简化ETL工作,编写一个Canal胶水层
前提
这是一篇憋了很久的文章,一直想写,却又一直忘记了写。整篇文章可能会有点流水账,相对详细地介绍怎么写一个小型的"框架"。这个精悍的胶水层已经在生产环境服役超过半年,这里尝试把耦合业务的代码去掉,提炼出一个相对简洁的版本。
之前写的几篇文章里面其中一篇曾经提到过Canal解析MySQL的binlog事件后的对象如下(来源于Canal源码com.alibaba.otter.canal.protocol.FlatMessage):
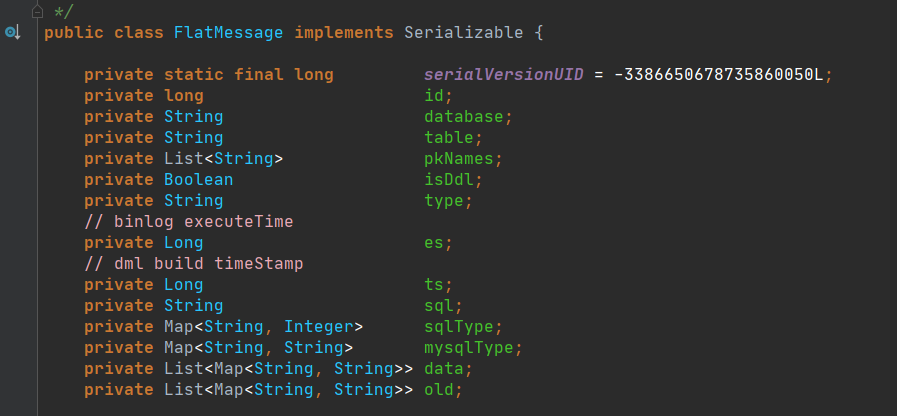
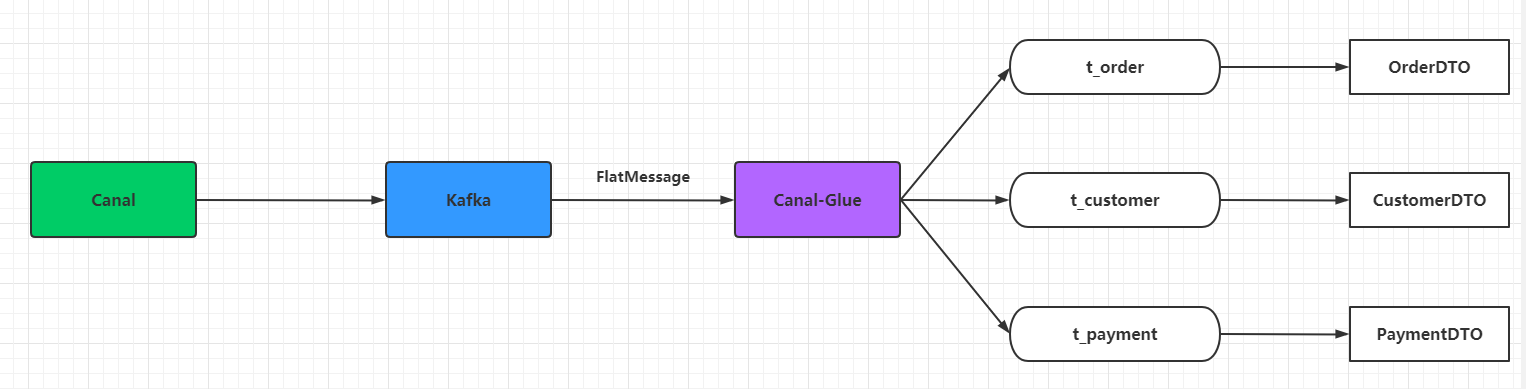
如果直接对此原始对象进行解析,那么会出现很多解析模板代码,一旦有改动就会牵一发动全身,这是我们不希望发生的一件事。于是花了一点点时间写了一个Canal胶水层,让接收到的FlatMessage根据表名称直接转换为对应的DTO实例,这样能在一定程度上提升开发效率并且减少模板化代码,这个胶水层的数据流示意图如下:
要编写这样的胶水层主要用到:
- 反射。
- 注解。
- 策略模式。
IOC容器(可选)。
项目的模块如下:
canal-glue-core:核心功能。spring-boot-starter-canal-glue:适配Spring的IOC容器,添加自动配置。canal-glue-example:使用例子和基准测试。
下文会详细分析此胶水层如何实现。
引入依赖
为了不污染引用此模块的外部服务依赖,除了JSON转换的依赖之外,其他依赖的scope定义为provide或者test类型,依赖版本和BOM如下:
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<spring.boot.version>2.3.0.RELEASE</spring.boot.version>
<maven.compiler.plugin.version>3.8.1</maven.compiler.plugin.version>
