Aurora 的发展史
https://mit-public-courses-cn-translatio.gitbook.io/mit6-824/lecture-10-cloud-replicated-db-aurora/10.1-aurora-bei-jing-li-shi
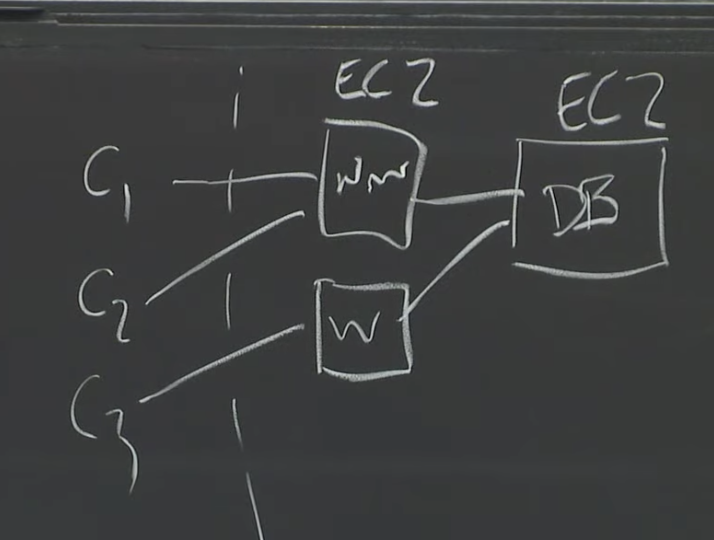
最早是EC2,装满服务器的数据中心,每个服务器都运行VMM,他们向用户出租虚拟机。每个EC2实例都运行一个操作系统,可以运行程序、web服务器、数据库等,EC2也会有属于自己的虚拟磁盘。
![]()
对于数据库来说,EC2的存储非常不友好,如果服务器崩了磁盘也无法访问。
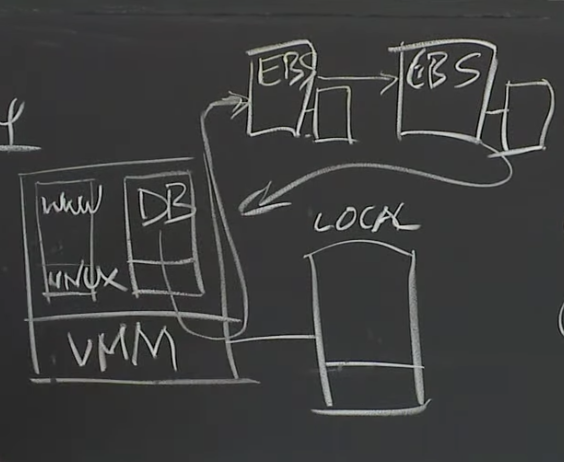
后出现了EBS服务,它是容错的且支持持久化存储的服务。
BS就是一个硬盘,你可以像一个普通的硬盘一样去格式化它,就像一个类似于ext3格式的文件系统或者任何其他你喜欢的Linux文件系统。但是在实现上,EBS底层是一对互为副本的存储服务器。
![]()
![]()
EBS的问题
如果你在EBS上运行一个数据库,那么最终会有大量的数据通过网络来传递。论文的图2中,就有对在一个Network Storage System之上运行数据库所需要的大量写请求的抱怨。所以,如果在EBS上运行了一个数据库,会产生大量的网络流量。在论文中有暗示,除了网络的限制之外,还有CPU和存储空间的限制。在Aurora论文中,花费了大量的精力来降低数据库产生的网络负载,同时看起来相对来说不太关心CPU和存储空间的消耗。所以也可以理解成他们认为网络负载更加重要。
另一个问题是,EBS的容错性不是很好。出于性能的考虑,Amazon总是将EBS volume的两个副本存放在同一个数据中心。所以,如果一个副本故障了,那没问题,因为可以切换到另一个副本,但是如果整个数据中心挂了,那就没辙了。很明显,大部分客户还是希望在数据中心故障之后,数据还是能保留的。数据中心故障有很多原因,或许网络连接断了,或许数据中心着火了,或许整个建筑断电了。用户总是希望至少有选择的权利,在一整个数据中心挂了的时候,可以选择花更多的钱,来保留住数据。 但是Amazon描述的却是,EC2实例和两个EBS副本都运行在一个AZ。
在Amazon的术语中,一个AZ就是一个数据中心。Amazon通常这样管理它们的数据中心,在一个城市范围内有多个独立的数据中心。大概2-3个相近的数据中心,通过冗余的高速网络连接在一起,我们之后会看一下为什么这是重要的。但是对于EBS来说,为了降低使用Chain Replication的代价,Amazon 将EBS的两个副本放在一个AZ中。
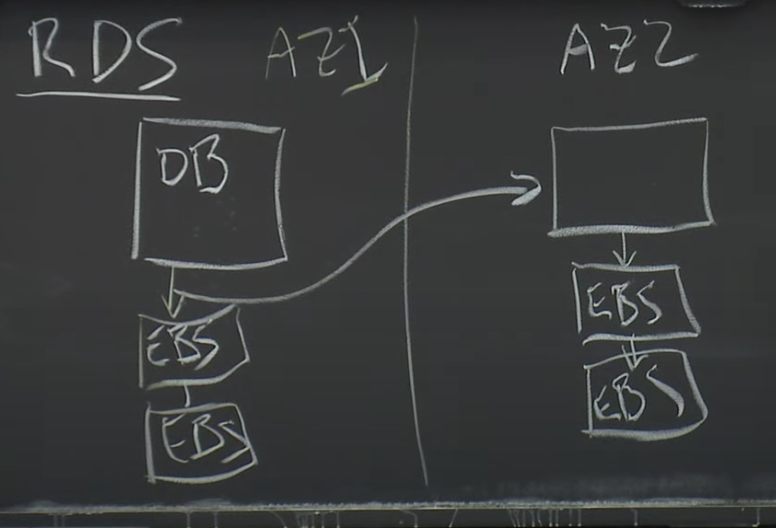
在MySQL基础上,结合Amazon自己的基础设施,Amazon为其云用户开发了改进版的数据库,叫做RDS(Relational Database Service)。尽管论文不怎么讨论RDS,但是论文中的图2基本上是对RDS的描述。RDS是第一次尝试将数据库在多个AZ之间做复制,这样就算整个数据中心挂了,你还是可以从另一个AZ重新获得数据而不丢失任何写操作。
![]()
每一次数据库软件执行一个写操作,Amazon会自动的,对数据库无感知的,将写操作拷贝发送到另一个数据中心的AZ中
