《操作系统真象还原》分页
本节是阅读第五章的收获。下面将阐述一些分页的相关内容。
分页
什么是分页
分页,顾名思义,就是将内存分成大小相同的页。分页,通过映射的方式,将连续的线性地址转化为不连续的物理地址;这样,在处理器进入分页模式之后,用户直接访问的并不是物理地址,而是分页模式下的虚拟地址。
上面有三个和地址相关的概念,分别为虚拟地址、线性地址和物理地址。
在打开保护模式之前,仅有线性地址和物理地址的概念,物理地址就是CPU最终访问的真正地址,是指令或数据真正保存的数据的地方。而线性地址代表“段基址+段内偏移地址”,由于在实模式下,段基址+段内偏移地址等于物理地址,所以线性地址和物理地址数值上是一样的。
而打开保护模式且打开分页模式之后,用户直接访问的是虚拟地址空间或是线性地址空间,线性地址仍然是段基址+段内偏移地址,虚拟地址数值上与线性地址相同。从概念上线性地址空间和虚拟地址空间有些不同,因为线性地址空间只有段的概念,没有页的概念;通过分页机制,将线性地址空间中大小不等的段转化为虚拟空间中大小相等的页。虚拟地址通过页表和页目录转化为最终的物理地址,分页机制如下图:
总的来说,虚拟地址就是分页后程序或任务访问的地址,线性地址就是段基址+段内偏移地址,物理地址是CPU最终访问的地址。
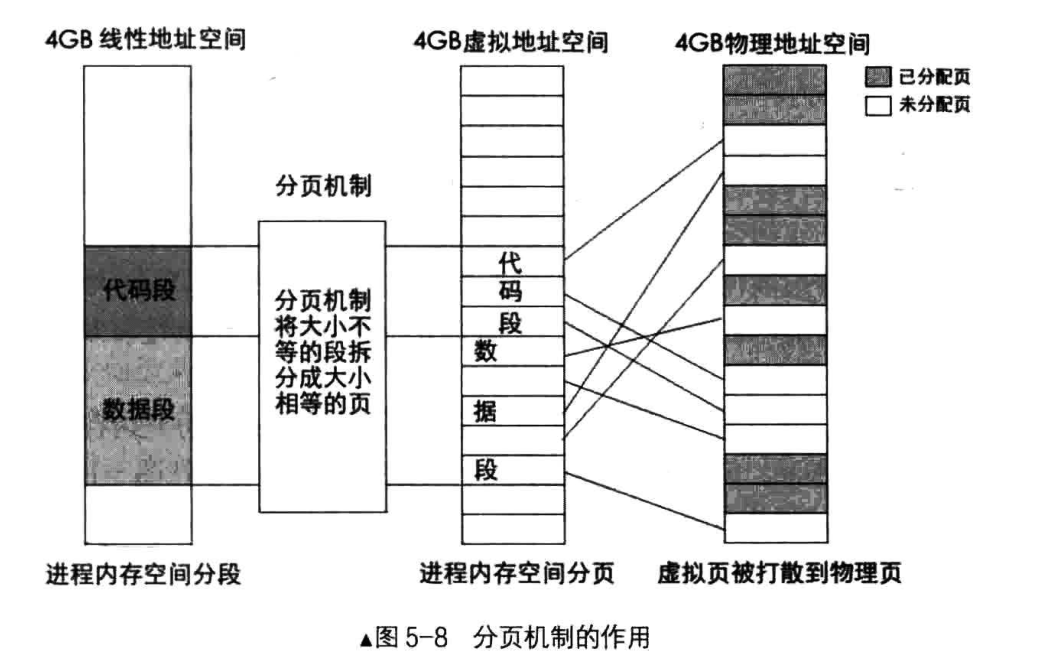
为什么要分页
那么为什么要分页呢?主要原因是内存分配的时候存在外部碎片。本来剩余的内存空间是足以分配给一个任务或进程的,但由于这些剩余的内存片并不连续,我们就不能连续地分配这些内存给任务或进程了。如下图,本来剩余的内存空间是35M,进程D的空间是20M+3KB的空间,按道理来说进程D的空间是少于剩余的内存空间的,应该能够放得下的,但由于进程D需要整一块塞进内存里面,不能拆分,就不能运行进程D了。所以导致不能分配的关键原因是我们分配内存时要求地址是连续的。

有人可能会问为什么内存地址需要连续,不连续不行吗?我们先从指令说起,我们执行指令除非有跳转,都是默认下一条指令地址=当前指令的地址+当前指令的大小,换而言之,都是约定指令执行是连续的;数据也是,一般而言,我们请求一块数据缓冲区,我们都希望这个缓冲区是连续的,这样,我们就能够像数组一样对缓冲区进行连续读写。所以从用户的角度来说,我们都默认一个数据段或者代码段在逻辑上是连续的,这也符合我们的直觉。用户希望空间是连续的,但导致分配失败的原因又是“连续”,那么怎么才能解决这个问题呢?下面来看看分页是怎么解决这个问题的。
分页机制的原理
一级页表
我们仍然希望访问的指令或数据是连续的,希望指令或数据的地址仍然保持着与分页前一样。所以我们像在分段模式下访问内存一样,采用段基址+段内偏移地址的模式访问内存,此时通过段部件输出线性地址,但我们肯定不能让线性地址代表物理地址,否则还是不能解决上述的内存分配的问题。我们这时候拿出了一张表,称为页表,将线性地址逐字节地映射到物理地址上,如下图,比如将0x0地址映射到物理内存0x0,将0x1映射到0x9,将0x2映射到0xfa,以此类推。这样子我们就能够保证用户访问的地址是连续的,但实际上,在物理内存是不连续的;以这种方式,我们能够充分的利用剩余的物理地址空间,不会因为“连续”的约束而导致分配内存失败。所以通过一级页表,我们就能很好地解决外部碎片产生的问题。