<lombok.version>1.18.12</lombok.version>
<fastjson.version>1.2.73</fastjson.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring.boot.version}</version>
<scope>import</scope>
<type>pom</type>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>${fastjson.version}</version>
</dependency>
</dependencies>
其中,canal-glue-core模块本质上只依赖于fastjson,可以完全脱离spring体系使用。
基本架构
这里提供一个"后知后觉"的架构图,因为之前为了快速怼到线上,初版没有考虑这么多,甚至还耦合了业务代码,组件是后来抽离出来的:
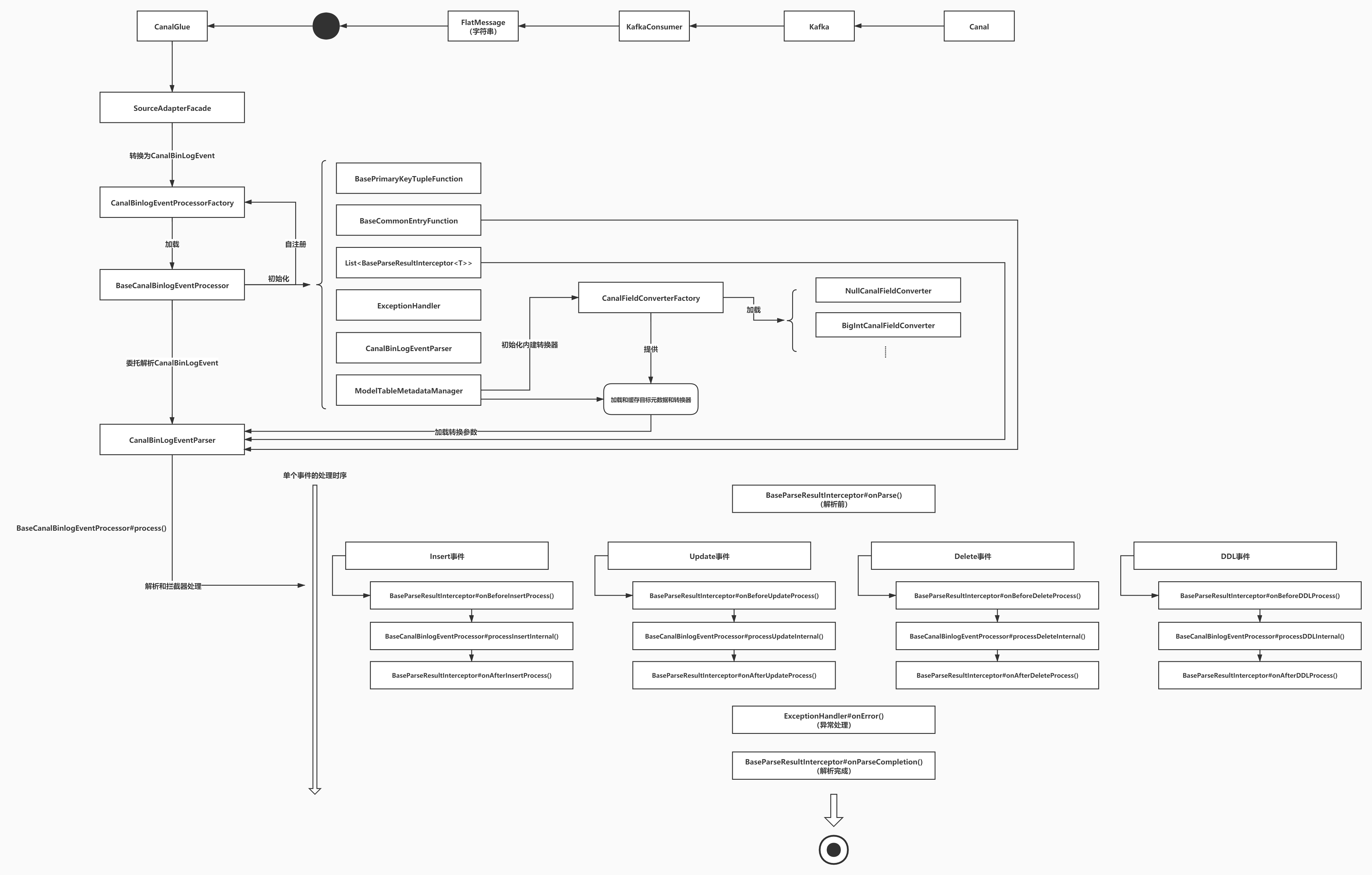
设计配置模块(已经移除)
设计配置模块在设计的时候考虑使用了外置配置文件和纯注解两种方式,前期使用了JSON外置配置文件的方式,纯注解是后来增加的,二选一。这一节简单介绍一下JSON外置配置文件的配置加载,纯注解留到后面处理器模块时候分析。
当初是想快速进行胶水层的开发,所以配置文件使用了可读性比较高的JSON格式:
{
"version": 1,
"module": "canal-glue",
"databases": [
{
"database": "db_payment_service",
"processors": [
{
"table": "payment_order",
"processor": "x.y.z.PaymentOrderProcessor",
"exceptionHandler": "x.y.z.PaymentOrderExceptionHandler"
}
]
},
{
......
