丢人,被自己出的校招题给麻痹了。
你好呀,我是歪歪。
先给大家推荐一个躺在我收藏夹里面好几年的一个好东西。
http://mysql.taobao.org/monthly/
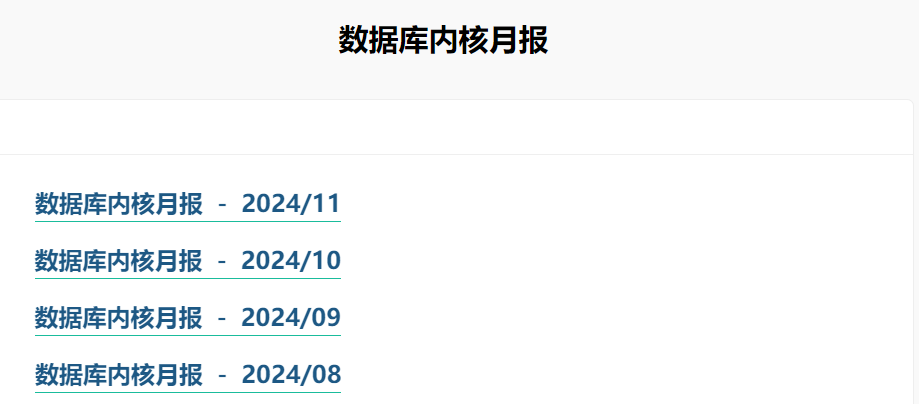
数据库内核月报,是阿里云的数据库内核团队从 2014 年开始维护的,内容主要是数据库内核和运维相关经验,这里的数据库不限于 MySQL,还有 PolarDB、PostgreSQL、MongoDB 等等。
链接点进去,你会发现页面非常简洁,标题只有年月,再点击进去,会有详细的文章链接。
比如这是最新一期,2024 年 11 月的月报内容:

月报具体的篇数不确定,有时候只有一篇,有时候又有好几篇。这是今年 9 月的月报内容:

由于这些文章都有阿里云数据库内核团队的背书,质量还是非常有保障的。
这个链接我忘记我收藏了多久了,但是至少也有四年左右的时间了。每隔一个月左右的时间,就点进这个链接里面看看最新的文章,已经养成了一个习惯了。
但是我也不会每篇都读,由于工作中使用的数据库就是 MySQL,所以我几乎只看 MySQL 相关的内容,其他的 DB 我感觉我是学不动了。
早期还会点开链接浏览一下大致内容,现在是看标题,只要不是 MySQL 相关的,都不会点进去看了。

这里面的文章大主题都是数据库相关的,但是又分为很多的分支,比如 BUG 分析、源码分析、特性介绍等等。
歪师傅去年写过这样一篇文章:《我试图扯掉 order by 的底裤。》
里面就是介绍了当 order by 遇到 limit 时可能会遇到的一个看起来像是 “BUG” 的现象。
当时查阅资料的时候,就找到了“数据库内核月报”的一篇文章:
http://mysql.taobao.org/monthly/2015/06/04/

