Canal v1.1.4版本避坑指南
前提
在忍耐了很久之后,忍不住爆发了,在掘金发了条沸点(下班时发的):
这是一个令人悲伤的故事,这条情感爆发的沸点好像被屏蔽了,另外小水渠(Canal意为水道、管道)上线一段时间,不出坑的时候风平浪静,一旦出坑令人想屎。重点吐槽几点:
- 目前最新的
RELEASE版本为v1.1.4,发布于2019-9-2,快一年没更新了。 Issue里面堆积了十分多未处理或者没有回应的问题,有不少问题的年纪比较大。master分支经常提交异常的代码,构建不友好,因为v1.1.4比较多问题,也曾经想过用master代码手动构建,导入项目之后决定放弃,谁试试谁知道,可以尝试对比导入和构建MyBatis的源码。
这些都只是表象,下面聊聊踩过的坑。
解析线程阻塞问题
这个基本是每个使用Canal的开发者的必踩之坑。$CANAL_HOME/conf/canal.properties配置文件中存在一行注释掉的配置:canal.instance.parser.parallelThreadSize = 16。该配置用于指定解析器实例并发线程数,如果注释了会导致解析线程阻塞,得到的结果就是什么都不会发生。
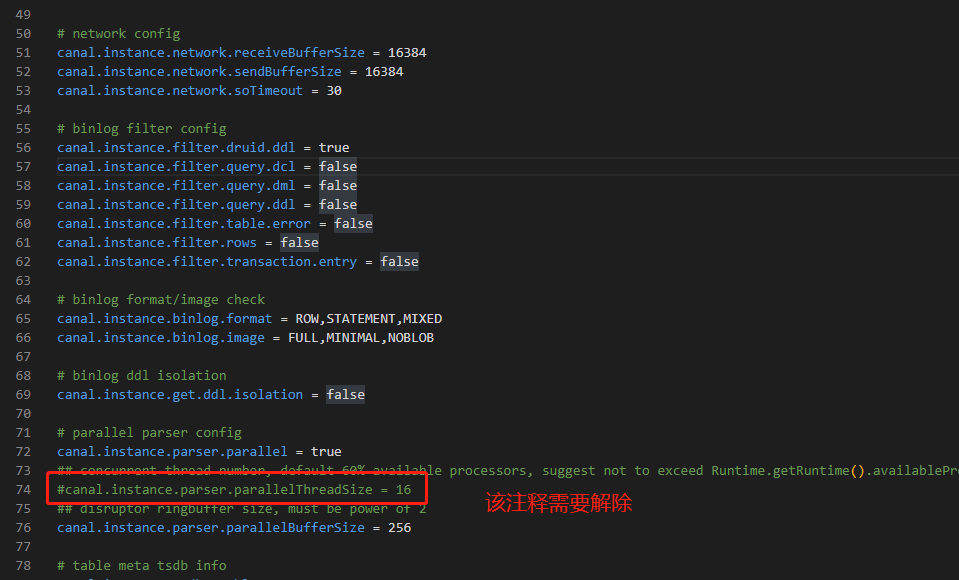
注释解除即可,建议使用默认值16。
表结构缓存异常阻塞问题
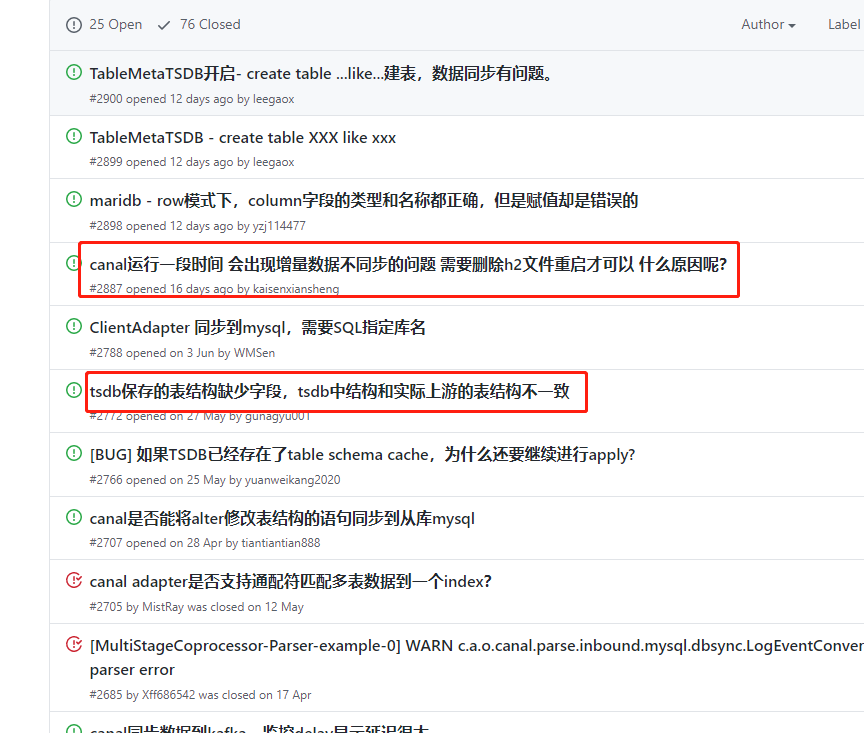
这是Issue里面很大部分提问者提到但是久未解决的问题,也就是表结构元数据的存储问题(配置项里面使用了tsdb也就是时序数据库的字眼,下面就称为tsdb功能)。

默认开启tsdb功能,也就是会通过h2数据库缓存解析的表结构,但是实际情况下,如果上游变更了表结构,h2数据库对应的缓存是不会更新的,这个时候一般会出现神奇的解析异常,异常的信息一般如下:
Caused by: com.alibaba.otter.canal.parse.exception.CanalParseException: column size is not match for table:数据库名称.表名称,新表结构的字段数量 vs 缓存表结构的字段数量;
该异常还会导致一个可怕的后果:解析线程被阻塞,也就是binlog事件不会再接收和解析。这个问题笔者也查看过很多Issue,大家都认为是一个严重的BUG,目前认为比较可行的解决方案是:禁用tsdb功能(真的够粗暴),也就是canal.instance.tsdb.enable设置为false。如果不禁用tsdb功能,一旦出现了该问题,必须要先停止Canal服务,接着删除$CANAL_HOME/conf/目标数据库实例标识/h2.mv.db文件,然后启动Canal服务。
因为这个比较坑的问题,笔者在生产禁用了tsdb功能,并且添加了DDL语句的处理逻辑,直接打到钉钉预警上并且@整个群的人。

每次看到这个预警都心惊胆战。
日志问题
如果刚好需要定位的binlog位点处于比较靠后的文件,文件数量比较多,会疯狂打印寻位的日志。之前尝试过重启一下子打印了几GB日志,超过99%是定位binlog文件和position的日志行。可以考虑通过修改$CANAL_HOME/conf/logback.xml(并不建议,不清楚源码容易造成其他新的问题)配置或者指定$CANAL_HOME/conf/目标数据库实例标识/instance.properties的下面几个属性手动定位解析的起点:
canal.instance.master.journal.name=binlog的文件名
canal.instance.master.position=binlog的文件中的位点
canal.instance.master.timestamp=时间戳
canal.instance.master.gtid=gtid的值
以上的手动定位解析的起点的属性需要在下次重启Canal之前更新或者注释掉,否则会造成重新解析或者找不到文件的严重后果!!!