}
]
}
JSON配置在设计的时候尽可能不要使用JSON Array作为顶层配置,因为这样做设计的对象会比较怪
因为使用该模块的应用有可能需要处理Canal解析多个上游数据库的binlog事件,所以配置模块设计的时候需要以database为KEY,挂载多个table以及对应的表binlog事件处理器以及异常处理器。然后对着JSON文件的格式撸一遍对应的实体类出来:
@Data
public class CanalGlueProcessorConf {
private String table;
private String processor;
private String exceptionHandler;
}
@Data
public class CanalGlueDatabaseConf {
private String database;
private List<CanalGlueProcessorConf> processors;
}
@Data
public class CanalGlueConf {
private Long version;
private String module;
private List<CanalGlueDatabaseConf> database;
}
实体编写完,接着可以编写一个配置加载器,简单起见,配置文件直接放ClassPath之下,加载器如下:
public interface CanalGlueConfLoader {
CanalGlueConf load(String location);
}
// 实现
public class ClassPathCanalGlueConfLoader implements CanalGlueConfLoader {
@Override
public CanalGlueConf load(String location) {
ClassPathResource resource = new ClassPathResource(location);
Assert.isTrue(resource.exists(), String.format("类路径下不存在文件%s", location));
try {
String content = StreamUtils.copyToString(resource.getInputStream(), StandardCharsets.UTF_8);
return JSON.parseObject(content, CanalGlueConf.class);
} catch (IOException e) {
// should not reach
throw new IllegalStateException(e);
}
}
}
读取ClassPath下的某个location为绝对路径的文件内容字符串,然后使用Fasfjson转成CanalGlueConf对象。这个是默认的实现,使用canal-glue模块可以覆盖此实现,通过自定义的实现加载配置。
JSON配置模块在后来从业务系统抽离此胶水层的时候已经完全废弃,使用纯注解驱动和核心抽象组件继承的方式实现。
核心模块开发
主要包括几个模块:
- 基本模型定义。
- 适配器层开发。
- 转换器和解析器层开发。
- 处理器层开发。
- 全局组件自动配置模块开发(仅限于
Spring体系,已经抽取到spring-boot-starter-canal-glue模块)。 CanalGlue开发。
基本模型定义
定义顶层的KEY,也就是对于某个数据库的某一个确定的表,需要一个唯一标识:
// 模型表对象
public interface ModelTable {
String database();
String table();
static ModelTable of(String database, String table) {
return DefaultModelTable.of(database, table);
}
}
@RequiredArgsConstructor(access = AccessLevel.PACKAGE, staticName = "of")
public class DefaultModelTable implements ModelTable {
private final String database;
private final String table;
@Override
public String database() {
return database;
}
@Override
public String table() {
return table;
}
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
DefaultModelTable that = (DefaultModelTable) o;
return Objects.equals(database, that.database) &&
Objects.equals(table, that.table);
}
@Override
public int hashCode() {
return Objects.hash(database, table);
}
}
这里实现类DefaultModelTable重写了equals()和hashCode()方法便于把ModelTable实例应用为HashMap容器的KEY,这样后面就可以设计ModelTable -> Processor的缓存结构。
由于Canal投放到Kafka的事件内容是一个原始字符串,所以要定义一个和前文提到的FlatMessage基本一致的事件类CanalBinLogEvent:
@Data
public class CanalBinLogEvent {
/**
* 事件ID,没有实际意义
*/
private Long id;
/**
* 当前更变后节点数据
*/
private List<Map<String, String>> data;
/**
* 主键列名称列表
*/
private List<String> pkNames;
/**
* 当前更变前节点数据
*/
private List<Map<String, String>> old;
/**
* 类型 UPDATE\INSERT\DELETE\QUERY
*/
private String type;
/**
* binlog execute time
*/
private Long es;
/**
* dml build timestamp
*/
private Long ts;
/**
* 执行的sql,不一定存在
*/
private String sql;
/**
* 数据库名称
*/
private String database;
/**
* 表名称
*/
private String table;
/**
* SQL类型映射
*/
private Map<String, Integer> sqlType;
/**
* MySQL字段类型映射
*/
