
6.824 FaRm
FaRM以及乐观锁并发控制
讨论FaRM1的原因,因为它是事务和Replication以及数据分片这块最后一片paper,这依然是一个开放的研究领域。人们对这块的性能依旧不满意,人们在性能和一致性方面,人们想要做出一定的取舍。这些新的具备RDMA能力的NIC拥有巨大的性能潜力,从而激发了人们写出这篇paer
Spanner和FaRM 有啥不同,在事务方面,他们俩都使用了复制和两阶段提交,从这个层面砍,他们非常相似,Spanner这个系统已经被广泛使用了很长一段时间,它的主要重心在于地理区域级别的复制,这使得我们能够在东海岸,西海岸的不同数据中心中建立副本,并且我们在处理涉及许多不同地方数据的事务的能力也很高效,为了解决跨远程进行二阶段提交上的时间问题,其中最具创新的地方在于,对于只读事务,通过使用同步时间,它拥有一种特别的优化路线,对于spanner所消耗的性能来说,如果你还记得的话,一个读写型事务要花10 到100 毫秒才能完成,并且这也取决于不同数据中心的距离远近。
FaFM做出了一些非常不同的设计决策,并且针对的workload也非常不同。
首先,它是一种研究原型,并不是一个完善的产品。其目标在于探索这些新的RDMA高速网络硬件的潜力,它已然是一个探索性质的系统。它所假设的情况是,所有的replica都在同一个数据中心,如果这些replica是在不同的数据中心,比如一部分在东海岸数据中心,一部分在西海岸数据中心,那么这就没有意义了,它并不会去试着解决Spanner所要解决的问题。比如整个数据中心挂掉,那我还能拿到我的数据吗。它的容错能力范围可能是针对单个服务器的崩溃。当一整个数据中心发生供电故障,之后供电恢复后,它会试着去恢复数据。
它使用了RDMA这项技术,严重限制了设计选项,因为这个原因,FaRM强制使用了乐观锁并发控制。 另一个方面,他们所获得的性能远比Spanner高得多,FaRM在58微秒内就可以完成一个简单事务。FaRM的性能比Spanner高出太多。
但它并不是用于解决Geographic replication的。FaRM的性能令人印象非常深刻。Spanner和FaRM针对的是不同瓶颈。在Spanner中,人们所担心的主要瓶颈在于卫星信号传播上的延迟以及数据中心间的网络延迟,在FaRM中主要瓶颈在于服务器上的CPU时间。因为他们希望通过将所有的replica放在同一个数据中心,以此消除卫星信号和网络传播所带来的影响。
这里有一个配置管理器,我们以前就见过,配置管理器回去决定每个数据分片中哪台服务器是primary,哪台服务器是backup。如果你仔细读过,你就会知道,他们使用了zookeeper来帮会他们实现配置管理器。 我们感兴趣的是,他们根据key将数据进行分片并分散到一堆primary-backup pair上去。我的意思是每个数据分片对应了一个primary 服务器和一个backup服务器,这里对应P1和B1。当你每次更新数据的时候,primary和backup上的数据你都得去进行更新。这些replica并不是由Paxos之类的东西来进行维护的。当有一处发生了改变,那么该数据所属的所有replica都会进行更新。如果你要去读取数据,那么你始终得从primary处读取数据。使用了这种replication方式的理由当然就是为了具备容错能力。他们所获得的能力是只要给定数据分片中的一个replica是可用的,他们只需要一个活着的replica就行了,而不是大多数。如果一个数据中心发生了供电故障,该系统中的每个数据分片之一奥有一个replica可用,那么它就可以恢复过来。另一种方式是,如果他们有f+1个replica,那么对于这个数据分片来说,他们就可以容忍f个replica发生故障。