现代操作系统:概述(四)
1.7 Addendum on Transfer of Control 控制权限的转换
用户进程和操作系统内核之间的控制传递可能非常复杂,特别是在阻塞系统调用、硬件中断和页面错误的情况下(都会产生中断,但区分为Trap和Interrupt)。我们稍后再处理这些问题;这里我们研究一个熟悉的用户模式进程中的过程调用示例。
一个重要的操作系统目标是,即使在更复杂的页面错误和阻塞系统调用需要设备中断的情况下,也可以从用户进程的角度观察简单的过程调用语义。复杂性隐藏在内核本身,这是操作系统为用户进程提供更抽象,也就是更简单的虚拟机的另一个例子。
更多的细节将在我们学习内存管理(并正式了解页面错误)和I/O(并正式了解设备中断)时添加。下面的一些细节还远远没有标准化。例如参数放置在哪里,哪个进程保存寄存器,Trap的确切语义等,都会随着语言/编译器/操作系统的变化而变化。事实上,其中一些被称为调用约定,也就是说,它们的实现是约定的问题,而不是逻辑要求。我希望下面的演示是合理的,但必须被看作是对可能发生的事情的一般描述,而不是对实际发生的事情的真实描述,比如,在Windows 10上运行的微软编译的C语言。
1.7.1 用户堆栈和系统堆栈的切换
当系统在创建一个进程时会为一个进程开辟两个堆栈分别是:用户堆栈和系统堆栈,进程在用户态时使用用户堆栈,在内核态时使用内核堆栈。
当进程P正常运行时,CPU中的堆栈寄存器ESP指向用户堆栈对应的地址,当进程由用户态向内核态转变时(发生系统调用触发Int 0x80软中断),CPU会将用户堆栈的地址保存到内核堆栈中,同时还会保存一些EIP,FLAG等寄存器,然后将ESP指针指向内核堆栈的地址,实现用户堆栈向系统堆栈的切换。
反之当系统调用完成后,然后弹出用户堆栈所在地址(也就是EBP)、EIP,FLAG等寄存器,将该地址存储在ESP寄存器中,完成内核堆栈向用户堆栈的切换。
https://www.k2zone.cn/?p=1911
ESP拓展栈指针(Extended Stack Pointer)寄存器:用于存放函数栈顶指针;
EBP扩展基址指针(Extended Base Pointer)寄存器:指向最后一个栈帧底部的指针;
EIP拓展指令指针(Extended Instruction Pointer)寄存器:存储Return语句后的下一条指令所在位置;
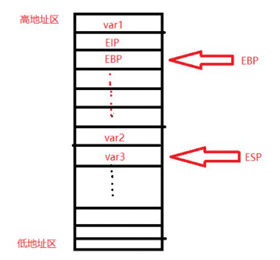
1.7.2 User-mode Procedure Calls 用户态程序调用
进程P中的步骤调用了方法
a. f调用g前的操作
将register压入运行时堆栈,再将g所需的参数按c,b,a的顺序压入堆栈;
问题:为什么要以反序压入堆栈?参数的数量问题!如果每个函数的参数数量和其声明的参数数量是一致的,那么编译器就可以计算出到一个参数的正确的偏移量,但是类似于printf这种可以无限添加参数的函数,这个偏移量就无法计算正确。反向压入堆栈的结果是第一个参数位于栈顶,那么相对于正向压入来说,这个偏移量一定是一个固定值。b. 处理调用
执行MethodCall(g的起始地址),这个指令保存了程序计数器(需要返回的地址)并跳转至g的起始地址,保存的值是更新之后的程序计数器值(当前函数f的下一个地址)。
c. g被调用时的操作 SP:Stack Pointer 堆栈向下生长,减SP值相当于增加堆栈空间
通过减小SP为g的局部变量开辟空间(方法中的局部变量也保存在运行时堆栈内,当方法调用结束时,这些局部变量会被释放),然后从g的初始地址开始执行,当然在执行过程中可能产生进一步的函数调用甚至递归调用。
d. 返回f时g的操作
将g的返回值存储在一个约定好的位置上,通过增加SP释放g的局部变量,执行return指令,然后将PC设置为b中存储的需要返回的地址位置。
e. 当g返回后f的操作
通过增加SP值从堆栈中移除先前想传给g的参数,当从堆栈中取值时不断恢复寄存器中的数值,然后继续执行f,如果g有返回值不要忘了在对应的位置取出返回值。
用户态下的调用特性:
- 可预测的行为:过程f的编码者知道函数g的调用将在何时何处发生。这并不奇怪,因此程序员可以相对容易地确保f为控制权的转移做好准备;
- Last In First Out(LIFO)控制转移:我们可以确定当g退出时一定会回到f继续执行,如果g进一步调用了h那么保持同样的递归处理方式,从h返回到g再返回到f;