private Map<String, String> mysqlType;
/**
* 是否DDL
*/
private Boolean isDdl;
}
根据此事件对象,再定义解析完毕后的结果对象CanalBinLogResult:
// 常量
@RequiredArgsConstructor
@Getter
public enum BinLogEventType {
QUERY("QUERY", "查询"),
INSERT("INSERT", "新增"),
UPDATE("UPDATE", "更新"),
DELETE("DELETE", "删除"),
ALTER("ALTER", "列修改操作"),
UNKNOWN("UNKNOWN", "未知"),
;
private final String type;
private final String description;
public static BinLogEventType fromType(String type) {
for (BinLogEventType binLogType : BinLogEventType.values()) {
if (binLogType.getType().equals(type)) {
return binLogType;
}
}
return BinLogEventType.UNKNOWN;
}
}
// 常量
@RequiredArgsConstructor
@Getter
public enum OperationType {
/**
* DML
*/
DML("dml", "DML语句"),
/**
* DDL
*/
DDL("ddl", "DDL语句"),
;
private final String type;
private final String description;
}
@Data
public class CanalBinLogResult<T> {
/**
* 提取的长整型主键
*/
private Long primaryKey;
/**
* binlog事件类型
*/
private BinLogEventType binLogEventType;
/**
* 更变前的数据
*/
private T beforeData;
/**
* 更变后的数据
*/
private T afterData;
/**
* 数据库名称
*/
private String databaseName;
/**
* 表名称
*/
private String tableName;
/**
* sql语句 - 一般是DDL的时候有用
*/
private String sql;
/**
* MySQL操作类型
*/
private OperationType operationType;
}
开发适配器层
定义顶层的适配器SPI接口:
public interface SourceAdapter<SOURCE, SINK> {
SINK adapt(SOURCE source);
}
接着开发适配器实现类:
// 原始字符串直接返回
@RequiredArgsConstructor(access = AccessLevel.PACKAGE, staticName = "of")
class RawStringSourceAdapter implements SourceAdapter<String, String> {
@Override
public String adapt(String source) {
return source;
}
}
// Fastjson转换
@RequiredArgsConstructor(access = AccessLevel.PACKAGE, staticName = "of")
class FastJsonSourceAdapter<T> implements SourceAdapter<String, T> {
private final Class<T> klass;
@Override
public T adapt(String source) {
if (StringUtils.isEmpty(source)) {
return null;
}
return JSON.parseObject(source, klass);
}
}
// Facade
public enum SourceAdapterFacade {
/**
* 单例
*/
X;
private static final SourceAdapter<String, String> I_S_A = RawStringSourceAdapter.of();
@SuppressWarnings("unchecked")
public <T> T adapt(Class<T> klass, String source) {
if (klass.isAssignableFrom(String.class)) {
return (T) I_S_A.adapt(source);
}
return FastJsonSourceAdapter.of(klass).adapt(source);
}
}
最终直接使用SourceAdapterFacade#adapt()方法即可,因为实际上绝大多数情况下只会使用原始字符串和String -> Class实例,适配器层设计可以简单点。
开发转换器和解析器层
对于Canal解析完成的binlog事件,data和old属性是K-V结构,并且KEY都是String类型,需要遍历解析才能推导出完整的目标实例。
转换后的实例的属性类型目前只支持包装类,int等原始类型不支持
为了更好地通过目标实体和实际的数据库、表和列名称、列类型进行映射,引入了两个自定义注解CanalModel和@CanalField,它们的定义如下:
// @CanalModel
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface CanalModel {
/**
* 目标数据库
*/
String database();
/**
* 目标表
*/
String table();
/**
* 属性名 -> 列名命名转换策略,可选值有:DEFAULT(原始)、UPPER_UNDERSCORE(驼峰转下划线大写)和LOWER_UNDERSCORE(驼峰转下划线小写)
*/
FieldNamingPolicy fieldNamingPolicy() default FieldNamingPolicy.DEFAULT;
}
// @CanalField
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.FIELD)
public @interface CanalField {
/**
* 行名称
*
* @return columnName
*/
String columnName() default "";
/**
* sql字段类型
*
* @return JDBCType
*/
JDBCType sqlType() default JDBCType.NULL;
/**