在这个架构中,对于数据库来说是无感知的,每一次数据库调用写操作,更新自己对应的EBS服务器,每一个写操作的拷贝穿过AZ也会写入到另一个AZ中的2个EBS服务器中,另一个AZ会返回确认说写入成功,只有这时,写操作看起来才是完成的。所以这里必须要等待4个服务器更新完成,并且等待数据在链路上传输,它通过网络传输了大量的数据所以性能太差。
Aurora 提供超级容错性
有6个数据的副本,位于3个AZ,每个AZ有2个副本。所以现在有了超级容错性,并且每个写请求都需要以某种方式发送给这6个副本。
这里通过网络传递的数据只有Log条目,这才是Aurora成功的关键。从之前的简单数据库模型可以看出,每一条Log条目只有几十个字节那么多,也就是存一下旧的数值,新的数值,所以Log条目非常小。然而,当一个数据库要写本地磁盘时,它更新的是data page,这里的数据是巨大的,虽然在论文里没有说,但是我认为至少是8k字节那么多。所以,对于每一次事务,需要通过网络发送多个8k字节的page数据。而Aurora只是向更多的副本发送了少量的Log条目。因为Log条目的大小比8K字节小得多,所以在网络性能上这里就胜出了。这是Aurora的第一个特点,只发送Log条目。
当然,这里的后果是,这里的存储系统不再是通用(General-Purpose)存储,这是一个可以理解MySQL Log条目的存储系统。EBS是一个非常通用的存储系统,它模拟了磁盘,只需要支持读写数据块。EBS不理解除了数据块以外的其他任何事物。而这里的存储系统理解使用它的数据库的Log。所以这里,Aurora将通用的存储去掉了,取而代之的是一个应用定制的(Application-Specific)存储系统。
另一件重要的事情是,Aurora并不需要6个副本都确认了写入才能继续执行操作。相应的,只要Quorum形成了,也就是任意4个副本确认写入了,数据库就可以继续执行操作。所以,当我们想要执行写入操作时,如果有一个AZ下线了,或者AZ的网络连接太慢了,或者只是服务器响应太慢了,Aurora可以忽略最慢的两个服务器,或者已经挂掉的两个服务器,它只需要6个服务器中的任意4个确认写入,就可以继续执行。所以这里的Quorum是Aurora使用的另一个聪明的方法。通过这种方法,Aurora可以有更多的副本,更多的AZ,但是又不用付出大的性能代价,因为它永远也不用等待所有的副本,只需要等待6个服务器中最快的4个服务器即可。
Aurora 的容错目标
首先是对于写操作,当只有一个AZ彻底挂了之后,写操作不受影响。
其次是对于读操作,当一个AZ和一个其他AZ的服务器挂了之后,读操作不受影响。
Aurora期望能够容忍暂时的慢副本
如果一个副本永久挂掉,提供快速恢复功能
Aurora使用Quorum复制机制来构建容错系统
对于Aurora来说,它的写请求从来不会覆盖任何数据,它的写请求只会在当前Log中追加条目(Append Entries)。所以,Aurora使用Quorum只是在数据库执行事务并发出新的Log记录时,确保Log记录至少出现在4个存储服务器上,之后才能提交事务。所以,Aurora的Write Quorum的实际意义是,每个新的Log记录必须至少追加在4个存储服务器中,之后才可以认为写请求完成了。当Aurora执行到事务的结束,并且在回复给客户端说事务已经提交之前,Aurora必须等待Write Quorum的确认,也就是4个存储服务器的确认,组成事务的每一条Log都成功写入了。
实际上,在一个故障恢复过程中,事务只能在之前所有的事务恢复了之后才能被恢复(中间有不能恢复的事务导致后面的所有事务被舍弃)。所以,实际中,在Aurora确认一个事务之前,它必须等待Write Quorum确认之前所有已提交的事务,之后再确认当前的事务,最后才能回复给客户端。
