
ETL实践之数据可视化架构
开篇心声:
不管是学习新知识,还是遇到各种难题,总能在技术论坛找到经验帖子。一直享受大家提供的帮助,而自己没有任何输出,实在过意不去。我相信技术是经验的交流,思维的碰撞。
这是我一次写技术分享文章,我想用系列文章介绍用Mongodb、Kettle、Metabase这三个开源软件在数据可视化实践中的一些关联问题,Mongodb脚本在不同软件中的应用注意事项。
先展示下我所用技术架构:
数据源:Mongodb数据库集群、Excel,业务端用的数据源,数据抽取只能兼容。
ETL工具:Kettle,大多数ETL工具数据源对关系型数据库支持友好,而对NoSQL支持就有点差强人意。Kettle在BigData里集成了Mongodb组件,虽然用起来不如SQL数据连接,但还算稳定,支持Json格式的Mongodb脚本查询。
DW:Mongodb、PostgreSQL,数据源其实很灵活。数据体量达到PB及以上,建议直接用云数据仓库;数据量不大的,用自己熟悉的库就好。
BI:Echart、Metabase,Echart是百度开源的Javascript可视化插件,Metabase是国外的开源数据可视化软件。试过FineBI,其功能和图表比Metabase更丰富。不过,FIneBI免费版仅支持两个节点同时访问,自带数据源不支持Mongodb数据源。应用市场里有付费Mongodb连接插件,公司一看25000,而且需要经过FineReport转换,怕掉坑果断跳过。
Kettle、Metabase运行需要JAVA环境。
整体技术架构图1所示:
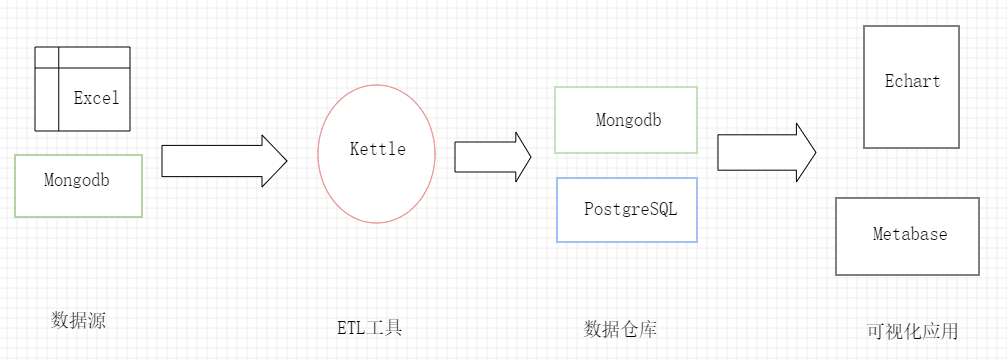
图 1
很久没有更新了,今天看来,当时写的内容过于简短,补充点哈。
Kettle做为一款经典ETL工具软件,公开的学习资料非常多,所以我就没有讲Kettle的教程,只结合自己的使用情况,讲下我是怎么用的。
当时写这篇的时候,我还是只用了Kettle的Spoon工具,设计ETL流程并执行作业任务。但是随着使用的深入,就发现这样用有很多局限的地方:
- Kettle的图形界面很吃内存,在寸G寸金的服务机器上用不合适
- 复杂任务中,某些变量并不能事先知道,要在调用数据的时候才能从前面的步骤取得,这在Kettle的Spoon中很难实现
- Rdbms与Nosq的数据表做差异同步,在Kettle的Spoon中无法实现
随着探索的深入,我现在用Spoon开发表级作业和转换,用python设计任务计划。将Kettle的转换和作业嵌入python任务中,通过pan、kichen附带传参执行转换和作业。
可能有人就要说了,只用python照样做ETL,干嘛费那脑筋引入Kettle。我认为至少有以下优点:
- 开发效率高。做同一个任务,你不停的写数据库配置、写数据转换逻辑、写日志监控逻辑、最后调试几遍也未必如愿;别人用Spoon拖好控件,简单配置,验证无误后在python上面写个执行语句就好了。
- 出错少。写的代码越多,潜在的BUG越多;变量越多,用错的机会越大,程序猿都知道。
- 代码简洁易维护。Kettle的任务与python代码隔离程度高,可以分别由不同的人维护。Kettle专门做最基础的单表、多表数据同步配置,python从业务角度组合不同的作业和转换。
当然也有缺点,因为需要花时间去学习Kettle嘛

 浙公网安备 33010602011771号
浙公网安备 33010602011771号