除了每个数据分片所对应的primary-backup副本以外,它还运行着事务协调器,为了方便起见,我们可以将事务协调器当做独立的client来看待,在他们的实验中,他们将事务协调器和FaRm的存储器放在同一台机器上运行,但我主要觉得他们会是一组独立的client,这些client回去执行事务,这些事务需要去对保存在数据分片上的数据对象进行读写。此外每个client除了执行事务以外,他们还扮演了两阶段提交中的事务协调器的角色,这也是他们获得高性能的方式,这就是paper中他们获得高性能的方式,同时他们依然可以对事务进行处理。他们获得高性能的其中一种方式就是对数据进行分片,某种意义上来讲,他们所使用的主要方式就是数据切片,他们将他们的数据进行分片并拆分到90台服务器上,或者可能是45台服务器上,只要在不同数据分片上锁进行的这些操作是彼此独立的。那么你就能获得90倍左右的处理速度,这就是数据分片所带来的巨大好处,-。
为了获得良好的性能,他们所玩的另一个技巧是他们将所有的数据放在来服务器的RAM中,他们并没有真的将数据放在磁盘上,而是将数据都放在了RAM中,这意味着你的速度就会变得非常快,他们获得高性能的另一种方式是,他们需要去容忍供电故障,这意味着,他们不能值使用RAM,因为当发生了供电故障,他们得去对数据进行恢复,因为供电故障的缘故,RAM数据可能会丢失,所以他们使用了一种更好的NVRAM(非易失性RAM)方案来解决RAM因供电故障导致数据全丢的情况,这与将数据持久存储在磁盘上相反,这种做法要比使用磁盘来的更快。
他们所使用的另一个技巧就是使用了RDMA技术,简单来讲就是,在不对服务器发出中断信号的情况下,他们通过网络接口卡(NIC)接受数据包并通过指令直接对服务器内存中的数据进行读写,他们所玩的这种技巧通常叫做 kernel bypass,在不涉及内核的情况下,应用层代码可以直接访问网络接口卡,我们所看的这些技术就是他们用来获得高性能的方式,关于数据分片这块我们已经讨论过很多了。
首先我们要讨论下非易失性RAM,这个主题并不是直接影响整个设计的其他部分,FaRm中所有的数据都是存放在RAM中的,当一个client所执行的事务对一份数据进行了更新时,这意味着它会让存储这该数据的相关服务器去对数据对象进行修改,事务会在RAM中对该数据对象进行修改。这样他们就无须跑到硬盘上对数据进行修改了,与诸如raft之类的实现相比,这样就省去了将数据落地刀磁盘时所花的大量时间,在FaRm中并不需要将数据持久化到磁盘,这是一个很大的好处,将数据写入RAM中需要话200纳秒,虽然固态硬盘的速度很快,但要将数据写入固态硬盘这得话100微秒,如果是普通的机械硬盘,那就得话10毫秒了,从各种方面来说,将数据写入RAM还是很值得,比如事务修改数据的速度会大大提高,如果遇上供电不足,RAM就会丢失它里面的东西,它并不是持久化的,从一方面来看,如果我们有多个replica服务器,那我们就得对着多台服务器的RAM中的数据进行更新,持久性可能就很高,如果你有f+1replica,那么你最多可以容忍f个replicca发生故障,将数据写入多个服务器上的RAM并不是那么好的原因是站点范围内的供电故障会摧毁你所有服务器上的数据。因此这就违反了我们所做的假设,即不同服务器所发生的故障都是互不相干的,我们需要一种方案,即使整个数据中心的供电都出现了问题,系统依然能够工作,FaRm所做的事情是它在每个机架上都放了一个大电池,它将这些电池组成了一个供电系统,来为服务器进行供电,如果发生供电故障,这些电池会自动接手对服务器的供电工作,并让所有的机器继续运行,只是奥这可以撑到电池出现问题为止(比如没电了),这些电池容量并不大,它只能够让他们的服务器再坚持个10分钟左右,电池自身并不足以让系统能够应对持续时间很长的供电故障,当电池系统看到主电源出现了故障,电池系统会让服务器继续运行,它就会向所有的服务器发出消息,并说,知道电池耗尽前,你们还剩下10分钟了,借