
最简大数据开发环境(一) Scala+Spark版
最简大数据开发环境(一) Scala+Spark版
最简大数据开发环境(二) Python+Spark版
是否有像我一样,大数据架构原理看了千百遍,可每次想动手操练一番,就被Hadoop、Hive、Storm、Spark、Flink……一大堆的环境配置搞得晕头转向。那么有没有不用配置或者尽可能少配置的方案?
我的方案是sbt+vscode,当然,需要Java开发环境。
以上三项配置好后,我就演示一下怎么一步一步构建一个Spark+Mongodb项目。对该方案方案感兴趣的可以看下唐建法的报告《Mongodb+Spark完整大数据解决方案》。
- 打开VSCode,可以看到欢迎界面
- Ctrl+Shift+X打开扩展插件选项,输入scala,安装Scala扩展插件

- Ctrl+Shift+`,或工具栏->终端->新终端,创建新终端
- 切换到自己常用文件夹,我的是E:\project
-
#创建项目文件夹 mkdir mongodbspark
-
cd .\mongodbspark\
-
#进入项目开发界面,会新打开一个VSCode窗口 code .
-
#新建终端 Ctrl+Shift+` #测试sbt是否配置好 sbt --version
![]()
-
#添加build.sbt文件 ni build.sbt
打开build.sbt文件,并添加以下代码
-
//项目名称 name :="mongodbspark" //项目版本 version :="1.0" //scala版本 scalaVersion :="2.12.12" libraryDependencies ++=Seq( "org.apache.spark"%%"spark-core"%"3.1.2", "org.apache.spark"%%"spark-sql"%"3.1.2", "org.mongodb.spark"%%"mongo-spark-connector"%"3.0.1" )
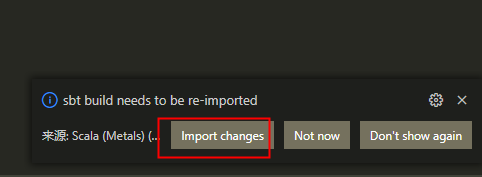
Ctrl+S保存build.sbt,从右下弹出框选择Import changes,稍等几分钟待依赖项被加载到项目中

-
#创建文件夹 mkdir .\src\main\scala\
#添加Main.scala文件 ni Main.scala
#Main.scala添加以下代码 package sparkmongo object Main extends App{ println(45+25) } #终端执行以下命令
sbt reload sbt run -
![]()
-
到这里我们的scala项目基本框架已经搭建好,目录结构如下图


Spark与Mongodb连接需要用到Mongodb官方的spark-connector
本地测试文档结构如下
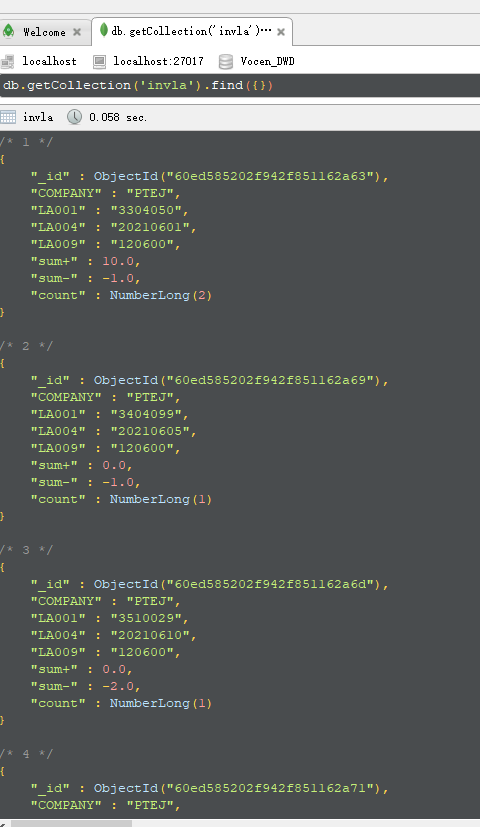

- Main.scala文件里的代码替换为以下代码
package sparkmongo //MongodbSaprk-Connector import com.mongodb.spark._ import org.apache.spark.sql.SparkSession object main extends App{ //在spark创建时配置mongodb连接信息 //手打的同学要注意别把uri打成url,很容易混淆 val sparkSession=SparkSession.builder() .master("local") .appName("MongodbSpark") .config("spark.mongodb.input.uri","mongodb://127.0.0.1/Vocen_DWD.invla?readPreference=secondaryPreferred") .config("spark.mongodb.output.uri","mongodb://127.0.0.1/Vocen_DWD.test") .getOrCreate() val df1=MongoSpark.load(sparkSession)//加载数据 df1.createOrReplaceTempView("invla")//缓存到临时表invla //用sql查询mongodb表中数据,并显示前5条 sparkSession.sql("SELECT COMPANY,LA001,LA004,LA009,count FROM invla WHERE COMPANY='PTYW' AND count>3").show(5) sparkSession.stop() }
- 在终端运行命令: sbt run,运行结果如下图

Mongodb与Spark擦出的真是爱的火花,即克服了Mongodb不能直接用SQL,又避免了HDFS不能用复杂索引的不足。
有人好奇那句SQL语句到了mongodb里怎么执行的吗?一起看下mongodb的执行记录:
//前两行是网络连接信息
