角度新奇!第一次看到这样使用MyBatis的,看得我一愣一愣的。
你好呀,我是歪歪。
这期给大家分享一个读者给我分享的一个关于 MyBatis 的“编程小技巧”,说真的,这骚操作,直接把我看得一愣一愣的。
我更情愿叫它:坑你没商量之埋雷大法。

Demo
为了让你丝滑入戏,我还是先给你搞个 Demo。
因为要使用到 MyBatis 嘛,所以我们先搞两个表。
一个表叫做 product 表,表结构非常简单:

另一个表叫做 order_info 表,表结构也非常简单:

看到这两个表出现的时候,你就知道我的场景是啥了,肯定是卖货嘛。
库存减一,订单加一。
大家再熟悉不过的场景了。
分分钟能写出这样的伪代码:
public void saleProduct(){
//更新库存,库存减一
productMapper.updateProductCount();
//保存订单信息
orderInfoMapper.saveOrderInfo();
}
当然了,这个伪代码你一眼就能看出问题:减库存和保存订单应该是一个事务操作,所以应该把这两个动作包裹在事务里面。
于是我们的伪代码变成了这样:
public void saleProduct() {
//开启事务
begin;
//更新库存,库存减一
Boolean updateSuccess = productMapper.updateProductCount();
//保存订单信息
orderInfoMapper.saveOrderInfo();
if (updateSuccess) {
//提交事务
commit;
} else {
//回滚事务
rollback
}
}
当时读者给我举例的时候,完全是另外一个场景,和卖货完全没有任何关系。
读者举的例子大概是几个表之间有关联关系,如果一个表的某条数据被删除了,另外几个表里面对应的数据也要删除,还有一个表需要更新状态。
为了更好的展示这个“编程小技巧”,我才把场景简化到了前面提到的卖货的样子。
前面说的是伪代码。
现在我给你展示一下用“编程小技巧”写出来的真实的代码。
首先是 controller 接口:
@GetMapping("/sale")
public void sale() {
productMapper.selaProduct();
}
然后是这个 productMapper 的 selaProduct 接口:
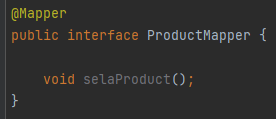
是的,你没有看错,这就是一个 MyBatis 的 mapper 接口,接下来就直接到了 mapper.xml 文件里面:
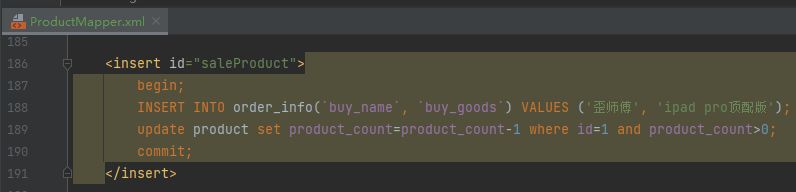
这写法,这小技巧,我都不打算问你骚不骚,我就问你见没见过?

