
Azure CosmosDB (13) CosmosDB数据建模
《Windows Azure Platform 系列文章目录》
我们在使用NoSQL的时候,如Azure Cosmos DB,可以非常快速的查询非结构化,或半结构化的数据。我们需要花一些时间,研究Cosmos DB的数据建模,来保证查询性能和可扩展性,同事降低成本。
阅读完这篇文章后,我们将学会:
1.什么是数据建模,为什么我们要关注数据建模
2.如何在Azure Cosmos DB进行数据建模,与传统关系型数据库有什么不同
3.如何在非关系型数据库中,保存关系型数据
4.什么时候执行嵌入(embed)数据,什么时候执行连接(link)数据
嵌入(embed)数据
当我们开始在Cosmos DB进行数据建模的时候,尝试对我们的数据实体(Entity)视为自包含(Self-contained items)并保存在JSON文件中
为了比较,让我们首先看一下如何在关系型数据库中进行数据建模。下面的案例将介绍我们在关系型数据库中,如何保存用户信息
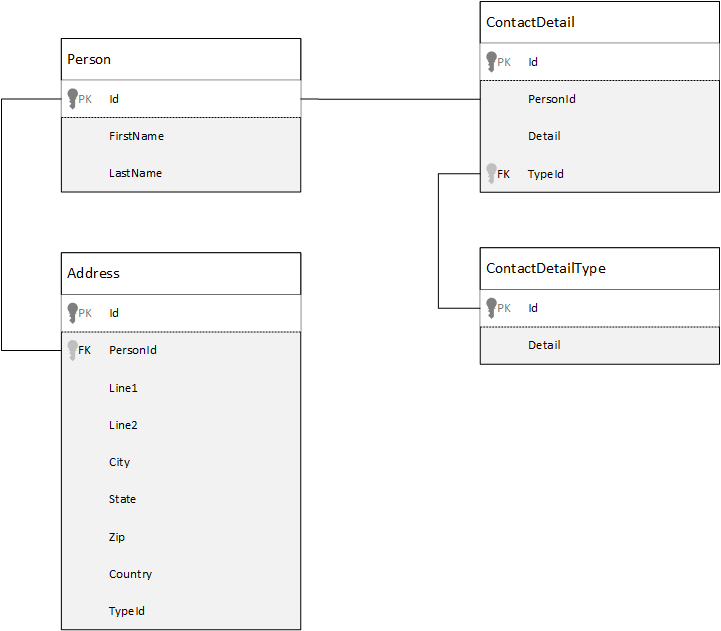
当我们使用关系型数据库的时候,一般都需要将数据规范化(Normalize)。规划范数据一般都会引入数据实体,比如一个人,我们可以将用户信息分解为不同的属性信息。
在上面的例子中,一个人有多个联系人,也有多个地址。联系人的详细信息可以进一步进行分解并提取常用字段。我们也可以用同样的方法,对地址进行分解,比如地址的类型可以是家庭地址,或者是公司地址。
规范化数据的指导方法是避免存储冗余的数据,并且应用数据。在上面的示例中,我们如果要读取一个人的所有联系人的详细信息和地址,我们需要使用JOIN方法,查询到所需要的数据:
SELECT p.FirstName, p.LastName, a.City, cd.Detail FROM Person p JOIN ContactDetail cd ON cd.PersonId = p.Id JOIN ContactDetailType on cdt ON cdt.Id = cd.TypeId JOIN Address a ON a.PersonId = p.Id
如果我们更新一个人的联系人信息和地址,需要跨多张表执行更新操作
现在我们看看如何在Azure Cosmos DB使用自包含(Self-contained items)实体
{ "id": "1", "firstName": "Thomas", "lastName": "Andersen", "addresses": [ { "line1": "100 Some Street", "line2": "Unit 1", "city": "Seattle", "state": "WA", "zip": 98012 } ], "contactDetails": [ {"email": "thomas@andersen.com"}, {"phone": "+1 555 555-5555", "extension": 5555} ] }
上面我们使用了非规范化(denormalized)来保存人的记录,我们将与人相关的所有信息,比如联系人的详细信息和地址信息,嵌入到单个JSON文档中,从而对人的记录进行了非规范化。另外,因为我们不局限于固定的Schema,我们可以灵活的使用不同类型的联系人信息
从Cosmos DB中读取一条记录,现在只需要单个读取操作。更新人的记录,包括联系人信息和地址信息,也只需要一次写入的操作。
通过使用非规范化(denormalized)保存数据,相比传统的关系型数据库,我们的应用程序的读取和更新的操作可以减少。
什么时候使用嵌入(embed)数据
我们一般在以下情况下,使用嵌入数据:
1.数据实体之间有包含(contained)关系
2.数据实体之间有1对多的关系
3.嵌入(embed)数据不经常变化
4.嵌入的数据不会无限增长
5.嵌入的数据是频繁集中查询的
通常非规范化(denormzlized)数据模型具有更好的读取性能
什么时候不使用嵌入(embed)数据
虽然Azure Cosmos DB中的经验法则是对所有内容进行非规范化,并将所有数据嵌入到单个项目中,但这可能会导致某些情况:
我们观察下面的JSON:
{ "id": "1", "name": "What's new in the coolest Cloud", "summary": "A blog post by someone real famous", "comments": [ {"id": 1, "author": "anon", "comment": "something useful, I'm sure"}, {"id": 2, "author": "bob", "comment": "wisdom from the interwebs"}, … {"id": 100001, "author": "jane", "comment": "and on we go ..."}, … {"id": 1000000001, "author": "angry", "comment": "blah angry blah angry"}, … {"id": ∞ + 1, "author": "bored", "comment": "oh man, will this ever end?"}, ] }
如果我们对一个博客系统进行建模,上面的例子就是采用嵌入(embed)数据方法,存储评论(comments)数据。上面例子的问题是评论的数据是没有限制的,这意味着任何一个发布的POST的内容,都有无限多个评论数据。这会让Cosmos DB的JSON文件变的无限大,可能会产生问题。
