

面经汇总
转载链接
一、Java
Java的优势
平台无关性、垃圾回收
Java有哪些特性,举个多态的例子。
封装、继承、多态
abstract interface区别
含有abstract修饰符的class即为抽象类,abstract类不能创建的实例对象。含有abstract方法的类必须定义为abstract class,abstract class类中的方法不必是抽象的。abstract class类中定义抽象方法必须在具体(Concrete)子类中实现,所以,不能有抽象构造方法或抽象静态方法。如果的子类没有实现抽象父类中的所有抽象方法,那么子类也必须定义为abstract类型。
接口(interface)可以说成是抽象类的一种特例,接口中的所有方法都必须是抽象的。接口中的方法定义默认为public abstract类型,接口中的成员变量类型默认为public static final。
下面比较一下两者的语法区别:
- 抽象类可以有构造方法,接口中不能有构造方法。
- 抽象类中可以有普通成员变量,接口中没有普通成员变量
- 抽象类中可以包含非抽象的普通方法,接口中的可以有非抽象方法,比如deaflut方法
- 抽象类中的抽象方法的访问类型可以是public,protected和(默认类型,虽然
eclipse下不报错,但应该也不行),但接口中的抽象方法只能是public类型的,并且默认即为public abstract类型。 - 抽象类中可以包含静态方法,接口中不能包含静态方法
- 抽象类和接口中都可以包含静态成员变量,抽象类中的静态成员变量的访问类型可以任意,但接口中定义的变量只能是public static final类型,并且默认即为public static final类型。
- 一个类可以实现多个接口,但只能继承一个抽象类。
有抽象方法一定是抽象类吗?抽象类一定有抽象方法吗?
有抽象方法不一定是抽象类,也可能是接口。抽象类不一定有抽象方法,可以有非抽象的普通方法。
Java的反射机制
在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为Java语言的反射机制。
反射的核心是JVM在运行时才动态加载类或调用方法/访问属性,它不需要事先知道运行对象是谁。
super()和this()能不能同时使用
不能同时使用,this和super不能同时出现在一个构造函数里面,因为this必然会调用其它的构造函数,其它的构造函数必然也会有super语句的存在,所以在同一个构造函数里面有相同的语句,就失去了语句的意义,编译器也不会通过。
hashcode,equals,Object的这两个方法默认返回什么?描述了一下为什么重写equals方法必须重写hashcode方法
默认的hashCode方法会利用对象的地址来计算hashcode值,不同对象的hashcode值是不一样的。
public boolean equals(Object obj) {
return (this == obj);
}可以看出Object类中的equals方法与“==”是等价的,也就是说判断对象的地址是否相等。Object类中的equals方法进行的是基于内存地址的比较。
一般对于存放到Set集合或者Map中键值对的元素,需要按需要重写hashCode与equals方法,以保证唯一性。
final
- final关键字可以用于成员变量、本地变量、方法以及类。
- final成员变量必须在声明的时候初始化或者在构造器中初始化,否则就会报编译错误。
- 你不能够对final变量再次赋值。
- 本地变量必须在声明时赋值。
- 在匿名类中所有变量都必须是final变量。
- final方法不能被重写。
- final类不能被继承。
- 接口中声明的所有变量本身是final的。
- final和abstract这两个关键字是反相关的,final类就不可能是abstract的。
- final方法在编译阶段绑定,称为静态绑定(static binding)。
- 没有在声明时初始化final变量的称为空白final变量(blank final variable),它们必须在构造器中初始化,或者调用this()初始化。不这么做的话,编译器会报错“final变量(变量名)需要进行初始化”。
- 将类、方法、变量声明为final能够提高性能,这样JVM就有机会进行估计,然后优化。
- 按照Java代码惯例,final变量就是常量,而且通常常量名要大写。
String,StringBuffer,StringBuilder区别
- String内容不可变,StringBuffer和StringBuilder内容可变;
- StringBuilder非线程安全(单线程使用),String与StringBuffer线程安全(多线程使用);
- 如果程序不是多线程的,那么使用StringBuilder效率高于StringBuffer。
String为什么不可变
public final class String
implements java.io.Serializable, Comparable<string>, CharSequence {
/** The value is used for character storage. */
private final char value[];
/** Cache the hash code for the string */
private int hash; // Default to 0</string>String 的底层实现是依靠 char[] 数组,既然依靠的是基础类型变量,那么他一定是可变的, String 之所以不可变,是因为 Java 的开发者通过技术实现,隔绝了使用者对 String 的底层数据的操作。
String,是否可以继承,“+”怎样实现
String不可以继承,因为String被final修饰,而final修饰的类是不能被继承的。
String为不可变的,每次String对象做累加时都会创建StringBuilder对象。
// 程序编译期即加载完成对象s1为"ab"
String s1 = "a" + "b";
// 这种方式,JVM会先创建一个StringBuilder,然后通过其append方法完成累加操作
String s1 = "a";
String s2 = "b";
String s3 = s1 + s2; // 等效于 String s3 = (new StringBuilder(s1)).append(s2).toString();字符串常量池
map、list、set的区别
List:
- 可以允许重复的对象。
- 可以插入多个null元素。
- 是一个有序容器,保持了每个元素的插入顺序,输出的顺序就是插入的顺序。
- 常用的实现类有 ArrayList、LinkedList 和 Vector。ArrayList 最为流行,它提供了使用索引的随意访问,而 LinkedList 则对于经常需要从 List中添加或删除元素的场合更为合适。
Set:
- 不允许重复对象
- 无序容器,你无法保证每个元素的存储顺序,TreeSet通过 Comparator 或者 Comparable 维护了一个排序顺序。
- 只允许一个 null 元素
- Set 接口最流行的几个实现类是 HashSet、LinkedHashSet 以及 TreeSet。最流行的是基于 HashMap 实现的 HashSet;TreeSet 还实现了 SortedSet 接口,因此 TreeSet 是一个根据其 compare() 和 compareTo() 的定义进行排序的有序容器。
Map:
- Map不是collection的子接口或者实现类。Map是一个接口。
- Map 的 每个 Entry 都持有两个对象,也就是一个键一个值,Map 可能会持有相同的值对象但键对象必须是唯一的。
- TreeMap 也通过 Comparator 或者 Comparable 维护了一个排序顺序。
- Map 里你可以拥有随意个 null 值但最多只能有一个 null 键。
- Map 接口最流行的几个实现类是 HashMap、LinkedHashMap、Hashtable 和 TreeMap。(HashMap、TreeMap最常用)
有没有有序的set?