这里的存储服务器接收Log条目,这是它们看到的写请求。它们并没有从数据库服务器获得到新的data page,它们得到的只是用来描述data page更新的Log条目。
一个新的写请求到达时,这个写请求只是一个Log条目,Log条目中的内容需要应用到相关的page中。但是我们不必立即执行这个更新,可以等到数据库服务器或者恢复软件想要查看那个page时才执行。对于每一个存储服务器存储的page,如果它最近被一个Log条目修改过,那么存储服务器会在内存中缓存一个旧版本的page和一系列来自于数据库服务器有关修改这个page的Log条目。所以,对于一个新的Log条目,它会立即被追加到影响到的page的Log列表中。这里的Log列表从上次page更新过之后开始(相当于page是snapshot,snapshot后面再有一系列记录更新的Log)。如果没有其他事情发生,那么存储服务器会缓存旧的page和对应的一系列Log条目。
如果之后数据库服务器将自身缓存的page删除了,过了一会又需要为一个新的事务读取这个page,它会发出一个读请求。请求发送到存储服务器,会要求存储服务器返回当前最新的page数据。在这个时候,存储服务器才会将Log条目中的新数据更新到page,并将page写入到自己的磁盘中,之后再将更新了的page返回给数据库服务器。同时,存储服务器在自身cache中会删除page对应的Log列表,并更新cache中的page,虽然实际上可能会复杂的多。
如刚刚提到的,数据库服务器有时需要读取page。所以,可能你已经发现了,数据库服务器写入的是Log条目,但是读取的是page。这也是与Quorum系统不一样的地方。Quorum系统通常读写的数据都是相同的。除此之外,在一个普通的操作中,数据库服务器可以避免触发Quorum Read。数据库服务器会记录每一个存储服务器接收了多少Log。所以,首先,Log条目都有类似12345这样的编号,当数据库服务器发送一条新的Log条目给所有的存储服务器,存储服务器接收到它们会返回说,我收到了第79号和之前所有的Log。数据库服务器会记录这里的数字,或者说记录每个存储服务器收到的最高连续的Log条目号。这样的话,当一个数据库服务器需要执行读操作,它只会挑选拥有最新Log的存储服务器,然后只向那个服务器发送读取page的请求。所以,数据库服务器执行了Quorum Write,但是却没有执行Quorum Read。因为它知道哪些存储服务器有最新的数据,然后可以直接从其中一个读取数据。这样的代价小得多,因为这里只读了一个副本,而不用读取Quorum数量的副本。
是,数据库服务器有时也会使用Quorum Read。假设数据库服务器运行在某个EC2实例,如果相应的硬件故障了,数据库服务器也会随之崩溃。在Amazon的基础设施有一些监控系统可以检测到Aurora数据库服务器崩溃,之后Amazon会自动的启动一个EC2实例,在这个实例上启动数据库软件,并告诉新启动的数据库:你的数据存放在那6个存储服务器中,请清除存储在这些副本中的任何未完成的事务,之后再继续工作。这时,Aurora会使用Quorum的逻辑来执行读请求。因为之前数据库服务器故障的时候,它极有可能处于执行某些事务的中间过程。所以当它故障了,它的状态极有可能是它完成并提交了一些事务,并且相应的Log条目存放于Quorum系统。同时,它还在执行某些其他事务的过程中,这些事务也有一部分Log条目存放在Quorum系统中,但是因为数据库服务器在执行这些事务的过程中崩溃了,这些事务永远也不可能完成。对于这些未完成的事务,我们可能会有这样一种场景,第一个副本有第101个Log条目,第二个副本有第102个Log条目,第三个副本有第104个Log条目,但是没有一个副本持有第103个Log条目。