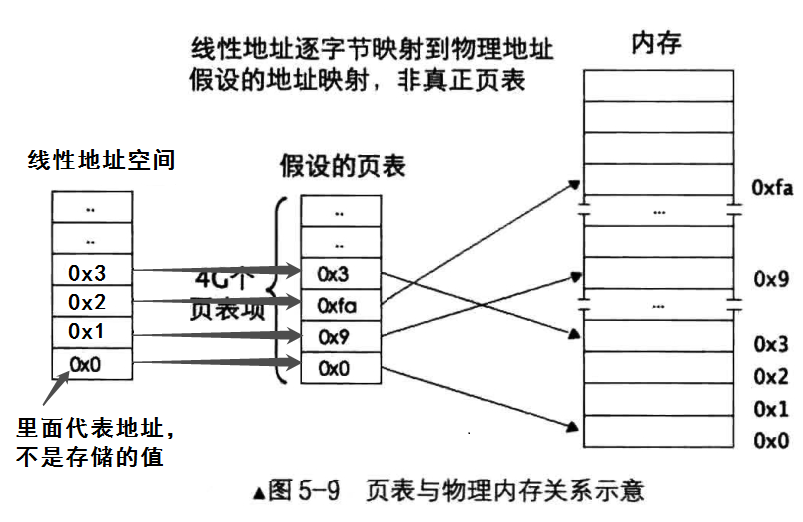
那么,我们再细想一下,上面这种映射方式有什么问题。想一想,假设线性地址空间为4G,也就是有4G个地址,也就是页表里面有4G个页表项,假设一个页表项需要4个字节存储32位地址,那就是一个页表的大小是16G,比线性地址空间还大hhhh。因此,一一映射的方式太耗内存了,所以我们需要减少页表项的开销,页表项存储地址是4个字节变不了了,只能减少页表项的数量。我们将32位地址分为两部分,一部分代表内存块的数量,一部分代表内存块的尺寸,如下图。那么我们怎么找到合适的页尺寸呢,我们分配内存的单位是内存块的尺寸,尺寸太大,内存块数量太少,因而能分配的内存块也就少;尺寸太小,内存块数量太多,这样页表的开销就很大。所以我们只能折中选个值,而现在CPU采用的内存块大小恰好是4KB,这样内存块的数量就是1M个,我们就按这个值来吧。
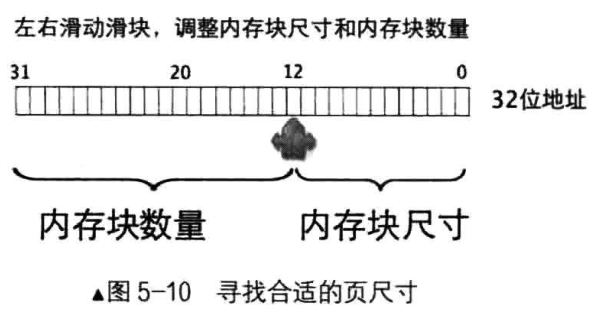
这样,我们不再将内存每个字节一一映射了。通过线性地址的高20位去索引页表的页表项找到对应的内存块基址,线性地址的低12位去索引这个内存块。既能够保证页表的大小不至于太大,也能确保分配的内存块不至于太少,也消除了外部碎片和“连续”导致的问题,其实已经差不多了,但一级页表并不是我们现在操作系统采用的页表模式,因为一级页表还是有一些问题,我们接下来继续来讨论。
二级页表
一级页表已经很好了,为什么还不够呢。我们下面来讨论一下一级页表问题。
①一级页表有1M个页表项,也就是一个页表需要4M的内存空间,并且4M的内存空间也是需要连续分配的,这和采用页表的原因类似,如果内存的外部碎片过多,本来剩余的内存空间>4M的,但由于这些剩余内存并不连续,这样就分配不了内存给一个页表了。我们通过二级页表,将连续的4M内存划分为1K个4K大小的页,这样我们既可以用页为任务分配内存空间,也可以用页去为页表分配空间,给页表分配空间就不再具有特殊性了,不再需要连续了。
②一级页表,一定需要完整的4M的内存空间,这是肯定的,如果不分配完整的4M空间,某一些内存地址就访问不到了。每一个进程都会有一份页表的,如果进程数量很多,页表占用的内存还是挺可观的。采用二级页表就能节省空间,二级页表只需要为那些用到的内存地址分配页表;那些没有用到的内存地址,除非与用到的内存地址用到同一块页表,否则是不会分配页表的。所以,一级页表一般会比二级页表消耗更多的内存。
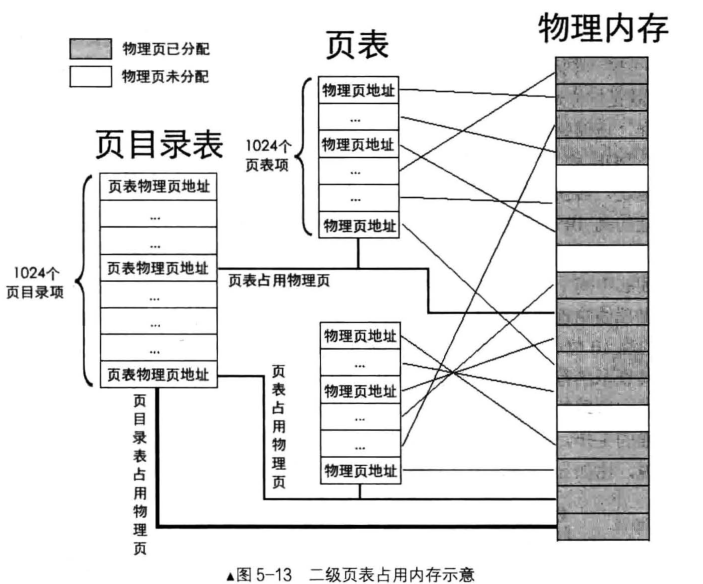
下面来描述一下二级页表的结构,二级页表与一级相比多了一层,我们称这层为页目录。接着说,二级页表将一级页表的1M个页表项继续划分,将1M个页表项均分到1K个页表里,也就是1个页表有1K个页表项,这样1个页表的大小就是4K,正好一个页的大小。一个页表能索引的内存大小就是1K*4K=4M,1K个页表就能索引4M*1K=4G内存。页表已经划分好了,那么我们就需要考虑怎么索引到对应的页表。这时候页目录正式登场,页目录有1K个页目录项,一个页目录项指向一个页表,这样整个二级页表的结构大致就这样组成。