有,LinkedHashSet和TreeSet
Set如何保证不重复?
HashSet中add()中调用了HashMap的put(),将一个key-value对放入HashMap中时,首先根据key的hashCode()返回值决定该Entry的存储位置,如果两个key的hash值相同,那么它们的存储位置相同。如果这个两个key的equals比较返回true。那么新添加的Entry的value会覆盖原来的Entry的value,key不会覆盖。因此,如果向HashSet中添加一个已经存在的元素,新添加的集合元素不会覆盖原来已有的集合元素。
说一说对Java io的理解
IO,其实意味着:数据不停地搬入搬出缓冲区而已(使用了缓冲区)。
nio与bio的了解以及说一下区别
BIO:同步阻塞式IO,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,当然可以通过线程池机制改善。
NIO:同步非阻塞式IO,服务器实现模式为一个请求一个线程,即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理。
Java并发的理解
Java是一种多线程编程语言,我们可以使用Java来开发多线程程序。 多线程程序包含两个或多个可同时运行的部分,每个部分可以同时处理不同的任务,从而能更好地利用可用资源,特别是当您的计算机有多个CPU时。多线程使您能够写入多个活动,可以在同一程序中同时进行操作处理。
死锁,死锁原因
两个或者多个线程之间相互等待,导致线程都无法执行,叫做线程死锁。
- 互斥条件:使用的资源是不能共享的。
- 不可抢占条件:线程持有一个资源并等待获取一个被其他线程持有的资源。
- 请求与保持条件:线程持有一个资源并等待获取一个被其他线程持有的资源。
- 循环等待条件:线程之间形成一种首尾相连的等待资源的关系。
wait和sleep的区别
-
wait和notify方法定义在Object类中,因此会被所有的类所继承。 这些方法都是final的,即它们都是不能被重写的,不能通过子类覆写去改变它们的行为。 而sleep方法是在Thread类中是由native修饰的,本地方法。
-
当线程调用了wait()方法时,它会释放掉对象的锁。
另一个会导致线程暂停的方法:Thread.sleep(),它会导致线程睡眠指定的毫秒数,但线程在睡眠的过程中是不会释放掉对象的锁的。 -
因为wait方法会释放锁,所以调用该方法时,当前的线程必须拥有当前对象的monitor,也即lock,就是锁。要确保调用wait()方法的时候拥有锁,即wait()方法的调用必须放在synchronized方法或synchronized块中。
ArrayList和LinkedList有什么区别?
- ArrayList是实现了基于动态数组的数据结构,LinkedList基于双向链表的数据结构。
- 对于随机访问get和set,ArrayList优于LinkedList,因为LinkedList要移动指针。
- 对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
HashMap 的原理,hashmap的扩容问题,为什么HashMap的初始容量会是16,为什么是2倍扩容,实现简单的 get/put操作;处理哈希冲突用的哪种方法(拉链),还知道什么处理哈希冲突的方法(开放地址检测),开放地址检测怎么实现的
从哈希表中删除一个元素,再加入元素时恰好与原来那个哈希冲突,这个元素会放在哪
HashMap、Hashtable、concurrenthashmap
HashTable为什么是线程安全的?
synchronized锁住了
HashMap,ConcurrentHashMap以及在什么情况下性能会不好
Thread状态有哪些
新建、就绪、运行、阻塞、死亡
多线程实现方法
- 继承Thread类创建线程类,重写run方法,run方法就是代表线程需要完成的任务,调用线程对象的start()来启动该线程,线程类已经继承了Thread类,所以不能再继承其他父类。
- 实现Runnable接口创建线程类,定义Runnable实现类,重写run方法
- 实现Callable接口,重写call()方法,call()作为线程的执行体,具有返回值
- 线程池,使用线程池产生线程对象java.util.concurrent.ExecutorService、java.util.concurrent.Executors;
Java如何实现线程安全
互斥同步:推荐使用 synchronized 关键字进行同步, 在 concurrent包中有ReentrantLock类, 实现效果差不多. 还是推荐原生态的synchronized.
