ann-benchmarks中recall计算方法解读
Faiss的ivfPQfs索引方法的recall有两种:
- 一种是Faiss提供的R@k,指的是搜索得到k个点,包含groundtruth中top-1的queries占查询个数的比例
- 另一种是我们通常使用的recall,recall@k指搜索得到的k个点中与groundtruth的前k个点重合的比例
但是我在运行faiss的时候却发现,在使用同一组参数的情况下,recall@10无法达到ann-benchmark中显示的召回率:(不知道大家有没有遇到和我一样的问题)
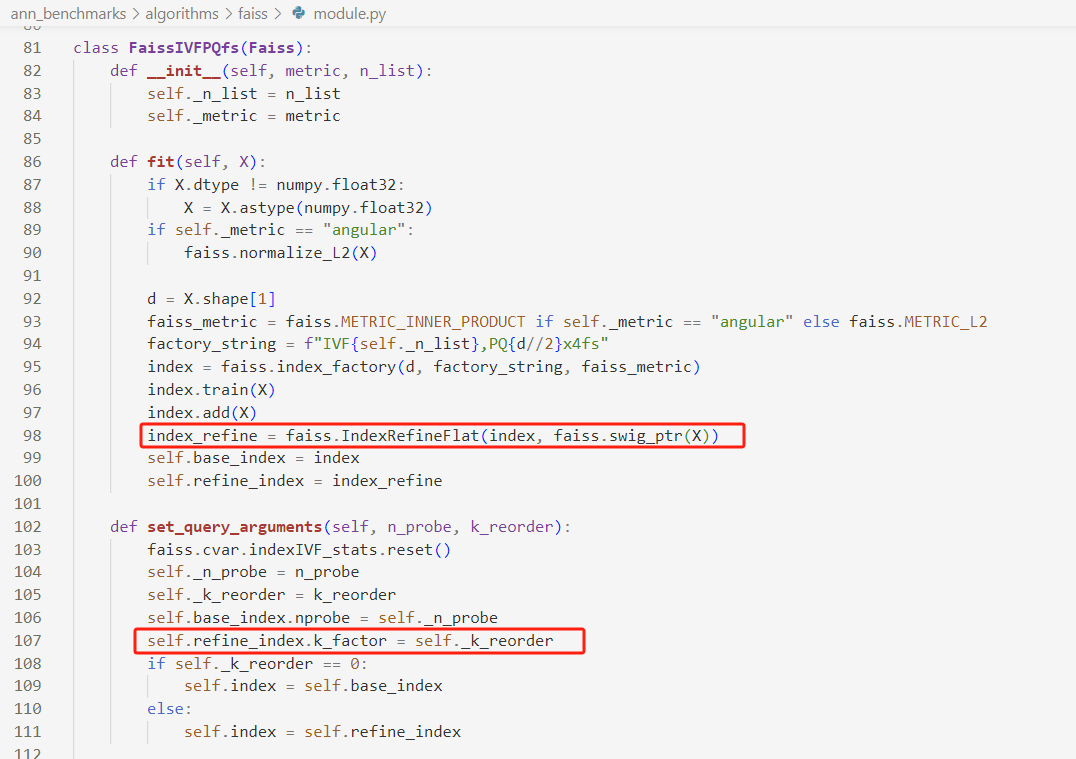
省流:最后发现问题出在索引构建阶段,ann-benchmark中使用了IndexRefineFlat的操作,而我没有使用,如果加上这个操作,我的代码recall达到了0.97043!

