body, cookies, meta, encoding, dont_filter, callback, errback]): 返回一个参数相同的Request,
可以为参数指定新数据。
给回调函数传递数据
当request的response被下载是,就会调用回调函数,并以response对象为第一个参数


def parse_page1(self, response): return scrapy.Request("http://www.example.com/some_page.html", callback=self.parse_page2) def parse_page2(self, response): # this would log http://www.example.com/some_page.html self.logger.info("Visited %s", response.url)
在某些情况下,你希望在回调函数们之间传递参数,可以使用Request.meta。(其实有点类似全局变量的赶脚)
def parse_page1(self, response): item = MyItem() item['main_url'] = response.url request = scrapy.Request("http://www.example.com/some_page.html", callback=self.parse_page2) request.meta['item'] = item yield request def parse_page2(self, response): item = response.meta['item'] item['other_url'] = response.url yield item
使用errback来捕获请求执行中的异常
当request执行时有异常抛出将会调用errback回调函数。
它接收一个Twisted Failure实例作为第一个参数,并被用来回溯连接超时或DNS错误等。
1 import scrapy 2 3 from scrapy.spidermiddlewares.httperror import HttpError 4 from twisted.internet.error import DNSLookupError 5 from twisted.internet.error import TimeoutError, TCPTimedOutError 6 7 class ErrbackSpider(scrapy.Spider): 8 name = "errback_example" 9 start_urls = [ 10 "http://www.httpbin.org/", # HTTP 200 expected 11 "http://www.httpbin.org/status/404", # Not found error 12 "http://www.httpbin.org/status/500", # server issue 13 "http://www.httpbin.org:12345/", # non-responding host, timeout expected 14 "http://www.httphttpbinbin.org/", # DNS error expected 15 ] 16 17 def start_requests(self): 18 for u in self.start_urls: 19 yield scrapy.Request(u, callback=self.parse_httpbin, 20 errback=self.errback_httpbin, 21 dont_filter=True) 22 23 def parse_httpbin(self, response): 24 self.logger.info('Got successful response from {}'.format(response.url)) 25 # do something useful here... 26 27 def errback_httpbin(self, failure): 28 # log all failures 29 self.logger.error(repr(failure)) 30 31 # in case you want to do something special for some errors, 32 # you may need the failure's type: 33 34 if failure.check(HttpError): 35 # these exceptions come from HttpError spider middleware 36 # you can get the non-200 response 37 response = failure.value.response 38 self.logger.error('HttpError on %s', response.url) 39 40 elif failure.check(DNSLookupError): 41 # this is the original request 42 request = failure.request 43 self.logger.error('DNSLookupError on %s', request.url) 44 45 elif failure.check(TimeoutError, TCPTimedOutError): 46 request = failure.request 47 self.logger.error('TimeoutError on %s', request.url)
Request.meta的特殊关键字
Request.meta可以包含任意的数据,但Scrapy和内置扩展提供了一些特殊的关键字
dont_redirect (其实dont就是don't,嗯哼~)dont_retryhandle_httpstatus_listhandle_httpstatus_alldont_merge_cookies(seecookiesparameter ofRequestconstructor)cookiejardont_cacheredirect_urlsbindaddressdont_obey_robotstxtdownload_timeout(下载超时)download_maxsizedownload_latency(下载延时)proxy
2、Request subclasses
FormRequest object
FormRequest继承自Request类,增加了处理HTML表单数据的功能
class scrapy.http.FormRequset(url[, formdata,...])
FormRequest类新增了'formdata'参数在构造方法中,其他参数与Request类相同,不再赘述。
Parameters:
formdata (dict or iterable of tuple)是一个字典(或键值对的可迭代元组),包含HTML表单数据(会被url_encode)并部署到请求体重。
FormRequest对象支持一个标准Request方法之外的类方法
classmethod from_response(response[, formname=None, formid=None, formnumber=0, formdata=None, formxpath=None, formcss=None,
clickdata=None, dont_click=False, ...])
根据response找到HTML的<from>元素,以此来填充给定的form字段值,并返回一个新的FormRequest对象。
在任何看起来可点击(例如<input type="submit">)的表单控制处,该策略默认自动模拟点击。虽然很方便,但有时会造成很难debug的问题,例如当满是javascript的and/or提交时,
默认的from_response就不再合适了。可以通过设置dont_click为True关闭这个动作。你也可以使用clickdata参数来改变对点击的控制。
parameters:
response(Response object): 包含HTML form的response对象,用来填充form字段
formname(string): 如果设置,name为该值的form将被使用
formid(string): 如果设置,id为该值的form将被使用。
formxpath(string): 如果设置,和xpath匹配的第一个form将被使用
formcss(string): 如果设置,和css选择器匹配的第一个form将被使用
formnumber(integer): 当response包含多个form的时候,指定使用的数量。第一个为0 (也是默认值)
formdata(dict): 用来重写form数据的字段。如果某个字段在response的<form>元素中已经存在一个值,那么现存的值将被重写。
clickdata(dict): (没明白,暂时不写)
dont_click(boolean): 如果为True, form数据将会提交而不点击任何元素。
Request应用实例
使用FormRequest通过HTML POST发送数据
如果你想在爬虫中模拟HTML Form POST并发送键值对字段,你可以返回一个FormRequest对象(从你的spider):
return [FormRequest(url="http://www.example.com/post/action", formdata={'name': 'John Doe', 'age': '27'}, callback=self.after_post)]
使用FormRequest.from_response模拟用户登录
web站点通常通过<input type="hidden">元素要求填充Form字段,比如会话相关数据或者验证口令(登录界面)。在爬取时,你想自动填充并重写这些字段,就像输入用户名和密码。可以使用
FormRequest.from_response()来实现。
import scrapy class LoginSpider(scrapy.Spider): name = 'example.com' start_urls = ['http://www.example.com/users/login.php'] def parse(self, response): return scrapy.FormRequest.from_response( response, formdata={'username': 'john', 'password': 'secret'}, callback=self.after_login ) def after_login(self, response): # check login succeed before going on if "authentication failed" in response.body: self.logger.error("Login failed") return # continue scraping with authenticated session...
(本编为本人学习Scrapy文档时的翻译,因为英语不好看了后面忘前面实在痛苦,自己做了这篇翻译,水平有限,若有错误请指正,谢谢!)
参考文献:
https://doc.scrapy.org/en/1.3/topics/request-response.html#topics-request-response-ref-request-callback-arguments

 浙公网安备 33010602011771号
浙公网安备 33010602011771号