{"t":{"$date":"2021-10-13T17:22:52.925+08:00"},"s":"I", "c":"NETWORK", "id":22943, "ctx":"listener","msg":"Connection accepted","attr":{"remote":"127.0.0.1:49698","connectionId":8,"connectionCount":6}} {"t":{"$date":"2021-10-13T17:22:52.925+08:00"},"s":"I", "c":"NETWORK", "id":51800, "ctx":"conn8","msg":"client metadata","attr":{"remote":"127.0.0.1:49698","client":"conn8","doc":{"driver":{"name":"mongo-java-driver|sync|mongo-spark","version":"4.0.5|3.0.1"},"os":{"type":"Windows","name":"Windows 10","architecture":"amd64","version":"10.0"},"platform":"Java/Oracle Corporation/1.8.0_291-b10|Scala/2.12.11:Spark/3.1.2"}}} //随机取样100行数据,以确定数据结构
{"t":{"$date":"2021-10-13T17:22:53.800+08:00"},"s":"I", "c":"COMMAND", "id":51803, "ctx":"conn8","msg":"Slow query","attr":{"type":"command","ns":"Vocen_DWD.invla","command":{"aggregate":"invla","pipeline":[{"$sample":{"size":1000}}],"cursor":{},"allowDiskUse":true,"$db":"Vocen_DWD","$readPreference":{"mode":"secondaryPreferred"}},"planSummary":"MULTI_ITERATOR","cursorid":7176739098596969558,"keysExamined":0,"docsExamined":0,"numYields":19,"nreturned":101,"reslen":14611,"locks":{"ReplicationStateTransition":{"acquireCount":{"w":21}},"Global":{"acquireCount":{"r":21}},"Database":{"acquireCount":{"r":21}},"Collection":{"acquireCount":{"r":21}},"Mutex":{"acquireCount":{"r":2}}},"storage":{"data":{"bytesRead":1543572,"timeReadingMicros":110058}},"protocol":"op_msg","durationMillis":137}} //执行了sql中的where和select获取数据,把sql语句转换成bson,返回的是全部数据,显示前5条的命令是在spark中执行
{"t":{"$date":"2021-10-13T17:22:57.356+08:00"},"s":"I", "c":"COMMAND", "id":51803, "ctx":"conn8","msg":"Slow query","attr":{"type":"command","ns":"Vocen_DWD.invla","command":{"aggregate":"invla","pipeline":[{"$match":{"$and":[{"COMPANY":"PTYW"},{"count":{"$gt":3}}]}},{"$group":{"_id":1,"n":{"$sum":1}}}],"cursor":{},"$db":"Vocen_DWD","$readPreference":{"mode":"secondaryPreferred"}},"planSummary":"IXSCAN { COMPANY: 1 }","keysExamined":910813,"docsExamined":910813,"cursorExhausted":true,"numYields":910,"nreturned":1,"queryHash":"FB8A4A00","planCacheKey":"E11D0BC7","reslen":128,"locks":{"ReplicationStateTransition":{"acquireCount":{"w":912}},"Global":{"acquireCount":{"r":912}},"Database":{"acquireCount":{"r":912}},"Collection":{"acquireCount":{"r":912}},"Mutex":{"acquireCount":{"r":2}}},"storage":{},"protocol":"op_msg","durationMillis":1125}}
- 如果我们在sql中用了聚合语句,聚合操作会不会在Mongodb中执行?来一起试验下看看:
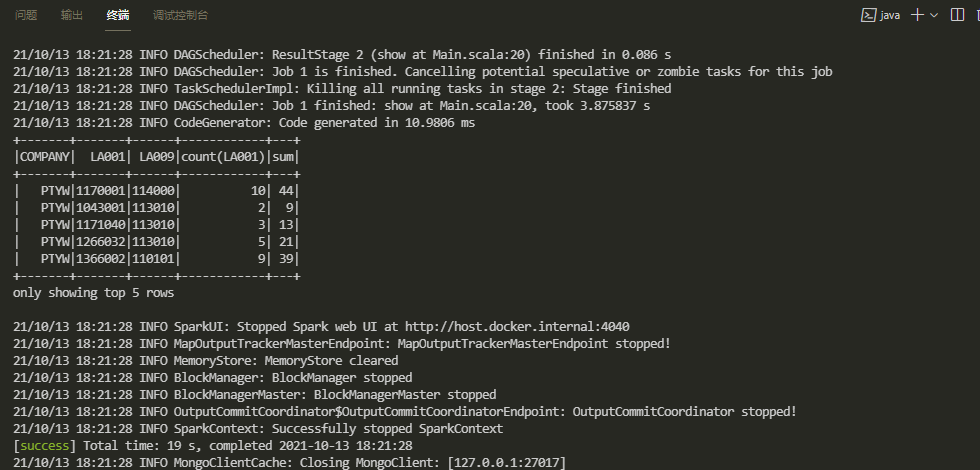
- 将Main.scala文件代码替换成下面的,我将sql改造成group by语句,仍然显示前5,然后sbt run走起:
-