那么如何将线性地址(虚拟地址)转换为最终的物理地址呢,和二级页表的关系是什么? 和一级页表类似,只不过32位的地址被划分为3个部分,高10位用来索引页目录找到页表的物理地址,中10位用来索引页表找到页的基址,低12位用于索引页。
举个例子,如下图,指令是mov ax, [0x1234567],将0x1234567铺开到二进制0000_0001_00 1000_1101_00 010101100111后,可以得到页目录索引为4,页表的索引为0x234,页的索引为0x567。
一个页目录项和页表项的大小为4B,设页目录的基址为DIR_BASE,页表的基址为PAGE_BASE,DIR_BASE+0x4 *(页目录项的大小4)=页目录索引为4所对应的物理地址,读取该物理地址存储的地址0x1000,即PAGE_BASE=0x1000。继续找页的基址,PAGE_BASE+0x234*(页表项的大小4)=页表索引为0x234时所对应的物理地址,同样读取该地址存储的地址0xfa000。继续找最终的物理地址,0xfa000+0x567=0xfa567得到最终的物理地址。

从虚拟地址到物理地址的转换是由页部件去完成的,操作系统只需要准备好相应的结构,即可让页部件去计算最终的物理地址。
进入分页模式
接下来,我们开始尝试编写代码,进入分页模式。
进入分页模式有三个步骤:
①准备好页目录和页表。
②将页目录地址加载到cr3控制寄存器。
③将cr0控制寄存器的PG位打开。
代码改动如下,头文件boot.inc在最后贴:
[bits 32] p_mode_start: mov ax, SELECTOR_DATA mov ds, ax mov es, ax mov ss, ax mov esp,LOADER_STACK_TOP mov ax, SELECTOR_VIDEO mov gs, ax ; 创建页目录及页表并初始化页内存位图 call setup_page ;要将描述符表地址及偏移量写入内存gdt_ptr,一会用新地址重新加载 sgdt [gdt_ptr] ; 存储到原来gdt所有的位置 ;将gdt描述符中视频段描述符中的段基址+0xc0000000 mov ebx, [gdt_ptr + 2] or dword [ebx + 0x18 + 4], 0xc0000000 ;视频段是第3个段描述符,每个描述符是8字节,故0x18。 ;段描述符的高4字节的最高位是段基址的31~24位 ;将gdt的基址加上0xc0000000使其成为内核所在的高地址 add dword [gdt_ptr + 2], 0xc0000000 add esp, 0xc0000000 ; 将栈指针同样映射到内核地址 ; 把页目录地址赋给cr3 mov eax, PAGE_DIR_TABLE_POS mov cr3, eax ; 打开cr0的pg位(第31位) mov eax, cr0 or eax, 0x80000000 