现代操作系统:进程与线程(四)
2.2 线程
进程的一个关键特性是进程具有一定的隔离性:当一个程序执行x++时,在同时运行的另一个程序中的x值并不会增加,但是这一特性同样会带来一些问题。
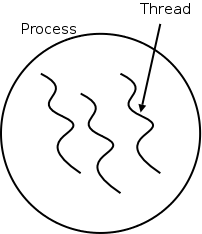
如上图所示,线程背后的思想是让多个控制线程在单个进程的地址空间中运行。地址空间是一个内存管理的概念,在本章节中我们可以先将地址空间看成是进程运行的内存(实际上还有从虚拟地址向物理地址的映射)。每个线程有一点像一个进程,但是线程包含的状态比进程少。
2.2.1 Thread Usage线程的使用
通常当执行应用程序的进程被阻塞时,进程中仍有可以为应用程序完成的计算,但是另一个进程无法进行这一计算,因为进程间的内存空间是不互通的。但是同一进程中的两个线程是共享内存的,所以线程可以解决这一问题。通过线程解决上述问题所带来的问题仍然是一定的安全性问题,因为每个线程在一个进程中并不受到其他线程的保护,多个线程在不加控制的情况下并发访问同一内存区域可能会导致一些轻微或严重的错误,所以进程和线程的选择一般是性能和简单性的决策。
两个进程vs两个线程
- 同一进程中的线程共享内存,但是单独的两个进程拥有自己独立的内存空间;
- 在同一个进程中一个线程切换到另一个线程比在进程外的两个进程切换要快的多;
A Producer Consumer Pipeline生产者消费者管道
loop 一个先读再写的循环
Read 10KB from disk1 to inBuffer 从disk1读10kb数据到inBuffer
Compute from inBuffer to outBuffer 将inBuffer的数据转移到outBuffer
Write outBuffer to disk2 将writeBuffer的数据写到disk2
end loop
分解成三个独立的进程
// process 1
loop
Read data from disk1 to inBuffer
end loop
// process 2
loop
Compute from inBuffer to outBuffer
end loop
// process 3
loop
Write outBuffer to disk2
end loop
思考一下上述代码的执行效率,假设每一行都会耗时10ms,因此整个循环每30s处理10kb数据,但是很显然CPU只在第二行繁忙,如果I/O系统很复杂,则第一行和第三行会使用单独的硬件。因此原则上上述三行代码是可以同时执行的,我们将这三个步骤转换为管道,以便在启动程序后实现每10ms处理10kb数据,效率提升了3倍。
但是如果我们仅仅将其分离成三个独立的进程会怎么样?在不使用IPC的情况下完全运行不起来,process1的inbuffer根本不是process2的inbuffer。但如果这三个函数全部转换成进程中的三个线程,那么每个线程的inbuffer实际上就指向了同一个内存位置,inbuffer和outbuffer在进程中就是全局变量,可以被所有线程共享。线程解决方案相对于独立进程非解决方案的另一个优点是,系统在同一进程中的线程之间切换的速度比在不同进程之间切换的速度快。
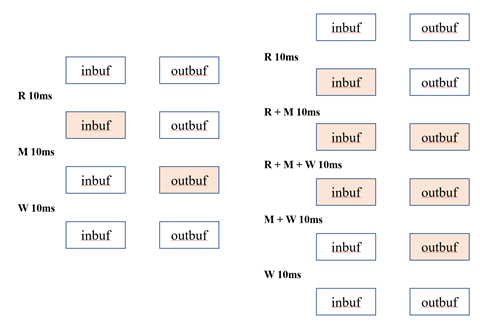
Double Buffering in the Producer Consumer Pipeline 生产者消费者管道中的双缓冲
上述情况是非常理想化的一个情况,很可能会失败,如果使用同一个缓冲区则必须要用户添加一定的同步互斥逻辑。
下面的方案展示了一种更现实的实现方法,需要在进程中开辟两个inbuffer和outbuffer总计4个buffer来实现。
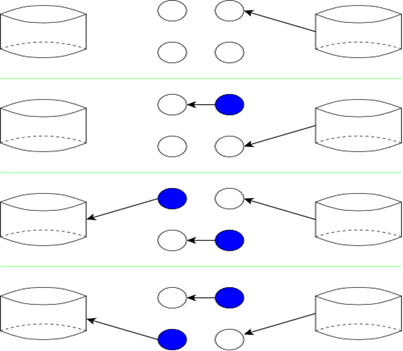
- 在第一个时间步骤中,如图中的箭头所示,线程1从输入磁盘读取数据到顶部输入缓冲区。对于这个步骤,输入磁盘是活动的(它被线程1使用),另一个磁盘(将被线程3使用)和CPU(将被线程2使用)是不活动的。因此,在这一步中,我们并不比使用更简单的非线程解决方案更好。
- 第二步比较好。线程1再次从输入磁盘读取数据,但现在读取到底部输入缓冲区。顶部的输入缓冲区是蓝色的,表示它包含有效数据。线程2使用CPU进行计算,从顶部输入缓冲区读取数据并写入顶部输出缓冲区。注意,线程正在读取有效数据。线程1和线程2在这个时间步骤中都是活动的。
- 从第三个时间步骤开始,我们达到了最高速度,所有三个线程都很忙。线程1将输入磁盘读入顶部输入缓冲区,覆盖之前写入的内容(这就是圆圈不再是蓝色的原因)。线程2使用底部的输入Buffer,并将其结果写入底部输出Buffer。线程3从顶部(蓝色)输出缓冲区写到输出磁盘。
- 随后的时间步骤类似于时间步骤3(直到输入耗尽)。如图所示,这些步骤交替使用顶部缓冲区和底部缓冲区。
Complications并发症
上面的例子仍然是对实际操作的简化。线程必须是协调/同步的,这样一个线程既不能读取前一个线程还没有完全写入的数据,也不能在下一个线程完成读取之前重写数据。
A Multithreaded Web Server多线程Web服务器
现代线程的一个重要例子是多线程web服务器。每个线程都响应一个www连接。当一个线程在I/O上被阻塞时,其他线程可以处理其他www连接。
问:为什么不使用单独的进程,即什么是【进程的共享内存】?