- 上述提及的所有调用都发生在用户模式和用户空间中。
1.7.3 Kernel-mode Procedure Calls内核态程序调用
我们现在考虑一个在内核模式下运行的进程调用另一个同样在内核模式下运行的进程,即操作系统本身中的进程调用。在下一节中,我们将讨论从用户态到内核态的切换。
在内核模式的程序调用和用户模式的程序调用所采取的操作没有太大区别,在内核态下执行的进程被允许发出特权指令,但是用于传输控制的指令都是无特权的,所以在这方面没有变化。
一个区别是在内核模式中通常使用不同的堆栈,但这只是意味着在从用户态切换到内核态时,必须将堆栈指针设置为内核中的那个堆栈。但这节课我们不会切换模式,假设堆栈指针已经指向内核堆栈。通常有两个堆栈指针,一个用于内核模式,一个用于用户模式。
1.7.4 The Trap/RTI Instructions: Switching Between User and Kernel Mode Trap/RTI指令:切换用户态和内核态
与进程调用一样,Trap指令也是一种可控制的同步传输:我们可以看到它在何处以及何时执行。在这方面,没有什么令人惊讶的。尽管并不令人惊讶,但Trap指令确实有一个不同寻常的效果:将处理器执行从用户模式切换到内核模式。也就是说,Trap指令本身通常以用户模式执行(它自然是一条非特权指令),但执行的下一条指令(不是在Trap之后写入的指令)是在内核模式执行的。
进程P在非特权(用户)模式下执行Trap指令,并且Trap指令是由汇编程序发出的,因为高级语言中没有Trap指令。我们不需要为正在执行的函数命名,将下面的例子与上面给出的f调用g的解释进行比较。
a. 在Trap指令前P的操作
通过将寄存器压入堆栈来保存寄存器。存储要传递的任何参数,堆栈通常不用于存储这些参数,因为内核有一个不同的堆栈,通常直接压寄存器。
b. 处理Trap指令
执行Trap。该指令将处理器切换到内核(特权)模式,跳转到操作系统中由trap-number决定的位置,并保存返回地址。例如,处理器可能被设计成:在Trap之后执行的下一条指令的物理地址是trap-number的8倍。(可以将trap-number看作是处理器将跳转到的代码序列的名称,而不是trap的参数。)
c. OS在Trap指令后的操作
跳转到真正的代码。具有不同Trap编号的Trap指令跳转到的位置往往非常接近,对于Trap指令的处理而言它们之间并没有足够的空间。事实上,我们可以将Trap想象成具有一个额外的间接层次,它先跳转到一个位置,然后再跳转到代码实际的起始位置(二段跳)。检查所有传递的参数,内核必须保持严谨的态度且假设用户是坏人。由于用户栈和内核栈是分开的,因此需要通过递减内核SP来为变量分配临时空间,然后从跳转到的位置开始执行。
d. 返回到用户态时OS的操作
如果函数存在返回值,就要把返回值存储在约定的位置上,然后开始递增内核SP释放临时变量空间,最后执行一条特殊的RTI(ReTurn From Interrupt)指令从中断返回,这条指令让处理器切换回用户态并且将控制转移到由Trap记录的需要返回的位置。词中断出现,因为RTI指令同样被用于内核从其它中断返回(不仅仅适用于Trap中断)。事实上,RTI不总是返回到用户态,它的特性是回到Trap或某个中断之间的一个有效状态。
https://www.baeldung.com/cs/os-trap-vs-interrupt
e. 由OS返回后P的操作
回收所有传递参数所使用的空间,从栈中弹出并恢复寄存器,继续执行P,如果有返回值则在约定位置获取返回值。
1.7.5 Trap和RTI的特性
a. 同步行为Synchronous behavior:编写P进程中汇编代码的作者是明确知道在哪里会发生Trap的,所以对于编码者来说是很容易去准备程序控制权限的转移的;
b. 在P处查看微小的控制转移:P执行的下一条指令是Trap指令后的那一条,我们将在后面看到,其他进程可能在P的Trap指令和P的下一条指令之间执行。
c. 在用户态和用户空间中开始和结束,但是在内核态和内核空间中执行;
注意:使用附录中的材料的一个好方法是逐行比较第一种情况(用户模式f调用用户模式g)和TRAP/RTI情况,以便您可以看到相似和不同之处。
posted on 2021-10-03 22:35 ThomasZhong 阅读(143) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号