非阻塞同步:需要硬件指令完成.常用的指令有:
Test-and-Set
Fetch-and-Increment
Swap
Compare-and-Swap (CAS)
Load-Linked/Store-Conditional (LL/SC)
典型的应用在 AtomicInteger 中
无同步方案:将变量保存在本地线程中,就不会出现多个线程并发的错误了。
java中主要使用的就是ThreadLocal这个类。
Synchronized和lock区别
- Lock提供了synchronized关键字所不具备的主要特性有:
- 尝试非阻塞地获取锁boolean tryLock():当前线程尝试获取锁,如果这一时刻没有被其他线程获取到,则成功获取并持有锁
- 能被中断地获取锁void lockInterruptibly():当获取到锁的线程被中断时,中断异常抛出同时会释放锁
- 超时获取锁boolean trylock(long time, TimeUnit unit):在指定截止时间之前获取锁,如果在截止时间仍旧无法获取锁,则返回
- synchronized是JVM提供的加锁,悲观锁;lock是Java语言实现的,而且是乐观锁。
- ReentrantLock是基于AQS实现的,由于AQS是基于FIFO队列的实现
Java中都有什么锁
重量级锁、显式锁、并发容器、并发同步器、CAS、volatile、AQS等
可重入锁的设计思路是什么
可重入公平锁获取流程
在获取锁的时候,如果当前线程之前已经获取到了锁,就会把state加1,在释放锁的时候会先减1,这样就保证了同一个锁可以被同一个线程获取多次,而不会出现死锁的情况。这就是ReentrantLock的可重入性。
对于非公平锁而言,调用lock方法后,会先尝试抢占锁,在各种判断的时候会先忽略等待队列,如果锁可用,就会直接抢占使用。
乐观锁和悲观锁
悲观锁:假定会发生并发冲突,则屏蔽一切可能违反数据完整性的操作
乐观锁:假定不会发生并发冲突,只在数据提交时检查是否违反了数据完整性(不能解决脏读问题)
juc包内有哪些类
CountDownLatch 同步计数器,主要用于线程间的控制,但计数无法被重置,如果需要重置计数,请考虑使用 CyclicBarrier 。
CAS如何实现
BlockQueue见过没?
(线程池的排队策略)
线程池原理
线程池的排队策略和拒绝策略的试用条件和具体内容。
线程池的类型,详细介绍cached和fixed
corePoolSize参数的意义
核心线程数
- 核心线程会一直存活,即使没有任务需要执行
- 当线程数小于核心线程数时,即使有线程空闲,线程池也会优先创建新线程处理
- 设置allowCoreThreadTimeout=true(默认false)时,核心线程会超时关闭
线程池新任务到达时会先使用空闲线程还是加入阻塞队列
Java并发包里面的CountdownLatch怎么使用
这个类是一个同步计数器,主要用于线程间的控制,当CountDownLatch的count计数>0时,await()会造成阻塞,直到count变为0,await()结束阻塞,使用countDown()会让count减1。CountDownLatch的构造函数可以设置count值,当count=1时,它的作用类似于wait()和notify()的作用。如果我想让其他线程执行完指定程序,其他所有程序都执行结束后我再执行,这时可以用CountDownLatch,但计数无法被重置,如果需要重置计数,请考虑使用 CyclicBarrier 。
volatile和synchronized区别
- volatile是变量修饰符,其修饰的变量具有可见性,Java的做法是将该变量的操作放在寄存器或者CPU缓存上进行,之后才会同步到主存,使用volatile修饰符的变量是直接读写主存,volatile不保证原子性,同时volatile禁止指令重排
- synchronized作用于一段代码或者方法,保证可见性,又保证原子性,可见性是synchronized或者Lock能保证通一个时刻只有一个线程获取锁然后执行不同代码,并且在释放锁之前会对变量的修改刷新到主存中去,原子性是指要么不执行,要执行就执行到底
线程池使用时一般要考虑哪些问题
一般线程和守护线程的区别
java中的线程分为两种:守护线程(Daemon)和用户线程(User)。
任何线程都可以设置为守护线程和用户线程,通过方法Thread.setDaemon(bool on);true则把该线程设置为守护线程,反之则为用户线程。Thread.setDaemon()必须在Thread.start()之前调用,否则运行时会抛出异常。
唯一的区别是判断虚拟机(JVM)何时离开,Daemon是为其他线程提供服务,如果全部的User Thread已经撤离,Daemon 没有可服务的线程,JVM撤离。也可以理解为守护线程是JVM自动创建的线程(但不一定),用户线程是程序创建的线程;比如JVM的垃圾回收线程是一个守护线程,当所有线程已经撤离,不再产生垃圾,守护线程自然就没事可干了,当垃圾回收线程是Java虚拟机上仅剩的线程时,Java虚拟机会自动离开。
一致性Hash原理,实现负载均衡
异常
servlet流程
forward redirect 二次请求
序列化,以及json传输
tomcat均衡方式
netty
二、JVM
JVM内存划分
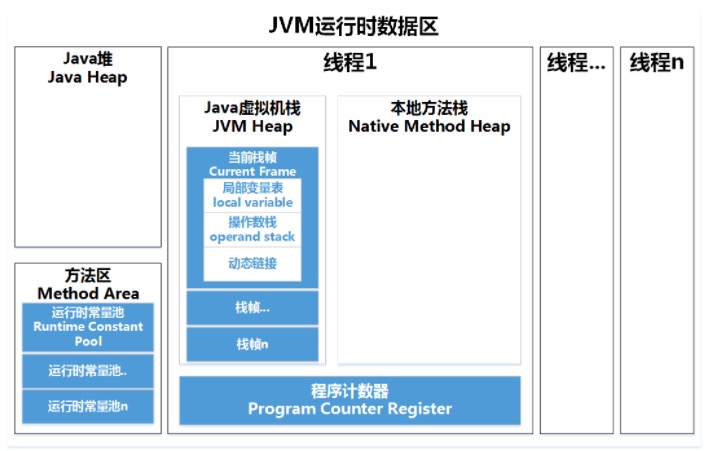
程序计数器:记录正在执行的虚拟机字节码指令的地址(如果正在执行的是本地方法则为空)。
Java虚拟机栈:每个 Java 方法在执行的同时会创建一个栈帧用于存储局部变量表、操作数栈、常量池引用等信息。每一个方法从调用直至执行完成的过程,就对应着一个栈帧在 Java 虚拟机栈中入栈和出栈的过程。
本地方法栈:与 Java 虚拟机栈类似,它们之间的区别只不过是本地方法栈为本地方法服务。
Java堆:几乎所有对象实例都在这里分配内存。是垃圾收集的主要区域("GC 堆"),虚拟机把 Java 堆分成以下三块:
- 新生代
- 老年代
- 永久代
新生代又可细分为Eden空间、From Survivor空间、To Survivor空间,默认比例为8:1:1。
方法区:方法区(Method Area)与Java堆一样,是各个线程共享的内存区域。Object Class Data(类定义数据)是存储在方法区的,此外,常量、静态变量、JIT编译后的代码也存储在方法区。
运行时常量池:运行时常量池是方法区的一部分。Class 文件中的常量池(编译器生成的各种字面量和符号引用)会在类加载后被放入这个区域。除了在编译期生成的常量,还允许动态生成,例如 String 类的 intern()。这部分常量也会被放入运行时常量池。
直接内存:直接内存(Direct Memory)并不是虚拟机运行时数据区的一部分,也不是Java虚拟机规范中定义的内存区域,但是这部分内存也被频繁地使用,而且也可能导致OutOfMemoryError 异常出现。避免在Java堆和Native堆中来回复制数据。
GC
垃圾回收器
Java对象头
HotSpot虚拟机中,对象在内存中的布局分为三块区域:对象头、实例数据和对齐填充。
对象头包括两部分:Mark Word 和 类型指针。
-
