现代操作系统:进程与线程(三)
2.1.5 进程的实现
操作系统将关于每个进程的数据组织在一个表中,很自然地称为进程表(Process Table)。该表中的每一项称为一个进程表项(Process Table Entry)或进程控制块(Process Control Block)。
进程表的特点:a. 每个进程表项表示一个进程;b. 这个数据结构用于系统的进程管理;c. 进程状态的转换是由PCB中的一个或多个字段值的变化所反映的;d. 我们将一个活动进程抽象化为了PCB这个数据结构,Finkel称其为级别准则,即在高等级看它是一个活动进程,但是在低级别看它是一个数据结构。
每一个PCB中包含了非常多关于进程的信息,主要有以下一些字段:
- 进程在非运行态时需要保存的寄存器值,其中包含一些程序员不能直接访问的寄存器,如程序计数器(保存了下一条需要运行指令的地址);
- Stack Pointer堆栈指针;
- CPU Time Used使用CPU的时间;
- Process ID PID进程ID;
- Parent Process ID PPID父进程ID;
- User ID UID用户ID;
- Group ID GID组ID;
- Pointer To Text Segment指向文本段的指针(系统指令所在内存段);
- Pointer To Stack Segment指向堆栈段的指针(用于自动或局部变量的内存);
- Pointer To Data Segment指向数据段的指针(用于静态变量和对象的内存);
- UMASK权限掩膜(用于确认新文件的默认rwx权限);
- Current Working Directory当前的工作目录;
- Many Others其他的很多很多;
2.1.6 An Addendum on Interrupts对中断的补充
中断的定义:中断是指处理机在执行进程的过程中,由于某些事件的出现,暂时停止当前进程的运行,转而去处理出现的事件,待处理完毕后返回原来被中断处继续执行或者调度其它进程执行。
所有的中断都从保存寄存器开始,对当前进程而言,通常是保存在PCB中,随后会从堆栈中删除由中断硬件机制存入堆栈的那部分信息,并且将堆栈指针指向一个由进程处理程序所使用的临时堆栈。一些诸如保存寄存器值和设置堆栈指针的操作需要使用汇编语言例程完成,通常该例程可以供所有的中断使用,因为无论中断是怎么引起的,有关保存寄存器的工作是完全一样的。在汇编例程执行完毕后,它会调用一个C过程处理某个特定类型的中断剩下的工作,在完成相关的工作后,大概就会使某些进程进入就绪态,接着使用调度程序来决定随后运行哪个进程。再然后将控制权限转给一段汇编语言例程,这个例程为当前的进程装入寄存器值以及内存映射并启动该进程运行。
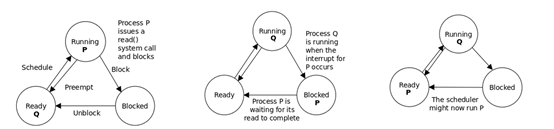
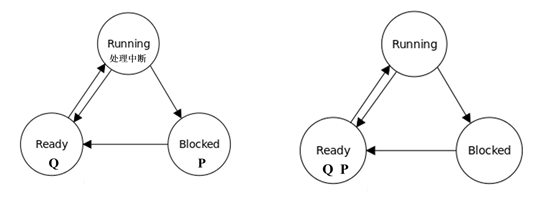
图1:P正在运行,此时P发生read()系统调用,此时P被阻塞转到Blocked,然后调度器会从Ready的进程中选一个优先级高的,如果只有一个Q那只能选Q;
图2:此时从磁盘开始获取到read()需要的数据,到在设备控制器发送中断告知CPU数据读取完毕前,P一直位于Blocked状态,Q处于Running状态;P在等待设备控制器向他发送一个表明数据读取完毕的中断。
图3:当磁盘读取完毕后,设备控制器告知OS P之前的读取指令已经完成(发送中断),那么OS将解除P的Block状态将其转为Ready状态,那么等待Q处理完毕,则调度器会将P分配给CPU继续运行。
需要注意的是:磁盘中断不太可能针对位于当前正在运行的进程,因为启动磁盘访问的进程在系统调用之后一般都会进入阻塞态,等待资源分配到位。
中断本身只指定中断号,与前面的Trap一样,OS在硬件指定的内存位置存储了一个中断向量,其中包含了所有中断处理程序的地址:
- Tanenbaum将中断处理程序称为中断服务程序;
- 实际上中断也具有不同的中断优先级,因此中断向量包含每一级中断的一个指针;
Actions by Q Just Prior to the Interrupt: Q在中断前的操作
- 1. 没人知道,因为中断可以发生在任何地方,因此我们也不知道具体在中断前发生了什么,这也是调试包含中断的代码时遇到的主要困难。A. 使用硬件监视器可以确定某个特定的执行发生了什么,但是重新执行进程后中断也可能发生在不同的位置;B. 实时上我们甚至都不知道在中断发生时哪一个进程正在运行,多次执行产生的结果很可能是不同的;C. 我们并不能很明确的认为某一条指令产生了中断;D. 我们唯一能做的事就是对于特定的一个执行对应的指令,认定这条指令一定发生在了中断之前。