所以故障之后,新的数据库服务器需要恢复,它会执行Quorum Read,找到第一个缺失的Log序号,在上面的例子中是103,并说,好吧,我们现在缺失了一个Log条目,我们不能执行这条Log之后的所有Log,因为我们缺失了一个Log对应的更新。
所以,这种场景下,数据库服务器执行了Quorum Read,从可以连接到的存储服务器中发现103是第一个缺失的Log条目。这时,数据库服务器会给所有的存储服务器发送消息说:请丢弃103及之后的所有Log条目。103及之后的Log条目必然不会包含已提交的事务,因为我们知道只有当一个事务的所有Log条目存在于Write Quorum时,这个事务才会被commit,所以对于已经commit的事务我们肯定可以看到相应的Log。这里我们只会丢弃未commit事务对应的Log条目。
![]()
Aurora如何处理大型数据库
为了能支持超过10TB数据的大型数据库。Amazon的做法是将数据库的数据,分割存储到多组存储服务器上,每一组都是6个副本,分割出来的每一份数据是10GB。所以,如果一个数据库需要20GB的数据,那么这个数据库会使用2个PG(Protection Group),其中一半的10GB数据在一个PG中,包含了6个存储服务器作为副本,另一半的10GB数据存储在另一个PG中,这个PG可能包含了不同的6个存储服务器作为副本。
![]()
因为Amazon运行了大量的存储服务器,这些服务器一起被所有的Aurora用户所使用。两组PG可能使用相同的6个存储服务器,但是通常来说是完全不同的两组存储服务器。随着数据库变大,我们可以有更多的Protection Group。
这里有一件有意思的事情,你可以将磁盘中的data page分割到多个独立的PG中,比如说奇数号的page存在PG1,偶数号的page存在PG2。如果可以根据data page做sharding,那是极好的。
Sharding之后,Log该如何处理就不是那么直观了。如果有多个Protection Group,该如何分割Log呢?答案是,当Aurora需要发送一个Log条目时,它会查看Log所修改的数据,并找到存储了这个数据的Protection Group,并把Log条目只发送给这个Protection Group对应的6个存储服务器。这意味着,每个Protection Group只存储了部分data page和所有与这些data page关联的Log条目。所以每个Protection Group存储了所有data page的一个子集,以及这些data page相关的Log条目。
如果其中一个存储服务器挂了,我们期望尽可能快的用一个新的副本替代它。因为如果4个副本挂了,我们将不再拥有Read Quorum,我们也因此不能创建一个新的副本。所以我们想要在一个副本挂了以后,尽可能快的生成一个新的副本。表面上看,每个存储服务器存放了某个数据库的某个某个Protection Group对应的10GB数据,但实际上每个存储服务器可能有1-2块几TB的磁盘,上面存储了属于数百个Aurora实例的10GB数据块。