Mark Word:Mark Word用于存储对象自身的运行时数据,如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等等,占用内存大小与虚拟机位长一致。
-
类型指针:类型指针指向对象的类元数据,虚拟机通过这个指针确定该对象是哪个类的实例。
内存泄漏
类加载过程
双亲委派模型,为什么要使用双亲委派模型
Java虚拟机的一些参数配置
为什么jvm调优经常会将-Xms和-Xmx参数设置成一样
三、数据结构与算法
常见的排序算法时间复杂度
快排算法 写代码
/**
* 快速排序
*
* @param array
* @param _left
* @param _right
*/
private static void quickSort(int[] array, int _left, int _right) {
int left = _left;//
int right = _right;
int pivot;//基准线
if (left < right) {
pivot = array[left];
while (left != right) {
//从右往左找到比基准线小的数
while (left < right && pivot <= array[right]) {
right--;
}
//将右边比基准线小的数换到左边
array[left] = array[right];
//从左往右找到比基准线大的数
while (left < right && pivot >= array[left]) {
left++;
}
//将左边比基准线大的数换到右边
array[right] = array[left];
}
//此时left和right指向同一位置
array[left] = pivot;
quickSort(array, _left, left - 1);
quickSort(array, left + 1, _right);
}
}堆排序怎么实现
链表,数组的优缺点,应用场景,查找元素的复杂度
入栈出栈的时间复杂度,链表插入和删除的时间复杂度
如何用LinkedList实现堆栈操作
Arraylist如何实现排序
利用数组,实现一个循环队列类
两个有序数组,有相同的元素,找出来
二叉树怎么实现的
二叉树前中后序遍历 深度 广度
二叉树深度
递归
public int TreeDepth(TreeNode root) {
if (root == null) {
return 0;
}
return Math.max(TreeDepth(root.left) + 1, TreeDepth(root.right) + 1);
}非递归,层次遍历
public int TreeDepth_2(TreeNode root) {
if (root == null) {
return 0;
}
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
int start = 0;
int end = 1;
int depth = 0;
while (!queue.isEmpty()) {
TreeNode temp = queue.poll();
start++;
if (temp.left != null) {
queue.offer(temp.left);
}
if (temp.right != null) {
queue.offer(temp.right);
}
if (start == end) {
start = 0;
end = queue.size();
depth++;
}
}
return depth;
}层序遍历二叉树
- 思路:
- 访问根节点,并将根节点入队。
- 当队列不空的时候,重复以下操作。
- 1、弹出一个元素。作为当前的根节点。
- 2、如果根节点有左孩子,访问左孩子,并将左孩子入队。
- 3、如果根节点有右孩子,访问右孩子,并将右孩子入队。
public void levelOrder(TreeNode root) {
//使用队列,先进先出
Queue<TreeNode> queue = new LinkedList<>();
queue.add(root);
while (!queue.isEmpty()) {
TreeNode temp = queue.poll();
System.out.print(temp.val + " ");
if (temp.left != null) {
queue.offer(temp.left);
}
if (temp.right != null) {
queue.offer(temp.right);
}
}
}树的中序遍历,除了递归和栈还有什么实现方式
二叉搜索树转换成一个排好序的双向链表
判断平衡二叉树
从下往上遍历,如果子树是平衡二叉树,则返回子树高度,否则返回-1
public boolean IsBalanced_Solution(TreeNode root) {
return MaxDepth(root) != -1;
}
public int MaxDepth(TreeNode root) {
if (root == null) {
return 0;
}
int leftHeight = MaxDepth(root.left);
if (leftHeight == -1) {
return -1;
}
int rightHeight = MaxDepth(root.right);
if (rightHeight == -1) {
return -1;
}
return Math.abs(leftHeight - rightHeight) > 1 ? -1 : 1 + Math.max(leftHeight, rightHeight);
}给定一个2叉树,打印每一层最右边的结点
一棵普通树(非二叉搜索树),找出一条路径和最大
一棵树,求所有路径之和
最长公共子序列
反转链表
将当前节点和下一节点保存起来,然后将当前节点反转。
public ListNode ReverseList(ListNode head) {
//head为当前节点,如果当前节点为空的话,那就什么也不做,直接返回null
ListNode pre = null;//pre为当前节点的前一节点
ListNode next = null;//next为当前节点的下一节点
//需要pre和next的目的是让当前节点从pre.head.next1.next2变成pre<-head next1.next2
//即pre让节点可以反转所指方向,但反转之后如果不用next节点保存next1节点的话,此单链表就此断开了
//所以需要用到pre和next两个节点
//1.2.3.4.5
//1<-2<-3 4.5
//做循环,如果当前节点不为空的话,始终执行此循环,此循环的目的就是让当前节点从指向next到指向pre
while (head != null) {
//先用next保存head的下一个节点的信息,保证单链表不会因为失去head节点的原next节点而就此断裂
next = head.next;
//保存完next,就可以让head从指向next变成指向pre了