Executing the interrupt itself: 处理中断自身
- 系统硬件保存程序计数器和一些其它的重要的寄存器(向PCB);
- 然后基于中断编号在中断向量表中找到对应中断处理程序的地址并跳转到该地址;
- 接下来系统转到内核模式(如果已经在内核模式就无所谓了)。
Actions by the interrupt handler (et al) upon being activated 中断处理程序被激活后的操作
- 内核中的汇编语言程序保存寄存器值;
- 堆栈寄存器指向内核(系统)堆栈;
- 汇编程序进一步调用高级语言程序,通常是C语言;
- C语言程序执行真正的工作,找到为何产生中断并执行对应的处理:
- 找到中断的原因:它知道被触发的中断的优先级信息;控制器可能会在中断前将信息写入内存;操作系统可能会读取控制器中的寄存器;
- 将进程P从Blocked转为Ready:P被移动至就绪态的进程队列中;P最初执行的代码可能是OS的代码,比如刚刚读取到的数据现在可能存放于内核中间中,OS需要将其复制进入用户空间中。
- 现在OS中至少有两个进程P,Q,可能还有其它任意多个进程。
- 调度器开始决定先运行哪个进程,P或者Q或者其余的某个进程,比如开始运行P然后最后运行Q;
Actions by The OS When Returning Control to Q:控制回到Q时OS的操作
- C语言程序继续执行并且在结束后后回到汇编语言程序;
- 汇编语言程序重新加载进程Q的状态,并且从中断处开始执行Q;
Properties of Interrupts中断的特性
A. 哎呀!喵喵喵?
B. 中断的发生是不可预测的,我们不知道在中断前执行了什么,也就是说控制的转移是异步的,很难确保系统当前为转移做好了一切准备;
C. 无法找到导致中断的命令;
D. 进程Q中的用户代码并没有意识到会发生中断,处理中断的流程是由OS负责的;
E. 当操作系统本身正在执行时也会发生中断,这会导致更大的困难,因为被中断的操作系统代码和中断处理代码都来自于同一个程序,因此很有可能使用相同的变量。
F. 进程间的控制传输既不是堆栈式的也不是队列式的而是一直在竞争,这就导致了中断结束后很有可能选则任意一个就绪态的进程进入运行态;
G. 当中断发生时,系统可能处于用户态也有可能处于内核态,中断处理本身处于内核态。
2.1.7 Modeling Multiprogramming多路编程模型
区分:uniprogramming, vs. multiprogramming, vs. parallel processing
- uniprogramming意味着一次只在内存中加载一个作业,单进程;
- multiprogramming多道编程意味着多个进程被加载,CPU/OS在它们之间切换调度。
- 并行处理有时意味着多道编程,但通常意味着有多个cpu,因此多个进程可以同时运行。
考虑一个无法计算时间的一小部分作业(例如正在等待I/O)
- 当系统中只有一个作业正在运行时,CPU的利用率为1-p;
- 通常p>0.5,因为CPU的利用率很低;
- 当系统中存在n个作业时,则所有n个作业都在等待I/O的概率是1-p^n;
- 所以假设当p=0.5且n=4时,多道编程带来的系统等待时间期望是15/16;
很显然,15/16相较于n=1时的1/2带来了极大的效率提升。
上述建模过程中至少有两个地方是不准确的:
- 操作系统在从一个进程切换到另一个进程时要进行上下文切换,进程切换会花费一部分的CPU时间,因此有效利用率即CPU执行代码的时间比例应当低于预期;
- 该模型假设一个进程等待I/O的概率和另一个进程等待I/O的概率无关,但实际上并不是完全无关的;
- 另一个额外的问题是内存,当我们批量打开很多进程时需要足够的内存供这些进程使用。
Homework 6
- 1. In Figure 2-2, three process states are shown. In theory, with three states, there could be six transitions. However, only four transitions are shown. Are there any circumstances in which either of both of the missing transitions might occur?
