【Java】SpringCloud架构系统中如何保证集群环境下定时任务同时只有一个实例运行工作?
问题
首先说下情况,我们平常开发SpringCloud微服务的时候,若要确保高可用,同一服务都会部署多台实例,然后注册到Eureka上。
一般我们会把所有定时任务写到一个服务里,那平常单实例的时候,都可以正常执行。如果该定时任务服务部署多个实例,如何确保只在一个服务实例里执行任务呢?
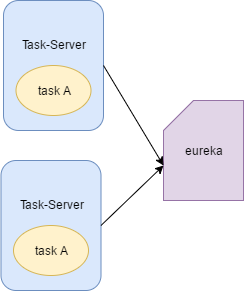
个人总结了下,可以有以下解决思路。
解决
1. 如果原有的task代码同时执行一次或多次的结果都是正确的,那么可以就不做任何处理,只不过会造成资源浪费,当然这种方式不推荐。
比如图里的taskA是每隔五分钟更新下已完成的工单的记录为归档,那其实本质就是执行一个update的sql,即使是同时执行mysql数据库也有锁机制,所以数据不会出错。那多实例下也可以不做处理,不过再说一遍,虽然结果不会出错,但是不推荐这样做,还是要处理一下的。
2. 使用分布式锁
借助分布式锁,确保多个实例里的task只有竞争到锁的实例任务才执行。比如,redis的分不式锁。这种方式不好的地方是需要修改逻辑代码,增加了对redis的依赖。
3. 使用任务调度框架的集群功能
之前我使用的是Quartz,Quartz是一个完全由Java编写的开源作业调度框架,Quartz的集群功能通过故障转移和负载平衡功能为您的调度程序带来高可用性和可扩展性。这种方式也有不好的地方,那就是要实现Quartz的集群功能,需要修改Quartz的配置,而且是要额外增加Quartz集群需要的数据库表,如果一开始开发没有考虑集群,后面再加入改动会有点大。
4. 最小ip执行
这应该算是一个思路,我也是在网上看到的,具体实现是。

①先在代码里获取获取到当前实例的ip,通过一定算法规则转成一个Long型。
②从Eureka里根据实例名,图里的Taks-Server获取到对应的集群ip集合,也就是192.168.2.10、192.168.2.11、192.168.2.12,也分别把它们转成对应的Long型。
③拿第一步里的Long和第二步获取的Long的List做对比,如果判断到它是集合里最小的,那就在该实例里执行task,否则就retur掉。
这样就能确保永远只有一个实例执行定时任务了。
5. elastic-job
elastic-job 是由当当网基于quartz 二次开发之后的分布式调度解决方案,所以本质和方法3一样。
总结
如果你的系统架构刚开始,那就可以把任务的分布式集群情况考虑进去,使用集群框架实现,如果你的系统已经完成或趋于稳定,则不建议大改,可以考虑方法2的分布式锁或者方法3。
最小ip算法:
@Slf4j @Component public class IpService { @Autowired private ApplicationContext applicationContext; /** * Eureka 客户端 */ private EurekaClient eurekaClient; /** * 比对当前ip及eureka上的其他ip * 判断当前ip是否是最小ip * * @param serviceName */ public Boolean canRun(String serviceName) { //获取 eureka 客户端 this.eurekaClient = this.applicationContext.getBean(DiscoveryClient.class); //获取当前服务注册的 eureka 上的全部实例 Applications applications = this.eurekaClient.getApplications(); if (applications == null || applications.size() <= 0) { log.info("未能从注册中心找到其它服务"); return false; } //若实例不为空则获取全部实例的集合 List<Application> applicationList = applications.getRegisteredApplications(); if (CollUtil.isNotEmpty(applicationList)) { List<String> urlList = new ArrayList<>(); for (Application application : applicationList) { if (application.getName().startsWith(serviceName)) { List<InstanceInfo> instances = application.getInstances(); instances.forEach(instanceInfo -> urlList.add(instanceInfo.getIPAddr())); } } return ipCompare(urlList); } else { return false; } } /** * 对比方法 * * @param serviceUrl * @return */ private static boolean ipCompare(List<String> serviceUrl) { try { String localIpStr = getIpAddress(); assert localIpStr != null; long localIpLong = ipToLong(localIpStr); int size = serviceUrl.size(); if (size == 0) { return false; } Long[] longHost = new Long[size]; for (int i = 0; i < serviceUrl.size(); i++) { longHost[i] = ipToLong(serviceUrl.get(i)); } Arrays.sort(longHost); if (localIpLong == longHost[0]) { return true; } } catch (Exception e) { e.printStackTrace(); } return false; } /** * 获取当前机器的IP * * @return */ private static String getIpAddress() { try { for (Enumeration<NetworkInterface> enumNic = NetworkInterface.getNetworkInterfaces(); enumNic.hasMoreElements(); ) { NetworkInterface ifc = enumNic.nextElement(); if (ifc.isUp()) { for (Enumeration<InetAddress> enumAddr = ifc.getInetAddresses(); enumAddr.hasMoreElements(); ) { InetAddress address = enumAddr.nextElement(); if (address instanceof Inet4Address && !address.isLoopbackAddress()) { return address.getHostAddress(); } } } } return InetAddress.getLocalHost().getHostAddress(); } catch (IOException e) { //log.warn("Unable to find non-loopback address", e); e.printStackTrace(); } return null; } /** * @param ipAddress * @return */ private static long ipToLong(String ipAddress) { long result = 0; String[] ipAddressInArray = ipAddress.split("\\."); for (int i = 3; i >= 0; i--) { long ip = Long.parseLong(ipAddressInArray[3 - i]); // left shifting 24,16,8,0 and bitwise OR // 1. 192 << 24 // 1. 168 << 16 // 1. 1 << 8 // 1. 2 << 0 result |= ip << (i * 8); } return result; } }
参考:https://www.cnblogs.com/shamo89/p/12269338.html
https://blog.csdn.net/linzhiqiang0316/article/details/88047138

 浙公网安备 33010602011771号
浙公网安备 33010602011771号