是 2015 年的一篇文章,和我去年写的那篇文章,背景是一模一样的。
当时除了 MySQL 官方文档对于 Limit 关键字的解释外,这篇文章也给我指引了一定的方向。
而我当时来这里找到这篇文章,也纯属“有枣没枣打一杆子”再说,看看有没有相关文章描述过类似的问题,这个用“分页”关键词还真找到了。
此外,还用“Order By”关键词找到了这篇文章,也在我理解源码的时候给到了一定的帮助:
http://mysql.taobao.org/monthly/2021/06/04/
说真的,我遇到过很多 MySQL 数据库的问题,能在这里面找到的相关资料的不多,但是找一下这个动作,反正也不麻烦,总比你直接去网上大浪淘沙的找好多了。
但是当你真的自己尝试去搜索的时候,你会发现这个“月报”不支持搜索啊,每月的标题都是“数据库内核月报 - yyyy/MM”,搜不到里面的内容,怎么办?
你当然可以把每个月的链接里面对应的文章标题和链接自己搞一份出来,方便自己阅读。
但是你要相信,像这种高质量的宝藏网站,你的困难,就是大家的困难,所有肯定已经有“好事之人”帮你解决了困难。
这里提供两个歪师傅在用的。
第一个是这个项目:
https://github.com/tangwz/db-monthly
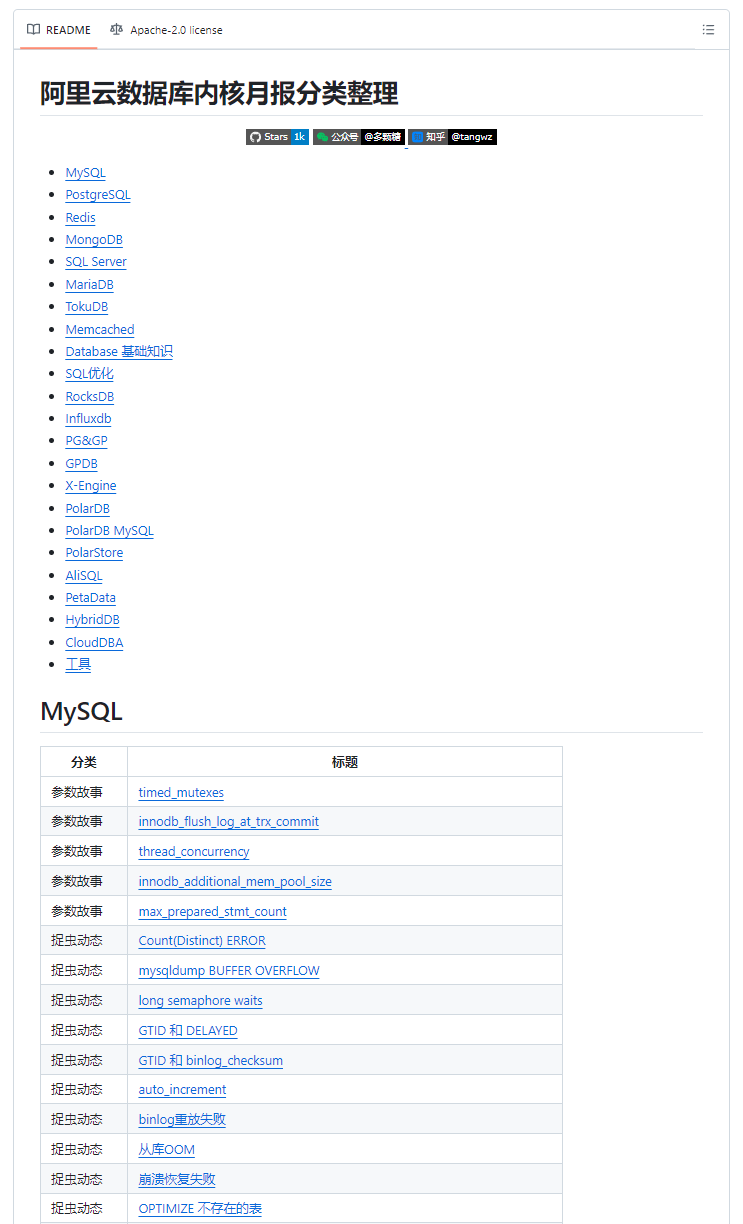
这里面按照类别对文章进行分类打标处理,有每篇文章的标题和具体链接,但是是人工维护,时效性上可能慢点。
好处是对于历史文章方便检索,在页面 Ctrl+F 直接搜就完事了。
第二个是这个项目:
https://github.com/vimiix/ali-db-monthly
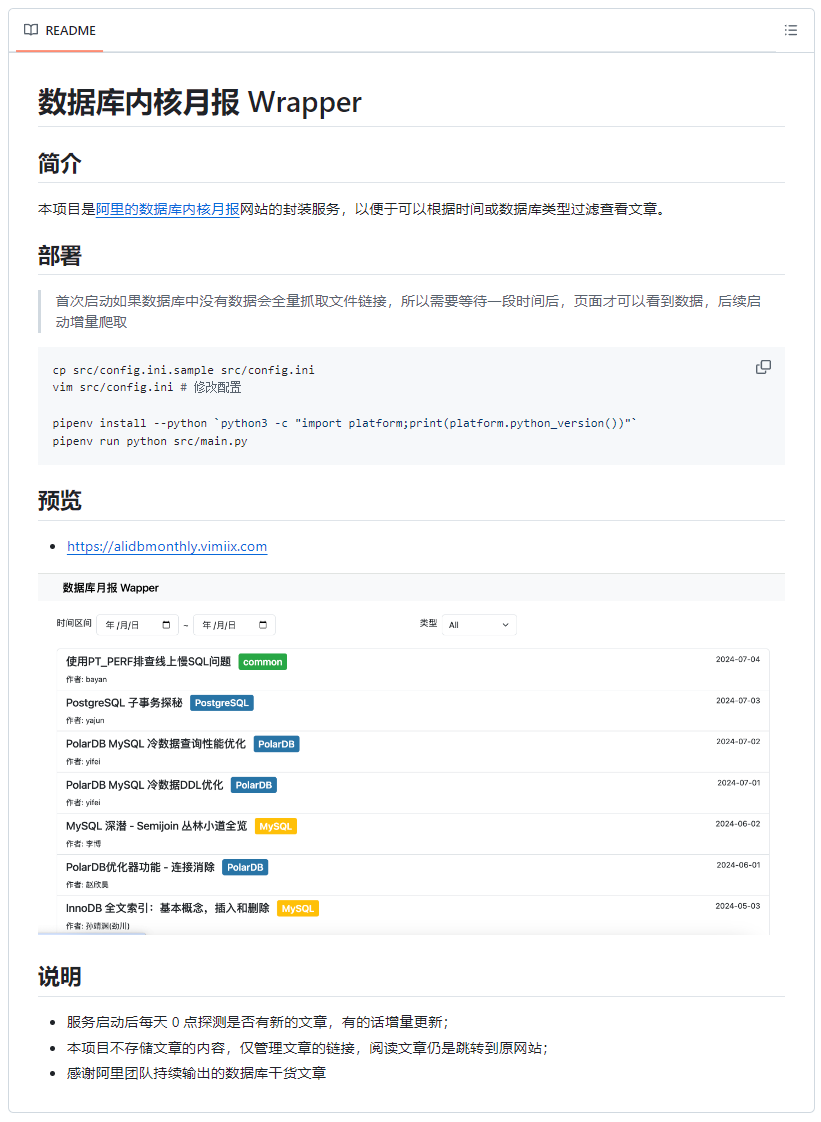
这个项目我是在第一个项目的 Issues 里面看到的,是一个“好事之人”今年才搞的。
提供了一个更加友好的页面,文章也是采用爬虫实现了“每天 0 点探测是否有新的文章,有的话增量更新”:
也是挺不错的,非常感谢这些“好事之人”的贡献。