- What is the key difference between a trap and an interrupt?
- 7. Multiple jobs can run in parallel and finish faster than if they had run sequentially. Suppose that two jobs, each of which needs 10 minutes of CPU time, start simultaneously. How long will the last one take to complete if they run sequentially? How long if they run in parallel? Assume 50% I/O wait.
A1:一般情况下不能直接从阻塞态直接转变为运行态,就绪态也不能直接转变为阻塞态。首先阻塞态必须先转为就绪态才能转为运行态,因为支持多道批处理的操作系统中需要调度器在就绪态的进程队列中选择合适的进程转为运行态,如果跳过就绪态直接到达运行态就缺失了调度的步骤,会打乱整体的系统稳定性,如果想要立刻运行可以给这个进程一个高一点的优先级。但是假设是一个非常特殊的环境,只支持单道程序运行的操作系统,这个时候整个操作系统中只存在一个进程,那么CPU在不处理这个进程的时候就一直是空闲的,一旦这个进程由阻塞转为就绪时就可以立刻被分配至CPU运行,那么此时就绪态实际上名存实亡,那么可以视为是一种特殊的由阻塞态转变为运行态。就绪态在任何情况下都不可能直接转为阻塞态,因为一个处于就绪态的程序不可能会产生任何系统调用产生阻塞或被设备中断产生阻塞,只有处于运行态的进程才会被自己内部或外部的事件阻塞。
A2:Trap和Interrupt的主要区别:
(1) Trap称为内中断,是由处理器和内存内部产生的中断,Trap中可能包含了程序运算引起的各种错误,由用户态向内核态的转换等;Interrupt称为硬中断,是由系统外接硬件向CPU发起的,一般包括I/O中断、外部信号中断以及各类定时器引发的时钟中断;
(2) Trap通常是由处理机内部正在执行的现行指令引起的,如程序员知道哪里会发生系统调用,哪里的运算可能会产生错误;Interrupt是由与现行指令无关的中断源引起的;
(3) Trap处理程序提供的服务为当前运行的进程所用,如系统调用将当前进程由用户态转为内核态;Interrupt处理程序提供的服务则不是为了当前进程的,如I/O完成后将进程由阻塞态转到就绪态;
(4) CPU执行完一条指令后,下一条指令前响应Interrupt而在一条指令执行的过程中也可以响应Trap;
A3:顺序执行就是,并行执行。理论情况下两个进程都是先运行5分钟,再执行10分钟I/O,再运行5分钟,那么就会有这样的时间线:
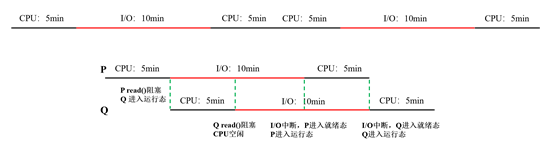
但是不能这样算,要拿公式算:p=0.5, n=2则CPU的利用率是1 - 0.5 * 0.5 = 0.75,那么此时并行计算的时间消耗 T = (10 + 10) / 0.75 = 26.7min。
posted on 2021-10-26 11:01 ThomasZhong 阅读(223) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号