运行结果:
recall = 0.61078
R@1 = 0.5099
R@10 = 0.9327
R@100 = 0.9873
recall = 0.61097
R@1 = 0.5104
R@10 = 0.9325
R@100 = 0.9325
然而在ann-benchmarks中运行结果为0.97
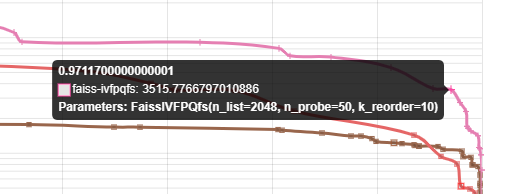
于是我怀疑ann-benchmark使用的是第二种,下面仔细分析ann-benchmark的recall计算方法
图像中对应的参数为:
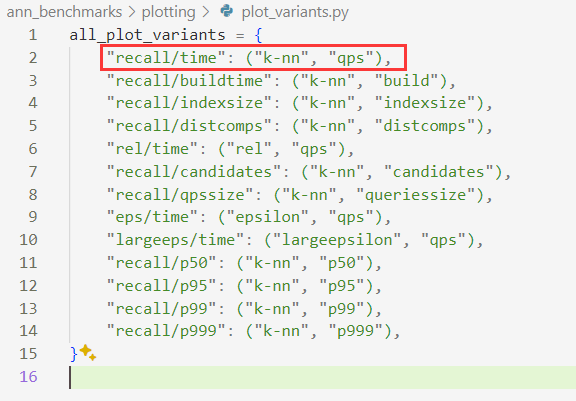
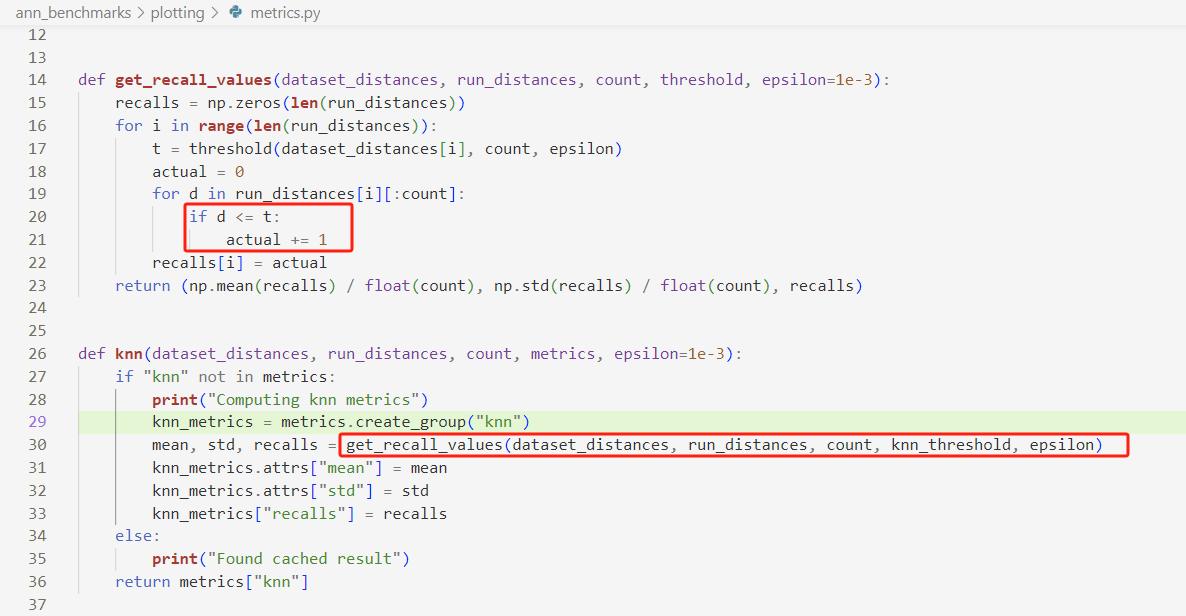