着,他就会想所有的服务器发出消息,并说,直到电池耗尽前,你们还剩下10分钟了,此时,FaRm服务器上的软件回西安区停止FaRm所做的所有操作,接着,它会将每台服务器的RAM中的所有数据复制到该服务器所挂载的固态硬盘上,我希望这个过程只需要花几分钟就好了,一旦RAM中所有的数据都复制到固态硬盘中,机器就会关机,如果遇上大范围的供电故障,所有的机器会将他们RAM中的数据保存到磁盘,当数据中心的供电恢复时,所有机器都会重启并恢复RAM中的数据,这里也需要去做一些恢复工作,他们不会因为供电故障而丢失他们已经持久化的状态,这意味着,FaRm使用的还是传统的RAM,但本质上来讲,使用后备电源来做刀RAM的非易失性,使得数据能够从供电故障中存活下来,后背电源系统会向服务器发出警告让他们将RAM中的数据存储到服务器所挂在的固态硬盘中。这种NVRAM方案适用于供电故障,但对其他类型的崩溃并不适用,所以每个数据分片还有多个repilica。
NVRAM方案消除了系统在持久化写操作方面的性能瓶颈,还剩下网络和CPU两个方面。
如果数据中心出现了供电故障,并且FaRm丢失了固态硬盘中的所有数据,我们是否有可能将所有数据转移到另一个数据中心并继续操作,从原则上来讲,这是绝对可以做到的。在实战中,我觉得还是恢复数据中心的供电会来的更容易,然后再移动硬盘中的数据,现在的问题是老的数据中心没有电了,那么你就得通过物理手段来移动磁盘以及服务器,可能只是将此次盘转移到新的数据中心就行了,但这并不是FaRm的设计人员所考虑的情况,他们假设的电源会恢复的情况,这就是NVRAM的相关内容。除了我们所关心的将数据希尔磁盘以外,设计中的其他部分都不会和它有所交互。,正如我提到的那些剩下的性能瓶颈,一旦你洗消除了将数据持久化到磁盘的这个问题。那我们所需要应对的其他性能瓶颈就在CPU和网络这块了。在FaRm以及我所参与的许多系统中,他们中存在了一个巨大的瓶颈,即我们需要通过CPU的时间来处理网络交互,此处CPU就成了性能上的一个综合瓶颈。FaRm不存在任何网络上的问题,设计人员花了大量时间和精力消除服务器间数据交换的性能瓶颈。
背景,先说这里传统架构,比如不同服务器上应用程序间的RPC数据包交换。
一台服务器可能想去发送一条RPC消息,你可能会有一个应用程序。该应用程序在用户空间中运行着,用户态和内核态之间存在着一条界限,为了发送数据,应用程序得调用内核中的系统调用,但这样做的成本并不低。然后,在内核中还存在着一大堆软件,我们要通过他们在网络中发送数据,通常,这会有一个叫做Socket层的东西,它的作用是对数据进行缓存,这设计到了复制数据,这个操作需要花些时间,通常这里还会有一个复杂的TCP协议栈,它知道所有关于重传,序列号,checksum以及flow control的所有相关事情。这里有一个叫做网络接口卡(NIC)的硬件,内核可以对它上面的一堆进村器进行通信和配置
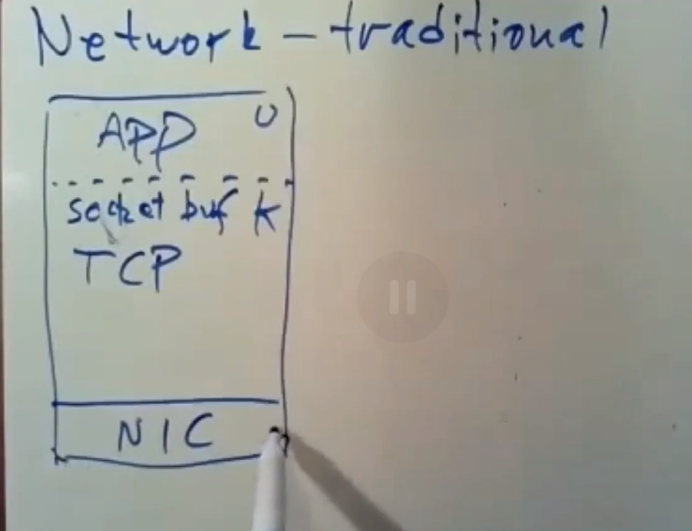
在内核中存在着某种网络接口卡驱动,他所做的就是通过网络接口卡直接往主机内功读取和写入数据包,这里会有一个队列之类的东西,它里面放着网络接口卡通过DMA 访问内存时所拿到的数据,并等待内核去读取这个队列中的数据包。
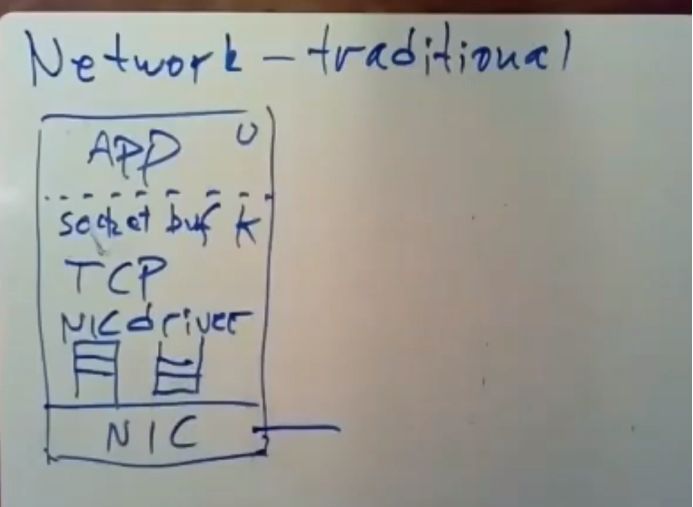
然后这里还有一个用于对外发送数据的数据包队列,这样的话,网络接口卡可以尽可能方便地将数据发送出去。你想去发送一条RPC请求之类的东西,应用程序会一步步往下走,网络接口卡会通过网线发送bit信息,在另外一边会有一个相反的栈
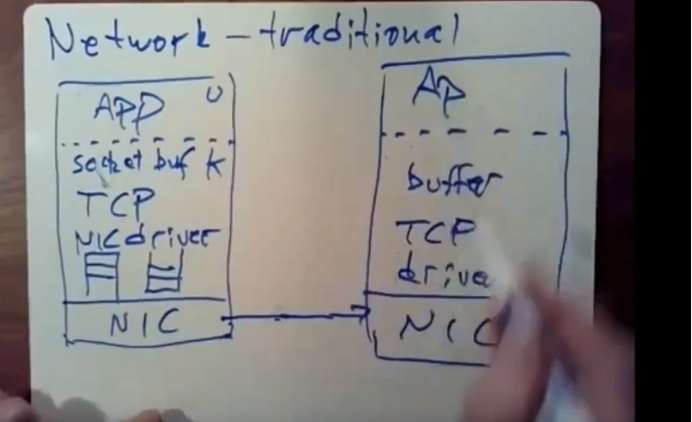
