
《Windows Azure Platform 系列文章目录》
昨天研究了一个CosmosDB分页的问题。
我们知道,在访问CosmosDB的时候,所有对CosmosDB操作的成本,将由Azure CosmosDB的Request Unit (RU)来表示。 读取 1-KB 项的成本为 1 个请求单位 (RU)
假设我们进行一个查询,如果查询的结果很多,数据量很大的话,则会造成RU消耗很多,理所当然的成本也会很高。
我们可以在访问的时候,通过设置:x-ms-max-item-count,来设置访问返回的数据量。
在这里,笔者主要使用Postman来进行演示。
1.我们选择按照时间范围查找
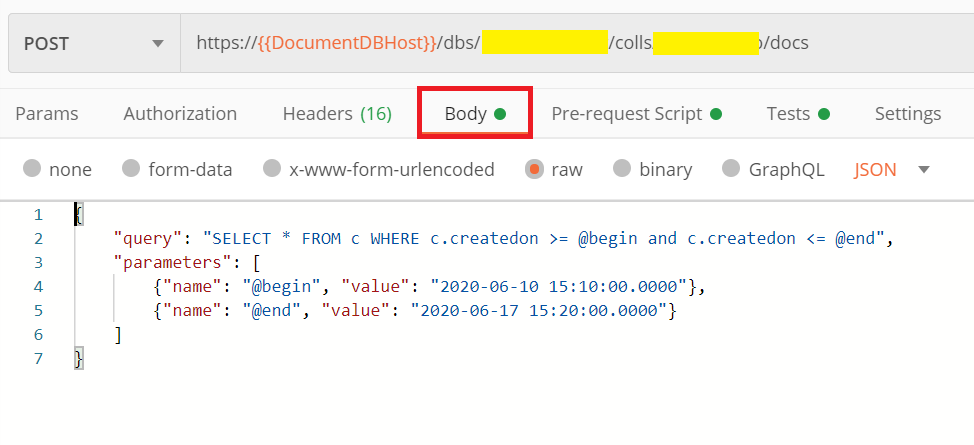
2.在Header的设置里
x-ms-documentdb-query-enablecrosspartition,表示跨分区键查询
x-ms-max-item-count,表示返回的数据量为10条。如果我们在请求中没有指定x-ms-max-item-count,则默认返回前100条数据。
如果返回的数据少于100条,则返回所有数据。

3.我们可以看到查询的结果,一共有10条

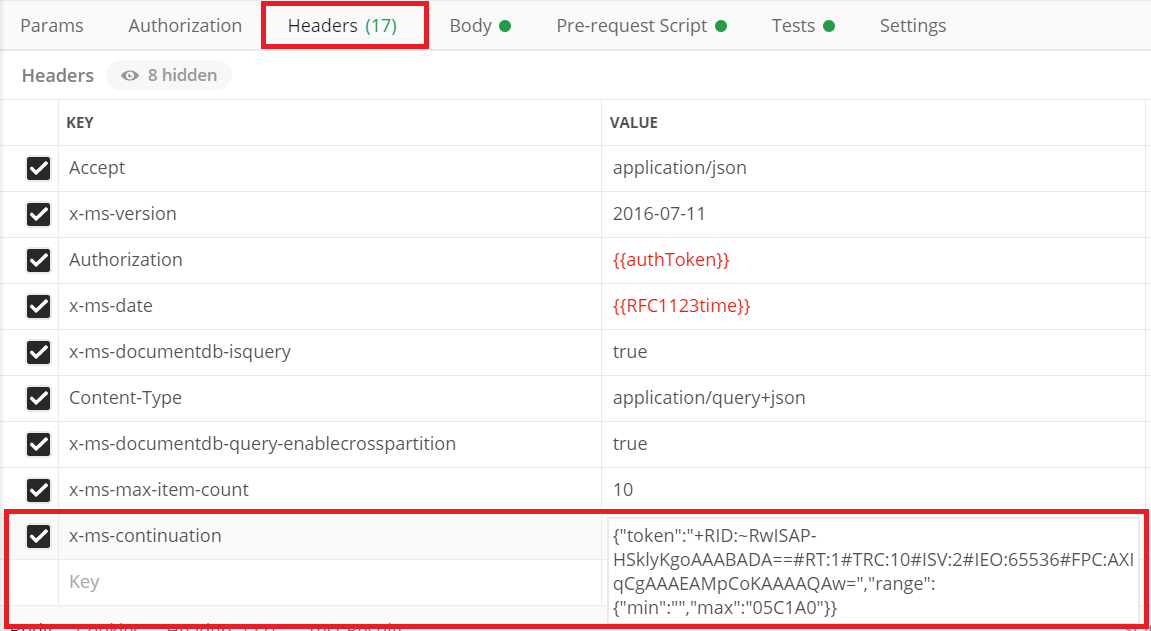
4.注意,在上面的返回结果中,有一个x-ms-continuation需要注意。
在上面的请求中,如果返回的数据有100条,但是我们只请求了10条数据,则请求额外的数据,需要在下一次请求中带x-ms-continuation这个值

5.好了,到目前为止,我们已经取出前10条数据,且CosmosDB服务器告诉我x-ms-continuation。
我们请求第11条-第20条数据 (即设置x-ms-max-item-count为10),则需要在http header里面,指定x-ms-continuation。
同样的,我们请求第11-30条数据,则设置x-ms-max-item-count为20
如下图:
6.该请求会返回第11条-第20条数据,如下图:

通过这种方式,既可以降低一次请求过多的数据,造成RU消耗过大,而且还可以实现分页的功能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号