mov cr0, eax ;在开启分页后,用gdt新的地址重新加载 lgdt [gdt_ptr] ; 重新加载 mov byte [gs:160], 'V' ;视频段段基址已经被更新,用字符v表示virtual addr jmp $ ;------------- 创建页目录及页表 --------------- setup_page: ;先把页目录占用的空间逐字节清0 mov ecx, 4096 mov esi, 0 .clear_page_dir: mov byte [PAGE_DIR_TABLE_POS + esi], 0 inc esi loop .clear_page_dir ;开始创建页目录项(PDE) .create_pde: ; 创建Page Directory Entry mov eax, PAGE_DIR_TABLE_POS add eax, 0x1000 ; 此时eax为第一个页表的位置及属性 mov ebx, eax ; 此处为ebx赋值,是为.create_pte做准备,ebx为基址。 ; 下面将页目录项0和0xc00都存为第一个页表的地址, ; 一个页表可表示4MB内存,这样0xc03fffff以下的地址和0x003fffff以下的地址都指向相同的页表, ; 这是为将地址映射为内核地址做准备 or eax, PG_US_U | PG_RW_W | PG_P ; 页目录项的属性RW和P位为1,US为1,表示用户属性,所有特权级别都可以访问. mov [PAGE_DIR_TABLE_POS + 0x0], eax ; 第1个目录项,在页目录表中的第1个目录项写入第一个页表的位置(0x101000)及属性(7) mov [PAGE_DIR_TABLE_POS + 0xc00], eax ; 一个页表项占用4字节,0xc00表示第769个页表占用的目录项,0xc00以上的目录项用于内核空间, ; 也就是页表的0xc0000000~0xffffffff共计1G属于内核,0x0~0xbfffffff共计3G属于用户进程. sub eax, 0x1000 mov [PAGE_DIR_TABLE_POS + 4092], eax ; 使最后一个目录项指向页目录表自己的地址 ;下面创建页表项(PTE) mov ecx, 256 ; 1M低端内存 / 每页大小4k = 256 mov esi, 0 mov edx, PG_US_U | PG_RW_W | PG_P ; 属性为7,US=1,RW=1,P=1 .create_pte: ; 创建Page Table Entry mov [ebx+esi*4],edx ; 此时的ebx已经在上面通过eax赋值为0x101000,也就是第一个页表的地址 add edx,4096 inc esi loop .create_pte ;创建内核其它页表的PDE mov eax, PAGE_DIR_TABLE_POS add eax, 0x2000 ; 此时eax为第二个页表的位置 or eax, PG_US_U | PG_RW_W | PG_P ; 页目录项的属性US,RW和P位都为1 mov ebx, PAGE_DIR_TABLE_POS mov ecx, 254 ; 范围为第770~1023的所有目录项数量 mov esi, 769 .create_kernel_pde: mov [ebx+esi*4], eax inc esi add eax, 0x1000 loop .create_kernel_pde ret