反正每次重启Canal服务都惊心动魄,没有一个开源软件可以让人有这种感觉。因为生产的服务器磁盘不是很充足,选配的时候只买了100GB,而且考虑到这些日志本质上没有太大意义,于是只能定期上去删日志,前期是手动删,后来觉得麻烦写了个Shell脚本定时删除久远的日志文件。
云RDS MySQL的使用问题
如果刚好使用了阿里云的RDS MySQL,那么有可能会遭遇更大的坑。主要问题是:
RDS MySQL有磁盘空间优化规则,触发了规则会把binlog文件上传到OSS,然后删除本地的binlog文件。- 从
Canal的文档来看,会自动拉取OSS上的binlog文件进行解析,让使用者无感知,但是此功能有BUG,一直无法正常使用。 RDS MySQL是一个暗箱,出了问题只能通过MySQL的相关查询去定位问题,没有办法进去服务器查看真实的现场。
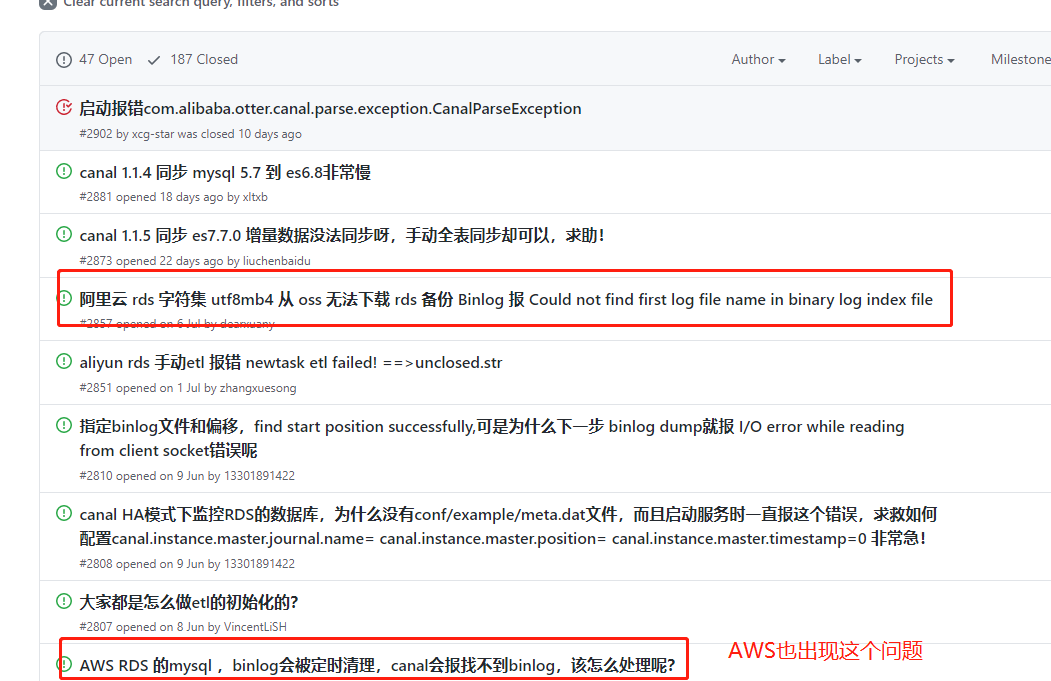
命中了这个问题,一般出现的异常是:
.................. sqlstate = HY000 errmsg = Could not find first log file name in binary log index file
可以基本确认这个功能是存在缺陷的,例如这里有个Issue-2596:
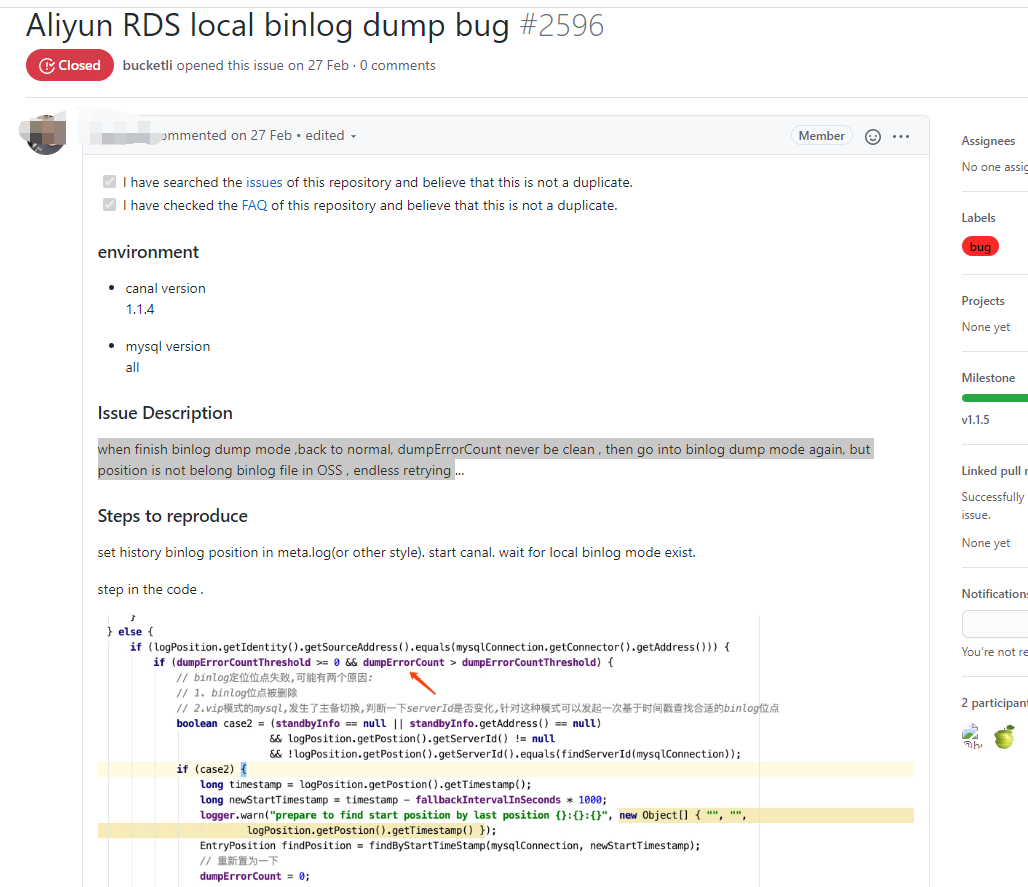
目前笔者的做法如下:
- 完全弃用
Canal拉取OSS上的binlog文件的功能。 RDS MySQL尽可能扩容一下磁盘,调整策略让尽可能多的binlog文件尽可能久地保留在本地,让它们被完全解析后再手动上传或者命中了过期规则后自动上传,这期间有很多东西需要额外收取费用,具体需要自行权衡。