随着Cosmos DB的数据尺寸变的越来越大,读取数据和更新数据可能会产生影响。
在这种情况下,我们最好可以考虑采用以下的数据建模。
Post item: { "id": "1", "name": "What's new in the coolest Cloud", "summary": "A blog post by someone real famous", "recentComments": [ {"id": 1, "author": "anon", "comment": "something useful, I'm sure"}, {"id": 2, "author": "bob", "comment": "wisdom from the interwebs"}, {"id": 3, "author": "jane", "comment": "....."} ] } Comment items: { "postId": "1" "comments": [ {"id": 4, "author": "anon", "comment": "more goodness"}, {"id": 5, "author": "bob", "comment": "tails from the field"}, ... {"id": 99, "author": "angry", "comment": "blah angry blah angry"} ] }, { "postId": "1" "comments": [ {"id": 100, "author": "anon", "comment": "yet more"}, ... {"id": 199, "author": "bored", "comment": "will this ever end?"} ] }
上面的数据模型中,在一个Container中,包含了最新三个评论,且评论具有固定的属性。
其他的评论信息是保存在单独的Container中,每个container保存100条数据。Batch的大小设置为100,是因为我们假设应用程序允许用户一次加载100条评论数据
另外的场景中,嵌入(embed)数据并不是一个好的主意,比如嵌入的数据需要经常跨项目使用,且经常发生变化
我们可以参考下面的JSON内容:
{ "id": "1", "firstName": "Thomas", "lastName": "Andersen", "holdings": [ { "numberHeld": 100, "stock": { "symbol": "zaza", "open": 1, "high": 2, "low": 0.5 } }, { "numberHeld": 50, "stock": { "symbol": "xcxc", "open": 89, "high": 93.24, "low": 88.87 } } ] }
这个场景是个人投资的股票信息。我们选择将股票信息嵌入到每个投资组合文档中。在一个相关数据频繁变化的环境中,如股票交易应用程序,嵌入频繁变化的数据意味着您每次交易股票时都会不断更新每个投资组合文档。
股票zaza可能在一天内被交易数百次,成千上万的用户可以在他们的投资组合中拥有zaza。 使用上述数据模型,我们每天必须多次更新数千个投资组合文档,导致系统无法很好地扩展。
引用数据 (Referencing data)
因此,在大多数情况下使用嵌入(embed)数据可以很好的处理业务场景,但是很明显在某些场景下,非规范化数据将导致更多的问题而得不偿失。我们现在应该怎么办?
关系型数据库不是在数据数据实体之间创建关系的唯一选择。在Document Database中,我们可以在一个Document中创建对另外一个Document的引用。我们并不是说使用 Azure Cosmos DB可以更好的适应关系型数据库,或者其他Document Database。我们仅仅说明在Azure Cosmos DB中也可以使用简单的关系,并且很有用。
在下面的JSON文档中,我们选择之前的股票投资组合的示例,但是我们采用了引用数据的关系,而不是嵌入数据(embed)。在这种情况下,当一天中股票信息发生频繁变化的时候,我们只需要更新股票的Document。
Person document: { "id": "1", "firstName": "Thomas", "lastName": "Andersen", "holdings": [ { "numberHeld": 100, "stockId": 1}, { "numberHeld": 50, "stockId": 2} ] } Stock documents: { "id": "1", "symbol": "zaza", "open": 1, "high": 2, "low": 0.5, "vol": 11970000, "mkt-cap": 42000000, "pe": 5.89 }, { "id": "2", "symbol": "xcxc", "open": 89, "high": 93.24, "low": 88.87, "vol": 2970200, "mkt-cap": 1005000, "pe": 75.82 }
不过, 这种方法的一个直接缺点是, 如果您的应用程序需要显示有关在显示一个人的投资组合时持有的每只股票的信息;在这种情况下, 您需要多次访问数据库以加载每个库存文档的信息。在这里, 我们决定提高写入操作的效率, 这些操作在一天中频繁发生, 但反过来又影响了对此特定系统的性能影响较小的读取操作。
规范化数据模型可能需要多次访问服务器
外键在哪里?