head.next = pre;
//head指向pre后,就继续依次反转下一个节点
//让pre,head,next依次向后移动一个节点,继续下一次的指针反转
pre = head;
head = next;
}
//如果head为null的时候,pre就为最后一个节点了,但是链表已经反转完毕,pre就是反转后链表的第一个节点
//直接输出pre就是我们想要得到的反转后的链表
return pre;
}利用递归走到链表的末端,然后再更新每一个节点的next值 ,实现链表的反转。
public ListNode ReverseList(ListNode head) {
//如果链表为空或者链表中只有一个元素
if (head == null || head.next == null) return head;
//先递归找到到链表的末端结点,从后依次反转整个链表
ListNode reverseHead = ReverseList(head.next);
//再将当前节点设置为后面节点的后续节点
head.next.next = head;
head.next = null;
return reverseHead;
}判断一个数是不是丑数
找出一个字符串中字符连续相同的最长子串,如aabbccc,结果就是ccc
蓄水池抽样算法
寻找一个字符串中第一个只出现一次的字符
用LinkedHashMap记录字符出现的次数
public Character firstNotRepeating(String str){
if(str == null)
return null;
char[] strChar = str.toCharArray();
LinkedHashMap<Character,Integer> hash = new LinkedHashMap<Character,Integer>();
for(char item:strChar){
if(hash.containsKey(item))
hash.put(item, hash.get(item)+1);
else
hash.put(item, 1);
}
for(char key:hash.keySet())
{
if(hash.get(key)== 1)
return key;
}
return null;
}给定一个数组,里面只有一个数出现了一次,其他都出现了两次。怎么得到这个出现了一次的数?
利用HashSet的元素不能重复,如果有重复的元素,则删除重复元素,如果没有则添加,最后剩下的就是只出现一次的元素
public void FindNumsAppearOnce(int[] array, int num[]) {
HashSet<Integer> set = new HashSet<>();
for (int i = 0; i < array.length; i++) {
if (!set.add(array[i])) {
set.remove(array[i]);
}
}
Iterator<Integer> iterator = set.iterator();
num[0] = iterator.next();
}用HashMap<K,V>保存数组的值,key为数组值,value为布尔型表示是否有重复
public void FindNumsAppearOnce_2(int[] array, int num[]) {
HashMap<Integer, Boolean> map = new HashMap<>();
for (int i = 0; i < array.length; i++) {
if (!map.containsKey(array[i])) {
map.put(array[i], true);
} else {
map.put(array[i], false);
}
}
for (int i = 0; i < array.length; i++) {
if (map.get(array[i])) {
num[0] = array[i];
}
}
}给定一个数组,如果有两个不同数的出现了一次,其他出现了两次,怎么得到这两个数?
利用HashSet的元素不能重复,如果有重复的元素,则删除重复元素,如果没有则添加,最后剩下的就是只出现一次的元素
public void FindNumsAppearOnce(int[] array, int num1[], int num2[]) {
HashSet<Integer> set = new HashSet<>();
for (int i = 0; i < array.length; i++) {
if (!set.add(array[i])) {
set.remove(array[i]);
}
}
Iterator<Integer> iterator = set.iterator();
num1[0] = iterator.next();
num2[0] = iterator.next();
}用HashMap<K,V>保存数组的值,key为数组值,value为布尔型表示是否有重复
public void FindNumsAppearOnce_2(int[] array, int num1[], int num2[]) {
HashMap<Integer, Boolean> map = new HashMap<>();
for (int i = 0; i < array.length; i++) {
if (!map.containsKey(array[i])) {
map.put(array[i], true);
} else {
map.put(array[i], false);
}
}
int index = 0;//区分是第几个不重复的值
for (int i = 0; i < array.length; i++) {
if (map.get(array[i])) {
index++;
if (index == 1) {
num1[0] = array[i];
} else {
num2[0] = array[i];
}
}
}
}位运算 异或,两个不相等的元素在位级表示上必定会有一位存在不同。
public void FindNumsAppearOnce_3(int[] array, int num1[], int num2[]) {
int diff = 0;
for (int num : array) diff ^= num;
// 得到最右一位
diff &= -diff;
for (int num : array) {
if ((num & diff) == 0) num1[0] ^= num;
else num2[0] ^= num;
}
}海量数据topk问题
四、操作系统
进程和线程区别
进程:进程是操作系统资源分配的基本单位。每个进程都有独立的代码和数据空间(进程上下文),进程间的切换会有较大的开销,一个进程包含1–n个线程。
线程:线程是CPU独立调度的基本单位。同一类线程共享代码和数据空间,每个线程有独立的运行栈和程序计数器(PC),线程切换开销小。
线程和进程的生命周期:新建、就绪、运行、阻塞、死亡
不同进程打开了同一个文件,那么这两个进程得到的文件描述符(fd)相同吗?