package sparkmongo //MongodbSaprk-Connector import com.mongodb.spark._ import org.apache.spark.sql.SparkSession object main extends App{ //在spark创建时配置mongodb连接信息 //手打的同学要注意别把uri打成url,很容易混淆 val sparkSession=SparkSession.builder() .master("local") .appName("MongodbSpark") .config("spark.mongodb.input.uri","mongodb://127.0.0.1/Vocen_DWD.invla?readPreference=secondaryPreferred") .config("spark.mongodb.output.uri","mongodb://127.0.0.1/Vocen_DWD.test") .getOrCreate() val df1=MongoSpark.load(sparkSession)//加载数据 df1.createOrReplaceTempView("invla")//缓存到临时表invla //用sql查询mongodb表中数据,并显示前5条 sparkSession.sql("SELECT COMPANY,LA001,LA009,COUNT(LA001),SUM(count) sum FROM invla WHERE COMPANY='PTYW' AND count>3 " + "GROUP BY COMPANY,LA001,LA009").show(5) sparkSession.stop() }
![]()
//前两行与上一个的相同都是网络连接记录
{"t":{"$date":"2021-10-13T18:21:20.706+08:00"},"s":"I", "c":"NETWORK", "id":22943, "ctx":"listener","msg":"Connection accepted","attr":{"remote":"127.0.0.1:49424","connectionId":14,"connectionCount":6}}
{"t":{"$date":"2021-10-13T18:21:20.707+08:00"},"s":"I", "c":"NETWORK", "id":51800, "ctx":"conn14","msg":"client metadata","attr":{"remote":"127.0.0.1:49424","client":"conn14","doc":{"driver":{"name":"mongo-java-driver|sync|mongo-spark","version":"4.0.5|3.0.1"},"os":{"type":"Windows","name":"Windows 10","architecture":"amd64","version":"10.0"},"platform":"Java/Oracle Corporation/1.8.0_291-b10|Scala/2.12.11:Spark/3.1.2"}}}//获取where过滤后的总条数
{"t":{"$date":"2021-10-13T18:21:25.328+08:00"},"s":"I", "c":"COMMAND", "id":51803, "ctx":"conn14","msg":"Slow query","attr":{"type":"command","ns":"Vocen_DWD.invla","command":{"aggregate":"invla","pipeline":[{"$match":{"$and":[{"COMPANY":"PTYW"},{"count":{"$gt":3}}]}},{"$group":{"_id":1,"n":{"$sum":1}}}],"cursor":{},"$db":"Vocen_DWD","$readPreference":{"mode":"secondaryPreferred"}},"planSummary":"IXSCAN { COMPANY: 1 }","keysExamined":910813,"docsExamined":910813,"cursorExhausted":true,"numYields":910,"nreturned":1,"queryHash":"FB8A4A00","planCacheKey":"E11D0BC7","reslen":128,"locks":{"ReplicationStateTransition":{"acquireCount":{"w":912}},"Global":{"acquireCount":{"r":912}},"Database":{"acquireCount":{"r":912}},"Collection":{"acquireCount":{"r":912}},"Mutex":{"acquireCount":{"r":2}}},"storage":{},"protocol":"op_msg","durationMillis":1101}} //返回where过滤后,select选取的字段,可以明确的一点是,group by没在mongodb中执行,而在spark中执行