,在某个时间点,应用程序回去读取buffer的数据,通过系统调用将内核buffer中的数据拷贝到用户态空间里。这里们存在大量软件操作,大量的处理以及很多十分消耗CPU的资源操作,比如系统调用,interrupt中断以及复制数据。因此传统的网络通信的速度是比较慢的,我们通过这种传统架构是很难构建出这种RPC系统,在这种架构下很难做到每秒钟传输数十万RPC消息,这可能看起来很多,但对于FaRm所要达到的性能目标来说,还是太少了,基本上来讲,每秒钟传输数十万条RPC消息远远小于网络接口卡通过网线传输的上限。这些网线传输的速度是每秒10GBIT,数据库通常需要使用信息大小很小,在这种情况下,我们很难去写一个RPC软件,使之每秒能够生成10GBIT大小的消息。它的速度可能是是每秒数百万条消息,也可能是每秒数千万条消息。
FaRm通过两种思路来减少推送数据包的成本。
方案一:kernel bypass
与其让应用程序通过调用复杂的内核代码来发送所有数据,相反,通过对内核保护机制进行配置,以此来让应用程序直接访问网络接口卡,应用程序实际上可以去访问网络接口卡上的寄存器,并告诉它应该做什么,当使用这种DMA以及kernel Bypass 方案时,,通过DMA,它能直接访问应用程序内存,在不需要内核参与的情况下,应用程序可以直接看到那些到达的字节信息

当应用程序需要发送数据时,应用程序可以去创建一些队列,网络接口卡可以直接通过DMA来读取数据,并通过网线将数据发送出去,现在我们旧已经消除了所有设计网络的内核代码调用,即内核不会参与这些操作,这里也没有系统调用,也没有interrupt中断。应用程序可以直接对内存进行读写,网络接口卡可以直接看到这些内容,对另一边也是如此。对于过去几年的网络接口卡来说,这种想法实际上是不切实际的。但是新的网络接口卡是可以通过设置来做到这一点的,但是它需要应用程序去做到TCP所谓我们做到的那些事情。比如,checksums或者重新传输,如果我们想要这么做,那么这些东西我对是由应用程序来进行负责的。实际上,你可以自己来做到这点,kernel bypass 使用了一个叫做DPDK的工具包,你们可以在网上找到,它使用起来相对简单,并且能够让人们写出性能非常高的网络应用程序,
FaRm确实使用了这个工具,FaRm确实使用了这个工具,应用程序可以直接和NIC进行通信,NIC通过DMA能看到写入应用程序内存中的数据。
现在NIC实际上知道该如何和多个不同的队列进行通信,你可以运行多个应用程序,并且每个应用程序都有它自己的一组队列,NIC知道该如何跟他们进行通信,这确实需要修改很多东西,第一步是去使用kernel Bypass这种方案。
第二步是一种更为聪明的办法
现在我们要去讨论一种目前还没有广泛使用的硬件,你可以买到它,但这不是默认的,这种RDMA方案指的是远程直接内存访问。这是一种特殊的网络接口卡,它支持RDMA,现在我们就有了一个支持RDMA的NIC,这两边都得有这种特殊的网络接口卡,在我画的这张图上,他们是通过网络连接的,这里会有一台交换机,有很多不同的服务器都和它连接在一起,通过它可以与任意的服务器进行通信
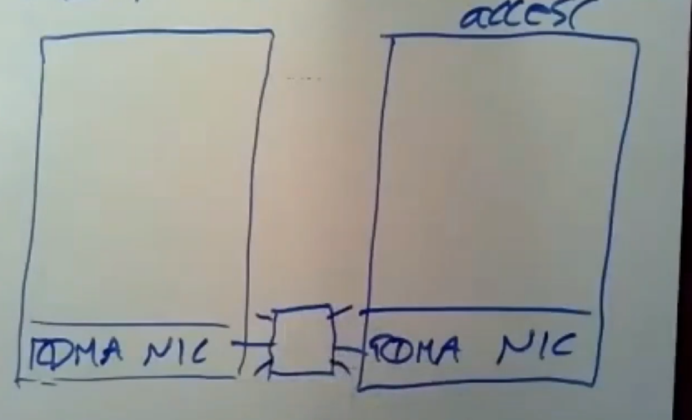
我们使用了这些支持RDMA的NIC,这里我们有一些应用程序,应用程序可以通过NIC来发送一条特殊的信息,我们在源主机这块运行着一个应用程序,我们将另一边的主机叫做目标主机,它(源机)可以通过RDM系统发送一条特殊的消息来告诉网络接口卡让它直接对目标应用程序地址空间中的内存直接进行读写操作,网络接口控制器上的硬件和软件会对应用程序的内存直接进行读写操作
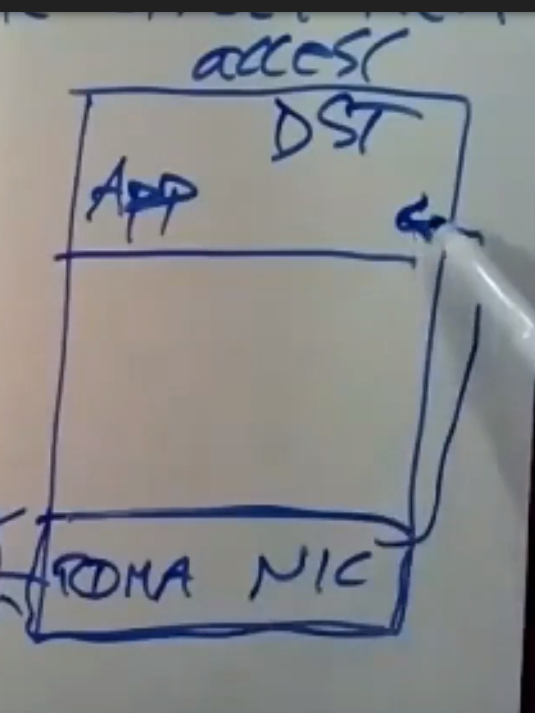
我们会将一个请求发送到这里,它会引起读操作或者写操作,目标应用程序会将响应结果返回给源应用程序的incoming queue 中,