在Document Database中并不存在约束,外键或其他类似概念。所以在Document Database中,任何Document之间的关系都是“弱链接”的关系,并且Document Database不会验证这些关系。如果想要确保文档要引用的数据实际存在,则需在应用程序中进行此验证,或通过使用 Azure Cosmos DB 上的服务器端触发器或存储过程来验证。
什么时候使用引用?
我们一般在以下情况下,使用引用数据:
1.一对多的关系
2.多对多的关系
3.数据需要频繁更改
4.使用数据可能没有限制
通常规范化能够提供更好的编写性能。
将关系存储在哪里?
关系的增长将有助于确定用于存储引用的文档。
让我们看看下面的对出版商和书籍进行建模的 JSON 代码。
Publisher document: { "id": "mspress", "name": "Microsoft Press", "books": [ 1, 2, 3, ..., 100, ..., 1000] } Book documents: {"id": "1", "name": "Azure Cosmos DB 101" } {"id": "2", "name": "Azure Cosmos DB for RDBMS Users" } {"id": "3", "name": "Taking over the world one JSON doc at a time" } ... {"id": "100", "name": "Learn about Azure Cosmos DB" } ... {"id": "1000", "name": "Deep Dive into Azure Cosmos DB" }
如果每个出版商的书籍数量较少且增长有限,那么在出版商文档中存储书籍引用可能很有用。 但是,如果每个出版商的书籍数量没有限制,那么此数据模型将产生可变、不断增长的数组,类似于上面示例中的出版商文档。
稍微做些更改就会使模型仍显示相同的数据,但可以避免产生较大的可变集合。
Publisher document: { "id": "mspress", "name": "Microsoft Press" } Book documents: {"id": "1","name": "Azure Cosmos DB 101", "pub-id": "mspress"} {"id": "2","name": "Azure Cosmos DB for RDBMS Users", "pub-id": "mspress"} {"id": "3","name": "Taking over the world one JSON doc at a time"} ... {"id": "100","name": "Learn about Azure Cosmos DB", "pub-id": "mspress"} ... {"id": "1000","name": "Deep Dive into Azure Cosmos DB", "pub-id": "mspress"}
在上面的示例中,我们删除了出版商文档中的无限制集合, 只在每个书籍文档中引用出版商。
如何处理多对多关系(Many: Many)进行数据建模
在关系型数据库中,多对多关系通常使用表连接来实现,表连接就是将其他表的记录连接在一起
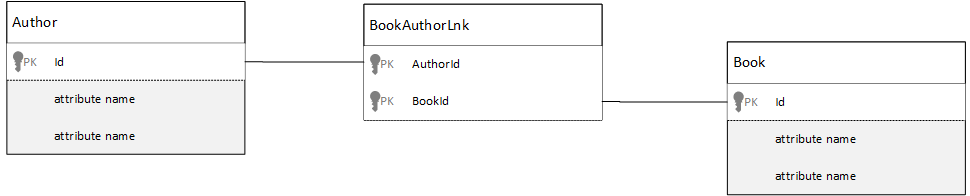
可能想要使用文档复制相同内容,并生成类似以下示例的数据模型。
Author documents: {"id": "a1", "name": "Thomas Andersen" } {"id": "a2", "name": "William Wakefield" } Book documents: {"id": "b1", "name": "Azure Cosmos DB 101" } {"id": "b2", "name": "Azure Cosmos DB for RDBMS Users" } {"id": "b3", "name": "Taking over the world one JSON doc at a time" } {"id": "b4", "name": "Learn about Azure Cosmos DB" } {"id": "b5", "name": "Deep Dive into Azure Cosmos DB" } Joining documents: {"authorId": "a1", "bookId": "b1" } {"authorId": "a2", "bookId": "b1" } {"authorId": "a1", "bookId": "b2" } {"authorId": "a1", "bookId": "b3" }
此模型可行。 但是,加载一个作者及其书籍或加载一个书籍及其作者,将始终要求对数据库执行至少两次查询。 一次是对联接文档的查询,另一个查询用来获取联接的实际文档。
如果联接表只是将两个数据片段联接在一起,那么为什么不将该表完全删除? 请考虑以下代码。
Author documents: {"id": "a1", "name": "Thomas Andersen", "books": ["b1, "b2", "b3"]} {"id": "a2", "name": "William Wakefield", "books": ["b1", "b4"]} Book documents: {"id": "b1", "name": "Azure Cosmos DB 101", "authors": ["a1", "a2"]} {"id": "b2", "name": "Azure Cosmos DB for RDBMS Users", "authors": ["a1"]} {"id": "b3", "name": "Learn about Azure Cosmos DB", "authors": ["a1"]} {"id": "b4", "name": "Deep Dive into Azure Cosmos DB", "authors": ["a2"]}
