现代操作系统:进程与线程(六)
2.3 Process Scheduling进程调度
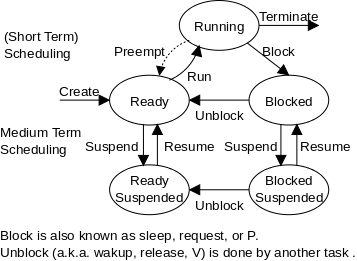
注意:我们将在2.3节之前做2.4节,因为2.3节和2.5节是密切相关的;在我看来,介于2.4之间似乎有些尴尬。在处理器上调度进程通常称为处理器调度、进程调度、简单地调度。正如我们在本课程后面将看到的,更准确的名称是短期处理器调度。当我们学习调度时,我们正在讨论我最喜欢的图中连接running和ready的两条弧线,在右侧重复,它显示了一个过程的各种状态以及这些状态之间的转换。中期调度将在后面讨论(磁盘臂调度)。
如您所料,操作系统中负责(短期、处理器)调度的部分称为(短期、处理器)调度程序,使用的算法称为(短期、处理器)调度算法。
2.3.0 Introduction to Scheduling调度的简介
调度对不同时代和应用环境的重要性
早期的计算机系统是单道编程的,因此并不存在调度的问题。对于现在的许多个人电脑来说,它们确实是多程序的,实际上很少有超过一个可运行的进程,因此,调度并不重要。
对于像access.cims.nyu.edu或cnn.com这样的服务器,调度确实很重要,您应该考虑的正是这样的系统。
Process Behavior进程行为
一个进程在CPU活动和I/O活动之间交替进行,通常将其称为CPU突发和I/O突发的交替,CPU Burst和I/O Burst的交替称之为CPU-I/O Burst Circle。
由于(当我们学习I/O时将会看到)磁盘访问所需的时间通常仅微弱取决于请求的大小,计算绑定(也就是CPU绑定)和I/O绑定作业之间的关键区别因素是CPU突发的长度。过去几十年的趋势是越来越多的工作成为I/O绑定,因为CPU处理速度的增长远远快于I/O速度的增长。(说白了就是哪个时间用的长就是哪个的绑定)
When to Schedule什么时候去调度
有一点很明显,但经常被遗忘,调度程序只能在操作系统运行时运行à有中断的地方就可能有调度。特别是,对于我们正在考虑的单处理器系统,当用户进程运行时不可能发生调度。(在多处理器的情况下,当每个处理器运行一个用户进程时,不可能发生调度)。让我们考虑上面状态转换图中的弧线(特别是上面的三角形),并讨论那些调度是可能的、可取的和必须的转换:
- 进程的创建:正在运行的进程发出了一个fork()系统调用,此时操作系统可以运行,与之对应的是此时调度是可行的,因为调度算法可能更倾向于选择新进程;
- 进程的终止(任务完成):exit()系统调用将控制转移到操作系统,因此可以进行调度。此外,由于先前运行的进程已经终止,因此调度是必要的;
- 进程阻塞(例如read()系统调用):read()系统调用已经将控制权转移到操作系统,因此可以进行调度。此外,由于之前运行的进程已经阻塞,因此需要进行调度;
- 进程不再阻塞:这通常是由于OS已经收到I/O中断。由于操作系统接管了控制权,调度再次成为可能。此外,解除阻塞意味着以前阻塞的进程现在已经准备好了。因此,我们有一个新的(可能是高优先级的)就绪态进程,因此调度是可取的;
- 进程被抢占(运行时间终止):在抢占式调度中系统通过一个时钟中断进入内核态,此时调度是有可能发生的,实际上由于时间片的结束,那么当前需要调度一个新的进程给CPU执行运算;
- 进程正在运行(发生优先级变化):这也是一个调度动作,它通常是前一个操作的结果。
Preemption抢占
区分抢占式调度算法和非抢占式调度算法非常重要。抢占式调度程序意味着操作系统可以在没有进程请求的情况下将进程从运行状态移动到就绪状态。
- 在没有抢占的情况下,系统执行进程直到目标进程完成,或阻塞(或yield,如果有线程)。
- 我们不强调yield(多线程中将线程由运行态转为就绪态)。
- 图中给出了用于抢占调度算法的抢占弧。
- 抢占需要一个时钟中断(或等效的中断)。
- 抢占需要保证公平性。
- 抢占在所有现代通用操作系统中都存在。
- 即使是不可抢占的系统也可以同时运行多个进程(记住,进程会被I/O阻塞)。
- 抢占的具有很大的代价。
Categories of Scheduling Algorithms调度算法的种类
根据抢占的重要级别我们将调度算法划分成三类:
a. Batch批处理系统的调度算法
b. Interactive交互式系统的调度算法
c. Real Time实时系统的调度算法
对于多道批处理系统(我们不考虑单程序处理系统),主要关注的是效率。由于没有用户在终端上等待,抢占并不重要,如果使用它,它很少执行,也就是说,每个进程在被抢占之前可以运行很长一段时间。对于交互式系统(和多用户服务器),抢占对于短请求的公平性和快速响应时间至关重要。我们在本课程中不学习实时系统,但会说抢占通常不重要,因为所有进程都是协作的,并被编程在规定的时间窗口内完成它们的任务。