* 转换器类型
*
* @return klass
*/
Class<? extends BaseCanalFieldConverter<?>> converterKlass() default NullCanalFieldConverter.class;
}
定义顶层转换器接口BinLogFieldConverter:
public interface BinLogFieldConverter<SOURCE, TARGET> {
TARGET convert(SOURCE source);
}
目前暂定可以通过目标属性的Class和通过注解指定的SQLType类型进行匹配,所以再定义一个抽象转换器BaseCanalFieldConverter:
public abstract class BaseCanalFieldConverter<T> implements BinLogFieldConverter<String, T> {
private final SQLType sqlType;
private final Class<?> klass;
protected BaseCanalFieldConverter(SQLType sqlType, Class<?> klass) {
this.sqlType = sqlType;
this.klass = klass;
}
@Override
public T convert(String source) {
if (StringUtils.isEmpty(source)) {
return null;
}
return convertInternal(source);
}
/**
* 内部转换方法
*
* @param source 源字符串
* @return T
*/
protected abstract T convertInternal(String source);
/**
* 返回SQL类型
*
* @return SQLType
*/
public SQLType sqlType() {
return sqlType;
}
/**
* 返回类型
*
* @return Class<?>
*/
public Class<?> typeKlass() {
return klass;
}
}
BaseCanalFieldConverter是面向目标实例中的单个属性的,例如对于实例中的Long类型的属性,可以实现一个BigIntCanalFieldConverter:
public class BigIntCanalFieldConverter extends BaseCanalFieldConverter<Long> {
/**
* 单例
*/
public static final BaseCanalFieldConverter<Long> X = new BigIntCanalFieldConverter();
private BigIntCanalFieldConverter() {
super(JDBCType.BIGINT, Long.class);
}
@Override
protected Long convertInternal(String source) {
if (null == source) {
return null;
}
return Long.valueOf(source);
}
}
其他类型以此类推,目前已经开发好的最常用的内建转换器如下:
| JDBCType | JAVAType | 转换器 |
|---|---|---|
NULL |
Void |
NullCanalFieldConverter |
BIGINT |
Long |
BigIntCanalFieldConverter |
VARCHAR |
String |
VarcharCanalFieldConverter |
DECIMAL |
BigDecimal |
DecimalCanalFieldConverter |
INTEGER |
Integer |
IntCanalFieldConverter |
TINYINT |
Integer |
TinyIntCanalFieldConverter |
DATE |
java.time.LocalDate |
SqlDateCanalFieldConverter0 |
DATE |
java.sql.Date |
SqlDateCanalFieldConverter1 |
TIMESTAMP |
java.time.LocalDateTime |
TimestampCanalFieldConverter0 |
TIMESTAMP |
java.util.Date |
TimestampCanalFieldConverter1 |
TIMESTAMP |
java.time.OffsetDateTime |
TimestampCanalFieldConverter2 |
所有转换器实现都设计为无状态的单例,方便做动态注册和覆盖。接着定义一个转换器工厂CanalFieldConverterFactory,提供API通过指定参数加载目标转换器实例:
// 入参
@SuppressWarnings("rawtypes")
@Builder
@Data
public class CanalFieldConvertInput {
private Class<?> fieldKlass;
private Class<? extends BaseCanalFieldConverter> converterKlass;
private SQLType sqlType;
@Tolerate
public CanalFieldConvertInput() {
}
}
// 结果
@Builder
@Getter
public class CanalFieldConvertResult {
private final BaseCanalFieldConverter<?> converter;
}
// 接口
public interface CanalFieldConverterFactory {
default void registerConverter(BaseCanalFieldConverter<?> converter) {
registerConverter(converter, true);
}
void registerConverter(BaseCanalFieldConverter<?> converter, boolean replace);
CanalFieldConvertResult load(CanalFieldConvertInput input);
}
CanalFieldConverterFactory提供了可以注册自定义转化器的registerConverter()方法,这样就可以让使用者注册自定义的转换器和覆盖默认的转换器。
至此,可以通过指定的参数,加载实例属性的转换器,拿到转换器实例,就可以针对目标实例,从原始事件中解析对应的K-V结构。接着需要编写最核心的解析器模块,此模块主要包含三个方面:
- 唯一