主要关注"k-nn",在度量方法中,“k-nn”调用了knn函数,该函数输入参数true_distances、run_distances、run_attrs["count"]、metrics,返回一个具有attrs属性的对象,包含一个名为"mean"的键:
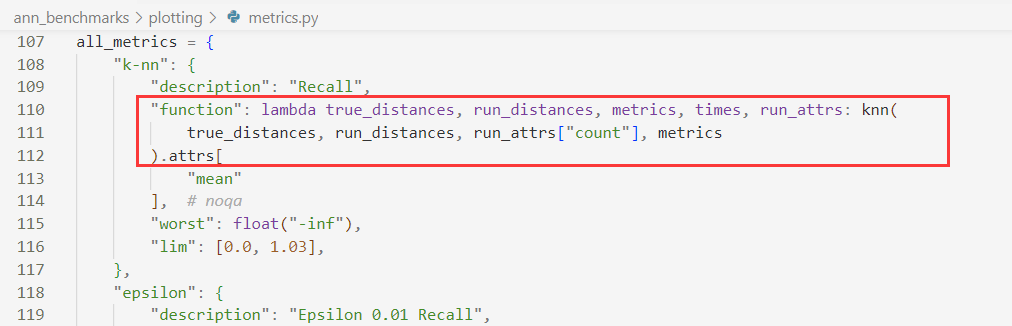
下面去观察knn函数,这个函数在metrics中创建了一个名为"knn"的group,并且用knn_metrics对其进行操作,调用了get_recall_values计算recall的平均值、标准差和recall值:

下面去看在哪里调用的knn函数,以及data_distance和run_distance保存的是什么