对此,比较cool的地方在于这台服务器上的cpu和应用程序对于刚刚所做的读操作或者写操作并不知情,读操作或者写操作完全是在网络接口卡的固件中执行的,这里不会有interrupt中断发生,应用程序不用考虑请求或者响应之类的事情,目标主机上的网络接口卡只需去对应用程序内存进行读取或写入操作,然后将结果返回给源应用程序即可,这种做法的开销会很低很低,你所要做的事对目标应用程序RAM中的数据进行读写,通过使用这种很神奇的kernel bypass networking,在进行简单的读和写的时候,它要远远比通过普通的RPC调用来发送信息的方式快得多。
paper中使用了一个特定术语,那就是one-sided RDMA,这就是我已经刚才提到的东西,当应用程序通过TDMA对另一个机器上内存中的数据进行读写时,这里使用了one-sided RDMA,FaRm使用了RDMA通过RPC之类的协议来发送信息,事实上,FaRm有时候会通过one-sided RDMA来直接读取数据,但FaRm有时候使用了RDMA是用来给目标对象的incoming message queue 追加消息的,实际上,这里追加的使用时写操作相关的消息,FaRm实际上会通过RDMA来给目标对象的incoming queue 追加一条新的消息,目标机器会进行轮询,因为这里没有人发出interrupt 信号,在目标机器这块,我会对内存中所接受到的消息进行定期检查,来看看其他人在最近是否有给我发送信息的。我是用RDMA是为了进行读和写,我还可以用RDMA发送或追加一条信息给一个消息队列或者日志,有时候,FaRm也会使用RDMA去给另一台服务器的日志追加消息或者日志条目,我们往这块内存中所修的数据都是不可丢失的,如果发生供电故障,那么这些消息队列中的数据都会被写入磁盘, figure 2 向我们展示了其性能,通过RDMA,我们每秒钟能够处理1000万次读写操作,这一点很棒,这要比使用TCP来发送RPC之类的消息速度要快太多,使用RDMA来进行简单的读或者写操作所导致的延迟只有5微秒,这要比你访问自己本地内存来得慢,但这要比人们在网络中所做的其他任何事情都要来得快,这其实是一种期望,搞FaRM的这群人想要去利用这种出现不久如同黑科技般的RDMA技术,通过它去做酷炫的事儿就是通过one-sided RDMA来直接对保存在数据库服务器内存中的记录进行读和写,如果我们不需要去和数据库服务器CPU或者软件进行通信,但通过使用one-sided RDMA能在5毫秒内就可以拿到我们需要的数据,并对其进行读写,这简直不要太棒。你可以根据这篇paper来构建出一些很有用的东西,这里有一个领我们很感兴趣的问题,
我们能否只是用one-sided RDMA来实现事务,即在不发送那些必须由服务器软件进行届时的消息的情况下,我们只使用了RDMA来对服务器中的数据进行读或者写,这值得我们思考,某种意义上来讲,FaRm对于这个问题的答案是No,这并不是FaRm的工作方式,但这个问题还是值得我们思考一下,即为什么我们无法单纯地靠 one-sided RDMA来做到这点,在事务系统中使用RDMA的难题在于replication以及数据分片,我们所面临的挑战是该如何将事务、数据分片以及replication 结合在一起,因为我们需要通过数据分片和事务复制才能做到一个严格意义上有用的数据库系统,事实证明,在我们目前为止看到的所有用来处理事务复制的协议他们都需要服务器软件的参与,在我们目前见过的所有协议中,服务器都得参与进来,帮助client对数据进行读取或写入,例如我们所见过的两阶段提交方案中,服务器得去判断一条记录上面是否有锁,如果该记录上没有锁,那么我们就得给他加一把锁,一次3来进行读操作或写操作,我们并不清楚如何通过RDMA来做到这点,服务器得去做一些事情,比如在Spanner中,我们得有版本号之类的东西,服务器得去思考如何找到版本号最新的数据,类似的,如果我们在事务中使用两阶段提交,服务器上的数据除了已经落地提交的数据以外,还有一些已经写入但未被提交的数据,一般来讲,服务器回去弄清楚最近更新的数据是否已经被提交,这就可以防止client 读到那些被锁住或者还未被提交的数据了。