{"t":{"$date":"2021-10-13T18:21:27.143+08:00"},"s":"I", "c":"COMMAND", "id":51803, "ctx":"conn14","msg":"Slow query","attr":{"type":"command","ns":"Vocen_DWD.invla","command":{"getMore":5143393766922072670,"collection":"invla","$db":"Vocen_DWD"},"originatingCommand":{"aggregate":"invla","pipeline":[{"$match":{"$and":[{"COMPANY":{"$exists":true,"$ne":null}},{"count":{"$exists":true,"$ne":null}},{"COMPANY":"PTYW"},{"count":{"$gt":3}}]}},{"$project":{"COMPANY":1,"LA001":1,"LA009":1,"count":1,"_id":0}}],"cursor":{},"allowDiskUse":true,"$db":"Vocen_DWD","$readPreference":{"mode":"secondaryPreferred"}},"planSummary":"IXSCAN { COMPANY: 1 }","cursorid":5143393766922072670,"keysExamined":907750,"docsExamined":907750,"cursorExhausted":true,"numYields":907,"nreturned":18957,"reslen":1538871,"locks":{"ReplicationStateTransition":{"acquireCount":{"w":908}},"Global":{"acquireCount":{"r":908}},"Database":{"acquireCount":{"r":908}},"Collection":{"acquireCount":{"r":908}},"Mutex":{"acquireCount":{"r":1}}},"storage":{},"protocol":"op_msg","durationMillis":1547}}
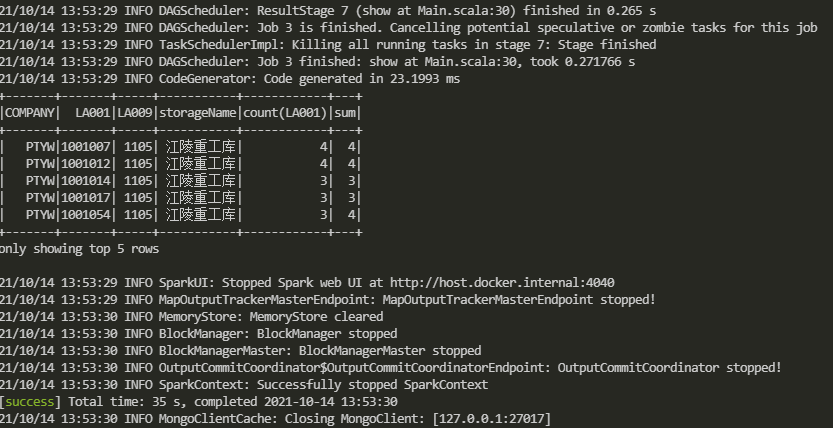
再看个表关联的例子,Main.scala代码如下:
package sparkmongo //MongodbSaprk-Connector import com.mongodb.spark._ import org.apache.spark.sql.SparkSession import com.mongodb.spark.config.ReadConfig object main extends App{ //在spark创建时配置mongodb连接信息 //手打的同学要注意别把uri打成url,很容易混淆 val sparkSession=SparkSession.builder() .master("local") .appName("MongodbSpark") .config("spark.mongodb.input.uri","mongodb://127.0.0.1/Vocen_DWD.invla?readPreference=secondaryPreferred") .config("spark.mongodb.output.uri","mongodb://127.0.0.1/Vocen_DWD.test") .getOrCreate() //加载数据 val df1=MongoSpark.load(sparkSession) val df2=MongoSpark.load(sparkSession,ReadConfig(Map("collection"->"cmsmc"),Some(ReadConfig(sparkSession))))
//缓存到临时表 df1.createOrReplaceTempView("invla") df2.createOrReplaceTempView("cmsmc") //表invla与cmsmc关联并聚合 val mySql="SELECT la.COMPANY,la.LA001,la.LA009,mc.storageName,COUNT(la.LA001),SUM(la.count) sum " + "FROM invla la " + "LEFT JOIN cmsmc mc ON mc.COMPANY=la.COMPANY AND mc.LA009=la.LA009 " + "WHERE la.COMPANY='PTYW' AND la.count>0 " + "GROUP BY la.COMPANY,la.LA001,la.LA009,mc.storageName" //用sql查询mongodb表中数据,并显示前5条 sparkSession.sql(mySql).show(5) sparkSession.stop() }
#mongodb操作日志
//获取表invla符合where条件的数据总数 {"t":{"$date":"2021-10-14T09:16:11.492+08:00"},"s":"I", "c":"COMMAND", "id":51803, "ctx":"conn26","msg":"Slow query","attr":{"type":"command","ns":"Vocen_DWD.invla","command":{"aggregate":"invla","pipeline":[{"$match":{"$and":[{"COMPANY":"PTYW"},{"count":{"$gt":0}}]}},{"$group":{"_id":1,"n":{"$sum":1}}}],"cursor":{},"$db":"Vocen_DWD","$readPreference":{"mode":"secondaryPreferred"}},"planSummary":"IXSCAN { COMPANY: 1 }","keysExamined":910813,"docsExamined":910813,"cursorExhausted":true,"numYields":910,"nreturned":1,"queryHash":"FB8A4A00","planCacheKey":"E11D0BC7","reslen":128,"locks":{"ReplicationStateTransition":{"acquireCount":{"w":912}},"Global":{"acquireCount":{"r":912}},"Database":{"acquireCount":{"r":912}},"Collection":{"acquireCount":{"r":912}},"Mutex":{"acquireCount":{"r":2}}},"storage":{},"protocol":"op_msg","durationMillis":1260}}
