Hdfs&MapReduce测试
Hdfs&MapReduce测试
测试 上传文件到hdfs
随意打开一个文件夹传一个文件试试(把javafx-src.zip传到hdfs的/根目录下):hadoop fs -put javafx-src.zip hdfs://node01:9000/
用客户端(windows主机)浏览器打开 http://node01:50070 能看到这文件(当然,先要在windows配置下hosts,加一行node01 192.168.216.100)

测试 运行一个MapReduce程序
cd hadoop-3.0.0/share/hadoop/mapreduce 有个example程序jar包
hadoop jar hadoop-mapreduce-examples-3.0.0.jar pi 5 5 运行其中一个pi程序,参数是map的任务数量和每个map的取样数
运行失败,log如下
Current usage: 38.3 MB of 1 GB physical memory used; 2.5 GB of 2.1 GB virtual memory used. Killing container.
解决方案:https://blog.csdn.net/paicMis/article/details/73477019 按照这个的方法三,到mapred-site.xml中设置map和reduce任务的内存配置
我设置的参数如下:
<property>
<name>mapreduce.map.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>4096</value>
</property>
<property>
<name>mapred.child.java.opts</name>
<value>-Xmx1024M</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx1024M</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx2048M</value>
</property>
再次运行成功。
Hdfs的实现思想粗略
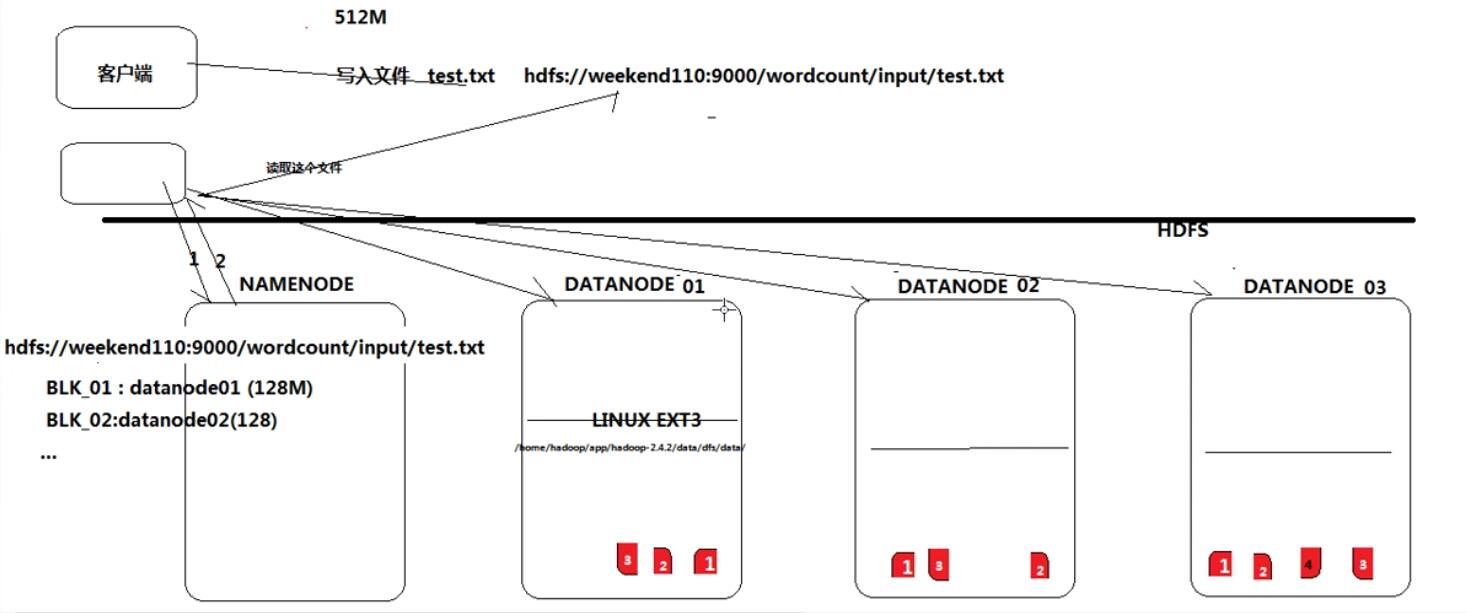
- hdfs是通过分布式集群来存储文件,但为客户端提供了一个便捷的访问方式(一个虚拟的目录结构)
- 文件存储到hdfs集群中去的时候是被切分成block的(由客户端负责切分)
- 文件的block存放在若干台datanode节点上(由hdfs负责拷贝和互传,拷贝出来的第一个副本会优先放在另一个机架上)
- hdfs文件系统中的文件与真实的block之间的映射关系,用namenode管理
- 每一个block在集群中会存储多个副本,可以提高数据的可靠性和访问的吞吐量,提高并发能力
Hdfs的shell操作
基本跟linux上的shell操作类似。hadoop fs(file system)-xx
最常用的shell指令:
hadoop fs -ls
hadoop fs -cat
hadoop fs -put
hadoop fs -get
试试看查看文件
[thousfeet@node01 mapreduce]$ hadoop fs -ls /
Found 5 items
-rw-r--r-- 1 thousfeet supergroup 5202881 2018-03-23 11:30 /javafx-src.zip
drwxr-xr-x - thousfeet supergroup 0 2018-03-23 15:30 /output
drwx------ - thousfeet supergroup 0 2018-03-23 11:42 /tmp
drwxr-xr-x - thousfeet supergroup 0 2018-03-23 11:42 /user
drwxr-xr-x - thousfeet supergroup 0 2018-03-23 12:08 /wordcount
第二列的 1 表示这个文件在hdfs中的副本数,文件夹是元数据是个虚拟的东西,所以没有副本

 浙公网安备 33010602011771号
浙公网安备 33010602011771号