多道批处理系统:1. 多道:系统内可同时容纳多个作业。这些作业放在外存中,组成一个后备队列,系统按一定的调度原则每次从后备作业队列中选取一个或多个作业进入内存运行,运行作业结束、退出运行和后备作业进入运行均由系统自动实现,从而在系统中形成一个自动转接的、连续的作业流。2. 成批:在系统运行过程中,不允许用户与其作业发生交互作用,即:作业一旦进入系统,用户就不能直接干预其作业的运行。
Scheduling Algorithm Goals调度算法的目标
调度程序要实现的目标有很多,其中有几个是冲突的。这些包括:
- Fair公平:统一对待所有用户,这可能与下面的一些目标冲突;
- Respecting priority尊重优先:也就是说更喜欢的工作更加重要。加入我使用的电脑正在处理一些后台进程,我并不希望它会减慢我的代码编译速度,尤其是不希望他让我的系统在我演示这个Word时变的卡顿。所以一般来说与用户产生直接交互的作业通常拥有更高的优先级;
- Efficiency效率:两个方面分别是不能在调度程序中花费过程时间和尽量让系统的所有部件都处于忙碌状态;
- Low Turnaround Time低周转时间:尽可能最小化一个作业从提交到其结束的时间,这样可以使整体体验更加流畅;
- High Throughput高吞吐量:最大化完成的作业数量,也就意味着系统的效率更高;
- Low Response Time低响应时间:最大程度的缩短从用户发出的交互式命令到系统给出响应的时间;
- Degrade gracefully under load负载下优雅降级:优雅的降低一些进程/线程的优先级,或将它们挂起,重要的作业先做;
- Repeatability重复性:Dartmouth (DTSS) 为可重复性浪费了周期和限制性登录。
Deadline scheduling终线调度
这用于具有一组固定任务的实时系统。每个任务的运行时间是预先知道的。调度程序的目标是找到一个时间表,以便每个任务都能在截止日期前完成。实际上要复杂得多。
- 定期任务。
- 如果我们不能安排所有的任务以确保每个任务都能在截止日期前完成(也就是说,惩罚函数应该是什么),该怎么办?
- 如果运行时不是常数,但有一个已知的概率分布呢?
https://www.kernel.org/doc/html/latest/scheduler/sched-deadline.html
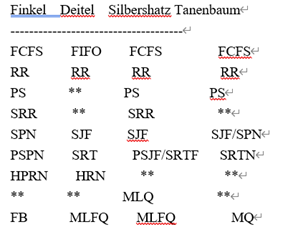
The Name Game姓名游戏
在命名不同的(短期的,处理器的)调度算法时存在惊人的不一致性。这些年来,我主要使用了4本书:按时间顺序,分别是Finkel、Deitel、Silberschatz和Tanenbaum。下面的表格说明了这四本书的名称游戏。在表之后,我们将详细讨论几种调度策略。
2.3.1 Scheduling in Batch Systems批处理系统的调度算法
First Come/In First Served/Out(FCFS FIFO FCFS FCFS)先来先服务调度算法
如果操作系统中没有调度,它仍然需要以某种方式存储就绪进程列表。如果它是一个队列,你会得到FCFS。如果它是一个堆栈,则得到LCFS,如果你想搞一些大事情比如乱来,也许你也可以得到一些随机的政策。LCFS和Random在实际中没有使用。
FCFS的特性
- 没有采用基于优先级的设计。
- 简单的调度策略。
- 从某种意义上说,它是最公平的,因为先到先得。但这也许不太公平。考虑一个1小时的作业在3秒之前提交。
- 它是一个高效的调度程序,使用很少的CPU时间。
- 它不支持交互式工作。
|
JobID |
ArriveOrder |
RunTime |
StartTime |
FinishTime |
WaitTime |
PowerWait |
|
A |
1 |
2 |
0 |
2 |
2 |
1.0 |
|
B |
2 |
60 |
2 |
62 |
62 |
1.03 |
|
C |
3 |
2 |
62 |
64 |
64 |
32 |
|
D |
4 |
2 |
64 |
66 |
66 |
33 |
|
Avg |
|
|
|
|
48.5 |
16.75 |
假设ABCD都在0时刻到达但是存在A-B-C-D的先后顺序
带权周转时间 = 周转时间 / 运行时间
缺陷:就剩下简单了,进程的优先级考虑不了,进程的平均等待时间不稳定有可能非常长;
Shortest Process/Job First(SPN, SJF, SJF, SJF)短作业优先调度算法
按照执行时间对作业进行排序,并先运行最短的作业。SJF是一种非抢占算法。首先考虑一个静态(过于简单,不现实)的情况,在这种情况下,所有的作业在一开始都是可用的,我们知道每个作业运行需要多长时间。为了简单起见,让我们考虑一下run-to-completion,也称为uniprogrammedor monoprogrammedor(也就是说,我们甚至不需要在I/O时切换到另一个进程),简单来说就是一个作业跑到底的情况。
- 在这种情况下,单程序SJF的平均等待时间最短,这是为什么?