//随机采样符合where条件的数据18条 {"t":{"$date":"2021-10-14T09:16:13.784+08:00"},"s":"I", "c":"COMMAND", "id":51803, "ctx":"conn26","msg":"Slow query","attr":{"type":"command","ns":"Vocen_DWD.invla","command":{"aggregate":"invla","pipeline":[{"$match":{"$and":[{"COMPANY":"PTYW"},{"count":{"$gt":0}}]}},{"$sample":{"size":18}},{"$project":{"_id":1}},{"$sort":{"_id":1}}],"cursor":{},"allowDiskUse":true,"$db":"Vocen_DWD","$readPreference":{"mode":"secondaryPreferred"}},"planSummary":"IXSCAN { COMPANY: 1 }","keysExamined":910813,"docsExamined":910813,"hasSortStage":true,"cursorExhausted":true,"numYields":922,"nreturned":18,"queryHash":"3C43B2DC","planCacheKey":"8AE2943E","reslen":562,"locks":{"ReplicationStateTransition":{"acquireCount":{"w":949}},"Global":{"acquireCount":{"r":949}},"Database":{"acquireCount":{"r":949}},"Collection":{"acquireCount":{"r":949}},"Mutex":{"acquireCount":{"r":27}}},"storage":{},"protocol":"op_msg","durationMillis":2288}} //下面这几个条日志做的是同一件事,即按ID分段拉取数据,这是优化慢查询的一种方法
{"t":{"$date":"2021-10-14T09:16:16.356+08:00"},"s":"I", "c":"COMMAND", "id":51803, "ctx":"conn26","msg":"Slow query","attr":{"type":"command","ns":"Vocen_DWD.invla","command":{"getMore":9005002959326612078,"collection":"invla","$db":"Vocen_DWD"},"originatingCommand":{"aggregate":"invla","pipeline":[{"$match":{"_id":{"$lt":{"$oid":"60ed58ba02f942f851230224"}}}},{"$match":{"$and":[{"COMPANY":{"$exists":true,"$ne":null}},{"count":{"$exists":true,"$ne":null}},{"COMPANY":"PTYW"},{"count":{"$gt":0}}]}},{"$project":{"COMPANY":1,"LA001":1,"LA009":1,"count":1,"_id":0}}],"cursor":{},"allowDiskUse":true,"$db":"Vocen_DWD","$readPreference":{"mode":"secondaryPreferred"}},"planSummary":"IXSCAN { COMPANY: 1 }","cursorid":9005002959326612078,"keysExamined":910712,"docsExamined":910712,"fromMultiPlanner":true,"cursorExhausted":true,"numYields":910,"nreturned":86663,"reslen":7095359,"locks":{"ReplicationStateTransition":{"acquireCount":{"w":911}},"Global":{"acquireCount":{"r":911}},"Database":{"acquireCount":{"r":911}},"Collection":{"acquireCount":{"r":911}},"Mutex":{"acquireCount":{"r":1}}},"storage":{},"protocol":"op_msg","durationMillis":1658}} {"t":{"$date":"2021-10-14T09:16:18.384+08:00"},"s":"I", "c":"COMMAND", "id":51803, "ctx":"conn26","msg":"Slow