BIGINT类型主键的解析(这一点是公司技术规范的一条铁规则,MySQL每个表只能定义唯一的BIGINT UNSIGNED自增趋势主键)。 - 更变前的数据,对应于原始事件中的
old属性节点(不一定存在,例如INSERT语句中不存在此属性节点)。 - 更变后的数据,对应于原始事件中的
data属性节点。
定义解析器接口CanalBinLogEventParser如下:
public interface CanalBinLogEventParser {
/**
* 解析binlog事件
*
* @param event 事件
* @param klass 目标类型
* @param primaryKeyFunction 主键映射方法
* @param commonEntryFunction 其他属性映射方法
* @return CanalBinLogResult
*/
<T> List<CanalBinLogResult<T>> parse(CanalBinLogEvent event,
Class<T> klass,
BasePrimaryKeyTupleFunction primaryKeyFunction,
BaseCommonEntryFunction<T> commonEntryFunction);
}
解析器的解析方法依赖于:
binlog事件实例,这个是上游的适配器组件的结果。- 转换的目标类型。
BasePrimaryKeyTupleFunction主键映射方法实例,默认使用内建的BigIntPrimaryKeyTupleFunction。BaseCommonEntryFunction非主键通用列-属性映射方法实例,默认使用内建的ReflectionBinLogEntryFunction(这个是非主键列的转换核心,里面使用到了反射)。
解析返回结果是一个List,原因是FlatMessage在批量写入的时候的数据结构本来就是一个List<Map<String,String>>,这里只是"顺水推舟"。
开发处理器层
处理器是开发者处理最终解析出来的实体的入口,只需要面向不同类型的事件选择对应的处理方法即可,看起来如下:
public abstract class BaseCanalBinlogEventProcessor<T> extends BaseParameterizedTypeReferenceSupport<T> {
protected void processInsertInternal(CanalBinLogResult<T> result) {
}
protected void processUpdateInternal(CanalBinLogResult<T> result) {
}
protected void processDeleteInternal(CanalBinLogResult<T> result) {
}
protected void processDDLInternal(CanalBinLogResult<T> result) {
}
}
例如需要处理Insert事件,则子类继承BaseCanalBinlogEventProcessor,对应的实体类(泛型的替换)使用@CanalModel注解声明,然后覆盖processInsertInternal()方法即可。期间子处理器可以覆盖自定义异常处理器实例,如:
@Override
protected ExceptionHandler exceptionHandler() {
return EXCEPTION_HANDLER;
}
/**
* 覆盖默认的ExceptionHandler.NO_OP
*/
private static final ExceptionHandler EXCEPTION_HANDLER = (event, throwable)
-> log.error("解析binlog事件出现异常,事件内容:{}", JSON.toJSONString(event), throwable);
另外,有些场景需要对回调前或者回调后的结果做特化处理,因此引入了解析结果拦截器(链)的实现,对应的类是BaseParseResultInterceptor:
public abstract class BaseParseResultInterceptor<T> extends BaseParameterizedTypeReferenceSupport<T> {
public BaseParseResultInterceptor() {
super();
}
public void onParse(ModelTable modelTable) {
}
public void onBeforeInsertProcess(ModelTable modelTable, T beforeData, T afterData) {
}
public void onAfterInsertProcess(ModelTable modelTable, T beforeData, T afterData) {
}
public void onBeforeUpdateProcess(ModelTable modelTable, T beforeData, T afterData) {
}
public void onAfterUpdateProcess(ModelTable modelTable, T beforeData, T afterData) {
}
public void onBeforeDeleteProcess(ModelTable modelTable, T beforeData, T afterData) {
}
public void onAfterDeleteProcess(ModelTable modelTable, T beforeData, T afterData) {
}
public void onBeforeDDLProcess(ModelTable modelTable, T beforeData, T afterData, String sql) {
}
public void onAfterDDLProcess(ModelTable modelTable, T beforeData, T afterData, String sql) {
}
public void onParseFinish(ModelTable modelTable) {
}
public void onParseCompletion(ModelTable modelTable) {
}
}
解析结果拦截器的回调时机可以参看上面的架构图或者BaseCanalBinlogEventProcessor的源代码。
开发全局组件自动配置模块
如果使用了Spring容器,需要添加一个配置类来加载所有既有的组件,添加一个全局配置类CanalGlueAutoConfiguration(这个类可以在项目的spring-boot-starter-canal-glue模块中看到,这个模块就只有一个类):
@Configuration
public class CanalGlueAutoConfiguration implements SmartInitializingSingleton, BeanFactoryAware {