答案:经常引用的页面的缓存。
Dispatchers and Workers调度线程和工作线程
多线程应用程序的一个常见架构是维护一个调度线程,该线程处理请求,然后将每个请求传递给空闲的工作线程。由于调度线程和工作线程共享内存,因此传递请求的开销非常低。多线程web服务器可以这样组织。
Helper Tasks辅助任务
最后一个(相关的)例子是主线任务与用户交互,有时需要执行不直接影响用户界面的长任务。Tanenbaum认为,当前的文字处理器正在编辑一个大文件(比如用户正在编写的一本书),而用户删除了书中较早的一个单词。这可能会导致所有后续页面的格式更改。因此,重新格式化这本书可能会导致用户界面出现可检测到的延迟。使用线程实现,可以将重新格式化任务分配给第二个线程,同时主线程继续与用户交互。只有当用户希望查看接近本书末尾的页面时,他们才必须等待第二个线程完成。希望用户在本书开始时已经进行了其他编辑,以便在用户需要访问接近尾声的页面之前,第二个线程已经完成。即使第二个线程没有完成,它也已经完成了一些工作,而用户还在靠近书的开头进行编辑。
2.2.1 The Classical Thread Model传统线程模型
Process-Wide vs Thread-Specific Items进程和线程的包含内容
|
Per process items |
Per thread items |
|
Address space 地址空间 |
Program counter 程序计数器 |
|
Global variables 全局变量 |
Machine registers 机器寄存器 |
|
Open files 打开的文件(fd) |
Stack 线程堆栈 |
|
Child processes 子进程 |
|
|
Pending alarms 等待警报 |
|
|
Signals and signal handlers 信号和信号处理 |
|
|
Accounting information 统计信息 |
一个进程包含许多资源,如地址空间、打开的文件、统计信息等。除了这些资源外,进程还有一个控制线程,例如程序计数器、寄存器内容、堆栈。线程的思想是允许多个控制线程在一个进程中执行,这通常被称为多线程,线程有时被称为轻量级进程。由于同一进程中的线程共享如此多的状态,因此在它们之间切换的代价要比在独立进程之间切换低得多。右边的表格显示了给定进程中所有线程共有的属性,以及特定于线程的属性。
同一进程中的各个线程并不是完全独立的。例如,它们之间没有内存保护。这通常不是一个安全问题,因为线程是协作的,而且所有线程都来自同一个用户(实际上是同一个进程)。然而,共享资源确实使调试更加困难。例如,一个线程可以很容易地覆盖进程中另一个线程所需的数据,当第二个线程失败时,原因可能很难确定,因为倾向于假设失败的线程导致了失败。您可能还记得,微内核操作系统设计的一个重要优势是,独立的操作系统进程即使有bug,也不会破坏彼此的数据结构。
同一个进程中的一个新线程通过thread_create()函数创建,类似的还有thread_exit()函数用于结束线程,线程控制中与wait()函数类似的函数是thread_join()用于让主线程等待其余线程或特定线程结束。
thread_yield()方法将线程由运行态转移至就绪态,即让目标线程立刻出让CPU资源,类似于操作系统对进程的调度。
Homework 7
15. Why would a thread ever voluntarily give up the CPU by calling thread_yield? After all, since there is no periodic clock interrupt, it may never get back the CPU?
pthread_yield() causes the calling thread to relinquish the CPU. The thread is placed at the end of the run queue for its static priority and another thread is scheduled to run. For further details, see sched_yield(2).
Strategic calls to sched_yield() can improve performance by giving other threads or processes a chance to run when (heavily) contended resources (e.g., mutexes) have been released by the caller. Avoid calling sched_yield() unnecessarily or inappropriately (e.g., when resources needed by other schedulable threads are still held by the caller), since doing so will result in unnecessary context switches, which will degrade system performance.
如果调用线程是当时最高优先级列表中唯一的线程,那么在调用sched_yield()之后,它将继续运行。sched_yield()可用的POSIX系统在<unistd.h>中定义_POSIX_PRIOR‐ITY_SCHEDULING。对sched_yield()的战略性调用可以通过在调用方释放(严重)竞争资源(例如互斥锁)时给其他线程或进程一个运行的机会来提高性能。避免不必要或不适当地调用sched_yield()(例如,当其他可调度线程所需的资源仍然由调用者持有时),因为这样做将导致不必要的上下文切换,这将降低系统性能。
进程中的线程是合作关系,那么为了让应用程序运行的更好需要正在运行的线程主动放弃CPU:
- a. 优先级问题,有更重要的线程需要立刻进行处理;
- b. 资源问题,释放一些当前线程占用的资源让系统整体有更高的运行效率;
posted on 2021-10-26 11:05 ThomasZhong 阅读(105) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号