说回标题
看到这里你可能发现了,这文不对题啊,怎么回事?
别急,这不就是来了嘛。
我为啥突然想给你分享这个“数据库内核月报”这个数据库相关的博客。
是因为前段时间的一个周末遇到一个读者问我关于 MySQL 的一个问题:

当时我看到这个问题的时候,刚刚在峡谷里面选完英雄,准备 carry 全场。
在游戏开始之前,刚好这个问题弹出来,然后我快速的提取了一下关键词:SQL、聚合函数、查询结果不确定...

我在脑海里面检索信息的时候,就像是有一个流程图,通过上面这几个关键词,在加上当时脑子处理信息的时候,还把 order by 和 group by 搞混了,我啪的一下,很快啊,就联想到了前面提到的,之前写过的那篇关于 order by 的文章。
SQL 都没仔细看,当时我就下结论了:这题我见过,和文件排序逻辑有关。
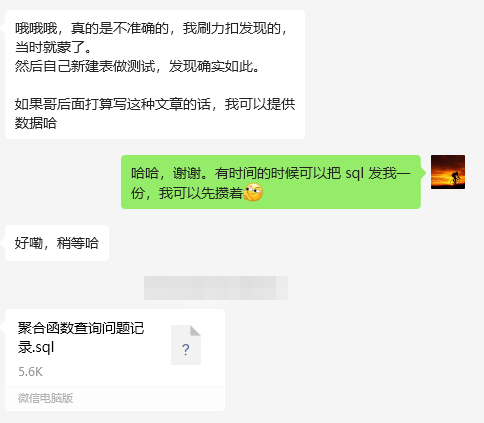
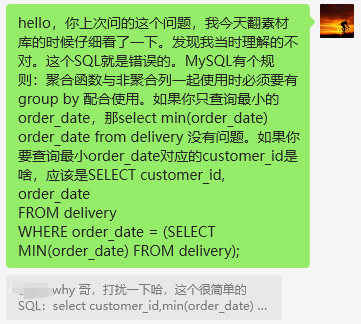
想着也是一个素材,于是就让读者帮忙提供了一下 SQL 文件,我收藏到了“素材库”的标签下:
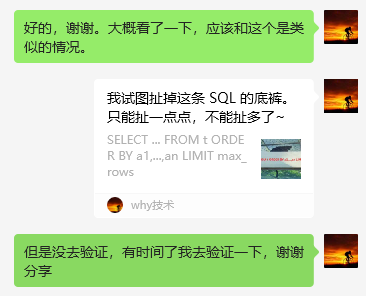
我当时甚至还给他分享了我之前写的这篇文章:
然后我就去峡谷了。
昨天整理素材库的时候,我又看到了这个素材。
看到这个 SQL 的第一眼,我当时就觉得“不好,前面整错了”:
SELECT customer_id, min(order_date) order_date FROM delivery;
你仔细看看,这 SQL 是想干啥?
是要从 delivery 表中获取 order_date 类的最小值和最小值对应的 customer_id 吗?
这 SQL 不应该这样写啊?
写出来的这个 SQL 是没有任何意义的呀,
因为没有 group by 语句,这个 SQL 的查询结果是返回整个表中最小的 order_date 以及任意一个 customer_id,具体是哪个这个取决于数据库系统的实现,反正这个“任意一个”是没啥具体意义的。
这也就和读者提前提出的“查询的 customer_id 数据是不准确的”呼应上了。
具体是咋不准确的呢?
看一下这个 SQL 的执行结果:
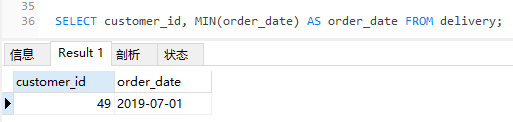
order_date 为 2019-07-01 确实是所有数据中最小的一个值,这个没问题。
然后我们拿着 “customer_id=49” 再查询一下数据:
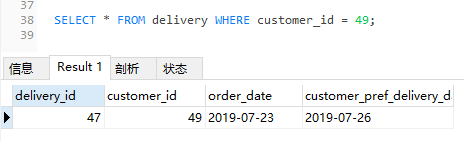
查询结果是 “order_date=2019-07-23”,和前面的 2019-07-01 呼应不起来啊。