setup_page,首先将页目录的4K内存清空位0,然后开始创建页目录项,将第1个和第769个(这里页目录和页表项从1开始算)页目录项设为第一个页表的地址;将最后一个页目录设为页目录的地址,将第一个页表映射到低1M的物理内存;将第770~1023的页目录项设置成第2~255个页表的地址,第2~255个页表是紧接着第1个页表之后的。流程图如下:
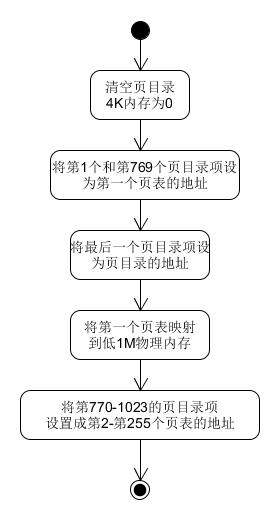
下面解释一下各个步骤的意义:
① 清空页目录的内存作初始化,防止原来存在的数据指向错误的地方。
② 将第1个和第769个页目录项设置为第一个页表的地址,而后面第一个页表映射到了低1M物理内存,低1M物理内存存储着内核程序。主要是因为打开分页模式之后,首先获得的是虚拟地址,然后将这个虚拟地址转换到最终的物理地址。所以试图访问内核程序的地址已经变成了虚拟地址了,如果最后转换到的物理地址不是原来的物理地址就会出问题。举个例子,假设内核程序在打开分页模式之前,通过地址0x900读写变量A,此时的地址是线性地址,也是物理地址,因为还没打开分页模式;但是打开分页模式之后,我们再想读写这个变量A时,提交的还是0x900,但是这个地址已经变成了虚拟地址了,处理器最终要访问的是物理地址,而变量A的物理地址仍然是0x900,所以需要将虚拟地址0x900映射到物理地址0x900,即一一对应,这样才能保证之前的程序能够正确运行。综上,我们需要将虚拟地址空间的低1M与物理地址的低1M进行一对一映射。将第769个页目录项设置为第一个页表的地址,主要是将虚拟地址空间的高1G内存作为内核程序的空间,以后试图请求内核程序的帮助都会访问高1G内存的空间;而低1M内存也属于内核程序的一部分,所以将0xc000 0000~0xc001 0000也映射到低1M的物理地址。
③ 将最后一个页目录项指向页目录。想一想,如果我们高10位索引到了最后一项页目录,那中10位相当于也在索引页目录,那么低12位最终索引的是页表,对不对?所以,将最后一个页目录项指向页目录的作用是对页表进行操作。再细想一下,我们通过什么地址可以对页表进行操作。
a. 我想最终访问页目录表,获得页目录项存储的页表地址。将高10位设置为最后一项页目录的索引,将中10位也设为最后一项页目录的索引,低12为再索引页目录表即可。
b.我想最终访问页表,获得页表项存储的页地址。将高10位设置为最后一项页目录的索引,将中10位设为某个页目录项的索引,低12位就可以索引页表了。
④ 将第770~1023的页目录项设置为第2~255个页表的地址,按书上的说法是与之后建立用户进程相关,咱不在这里讨论。