现在,如果我有作者的姓名,我可以立即知道他们所写的哪些书,相反如果我有一个书籍文档加载我可以知道作者的 Id。 这可以省去对联接表的中间查询,从而减少了应用程序需要往返访问服务器的次数。
混合数据建模
现在我们已经看了嵌入数据(或非规范化)和引用数据(规范化)的示例,正如我们看到的每种方法都有其优点和缺点。
不需要始终只使用其中一种方法,可以大胆地将这两种方法结合使用。
根据应用程序的特定使用模式和工作负载,可能在一些情况下结合使用嵌入式数据和引用数据是有意义的,可产生具有更少的服务器往返访问次数的更简单的应用程序逻辑,同时仍保持较好的性能级别。
请考虑以下 JSON。
Author documents: { "id": "a1", "firstName": "Thomas", "lastName": "Andersen", "countOfBooks": 3, "books": ["b1", "b2", "b3"], "images": [ {"thumbnail": "https://....png"} {"profile": "https://....png"} {"large": "https://....png"} ] }, { "id": "a2", "firstName": "William", "lastName": "Wakefield", "countOfBooks": 1, "books": ["b1"], "images": [ {"thumbnail": "https://....png"} ] } Book documents: { "id": "b1", "name": "Azure Cosmos DB 101", "authors": [ {"id": "a1", "name": "Thomas Andersen", "thumbnailUrl": "https://....png"}, {"id": "a2", "name": "William Wakefield", "thumbnailUrl": "https://....png"} ] }, { "id": "b2", "name": "Azure Cosmos DB for RDBMS Users", "authors": [ {"id": "a1", "name": "Thomas Andersen", "thumbnailUrl": "https://....png"}, ] }
此处我们(主要)遵循了嵌入式模型,在顶层文档中嵌入其他实体的数据,但同时引用了其他数据。
如果查看书籍文档(Book)中的作者数组,会看到一些有趣的字段。 在Document Book中,我们有一个authors:id字段,通过id字段我们可以查到找Document Author中的信息,这是一个标准的规范化模型。但是我们在Document Book中,还包含了name和thumbnailUrl字段。我们可以通过Document Book中的authors:id字段,查找到Document Author中的其他属性。因为在这个应用程序中,我们需要在每一本书中显示作者的名称和作者的缩略图,所以使用非规范化(denormalizing)的方式,把作者的名称和作者的缩略图,预先保存到Document Book中,减少额外的传输和IO开销。
当然,如果作者的名称更改,或者他们想要更新自己的照片,我们将需要转并更新他们曾经发布,但我们的应用程序,基于作者不经常更改其名称的假设每本书,这是一个可接受的设计。
在示例中预先计算的聚合值可在读取操作上节省高昂的处理成本。 在本例中,作者文档中嵌入的一些数据为在运行时计算的数据。 每当出版了一本新书,就会创建一个书籍文档并且将 countOfBooks 字段设置为基于特定作者的现有书籍文档数的计算值。 这种优化对于读取频繁的系统来说是有益的,为了优化读取,我们可以对写入操作执行更多计算。
因为 Azure Cosmos DB 支持多文档事务,所以构建一个具有预先计算字段的模型是可能的。许多 NoSQL 存储无法跨文档执行事务,正是因为该限制,所以提倡诸如“始终嵌入所有数据”的设计决策。 在 Azure Cosmos DB 中,可以使用服务器端触发器或存储过程在一个 ACID 事务中插入书籍和更新作者信息等。 现在无需将所有数据嵌入一个文档,只需确保数据保持一致性。
区分不同的文档类型
在一些场景中,我们可能需要在一个Collection中,保存不同类型的文档。这通常是这种情况,如果希望多个相关的文档中保存在相同的分区。 例如,可以将这两个丛书和同一集合中的书评和分区通过bookId。 在这种情况下,你通常想要添加到文档中使用字段,用于标识其类型以区分它们。
Book documents: { "id": "b1", "name": "Azure Cosmos DB 101", "bookId": "b1", "type": "book" } Review documents: { "id": "r1", "content": "This book is awesome", "bookId": "b1", "type": "review" }, { "id": "r2", "content": "Best book ever!", "bookId": "b1", "type": "review" }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号