所以在存储服务器上,可能总共会有10TB的数据,当它故障时,它带走的不仅是一个数据库的10GB数据,同时也带走了其他数百个数据库的10GB数据。所以生成的新副本,不是仅仅要恢复一个数据库的10GB数据,而是要恢复存储在原来服务器上的整个10TB的数据。我们来做一个算术,如果网卡是10Gb/S,通过网络传输10TB的数据需要8000秒。这个时间太长了,我们不想只是坐在那里等着传输。所以我们不想要有这样一种重建副本的策略:找到另一台存储服务器,通过网络拷贝上面所有的内容到新的副本中。我们需要的是一种快的多的策略。
Aurora实际使用的策略是,对于一个特定的存储服务器,它存储了许多Protection Group对应的10GB的数据块。对于Protection Group A,它的其他副本是5个服务器。
如果一个存储服务器挂了,假设上面有100个数据块,现在的替换策略是:找到100个不同的存储服务器,其中的每一个会被分配一个数据块,也就是说这100个存储服务器,每一个都会加入到一个新的Protection Group中。所以相当于,每一个存储服务器只需要负责恢复10GB的数据。所以在创建新副本的时候,我们有了100个存储服务器(下图中下面那5个空白的)。
对于每一个数据块,我们会从Protection Group中挑选一个副本,作为数据拷贝的源。这样,对于100个数据块,相当于有了100个数据拷贝的源。之后,就可以并行的通过网络将100个数据块从100个源拷贝到100个目的。
现在我们可以以100的并发,并行的拷贝1TB的数据,这只需要10秒左右。如果只在两个服务器之间拷贝,正常拷贝1TB数据需要1000秒左右。
只读服务器
,Aurora不仅有主数据库实例,同时多个数据库的副本。对于Aurora的许多客户来说,相比读写查询,他们会有多得多的只读请求。你可以设想一个Web服务器,如果你只是查看Web页面,那么后台的Web服务器需要读取大量的数据才能生成页面所需的内容,或许需要从数据库读取数百个条目。但是在浏览Web网页时,写请求就要少的多,或许一些统计数据要更新,或许需要更新历史记录,所以读写请求的比例可能是100:1。所以对于Aurora来说,通常会有非常大量的只读数据库查询。
对于写请求,可以只发送给一个数据库,因为对于后端的存储服务器来说,只能支持一个写入者。背后的原因是,Log需要按照数字编号,如果只在一个数据库处理写请求,非常容易对Log进行编号,但是如果有多个数据库以非协同的方式处理写请求,那么为Log编号将会非常非常难。
当客户端向只读数据库发送读请求,只读数据库需要弄清楚它需要哪些data page来处理这个读请求,之后直接从存储服务器读取这些data page,并不需要主数据库的介入。所以只读数据库向存储服务器直接发送读取page的请求,之后它会缓存读取到的page,这样对于将来的一些读请求,可以直接根据缓存中的数据返回。
只读数据库也需要更新自身的缓存,所以,Aurora的主数据库也会将它的Log的拷贝发送给每一个只读数据库。这就是你从论文中图3看到的蓝色矩形中间的那些横线。主数据库会向这些只读数据库发送所有的Log条目,只读数据库用这些Log来更新它们缓存的page数据,进而获得数据库中最新的事务处理结果。
这的确意味着只读数据库会落后主数据库一点,但是对于大部分的只读请求来说,这没问题。


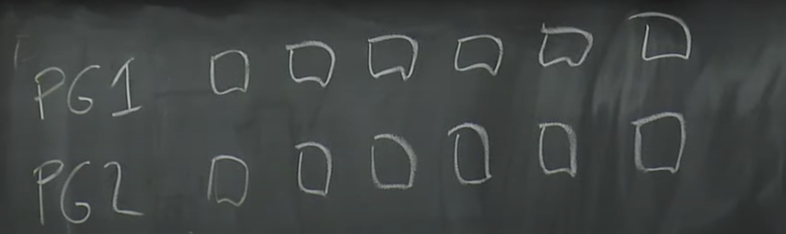



 浙公网安备 33010602011771号
浙公网安备 33010602011771号