- 假设你的计划是在短期工作之前先做一份长期工作。
- 考虑交换这两个工作。
- 这种交换以长工作的长度减少短工作的等待,并以短工作的长度增加长工作的等待。
- 不影响其他任务的等待。
- 由于短期工作的收益超过了长期工作的损失,互换减少了这两个工作的总等待时间。
- 因此,交换减少了所有作业的总等待时间,因此也减少了平均等待时间。
- 总而言之,每当一个长工作在一个短工作之前,我们可以互换它们,减少平均等待时间。
- 因此,当长工作之后没有短工作时,平均周转时间最低,即最短的工作优先(SJF)。
- 事实上,我们已经按照增加运行时间的顺序对作业进行了排序。
上面的论证说明了青睐短期工作的好处:平均等待时间减少了。例如,我们很快就会学到RR(Round-Robin时间片轮转法)和它的量子。使RR量子变小的一个论据是,短的工作更受青睐。
|
JobID |
ArriveOrder |
RunTime |
StartTime |
FinishTime |
WaitTime |
PowerWait |
|
A |
1 |
2 |
0 |
2 |
2 |
1.0 |
|
B |
2 |
60 |
6 |
66 |
66 |
1.1 |
|
C |
3 |
2 |
2 |
4 |
4 |
2.0 |
|
D |
4 |
2 |
4 |
6 |
6 |
3.0 |
|
Avg |
|
|
|
|
19.5 |
1.8 |
缺陷:有失公允,时间长的进程可能会被一直挂在最后,与Fair的准则背道而驰,而且程序运行的时间通常是由用户估计的并不能保证真正意义上的最短时间优先,且无法让优先级高紧迫程度高的任务先运行。
在真实SJF的更现实的情况下,当前运行的进程阻塞时(比如I/O)时,需要调度器切换到一个新进程,那么我将首先调用最短的next-CPU-burst策略。然而,除了我,我从来没听别人这么说过。真正的困难在于预测未来(即提前知道任务或任务下一次CPU突发所需的时间)(谁知道呢,理论上没法预测)。估计下一次CPU突发持续时间的一种方法是计算最近CPU突发持续时间的加权平均值。Tanenbaum称这个最短过程为“下一步”。我们将在本节稍后讨论它。最短工作优先会使需要长时间CPU Burst的进程中断。
用某些标准技术可以防止饥饿(某些进程长时间也拿不到CPU资源称为饥饿)。
问:这是什么技术?
答案:优先级老化(见下文)。
Shortest Remaining Time Next(PSPN, SRT, PSJF/SRTF, SRTN)最短剩余时间优先调度
这是抢占式的版本SJF。事实上,一些作者称之为抢占式的最短工作优先。使用SRTN,如果新进程(或下一个CPU Burst)的时间小于正在运行的进程(或当前Burst)的剩余时间,则进入就绪列表的进程会抢占正在运行的进程。
已经在就绪列表中的进程P所需要的时间永远不会少于当前正在运行的进程Q的剩余时间。问题:为什么?答:当P第一次进入就绪列表时,如果Q剩余的时间比P所需的时间多,它就会开始运行。因为这没有发生,Q剩下的时间比P少,因为Q现在运行,它剩下的时间更少。
|
JobID |
ArriveTime |
RunTime |
StartTime |
FinishTime |
WaitTime |
PowerWait |
|
A |
0 |
20 |
30 |
50 |
50 |
2.5 |
|
B |
0 |
17 |
0 |
30 |
30 |
1.76 |
|
C |
5 |
10 |
5 |
18 |
13 |
1.3 |
|
D |
10 |
3 |
10 |
13 |
3 |
1.0 |
|
Avg |
|
|
|
|
24 |
1.64 |
posted on 2021-10-26 11:11 ThomasZhong 阅读(125) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号