query","attr":{"type":"command","ns":"Vocen_DWD.invla","command":{"getMore":2609909263370750001,"collection":"invla","$db":"Vocen_DWD"},"originatingCommand":{"aggregate":"invla","pipeline":[{"$match":{"_id":{"$gte":{"$oid":"60ed58ba02f942f851230224"},"$lt":{"$oid":"610bc37035dab7f3973d9a2d"}}}},{"$match":{"$and":[{"COMPANY":{"$exists":true,"$ne":null}},{"count":{"$exists":true,"$ne":null}},{"COMPANY":"PTYW"},{"count":{"$gt":0}}]}},{"$project":{"COMPANY":1,"LA001":1,"LA009":1,"count":1,"_id":0}}],"cursor":{},"allowDiskUse":true,"$db":"Vocen_DWD","$readPreference":{"mode":"secondaryPreferred"}},"planSummary":"IXSCAN { _id: 1 }","cursorid":2609909263370750001,"keysExamined":588534,"docsExamined":588534,"fromMultiPlanner":true,"numYields":588,"nreturned":205254,"reslen":16777207,"locks":{"ReplicationStateTransition":{"acquireCount":{"w":589}},"Global":{"acquireCount":{"r":589}},"Database":{"acquireCount":{"r":589}},"Collection":{"acquireCount":{"r":589}},"Mutex":{"acquireCount":{"r":1}}},"storage":{"data":{"bytesRead":4315895,"timeReadingMicros":49043}},"protocol":"op_msg","durationMillis":1315}} {"t":{"$date":"2021-10-14T09:16:20.250+08:00"},"s":"I", "c":"COMMAND", "id":51803, "ctx":"conn26","msg":"Slow query","attr":{"type":"command","ns":"Vocen_DWD.invla","command":{"getMore":2609909263370750001,"collection":"invla","$db":"Vocen_DWD"},"originatingCommand":{"aggregate":"invla","pipeline":[{"$match":{"_id":{"$gte":{"$oid":"60ed58ba02f942f851230224"},"$lt":{"$oid":"610bc37035dab7f3973d9a2d"}}}},{"$match":{"$and":[{"COMPANY":{"$exists":true,"$ne":null}},{"count":{"$exists":true,"$ne":null}},{"COMPANY":"PTYW"},{"count":{"$gt":0}}]}},{"$project":{"COMPANY":1,"LA001":1,"LA009":1,"count":1,"_id":0}}],"cursor":{},"allowDiskUse":true,"$db":"Vocen_DWD","$readPreference":{"mode":"secondaryPreferred"}},"planSummary":"IXSCAN { _id: 1 }","cursorid":2609909263370750001,"keysExamined":409333,"docsExamined":409333,"fromMultiPlanner":true,"numYields":409,"nreturned":203865,"reslen":16777256,"locks":{"ReplicationStateTransition":{"acquireCount":{"w":410}},"Global":{"acquireCount":{"r":410}},"Database":{"acquireCount":{"r":410}},"Collection":{"acquireCount":{"r":410}},"Mutex":{"acquireCount":{"r":1}}},"storage":{},"protocol":"op_msg","durationMillis":958}} {"t":{"$date":"2021-10-14T09:16:22.745+08:00"},"s":"I", "c":"COMMAND", "id":51803, "ctx":"conn26","msg":"Slow