这意味着,在没有一些更好的办法的情况下,RDMA 或者 one-sided RDMA 似乎是无法直接,它是没法使用 one-sided RDMA来对该数据进行修改的,这届约会让我们去使用乐观锁并发控制了。为了让FaRm能够使用RDMA并且对事务进行支持,他们所使用的主要手段就是乐观锁并发控制,如果你还记得我之前所提到过的,并发控制方案可以分为两大类,悲观和乐观,悲观方案使用了锁,它的思路是,如果你有一个事务要去读取或写入某些数据,在你可以对该数据进行读取或写入前,它必须等待获得这把锁,你们得去读下两阶段锁相关的东西了。在你执行事务前获取这把锁,在你执行事务的这段时间内,你都的拿着这把锁,只有当事务提交或终止时,你才能将锁释放。如果事务间存在着冲突,因为两个事务想在容易时间对同一个数据对象进行写入操作,或者一个事务向读取该数据对象,但是另一个相对该数据对象进行写入,他们没法同时去执行他们的操作,其中一个事务就会被阻塞住,或者这两个想对数据进行写入操作的事务都会被阻塞,并等待锁被释放,在这个锁方案中,数据得被锁住,有人得去跟踪谁持有该数据所对应的所,什么时候该所被释放等等,这是RDMA使用过程中并不清楚的一个地方,即我们在锁方案中该如何进行写或者读。因为有人得强制使用所,我对这点持有疑问,我怀疑那些更智能的具备RDMA能力的网络接口卡可以支持更多的操作,比如原子性test-and-set,你们可能某一天通过使用这种纯粹的one-sided RDMA就可以实现一套锁方案。FaRm使用了一种乐观锁机制,在乐观锁机制中,至少你可以在没有锁的情况下去读取数据,你只需要去读取数据就行了,你不用去知道你是否有权去读取该数据,或者有没有正在对该数据进行修改之类的操作,这些你都不用管,只管去读取该事务执行时所需要的数据就行了。在乐观锁方案情况下,你不会直接写入数据,你将他们缓存起来,我们会将这些写操作缓存在client本地,直到事务最终结束,当事务最终结束的时候,你会试着去提交该事务,这里会有一个验证阶段,事务处理系统会试着弄清楚你所做的读和写操作是否与执行顺序一致,当我在读取数据的时候,有人正在对该数据对象进行写操作,如果是这样的话,那我们就没法提交该事务,因为此时该数据对我来讲就是一个脏数据,我不能用它进行计算,如果验证成功的话,那么你就可以提交该事务了,如果验证失败了,如果你发现在你试着使用数据的时候,有人弄乱了这个数据,那么就终止这个事务。
这意味着这里面存在着冲突,如果你正在对某个数据进行读或者写,并且其他事务在同一时间也在对该数据对象进行修改,此时我们就不会去使用乐观锁机制了。因为在提交的时候,计算结果就已经是错的了。你所读到的数据就是那些你不想读到的损坏数据。提交完成才不会被阻塞,相反事务已经被污染了,我们只能去终止他们,并去试着重新执行。
FaRm使用了乐观锁,因为他想去使用one-sided RDMA来对数据进行快速读取,在这个设计中确实强制去使用了RDMA我们经常将乐观锁并发控制简写为OCC,关于乐观锁并发控制协议里其中又去的一点是validation是如何工作的,当你试着去操作一个数据对象的时候,你该如何检测出其他人也正在对该数据对象进行写入操作,这实际上也是我们这节课剩下时间所主要讨论的东西。我们回到这个设计的最顶层,它为FaRm所做的事情是,我们的读操作可以去使用one-sided RDMA ,因此,读取速度就会超级快,因为我们会在稍后去检查这些读操作是否成功读到了数据,FaRm的研究原型并不支持SQL之类的东西,它使用了一个相当简单的API来支持事务,调用这个API ,你能够知道 transaction code是什么,如果你有一个事务,那么它会在事务开头处标记生命下事务要开始执行了,因此我们得声明下,这一个完成的事务是由这些读操作和写操作所组成的,,我们通过调用txCreate()来声明一个新事务,这个在2014年中的一片paper中有提到,该paper是由同一个作者编写的,调用这个API,我们创建了一个新事务,接着,你通过调用函数来显示读取对象,你得往里面传入一个对象标识符OID,一次来表示你想读取的对象是哪个,