读取和解析OSS上的binlog文件在目前(2020-08-05)的master分支上依然有BUG,想手动构建master分支的伙伴建议放弃幻想。
这个问题的严重后果是:有比较大的可能性导致某段binlog文件解析完全缺失,除非可以把binlog文件重新塞回去RDS MySQL里面,否则需要做上下游手动同步功能。
to be continue
除此之外,要注意Canal最好做主备部署,提交位点和集群管理建议使用Zookeeper,而服务模式(canal.serverMode,目前支持tcp、kafka和rocketmq)建议选用Kafka(master分支上有RabbitMQ的连接器支持,如果想尝鲜可以手动构建一下),并且每个节点的资源要求比较高,笔者生产上每个节点使用了2C8G低主频的ECS,感觉有点压不住,特别时重启实例的时候如果需要重新定位binlog位点,CPU在一段时间内使用率会飙高。
笔者发现了阿里云的DTS就是使用了Canal作为基础中间件进行数据同步的,说明它有被投产到实际应用场景中,真不希望它最终演变成废弃的KPI任务项目。不知道往后还会遇到多少问题,如果碰到了也会持续更新本避坑指南。
(本文完 c-2-d e-a-20200805)
![]()
这是公众号《Throwable》发布的原创文章,收录于专辑《架构与实战》。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号