query","attr":{"type":"command","ns":"Vocen_DWD.invla","command":{"getMore":1612716104933424645,"collection":"invla","$db":"Vocen_DWD"},"originatingCommand":{"aggregate":"invla","pipeline":[{"$match":{"_id":{"$gte":{"$oid":"610bc37035dab7f3973d9a2d"}}}},{"$match":{"$and":[{"COMPANY":{"$exists":true,"$ne":null}},{"count":{"$exists":true,"$ne":null}},{"COMPANY":"PTYW"},{"count":{"$gt":0}}]}},{"$project":{"COMPANY":1,"LA001":1,"LA009":1,"count":1,"_id":0}}],"cursor":{},"allowDiskUse":true,"$db":"Vocen_DWD","$readPreference":{"mode":"secondaryPreferred"}},"planSummary":"IXSCAN { _id: 1 }","cursorid":1612716104933424645,"keysExamined":560354,"docsExamined":560354,"fromMultiPlanner":true,"numYields":560,"nreturned":203473,"reslen":16777252,"locks":{"ReplicationStateTransition":{"acquireCount":{"w":561}},"Global":{"acquireCount":{"r":561}},"Database":{"acquireCount":{"r":561}},"Collection":{"acquireCount":{"r":561}},"Mutex":{"acquireCount":{"r":1}}},"storage":{},"protocol":"op_msg","durationMillis":1313}} {"t":{"$date":"2021-10-14T09:16:24.658+08:00"},"s":"I", "c":"COMMAND", "id":51803, "ctx":"conn26","msg":"Slow query","attr":{"type":"command","ns":"Vocen_DWD.invla","command":{"getMore":1612716104933424645,"collection":"invla","$db":"Vocen_DWD"},"originatingCommand":{"aggregate":"invla","pipeline":[{"$match":{"_id":{"$gte":{"$oid":"610bc37035dab7f3973d9a2d"}}}},{"$match":{"$and":[{"COMPANY":{"$exists":true,"$ne":null}},{"count":{"$exists":true,"$ne":null}},{"COMPANY":"PTYW"},{"count":{"$gt":0}}]}},{"$project":{"COMPANY":1,"LA001":1,"LA009":1,"count":1,"_id":0}}],"cursor":{},"allowDiskUse":true,"$db":"Vocen_DWD","$readPreference":{"mode":"secondaryPreferred"}},"planSummary":"IXSCAN { _id: 1 }","cursorid":1612716104933424645,"keysExamined":463309,"docsExamined":463309,"fromMultiPlanner":true,"numYields":463,"nreturned":203473,"reslen":16777252,"locks":{"ReplicationStateTransition":{"acquireCount":{"w":464}},"Global":{"acquireCount":{"r":464}},"Database":{"acquireCount":{"r":464}},"Collection":{"acquireCount":{"r":464}},"Mutex":{"acquireCount":{"r":1}}},"storage":{},"protocol":"op_msg","durationMillis":1083}}
综合以上三个例子,我们可以得出关于mongodb-spark-connector的以下结论:
- 只用mongodb索引做条件过滤和字段缩减
- 复杂计算任务都在spark中执行
- 多表关联在spark中执行
最后做个总结,之所以敢说这是最简大数据开发环境,是因为本篇只用了sbt和VSCode,避免了繁杂的大数据组件搭建和配置工作。新猿可以用这个方案快速上手体验大数据开发;老猿也可以用这个方案做开发测试,省却版本维护之类的繁琐。
如果看的不尽兴,或者想吐糟,欢迎Email拍砖983353083@qq.com。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号