调用setup_page之后,将视频段描述符段基址+0xc000 0000,禁止用户进程直接访问显存,只能通过高1G的内核空间去访问显存。将栈指针和GDT也映射到内核地址空间。最后按三部曲打开分页模式。
运行程序
我把boot.inc搬到了include文件夹下,按下面的指令编译代码, -I指定头文件的目录位置,注意别把include后的'/'漏了:
nasm -I include/ -o loader.bin loader.S
写进硬盘,count写大点没关系,dd指令会自动识别代码长度,写到200都没关系hhh,重点是不能写少,否则代码没写全进硬盘就会出问题:
dd if=./loader.bin of=./hd60M.img bs=512 count=3 seek=2 conv=notrunc
接下来执行代码:
bin/bochs -f bochsrc.disk
执行结果如下图:
再通过info tab看一下虚拟地址到物理地址的映射结果:
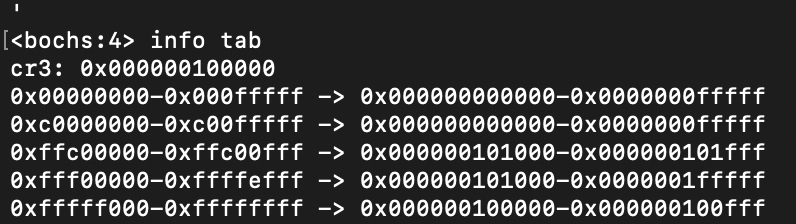
结果和上面讨论的一致,低1M和高1G内存的低1M的虚拟地址映射到了低1M的物理地址,通过最后一个页目录项最终可以访问到255个页表和页目录。
TLB
TLB,Translation Lookaside Buffer,简称快表。和段描述符缓存寄存器类似,毕竟每次访问地址都要访问一次内存里面的页目录、页表太耗时间了,比起CPU执行指令或访问寄存器这些要慢一个数量级,所以缓存又出来了。TLB高速缓存,用于缓解处理器与内存访问速度之间的不匹配。结构大致如下,保存着虚拟地址高20位到物理地址高20位的映射,这样子就能加快对内存的访问,不用每次访问内存都要问一下页表。当然,这样子处理器访问内存的话,首先访问到的就是TLB,所以务必保证TLB的有效性。
TLB的有效性是由谁去保证呢?处理器?并不是,TLB什么时候会失效?页目录和页表数据被改变得时候就会失效,这时候操作系统肯定是知道的,所以维护TLB的有效性的工作就交给了操作系统。有什么办法可以更新TLB呢,一种是通过invlpg指令刷新某个虚拟地址对应的条目;一种是重新加载页目录,使整个TLB失效,进而重新加载TLB数据。

头文件boot.inc
重新贴一下头文件boot.inc:
;------------- loader和kernel ---------- LOADER_BASE_ADDR equ 0x900 LOADER_START_SECTOR equ 0x2 KERNEL_BIN_BASE_ADDR equ 0x70000 KERNEL_IMAGE_BASE_ADDR equ 0x1500 KERNEL_START_SECTOR equ 0x9 PAGE_DIR_TABLE_POS equ 0x100000 ;-------------- gdt描述符属性 ------------- DESC_G_4K equ 1_00000000000000000000000b DESC_D_32 equ 1_0000000000000000000000b DESC_L equ 0_000000000000000000000b ; 64位代码标记,此处标记为0便可。 