private ConfigurableListableBeanFactory configurableListableBeanFactory;
@Bean
@ConditionalOnMissingBean
public CanalBinlogEventProcessorFactory canalBinlogEventProcessorFactory() {
return InMemoryCanalBinlogEventProcessorFactory.of();
}
@Bean
@ConditionalOnMissingBean
public ModelTableMetadataManager modelTableMetadataManager(CanalFieldConverterFactory canalFieldConverterFactory) {
return InMemoryModelTableMetadataManager.of(canalFieldConverterFactory);
}
@Bean
@ConditionalOnMissingBean
public CanalFieldConverterFactory canalFieldConverterFactory() {
return InMemoryCanalFieldConverterFactory.of();
}
@Bean
@ConditionalOnMissingBean
public CanalBinLogEventParser canalBinLogEventParser() {
return DefaultCanalBinLogEventParser.of();
}
@Bean
@ConditionalOnMissingBean
public ParseResultInterceptorManager parseResultInterceptorManager(ModelTableMetadataManager modelTableMetadataManager) {
return InMemoryParseResultInterceptorManager.of(modelTableMetadataManager);
}
@Bean
@Primary
public CanalGlue canalGlue(CanalBinlogEventProcessorFactory canalBinlogEventProcessorFactory) {
return DefaultCanalGlue.of(canalBinlogEventProcessorFactory);
}
@Override
public void setBeanFactory(BeanFactory beanFactory) throws BeansException {
this.configurableListableBeanFactory = (ConfigurableListableBeanFactory) beanFactory;
}
@SuppressWarnings({"rawtypes", "unchecked"})
@Override
public void afterSingletonsInstantiated() {
ParseResultInterceptorManager parseResultInterceptorManager
= configurableListableBeanFactory.getBean(ParseResultInterceptorManager.class);
ModelTableMetadataManager modelTableMetadataManager
= configurableListableBeanFactory.getBean(ModelTableMetadataManager.class);
CanalBinlogEventProcessorFactory canalBinlogEventProcessorFactory
= configurableListableBeanFactory.getBean(CanalBinlogEventProcessorFactory.class);
CanalBinLogEventParser canalBinLogEventParser
= configurableListableBeanFactory.getBean(CanalBinLogEventParser.class);
Map<String, BaseParseResultInterceptor> interceptors
= configurableListableBeanFactory.getBeansOfType(BaseParseResultInterceptor.class);
interceptors.forEach((k, interceptor) -> parseResultInterceptorManager.registerParseResultInterceptor(interceptor));
Map<String, BaseCanalBinlogEventProcessor> processors
= configurableListableBeanFactory.getBeansOfType(BaseCanalBinlogEventProcessor.class);
processors.forEach((k, processor) -> processor.init(canalBinLogEventParser, modelTableMetadataManager,
canalBinlogEventProcessorFactory, parseResultInterceptorManager));
}
}
为了更好地让其他服务引入此配置类,可以使用spring.factories的特性。新建resources/META-INF/spring.factories文件,内容如下:
org.springframework.boot.autoconfigure.EnableAutoConfiguration=cn.throwx.canal.gule.config.CanalGlueAutoConfiguration
这样子通过引入spring-boot-starter-canal-glue就可以激活所有用到的组件并且初始化所有已经添加到Spring容器中的处理器。
CanalGlue开发
CanalGlue其实就是提供binlog事件字符串的处理入口,目前定义为一个接口:
public interface CanalGlue {
void process(String content);
}
此接口的实现DefaultCanalGlue也十分简单:
@RequiredArgsConstructor(access = AccessLevel.PUBLIC, staticName = "of")
