基于DBScan和行块分布函数的网页正文提
工作以来,一直做数据挖掘。刚开始的时候,为政府网站抓取其他网站的正文内容做统计分析,到现在的公司,做海量数据相似度分析。刚开始时,仅仅基于Dom树做分析,然后找出那些最可能是正文的内容,但是这样做,仅能针对的网站数量很少,对于严重不符合规范的网站,抓取准确率很低。
这次,借着做毕业设计之际,有充足的时间做深入的学习。先是看了《基于DBScan算法的网页正文提取》,开始对正文提取的手段有了改观。
1.DBScan(for density-based spatial clustering of applications with noise),我觉得维基百科中对它的描述很准确,很详尽:
DBSCAN's definition of a cluster is based on the notion of density reachability. Basically, a point  isdirectly density-reachable from a point
isdirectly density-reachable from a point  if it is not farther away than a given distance
if it is not farther away than a given distance  (i.e., is part of its -neighborhood) and if is surrounded by sufficiently many points such that one may consider and to be part of a cluster. is called density-reachable (note the distinction from "directly density-reachable") from if there is a sequence
(i.e., is part of its -neighborhood) and if is surrounded by sufficiently many points such that one may consider and to be part of a cluster. is called density-reachable (note the distinction from "directly density-reachable") from if there is a sequence  of points with
of points with  and
and  where each
where each  is directly density-reachable from
is directly density-reachable from 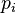 .
.
Note that the relation of density-reachable is not symmetric. might lie on the edge of a cluster, having insufficiently many neighbors to count as dense itself. This would halt the process of finding a path that stops with the first non-dense point. By contrast, starting the process with would lead to (though the process would halt there, being the first non-dense point). Due to this asymmetry, the notion of density-connected is introduced: two points and are density-connected if there is a point such that both and are density-reachable from . Density-connectedness is symmetric.
such that both and are density-reachable from . Density-connectedness is symmetric.
A cluster, which is a subset of the points of the database, satisfies two properties:
- All points within the cluster are mutually density-connected.
- If a point is density-connected to any point of the cluster, it is part of the cluster as well.
 【摘自维基百科:http://en.wikipedia.org/wiki/DBSCAN】
【摘自维基百科:http://en.wikipedia.org/wiki/DBSCAN】
2.DBSCan在网页抓取中的应用:DBScan的应用场景是通过聚类来找出相似的簇,从而过滤孤立点,也就是“噪声”。而在抓取网页正文这个应用场景中,我们却是通过DBScan来找出“噪声”。据统计,对于一个网页,正文的内容是密度最高的地方。当然,也存在这样的情况,导航不规范,内容堆砌在一起;评论内容很长等,这些都会导致后期的判断。所以,我们要在算法的基础上根据网页做出相应处理(例如,可以建立一个相对小的模板库,对抓取有误的网页模板进行存储等)。

3.哈尔滨工业大学社会计算与信息检索中心的陈鑫写过《基于行块分布函数的通用网页正文提取》这篇论文,该算法与DBScan类似:这个算法是通过求文字字数的分布函数,再找出分布图中的骤升骤降点。这跟查找“噪声”类似。基于行块分布函数还引入了文块长度这个阀值。

4.我所做的,就是在某些方面改写这个方法,让它更具应用性,例如,过滤时跳过图片,标题等等。为了使它更贴近我们的工作生活,我把它改写成javascript,让它在客户端工作,这样可以更加流畅,方便。下图为,在起点中文网上的实验图:


好了,现在开始一步一步来讲解:
4.1 在收藏夹上面创建“快捷键”(当然,你可以把它打包为chrome插件,关于chrome插件开发,可以参照:http://dev.chromechina.com/thread-1940-1-1.html):新建一个收藏夹,在网址中写入下面的代码:
javascript: void((function() { var d = document; if (null == d.getElementById("thinkBank_ClearReader")) { var e = d.createElement("script"); e.setAttribute("id", "thinkBank_ClearReader"); e.setAttribute("charset", "UTF-8"); e.setAttribute("src", "http://XXX/Scripts/displayHtmlClearly.js?" + Math.floor(new Date / 1E7)); d.body.appendChild(e); } })());
创建好如图所示:
4.2 创建displayHtmlClearly.js文件:
定义两个字符串对象,一个用于存储去掉所有js,css,标签后的内容(以行作为数组分隔)的textBody,另一个,存储去掉js,css,部分标签后的内容(非div,img,p,br,h1等)的textBodytPreview:(我的正则表达式学得很水,大家可以自行修改)
function removeTags() { var docType = /<!DOCTYPE.*?>/gi; var comment = /<!--.*?-->/gi; var js = /<script[^>]*?>([\s\S]*?)<\/script>/gi; var marquee = /<marquee[^>]*?>([\s\S]*?)<\/marquee>/gi; var css = /<style[^>]*?>([\s\S]*?)<\/style>/gi; var specialChar = /&.{2,8};|&#.{2,8};/g; var otherTag = /<[\s\S]*?>/gi; var liBTag = /<\s{0,}\/?li.*?>/gi; var removeStyle = /(<(h1|h2|h3|h4|h5|h6|strong|div|p|pre|person|plaintext))\s(?:\s*\w*?\s*=\s*".+?")*?\s*?(>)/gi; var otherTag_preview = /<(?!img)(?!\/?h1)(?!\/?h2)(?!\/?h3)(?!\/?h4)(?!\/?h5)(?!\/?h6)(?!\/?strong)(?!\/?div)(?!\/?p)(?!\/?br)(?!\/?a)[\s\S]*?>/gi; textBody = textBody.replace(docType, ""); textBody = textBody.replace(comment, ""); textBody = textBody.replace(marquee, ""); textBody = textBody.replace(js, ""); textBody = textBody.replace(/<script[^>]*?\/>/gi, ""); textBody = textBody.replace(/<noscript[^>]*?>([\s\S]*?)<\/noscript>/gi, ""); textBody = textBody.replace(css, ""); textBody = textBody.replace(specialChar, ""); textBody = textBody.replace(liBTag, "\n"); textBodytPreview = textBody; textBody = textBody.replace(otherTag, ""); textBodytPreview = textBodytPreview.replace(removeStyle, "$1$3"); textBodytPreview = textBodytPreview.replace(otherTag_preview, ""); textBodytPreview = textBodytPreview.replace(/(<h1><\/h1>\s{0,}){2,}/gi, "<h1></h1>"); textBodytPreview = textBodytPreview.replace(/(<h2><\/h2>\s{0,}){2,}/gi, "<h2></h2>"); textBodytPreview = textBodytPreview.replace(/(<h3><\/h3>\s{0,}){2,}/gi, "<h3></h3>"); textBodytPreview = textBodytPreview.replace(/(<h4><\/h4>\s{0,}){2,}/gi, "<h4></h4>"); textBodytPreview = textBodytPreview.replace(/(<h5><\/h5>\s{0,}){2,}/gi, "<h5></h5>"); textBodytPreview = textBodytPreview.replace(/(<h6><\/h6>\s{0,}){2,}/gi, "<h6></h6>"); }
这样,我们就得到两个字符串,用于查找聚类的纯文本和用于显示的带部分标签的文本。
4.3 核心算法分析:
将去掉文本的内容以行为单位,看成区域内离散的点,途中红色标出的点就是孤立点,就是我们要找的标题和正文内容:

核心代码:
 View Code
View Code

1 function extractText() { 2 // 去除每行的空白字符 3 lines = textBody.split('\n'); 4 lines2 = textBodytPreview.split('\n'); 5 for (var i = 0; i < lines.length; i++) 6 lines[i] = lines[i].replace(/\s*/gi, ""); 7 8 // 去除上下紧邻行为空,且该行字数小于30的行 9 for (var i = 1; i < lines.length - 1; i++) { 10 if (lines[i].length < 30 && 0 == lines[i - 1].length && 0 == lines[i + 1].length) 11 lines[i] = ""; 12 } 13 14 // 统计去除空白字符后每个行块所含总字数 15 for (var i = 0; i < lines.length - blockHeight; i++) { 16 var len = 0; 17 for (var j = 0; j < blockHeight; j++) 18 len += lines[i + j].length; 19 blockLen.push(len); 20 } 21 22 // 寻找各个正文块起始和结束行,并进行拼接 23 textStart = FindTextStart(0); 24 if (0 == textStart) 25 content = "未能提取到正文!"; 26 else { 27 if (bJoinMethond == 1) { 28 while (textEnd < lines.length) { 29 textEnd = FindTextEnd(textStart); 30 content += GetText(); 31 textStart = FindTextStart(textEnd); 32 if (0 == textStart) 33 break; 34 textEnd = textStart; 35 } 36 } 37 else { 38 textEnd = FindTextEnd(textStart); 39 content += GetText(); 40 } 41 } 42 } 43 44 // 如果一个行块大小超过阈值,且紧跟其后的1个行块大小不为0,则此行块为起始点(即连续的4行文字长度超过阈值) 45 function FindTextStart(index) { 46 for (var i = index; i < blockLen.length - 1; i++) { 47 if (blockLen[i] > threshold && blockLen[i + 1] > 0) { 48 return i; 49 } 50 } 51 return 0; 52 } 53 54 // 起始点之后,如果2个连续行块大小都为0,则认为其是结束点(即连续的4行文字长度为0) 55 function FindTextEnd(index) { 56 for (var i = index + 1; i < blockLen.length - 1; i++) { 57 if (0 == blockLen[i] && 0 == blockLen[i + 1]) 58 return i; 59 } 60 return lines.length - 1; 61 } 62 63 function GetText() { 64 var sb = ""; 65 for (var i = textStart; i < textEnd; i++) { 66 if (lines2[i].length != 0) 67 sb += lines2[i]; 68 } 69 return sb; 70 }
4.4 找出正文,接下来显示即可,我的显示就是在原网页上覆盖一个iframe,这样,因为我们请求过网页,仅仅需要在客户端做这些分析即可,不用再次请求(在网易的新闻做的测试,原网页上):

4.5 感谢HIT-SCIR的陈鑫前辈,感谢华南农业大学信息学院的欧阳佳,林丕源 给我的灵感。
4.6 如果下次有空,在分享我对这个js类库的改进,添加了基于视觉的网页分割算法VIPS。本人学艺尚浅,如果有写的不好的地方,请指教。
QQ:344481058 邮箱:three_zone@163.com
2012年07月05日 修改: 由于有些读者想看整个javascript文件,故将文件共享出来,希望可以与大家一起交流。
多聚旅游 聚游宝 学友网

 浙公网安备 33010602011771号
浙公网安备 33010602011771号