DESC_AVL equ 0_00000000000000000000b ; cpu不用此位,暂置为0 DESC_LIMIT_CODE2 equ 1111_0000000000000000b DESC_LIMIT_DATA2 equ DESC_LIMIT_CODE2 DESC_LIMIT_VIDEO2 equ 0000_000000000000000b DESC_P equ 1_000000000000000b DESC_DPL_0 equ 00_0000000000000b DESC_DPL_1 equ 01_0000000000000b DESC_DPL_2 equ 10_0000000000000b DESC_DPL_3 equ 11_0000000000000b DESC_S_CODE equ 1_000000000000b DESC_S_DATA equ DESC_S_CODE DESC_S_sys equ 0_000000000000b DESC_TYPE_CODE equ 1000_00000000b ;x=1,c=0,r=0,a=0 代码段是可执行的,非依从的,不可读的,已访问位a清0. DESC_TYPE_DATA equ 0010_00000000b ;x=0,e=0,w=1,a=0 数据段是不可执行的,向上扩展的,可写的,已访问位a清0. DESC_CODE_HIGH4 equ (0x00 << 24) + DESC_G_4K + DESC_D_32 + DESC_L + DESC_AVL + DESC_LIMIT_CODE2 + DESC_P + DESC_DPL_0 + DESC_S_CODE + DESC_TYPE_CODE + 0x00 DESC_DATA_HIGH4 equ (0x00 << 24) + DESC_G_4K + DESC_D_32 + DESC_L + DESC_AVL + DESC_LIMIT_DATA2 + DESC_P + DESC_DPL_0 + DESC_S_DATA + DESC_TYPE_DATA + 0x00 DESC_VIDEO_HIGH4 equ (0x00 << 24) + DESC_G_4K + DESC_D_32 + DESC_L + DESC_AVL + DESC_LIMIT_VIDEO2 + DESC_P + DESC_DPL_0 + DESC_S_DATA + DESC_TYPE_DATA + 0x0b ;-------------- 选择子属性 --------------- RPL0 equ 00b RPL1 equ 01b RPL2 equ 10b RPL3 equ 11b TI_GDT equ 000b TI_LDT equ 100b ;---------------- 页表相关属性 -------------- PG_P equ 1b PG_RW_R equ 00b PG_RW_W equ 10b PG_US_S equ 000b PG_US_U equ 100b

 浙公网安备 33010602011771号
浙公网安备 33010602011771号