不同进程打开同一个文件,文件描述符可能相同可能不同。
操作系统如何实现输出
进程通信
- 消息传递
- 管道
- 消息队列
- 套接字
- 共享内存
五、网络
OSI七层网络模型中,你对哪层最了解?了解哪些协议?做过web开发?

| OSI七层网络模型 | 对应网络协议 |
|---|---|
| 应用层 | HTTP、TFTP、FTP、NFS、WAIS、SMTP |
| 表示层 | Telnet、Rlogin、SNMP、Gopher |
| 会话层 | SMTP、DNS |
| 传输层 | TCP、UDP |
| 网络层 | IP、ICMP、ARP、RARP、AKP、UUCP |
| 数据链路层 | FDDI、Ethernet、Arpanet、PDN、SLIP、PPP |
| 物理层 | IEEE 802.1A、IEEE 802.2到IEEE 802.11 |
HTTP 0.9/1.0/1.1/2
HTTP/0.9只支持客户端发送Get请求,且不支持请求头。HTTP具有典型的无状态性。
HTTP/1.0在HTTP/0.9的基础上支持客户端发送POST、HEAD。HTTP 1.0需要使用keep-alive参数来告知服务器端要建立一个长连接,但默认是短连接。
HTTP 和 HTTPS 有什么区别?
HTTP(Hypertext Transfer Protocol)超文本传输协议是用来在Internet上传送超文本的传送协议,它可以使浏览器更加高效,使网络传输减少。但HTTP协议采用明文传输信息,存在信息窃听、信息篡改和信息劫持的风险。
HTTPS(Secure Hypertext Transfer Protocol) 安全超文本传输协议是一个安全的通信通道,它基于HTTP开发,用于在客户计算机和服务器之间交换信息。HTTPS使用安全套接字层(SSL)进行信息交换,简单来说HTTPS是HTTP的安全版,是使用TLS/SSL加密的HTTP协议。
HTTPS和HTTP的区别主要如下:
- https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。
- http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
- http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
- http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全.
知道 HTTPS 通信过程吗?
- 客户端发送请求到服务器端
- 服务器端返回证书和公开密钥,公开密钥作为证书的一部分而存在
- 客户端验证证书和公开密钥的有效性,如果有效,则生成共享密钥并使用公开密钥加密发送到服务器端
- 服务器端使用私有密钥解密数据,并使用收到的共享密钥加密数据,发送到客户端
- 客户端使用共享密钥解密数据
- SSL加密建立
TCP三次握手
所谓三次握手(Three-Way Handshake)即建立TCP连接,就是指建立一个TCP连接时,需要客户端和服务端总共发送3个包以确认连接的建立。整个流程如下图所示:

- 第一次握手:Client将标志位SYN置为1,随机产生一个值seq=J,并将该数据包发送给Server,Client进入SYN_SENT状态,等待Server确认。
- 第二次握手:Server收到数据包后由标志位SYN=1知道Client请求建立连接,Server将标志位SYN和ACK都置为1,ack=J+1,随机产生一个值seq=K,并将该数据包发送给Client以确认连接请求,Server进入SYN_RCVD状态。
- 第三次握手:Client收到确认后,检查ack是否为J+1,ACK是否为1,如果正确则将标志位ACK置为1,ack=K+1,并将该数据包发送给Server,Server检查ack是否为K+1,ACK是否为1,如果正确则连接建立成功,Client和Server进入ESTABLISHED状态,完成三次握手,随后Client与Server之间可以开始传输数据了。
为什么三次握手和四次挥手
Server在LISTEN状态下,收到建立连接请求的SYN报文后,可以直接把ACK和SYN放在一个报文里发送给Client。而关闭连接时,当收到对方的FIN报文时,仅仅表示对方不再发送数据了但是还能接收数据,己方也未必全部数据都发送给对方了,所以己方可以立即close,也可以发送一些数据给对方后,再发送FIN报文给对方来表示同意现在关闭连接,因此,己方ACK和FIN一般都会分开发送。
TCP与HTTP有什么关系
http是要基于TCP连接基础上的,简单的说,TCP就是单纯建立连接,不涉及任何我们需要请求的实际数据,简单的传输。http是用来收发数据,即实际应用上的。
Tcp连接4次挥手的原因。Time_wait等待超时了会怎样?
Server在LISTEN状态下,收到建立连接请求的SYN报文后,可以直接把ACK和SYN放在一个报文里发送给Client。而关闭连接时,当收到对方的FIN报文时,仅仅表示对方不再发送数据了但是还能接收数据,己方也未必全部数据都发送给对方了,所以己方可以立即close,也可以发送一些数据给对方后,再发送FIN报文给对方来表示同意现在关闭连接,因此,己方ACK和FIN一般都会分开发送。
SSL 握手
- 客户端发送随机数1,支持的加密方法(如RSA公钥加密)
- 服务端发送随机数2,和服务器公钥,并确认加密方法
- 客户端发送用服务器公钥加密的随机数3
- 服务器用私钥解密这个随机数3,用加密方法计算生成对称加密的密钥给客户端,
- 接下来的报文都用双方协定好的加密方法和密钥,进行加密
session/cookie
常用的会话跟踪技术是Cookie与Session。Cookie通过在客户端记录信息确定用户身份,Session通过在服务器端记录信息确定用户身份。
联系:
- Cookie与Session都是用来跟踪浏览器用户身份的会话方式。
区别:
- Cookie数据存放在客户的浏览器上,Session数据放在服务器上。
- Cookie不是很安全,别人可以分析存放在本地的Cookie并进行Cookie欺骗,如果主要考虑到安全应当使用加密的Cookie或者Session。
- Session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能,如果主要考虑到减轻服务器性能方面,应当使用Cookie。
- 单个Cookie在客户端的限制是4K,很多浏览器都限制一个站点最多保存20个Cookie。
当你在浏览器地址栏输入一个URL后回车,将会发生的事情?