然后,你会拿到某个对象,你可以在本地内存中对该对象进行修改,我们不会对它进行写入操作,通过调用txRead我们从服务器处拿到该对象的一个副本,比如我们可能对这个对象的某个字段的值加1,接着,当你想要更新一个对象的数据时,那么你就可以去调用txWrite,你得往里面传入OID以及要更新的对象内容,当你做完这一切的时候,你得告诉系统去提交这个事务,并让它对这个事务进行验证,如果验证通过,那么它就会对这些写操作生效,并让其修改结果对外可见,然后你调用txCommit

提交的时候,它做了很多事情,这个我们会在讨论Figure4的时候讲一下,它会将ok的值返回给我们,它需要告诉应用程序该事务提交是成功了,还是中止了,你知道的,如果事务提交成功,我们就得返回事务提交成功所对应的ok值。
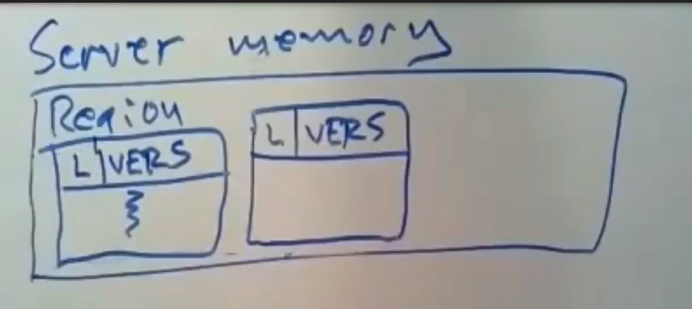
这里有几个问题,如果事务出现冲突,那么我们机会停止使用occ,它得问题是,在重试过程中是否会设计指数补偿,因为如果你立刻进行重试的话,并且在同一时间有大量的事务试着去更新同一个值,那么这些事务就都会被中止,然后重新尝试更新,这样就会导致浪费大量的时间,我不知道这个问题的答案是怎么样的,我不记得有没有paper中有没有提到指数补偿这个东西,给这些重试增加延迟时间会非常有意义,这就是raft中Randomization算法,通过给他们机会来让其重试成功,另一个问题是,FaRm的API更接近与NoSQL数据库的API,你知道的,这是看待它的一种方式,它并没有那种查询中很花式的操作,例如SQL中的join操作,它的读写和事务支持的接口都是很底层的,你可以把它当做是带事务的NoSQL数据库,这就是一个事务的样子,这些都是库中调用的API,比如txCreate,txRead,txWrite,txCommit。txCommit作为一些列复杂的写调用,是很复杂的,它首先要去调用事务协调器的代码,这是两阶段提交的一个比较少见的变种,figure4中对此进行了描述,再重复一下,当我们调用txRead时,他会去读取相关服务器上的数据,这里的txWrite只会对本地的buffer数据进行修改,只有当这个修改过的数据对象发送到服务器后,他才会去提交该事务,对象所对应的objext id 实际上是一个符合标识符他们由两部分组成,其中一部分用来识别区域的,所有服务器上的内存会被拆分到不同的区域进行管理,配置管理器回去跟踪服务器所复制的区域编号是什么,这里会有一个区域编号,那么你就知道,根据给定的区域编号,你的client可以根据当前primary和backup中的表进行查找,第二部分则是该区域中的内存地址,client通过地区编码来选择要去进行通信的primary和backup,它将地址告诉支持RDMA的NIC,请从这个地址去获取这个对象吧,我们地区弄清楚的另一个细节就是,我们得去看下服务器的内存布局,在任意一台服务器的内存中都存放着一堆东西,其中一部分东西是,在该服务器的内存中包含了一个或多个数据区域(每个数据区域都可以看做是一个集合对象),一个区域包含了一堆的数据对象,它(这个区域)所在的内存中有很多数据对象,在每个对象的内部都有一个header,它里面包含了该对象的版本号,这里的对象都打上了版本号,但每个对象一次只会有一个版本号,在每个版本号的高位处都会有一个lock标志位,在每个对象的header中的高位出会有一个lock标志位,地位出则是放着该数据的版本号,然后就是该对象的实际数据了,每个对象在各个服务器中的内存布局都是相同的,在高位出回访一个lock标志位,在地位出则是放对象的当前版本号,每当系统对一个对象进行修改时,它会对该对象的版本号进行加1,我们会在稍后看到这些lock标志位是如何使用的