所以我说这个查询结果中的 customer_id=49 在实际场景中几乎是没有意义的:
有意义的是什么?
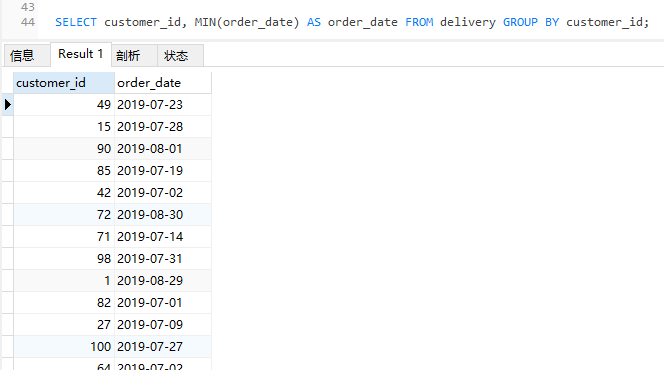
有意义的是我校招面试的时候,可能会出的一个题目。我就借用这个表来描述一下:查询表中每个用户的第一次下单的时间。
对应的 SQL 就该这样写:
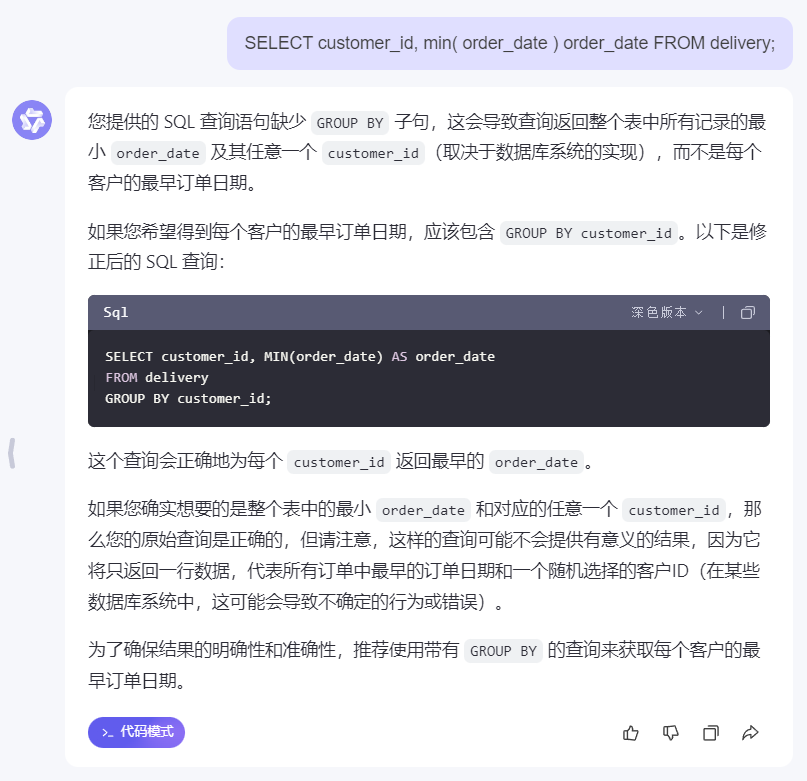
SELECT customer_id, MIN(order_date) AS order_date FROM delivery GROUP BY customer_id;
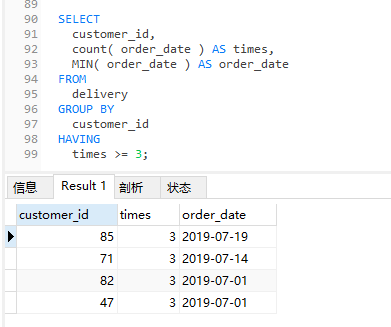
然后我一般还会继续考察一下 having 的用法,所以在同学回答正确的情况下,我会追问一下:查询表中下单次数大于等于 3 次的用户,以及每个用户的第一次下单的时间。
对应的 SQL 就会变成这样:
SELECT customer_id,count(order_date) as times,MIN(order_date) AS order_date FROM delivery GROUP BY customer_id having times>=3;
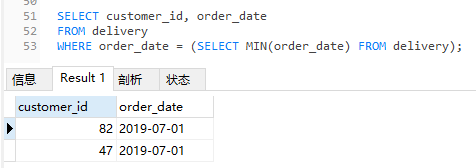
如果是要需要查询下单日期最早的用户,那也简单嘛,直接套个子查询就搞定了:
SELECT customer_id, order_date FROM delivery WHERE order_date = (SELECT MIN(order_date) FROM delivery);
回到最开始的这个 SQL:
SELECT customer_id, min(order_date) order_date FROM delivery;
聚合函数与非聚合列一起使用时要有 group by 配合使用,这是 MySQL 在语法上的规定。
如果我只是要查询表中最小的 order_date,即只有聚合列,那么也可以不配合 group by 使用,直接这样就行:
SELECT min(order_date) order_date FROM delivery;
最后,再次给这位读者道个歉,第一次的时候给你的信息确实误导了你,不好意思。
这种 SQL 我在工作中经常写啊,怎么当时就被峡谷蒙蔽了双眼呢?
哎,幸好我在十几连跪之后就卸载了,大概一个多月的时间了。
现在提起那十几连跪,我都觉得被制裁的太惨了。
队友太菜,三个人都带不动我和 Max 同学两个人,大顺风局都能被偷家,我就问你惨不惨:

哦,对了,最最后,还得提一下大模型。
比如这个场景下,我把这个 SQL 给大模型,它直接就发现了问题所在:
时代不一样了,现在我们要全面拥抱大模型,作为程序员更是要善于使用大模型,摒弃面向浏览器编程的旧思想,学会面向大模型编程新模式。
好了,本文的技术部分就到这里了。
下面这个环节叫做[荒腔走板],技术文章后面我偶尔会记录、分享点生活相关的事情,和技术毫无关系。我知道看起来很突兀,但是我喜欢,因为这是一个普通博主的生活气息。
荒腔走板

有一天晚上出去跑步的时候,换了一个白天经常跑,晚上没跑过的路线。
图片中的这一段是在高架桥下,这一段非机动车道上晚上几乎没车,白天跑的时候我觉得平平无奇,但是那天晚上跑的时候我觉得这个路线真的是太绝了,有一种难以言说的美感,冷寂的同时还有蓬勃的生命力,肃杀的氛围下还有灯光点点。
以至于我愿意停下脚步,拍几张照片。
其实大家都常常在说生活的一成不变,但是其实一成不变的不是生活,而是在生活中的人。
人要主动愿意变化,生活才会跟着变得不那么一成不变。
比如我跑步这个非常小的例子,前一段时间一直跑同一个路线,那条路线一圈 1.2km,我至少在这个路线上跑过了 500km,已经熟悉到不用看表就知道自己大概已经跑了多少距离,甚至下雨路面积水之后,知道哪些地方有水坑,水坑的深浅大概是怎样的,怎么样可以提前准备绕行一下。
熟悉当然是好处,但是也带来一丝疲惫。
所以我后面换了一个路线,这个路线也不是陌生的路线,我周末的白天会去跑,看到的都是白天的风景。
但是仅仅是换个路线这个微不足道的小动作,我就遇到了这个“难以言说的美感”,有这样的不期而遇的美好。
主动求变,当然有风险,但是也有风景。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号