域名解析 --> 发起TCP的3次握手 --> 建立TCP连接后发起http请求 --> 服务器响应http请求,浏览器得到html代码 --> 浏览器解析html代码,并请求html代码中的资源(如js、css、图片等) --> 浏览器对页面进行渲染呈现给用户
DNS域名解析过程
浏览器缓存 --> 系统缓存 --> 路由器缓存 --> ISP(互联网服务提供商)DNS缓存 --> 根域名服务器 --> 顶级域名服务器 --> 主域名服务器 --> 保存结果至缓存
ping工作原理
Ping程序的实质是利用了ICMP请求回显和回显应答报文,但ARP请求和应答报文也在其中起了非常重要的作用。
Get和Post请求
GET 请求:
- GET 请求可被缓存
- GET 请求保留在浏览器历史记录中
- GET 请求可被收藏为书签
- GET 请求不应在处理敏感数据时使用
- GET 请求有长度限制
- GET 请求只应当用于取回数据
POST 请求 :
- POST 请求不会被缓存
- POST 请求不会保留在浏览器历史记录中
- POST 不能被收藏为书签
- POST 请求对数据长度没有要求
HTTP状态码
- 1XX 信息,服务器收到请求,需要请求者继续执行操作
- 2XX 成功,操作被成功接收并处理
- 3XX 重定向,需要进一步的操作以完成请求
- 4XX 客户端错误,请求包含语法错误或无法完成请求
- 5XX 服务器错误,服务器在处理请求的过程中发生了错误
六、数据库
数据库事务的四个隔离级别,MySql在哪一个级别
- 未提交读(READ UNCOMMITTED):事务中的修改,即使没有提交,对其它事务也是可见的。最低级别,任何情况都无法保证。
- 提交读(READ COMMITTED):一个事务只能读取已经提交的事务所做的修改。换句话说,一个事务所做的修改在提交之前对其它事务是不可见的。可避免脏读的发生。
- 可重复读(REPEATABLE READ):保证在同一个事务中多次读取同样数据的结果是一样的。可避免脏读、不可重复读的发生。
- 可串行化(SERIALIXABLE):强制事务串行执行。可避免脏读、不可重复读、幻读的发生。
在MySQL数据库中,支持上面四种隔离级别,默认的为REPEATABLE READ(可重复读)。
数据库死锁/如何防止
mysql索引,索引机制,聚集索引和非聚集索引,如何创建索引,实现原理,建立准则,优缺点,注意事项,
索引在什么情况下失效
说一下对B+树的了解
innodb建立的索引,如果字段重复率很高索引,索引是什么样,查找效率如何
innodb在插入的时候,是否会给行上锁
说一下innodb的默认隔离级别
数据库设计(订单、购物车和商品)
sql中join的几种操作的区别
left join / inner join / right join
union和union all的区别,谁的效率更高
用distinct和用group by去重,谁的效率更高
sql中的优化,怎么提高查询效率
缓存的穿透和雪崩,解决办法
redis的排序算法?
redis集群
redis过期策略
Redis如何解决key冲突
redis数据类型+redis是单线程的么,为什么呢
redis和memcache区别
redis与mysql的区别以及优缺点
回答存储机制以及持久化
七、设计模式
单例模式里面的双重检查锁定的原理,以及为什么使用volatile
确保一个类最多只有一个实例,并提供一个全局访问点。
public class Singleton {
private volatile static Singleton instance = null;
private Singleton() {
}
/**
* 当第一次调用getInstance()方法时,instance为空,同步操作,保证多线程实例唯一
* 当第一次后调用getInstance()方法时,instance不为空,不进入同步代码块,减少了不必要的同步
*/
public static Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}生产者消费者
工厂,说下原理和应用
策略模式
适配器模式
装饰模式
代理模式
线程池使用了什么设计模式
单例模式
JDK中哪些体现了命令模式
八、框架
介绍下SpringBoot
SpringBoot就是对各种框架的整合,让框架集成在一起更加简单,简化了开发过程、配置过程、部署过程、监控过程。
Spring IOC AOP
IOC:控制反转也叫依赖注入,IOC利用java反射机制。所谓控制反转是指,本来被调用者的实例是有调用者来创建的,这样的缺点是耦合性太强,IOC则是统一交给spring来管理创建,将对象交给容器管理,你只需要在spring配置文件总配置相应的bean,以及设置相关的属性,让spring容器来生成类的实例对象以及管理对象。在spring容器启动的时候,spring会把你在配置文件中配置的bean都初始化好,然后在你需要调用的时候,就把它已经初始化好的那些bean分配给你需要调用这些bean的类。
AOP是对OOP的补充和完善。AOP利用的是代理,分为CGLIB动态代理和JDK动态代理。OOP引入封装、继承和多态性等概念来建立一种对象层次结构。OOP编程中,会有大量的重复代码。而AOP则是将这些与业务无关的重复代码抽取出来,然后再嵌入到业务代码当中。实现AOP的技术,主要分为两大类:一是采用动态代理技术,利用截取消息的方式,对该消息进行装饰,以取代原有对象行为的执行;二是采用静态织入的方式,引入特定的语法创建“方面”,从而使得编译器可以在编译期间织入有关“方面”的代码,属于静态代理。
Spring IOC有哪些好处
降低了组件之间的耦合性 ,实现了软件各层之间的解耦
IOC涉及到的设计模式
工厂模式
AOP的应用场景,具体介绍,配置文件中需要写什么?具体注解需要写啥?