从main函数开始阅读,在main函数的最后调用了函数create_workers_and_execute函数:
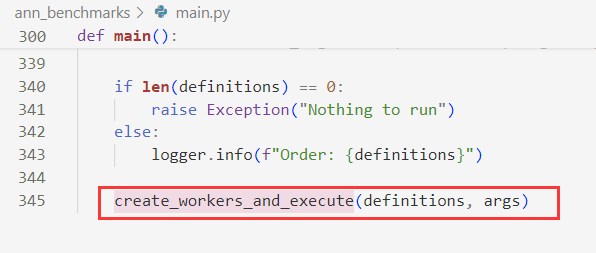
在这个函数中,创建了一个包含多个进程的列表workers,每个进程都会执行run_worker函数,然后启动每个进程并等待它们完成,因此进入run_worker函数:

run_worker函数中,调用本地或docker容器中的run函数,携带的参数为definition,dataset是数据集,count默认是10,指的是the number of near neighbours to search for:

进入run函数,在函数中计算结果并存储结果:
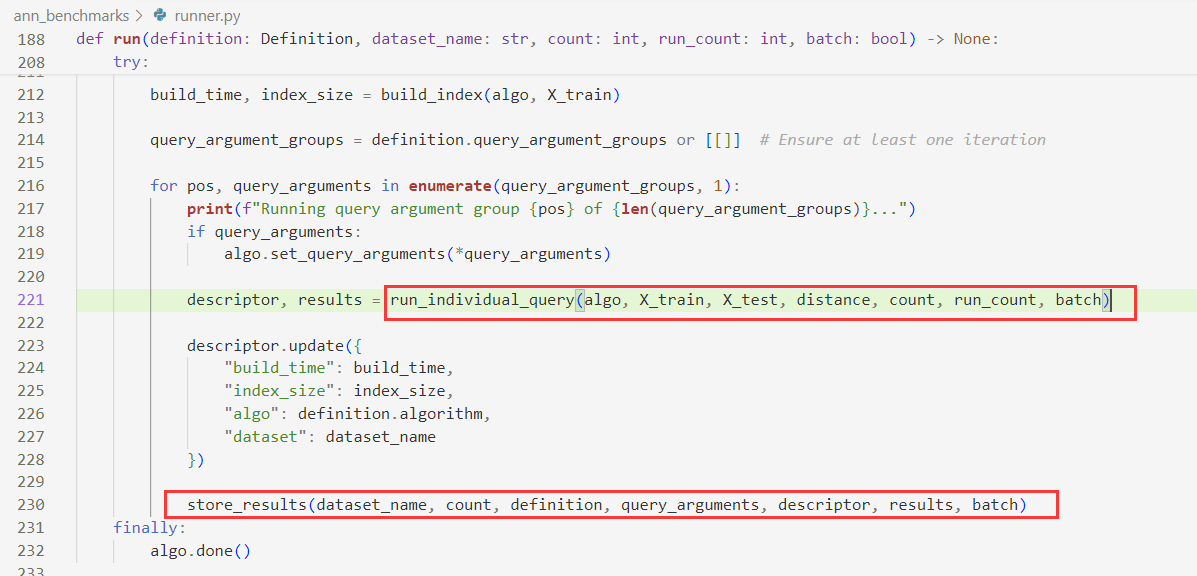
在run_individual_query中会调用相应索引方法的query函数形成candidates,然后返回,这里的query函数就定义在相应的索引文件夹的module.py内:
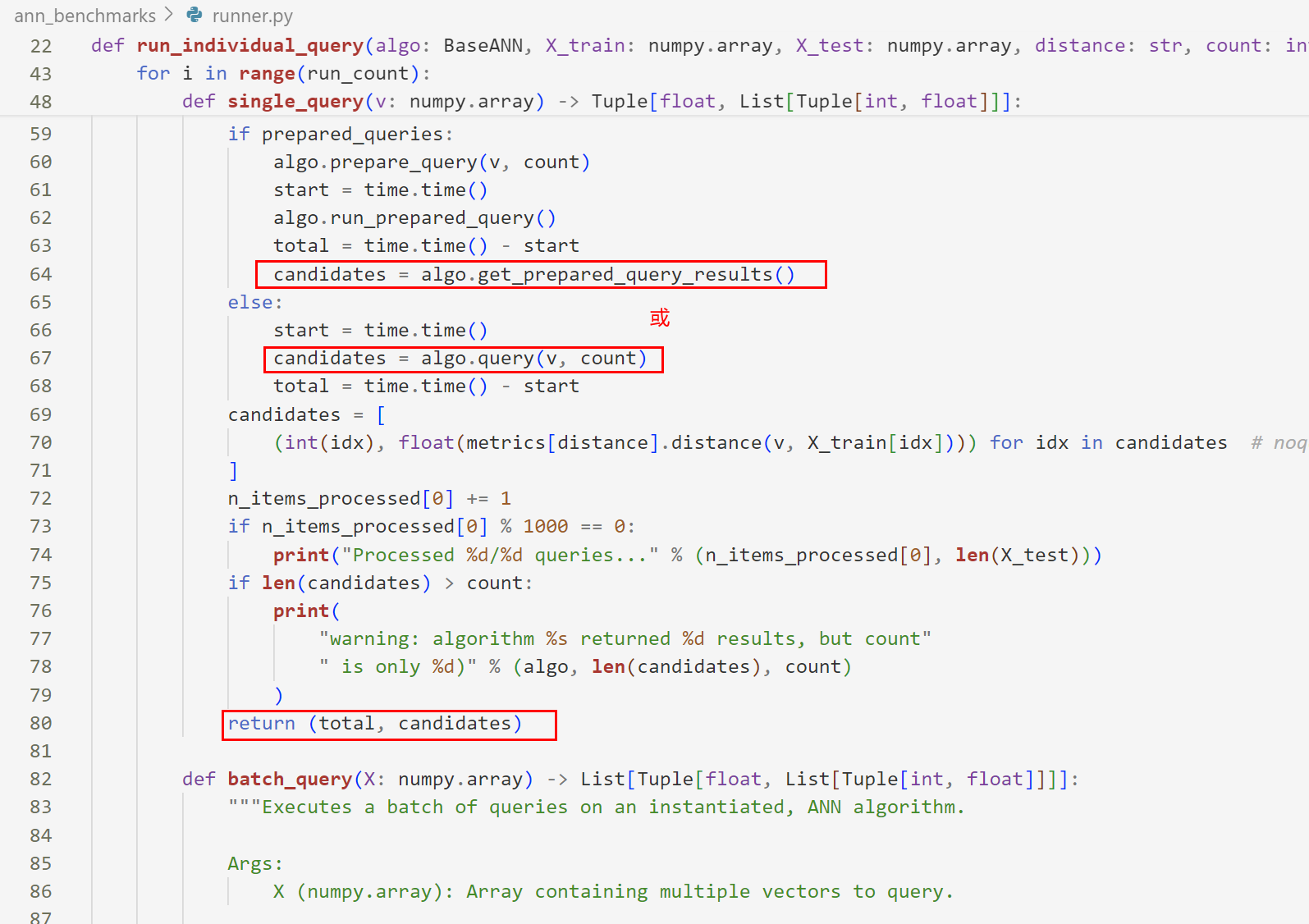
进入faiss文件夹,查看yml文件对于“faiss-ivfpqfs”算法的定义,构造函数使用的是FaissIVFPQfs,模块使用ann_benchmarks.algorithms.faiss。
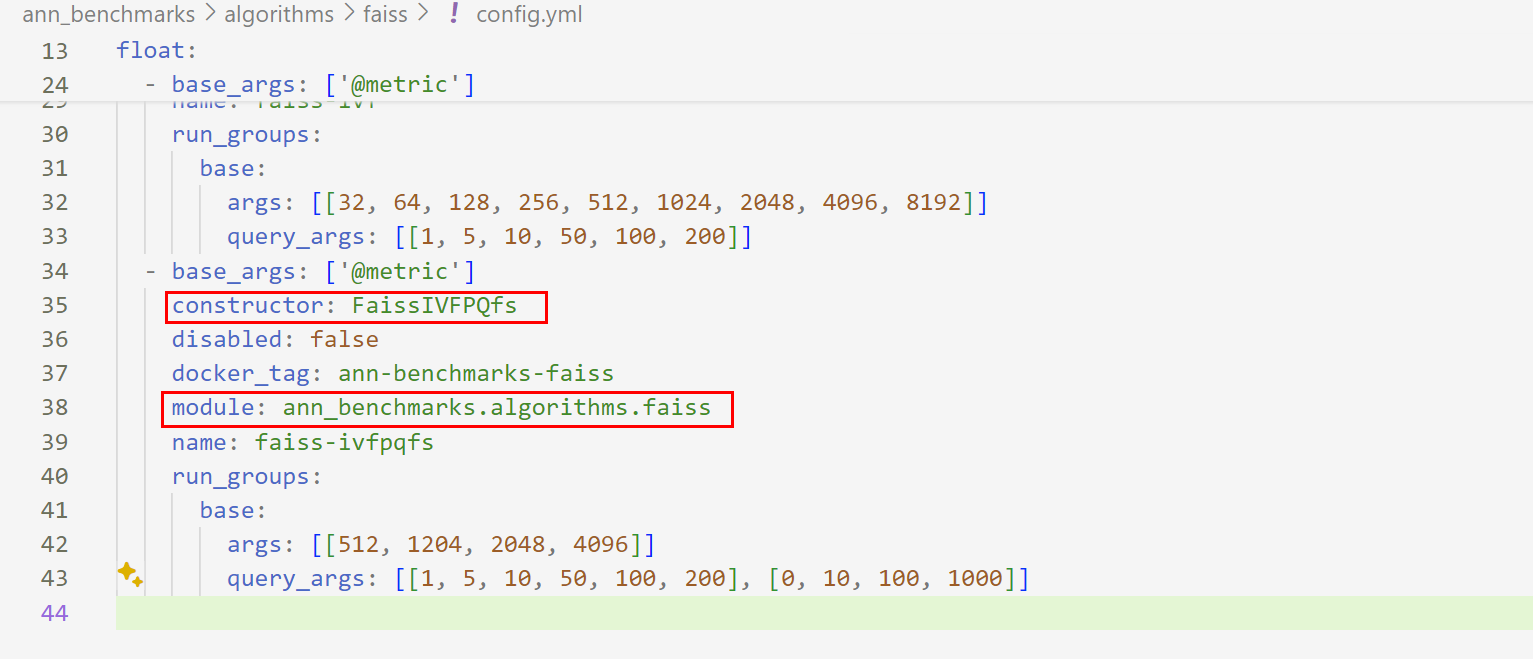
进入module.py中,观察到query函数实际上就是调用了index.search函数:
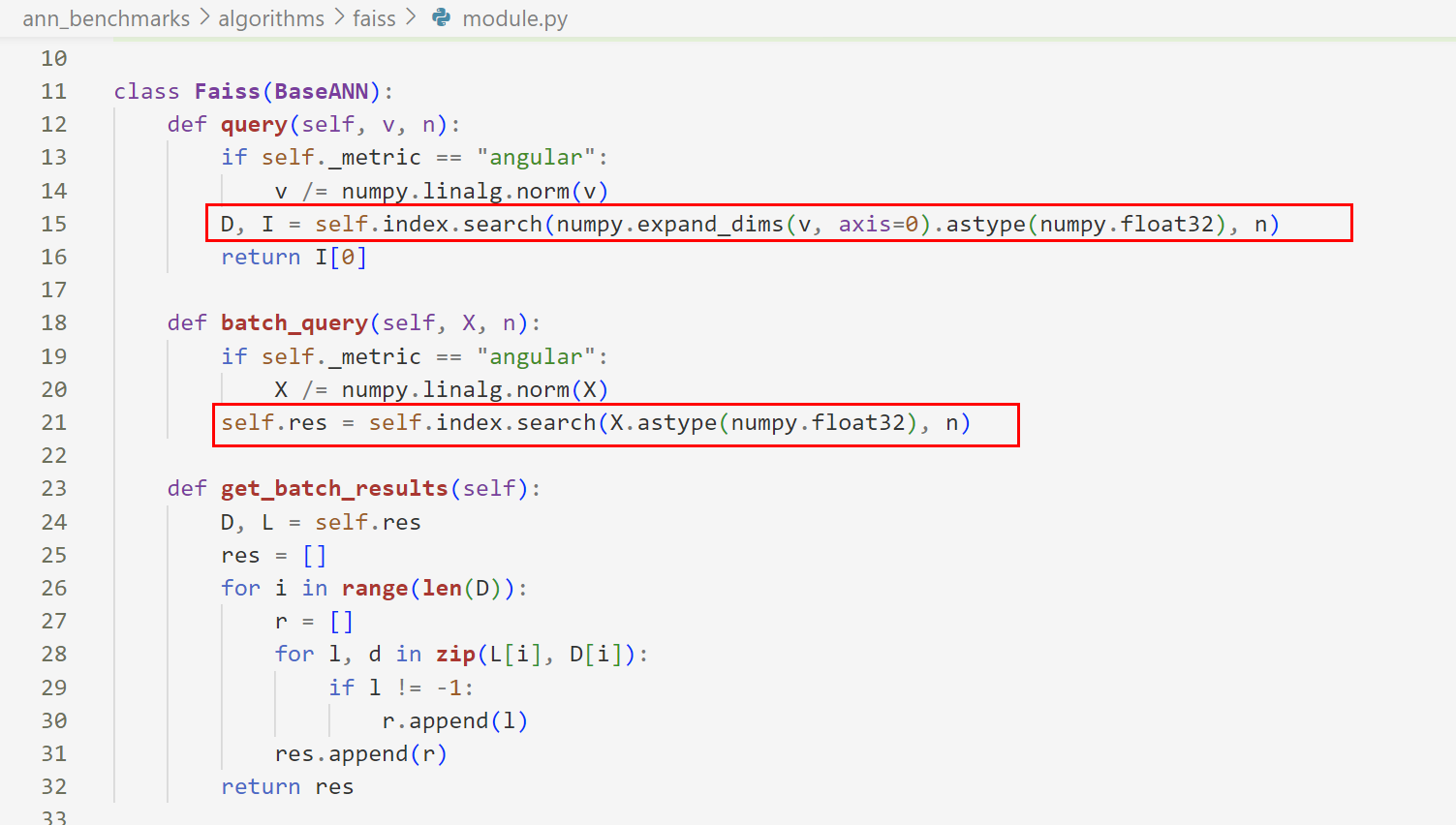
而对应于faiss的index.search为:
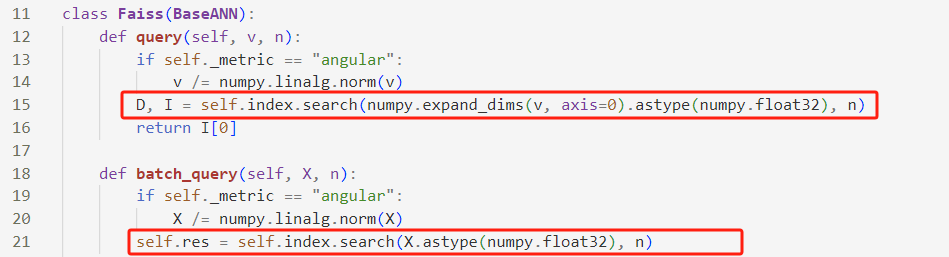
这完全没有任何问题,再来看recall,这里的recall计算方法是先算出query与groundtruth中第k个点的距离,然后将距离小于该值的点算入recall,这其实也没有问题:
最后发现问题出在索引构建阶段,ann-benchmark中使用了IndexRefineFlat的操作,而我没有使用,如果加上这个操作,我的代码recall达到了0.95!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号