public class DefaultCanalGlue implements CanalGlue {
private final CanalBinlogEventProcessorFactory canalBinlogEventProcessorFactory;
@Override
public void process(String content) {
CanalBinLogEvent event = SourceAdapterFacade.X.adapt(CanalBinLogEvent.class, content);
ModelTable modelTable = ModelTable.of(event.getDatabase(), event.getTable());
canalBinlogEventProcessorFactory.get(modelTable).forEach(processor -> processor.process(event));
}
}
使用源适配器把字符串转换为CanalBinLogEvent实例,再委托处理器工厂寻找对应的BaseCanalBinlogEventProcessor列表去处理输入的事件实例。
使用canal-glue
主要包括下面几个维度,都在canal-glue-example的test包下:
这里简单提一下在Spring体系下的使用方式,引入依赖spring-boot-starter-canal-glue:
<dependency>
<groupId>cn.throwx</groupId>
<artifactId>spring-boot-starter-canal-glue</artifactId>
<version>版本号</version>
</dependency>
编写一个实体或者DTO类OrderModel:
@Data
@CanalModel(database = "db_order_service", table = "t_order", fieldNamingPolicy = FieldNamingPolicy.LOWER_UNDERSCORE)
public static class OrderModel {
private Long id;
private String orderId;
private OffsetDateTime createTime;
private BigDecimal amount;
}
这里使用了@CanalModel注解绑定了数据库db_order_service和表t_order,属性名-列名映射策略为驼峰转小写下划线。接着定义一个处理器OrderProcessor和自定义异常处理器(可选,这里是为了模拟在处理事件的时候抛出自定义异常):
@Component
public class OrderProcessor extends BaseCanalBinlogEventProcessor<OrderModel> {
@Override
protected void processInsertInternal(CanalBinLogResult<OrderModel> result) {
OrderModel orderModel = result.getAfterData();
logger.info("接收到订单保存binlog,主键:{},模拟抛出异常...", orderModel.getId());
throw new RuntimeException(String.format("[id:%d]", orderModel.getId()));
}
@Override
protected ExceptionHandler exceptionHandler() {
return EXCEPTION_HANDLER;
}
/**
* 覆盖默认的ExceptionHandler.NO_OP
*/
private static final ExceptionHandler EXCEPTION_HANDLER = (event, throwable)
-> log.error("解析binlog事件出现异常,事件内容:{}", JSON.toJSONString(event), throwable);
}
假设一个写入订单数据的binlog事件如下:
{
"data": [
{
"id": "1",
"order_id": "10086",
"amount": "999.0",
"create_time": "2020-03-02 05:12:49"
}
],
"database": "db_order_service",
"es": 1583143969000,
"id": 3,
"isDdl": false,
"mysqlType": {
"id": "BIGINT",
"order_id": "VARCHAR(64)",
"amount": "DECIMAL(10,2)",
"create_time": "DATETIME"
},
"old": null,
"pkNames": [
"id"
],
"sql": "",
"sqlType": {
"id": -5,
"order_id": 12,
"amount": 3,
"create_time": 93
},
"table": "t_order",
"ts": 1583143969460,
"type": "INSERT"
}
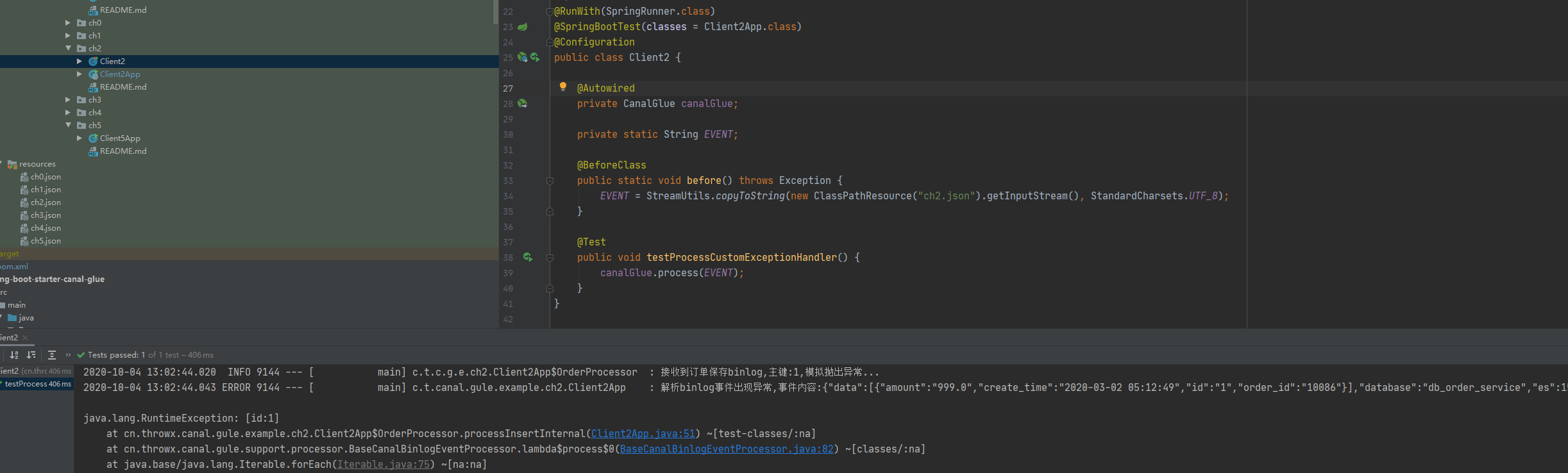
执行结果如下:
如果直接对接Canal投放到Kafka的Topic也很简单,配合Kafka的消费者使用的示例如下:
@Slf4j
@Component
@RequiredArgsConstructor
public class CanalEventListeners {
private final CanalGlue canalGlue;
@KafkaListener(
id = "${canal.event.order.listener.id:db-order-service-listener}",
topics = "db_order_service",
containerFactory = "kafkaListenerContainerFactory"
)
public void onCrmMessage(String content) {
canalGlue.process(content);
}
}
小结
笔者开发这个canal-glue的初衷是需要做一个极大提升效率的大型字符串转换器,因为刚刚接触到"小数据"领域,而且人手不足,而且需要处理下游大量的报表,因为不可能花大量人力在处理这些不停重复的模板化代码上。虽然整体设计还不是十分优雅,至少在提升开发效率这个点上,canal-glue做到了。
项目仓库:
Gitee:https://gitee.com/throwableDoge/canal-glue
仓库最新代码暂时放在develop分支。
(本文完 c-15-d e-a-20201005 鸽了快一个月)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号