权限管理、日志、事务管理等。
切面通过带有@Aspect注解的类实现。
Spring中定义了四个advice:BeforeAdvice, AfterAdvice, ThrowAdvice和DynamicIntroductionAdvice。
Before Advice:在方法执行前执行。
AfterAdvice:在方法执行之后调用的通知,无论方法执行是否成功。
After ReturningAdvice:在方法执行后返回一个结果后执行。
After ThrowingAdvice:在方法执行过程中抛出异常的时候执行。
说说静态代理和动态代理
代理分为静态代理和动态代理,静态代理是在编译时就将接口、实现类、代理类全部手动完成,但如果我们需要很多的代理,每一个都这么手动的去创建实属浪费时间,而且会有大量的重复代码。动态代理可以在程序运行期间根据需要动态的创建代理类及其实例,来完成具体的功能。
Spring事务传播,隔离级别
- Spring事务管理高层抽象主要包括3个接口:
- PlatformTransactionManager(事务管理器)
- TransactionDefinition(事务定义信息,包含隔离级别、事务传播行为、超时、只读)
- TransactionStatus(事务具体运行状态)
- Spring事务的本质其实就是数据库对事务的支持
- 获取连接->开启事务 -> 执行CRUD -> 提交事务/回滚事务 -> 关闭连接
Spring bean初始化过程
Spring如何生成一个Bean?配置文件写完了之后又怎么生成?
Mybatis 传参
- map
- @Param注解
- JavaBean
Mybatis中 # 和 $ 区别
-
相当于对数据加上双引号, $ 相当于直接显示数据
-
方式能够很大程度防止sql注入
Mybatis缓存
SpringMVC的运行流程
- 客户端发送HTTP请求到服务器
- SpringMVC的核心DispatcherServlet将请求交给HandlerMapping处理
- HandlerMapping通过查询机制找到处理当前请求的Handler
- DispatcherServlet将请求交给这个Handler处理
- Handler处理完成后返回一个ModleAndView对象,这个对象包含视图逻辑名和数据对象
- 返回的视图逻辑名会通过视图解析器解析成真正的视图,并交给DispatcherServlet处理
- DispatcherServlet将请求分派给真正的视图对象,并反映到客户端
说几个SpringMVC的几个注解,都是干啥的?
@Controller:用于标记在一个类上,使用它标记的类就是一个SpringMVC Controller 对象。
@RequestMapping:是一个用来处理请求地址映射的注解,可用于类或方法上。用于类上,表示类中的所有响应请求的方法都是以该地址作为父路径。
@Resource和@Autowired:@Resource和@Autowired都是做bean的注入时使用,其实@Resource并不是Spring的注解,它的包是javax.annotation.Resource,需要导入,但是Spring支持该注解的注入。
@ResponseBody:返回的数据不是html标签的页面,而是其他某种格式的数据时(如json、xml等)使用。
@Repository:DAO层
@Service:服务层
@autireware和@resource的区别
@Autowired注解是按类型装配依赖对象,默认情况下它要求依赖对象必须存在,如果允许null值,可以设置它required属性为false。
@Resource注解和@Autowired一样,也可以标注在字段或属性的setter方法上,但它默认按名称装配。名称可以通过@Resource的name属性指定,如果没有指定name属性,当注解标注在字段上,即默认取字段的名称作为bean名称寻找依赖对象,当注解标注在属性的setter方法上,即默认取属性名作为bean名称寻找依赖对象。
@Resources按名称,是JDK的,@Autowired按类型,是Spring的。
@PathVariable是干啥的?
@PathVariable是用来对指定请求的URL路径里面的变量。
说说filter、servlet、listener。
Listener我是这样理解他的,他是一种观察者模式的实现。
Filter的使用户可以改变一 个request或修改一个response。 Filter 不是一个servlet,它不能产生一个response,但是他能够在一个request到达servlet之前预先处理request,也可以在一个响应离开 servlet时处理response。
消息队列了解吗?
通俗的说,就是一个容器,把消息丢进去,不需要立即处理。然后有个程序去从容器里面把消息一条条读出来处理。
九、分布式
Raft协议的leader选举,正常情况下,网络抖动造成follower发起leader选举,且该follower的Term比现有leader高。集群中所有结点的日志信息当前一致,这种情况下会选举成功吗?
分布式框架知道哪些?
dubbo
dubbo怎么用的,有没有参与部署
分布式缓存的理解
十、Linux
linux查询Java进程
ps -ef | grep java
linux查看内存占用情况
- top命令提供了实时的运行中的程序的资源使用统计。你可以根据内存的使用和大小来进行排序。
- vmstat命令显示实时的和平均的统计,覆盖CPU、内存、I/O等内容。例如内存情况,不仅显示物理内存,也统计虚拟内存。
十一、杂项
设计一个秒杀系统,如何保证不超卖,还要保证服务可用
如何设计一个定时器定时完成某个任务?
如何保证集群环境下抢购的并发安全?
Java中你擅长的地方
多线程,JVM
如果学习一门技术,你会怎么学习
书籍+博客+视频
对国内互联网公司目前的开源生态有没有什么了解
举出三个以上的国内开源框架,越多越好,dubbo、fastjson、sharding-jdbc、Elastic-job...
你对京东的看法
电商,突出质量
说出三个京东不如淘宝或者天猫的地方
淘宝是C2C,京东和天猫是B2C,淘宝门槛低,种类,国际市场布局
看过啥书。
深入理解Java虚拟机&HEAD FIRST设计模式&高性能MYSQL&Java并发编程实战,看博客比较多,感觉博客更有针对性

 浙公网安备 33010602011771号
浙公网安备 33010602011771号