此外,在服务器内部内存中,这里们存放着多对消息队列,在该系统中的其他服务器里,每个服务器都会有一份log日志,这意味着,如果该系统中有4台服务器再执行事务,在内存中就会有4份日志,他们可以通过RDMA来进行追加,会为每台服务器都创建一份日志,这意味着每个日志记录着对应服务器所执行的事务,我们给这些队列编个号,比如以服务器2所执行的事务代码为例,它这里面要做的事情是,他要和这个服务器进行同喜并追加日志,实际上它会将服务器2的日志追加到这个服务器的内存中,每个服务器的内存中总会有N^2个队列(一台服务器和另一台服务器建立的channel中会有一个读队列RQ,还有一个写队列SQ),实际上这里有一组非易失性的日志,

然后这里还有一个单独的消息队列,他们用于处理RPC那样的通信
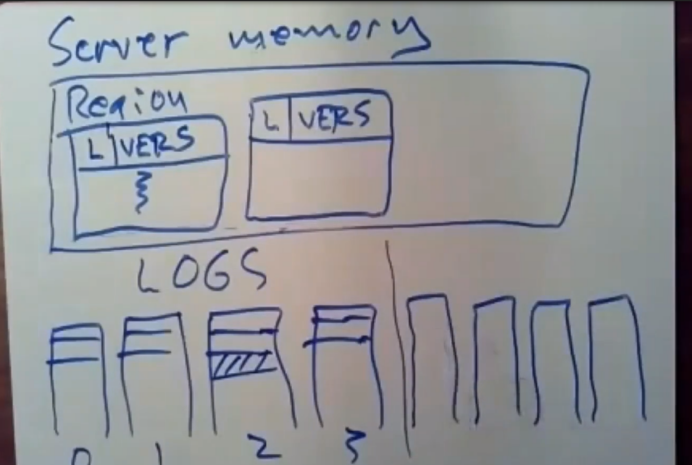
再次强调,在每台服务器上的incoming message queue,其他服务器可以通过RDMA来对它进行写入操作(A和
B通过RNIC建立channel,B对在A中建立的incoming message queue 进行直接写入。)
接下来要讲的就是paper中的figure 4
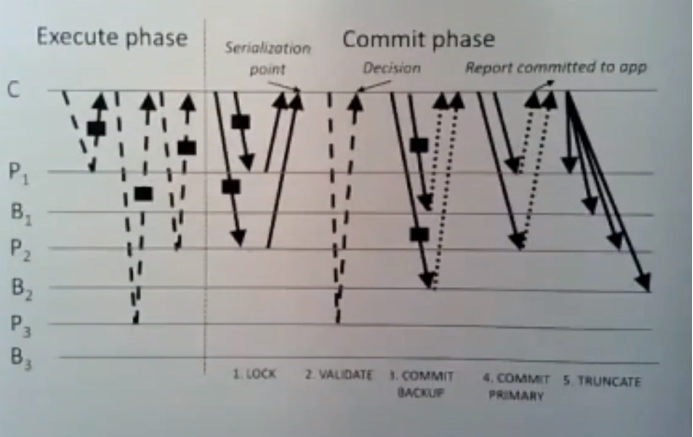
这张图解释了FaRm所使用的OCC提交协议我们会对这张图逐步讲解,并且我只会着重讲解并发控制这块,事实证明,这些步骤中除了进行replication以外,它还实现了事务的有序执行,但我们稍后回去讨论一点关于为容错而生的replication,这里首先要经历的是执行阶段,这里是事务尽心读和写的地方,这里是client端的事务所做的读和写,这里的每个箭头所表示的意思是,这值得是在机器C上所执行的事务,当它需要去读取某些东西的时候,他会去使用one-sided RDMA来读取相关primary服务器上内存的数据,对于这里的3个不同数据分片来说(P1 B1 P2 B2 。。。),他们各有一个primary服务器和backup服务器,假设我们的事务使用one-sided RDMA从每个数据分片上读取一个对象,这意味着每次读取值需要话5毫秒,client需要去读取事务所需要的所有数据,以及他要去写入的所有数据。接着当事务调用txCommit来表示它已经执行完所有的操作了。client处调用txCommit时扮演了事务协调器的角色,它所使用的整个协议可以看做是一种很精致的两阶段提交,在第一阶段中他们会来回发送消息事务协调器发送了lock消息给primary,并等待他们进行回复急着他会去按照消息,然后等待所有的回复,调节协议中第一个阶段是lock阶段,在这个阶段中,client会给每个primary发送它要去访问的object id,对于client要写入的每个对象来说,它需要将更新后的对象发送给相关的primary,它会将更新后的对象发送给primary,并将其作为一个新的日志条目追加到primary的日志中,client已经将日志条目追加到primary的日志上了,它这里苏姚追加的东西是它想写入对象的objectid,client 一开始读取该对象时所获取的版本号,以及新的值,它会往他要写入的每个数据分片的primary上的日志中追加该对象的版本号以及该对象的新值。
。。。。后面我没有理解是什么意思。没继续下去了


 浙公网安备 33010602011771号
浙公网安备 33010602011771号