能用吗?
歪师傅还是太年轻,见识不够,在这之前从来没见过在 mapper.xml 里面能这样去写 sql 的。
不说见过,在我的小脑袋里面,我是压根就没想过这样去写。所以看到这个写法的第一反应是:这能行吗?这不行吧?
于是,秉承着大胆假设小心求证的态度,写了上面的 Demo。
项目启动之后发起调用,控制台直接报了错:
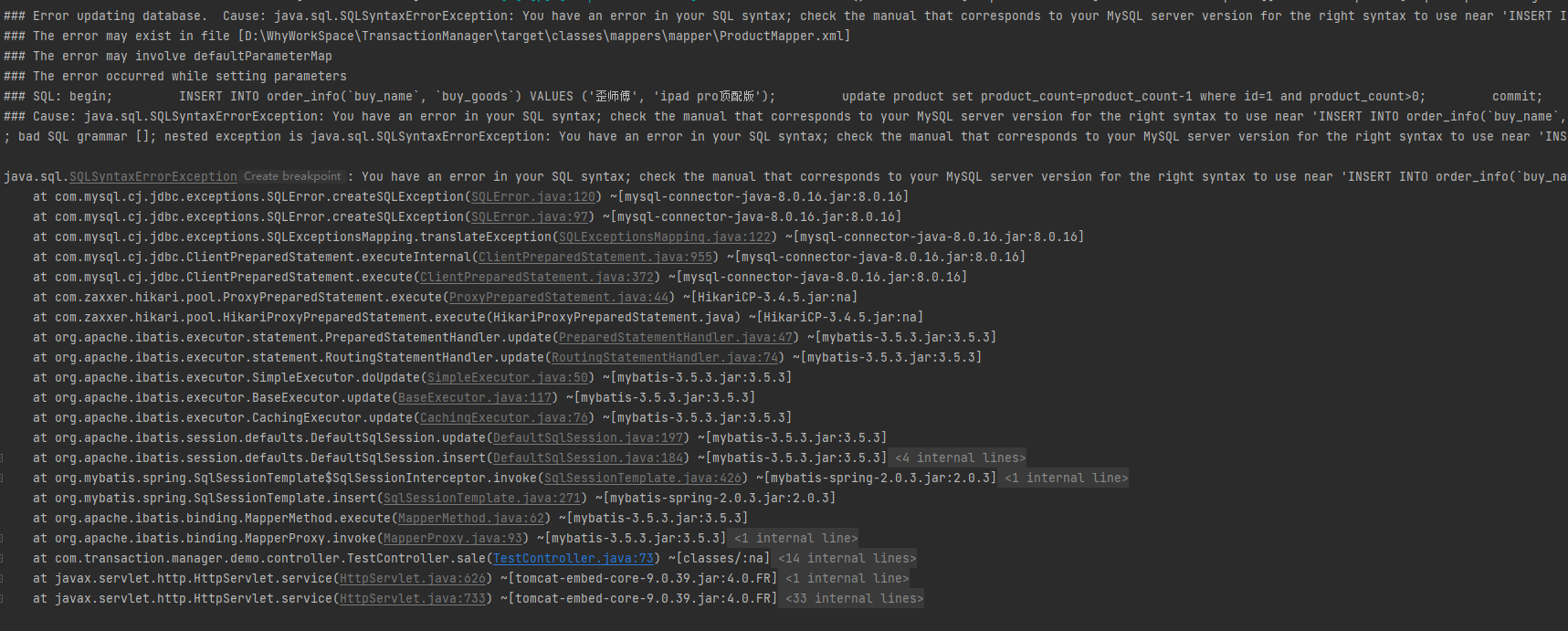
看到这个报错的时候,我下意识的觉得就是 MyBatis 不支持这样的写法,直接报错了,这也符合我之前的认知。
但是,在读者的指导下,他提醒我在数据库连接的配置上加上这样的配置:
allowMultiQueries=true
我的 Demo 启动的时候,确实没有加这个配置。但是看到这个配置的一瞬间,我开始觉得有点意思了。
因为我知道这个配置是干嘛的。
见名知意嘛:allow Multi Queries,允许进行多个查询。
最常用的场景就是用 foreach 标签来进行批量插入或者更新的时候会用到这个配置。
在这个参数的加持下,前面 mapper.xml 里面的写的那个 sql,很有可能就能正常执行了。
因为加入这个配置之后,可以在一个数据库连接中执行多个 sql 语句,而对于 MyBatis 或者 MySQL 的驱动来说,它并不区这“多个 sql”都是 insert 语句还是 update 语句,或者是混合着都有的语句。
我也去 MySQL 官网上查询了这个配置的含义:
https://dev.mysql.com/doc/connector-j/8.1/en/connector-j-connp-props-security.html#cj-conn-prop_allowMultiQueries

对于这个参数,官网上就一句话:
Allow the use of ";" to delimit multiple queries during one statement. This option does not affect the 'addBatch()' and 'executeBatch()' methods, which rely on 'rewriteBatchStatements' instead.
允许在一条语句中使用"; "分隔多个查询。该选项不会影响 "addBatch() "和 "executeBatch() "方法,因为它们依赖于 "rewriteBatchStatements"。
在介绍 allowMultiQueries 的时候,还提到了一个 rewriteBatchStatements 参数。
关于这个参数是干啥的,我这里就不展开描述了,我只能说这两个玩意是一套组合拳,里面也大有文章,如果你不知道,建议你去了解一下。
就当是课后习题了。

我们还是先跟着主干走。
当我在数据库连接上追加配置 allowMultiQueries=true 之后,重启了服务。
再次发起调用。
为了表示我的震惊,我给你搞个动图:

库存减一,订单加一,方法执行成功了。
还真 TM 能用,你说这事搞的,实属是开了眼了。

这波涨知识了,属于未曾设想过的道路。
埋雷
千万别这样写!
听歪师傅一句劝,千万别这样写!
首先这样的写法就不符合绝大部分程序员的认知。
试问谁能想到最后的 mapper.xml 里面,并不只是简简单单的 sql,里面居然还埋在一坨业务逻辑呢?

关键是这样写也埋雷啊。
举个简单的例子,这样的写法,完全没有考虑库存是否足够的情况:
比如,当前库存没有了,按照这样的写法,还是会在 order_info 表里面插入一条数据。
超卖了,朋友。
只有 commit,没有考虑回滚的情况。
而且这样写根本就完全不可能考虑超卖的情况,因为你拿不到扣减库存的操作是否执行成功,从而无法判断是需要 commit 还是 rollback。
什么,你问我能不能写存储过程来判断?
能,MyBatis 确实可以调用存储过程。
首先,存储过程还是得在 MySQL 里面写好,MyBatis 只是发起调用。
其次,赶紧打消你这个越走越远的骚想法,老老实实的写 Java 代码来解决这个问题,它不香吗?
什么,你又问我如果是不需要判断前一条 sql 是否执行成功的场景呢?
比如我前面提到的读者举的例子,几个表之间有关联关系,如果一个表的某条数据被删除了,另外几个表里面对应的数据也要删除,还有一个表需要更新状态。
大概是这样的:
begin;
delete from table1 where user_id=xxx;
delete from table2 where user_id=xxx;
delete from table3 where user_id=xxx;
update table4 set user_status=1 where user_id=xxx;
commit;
和卖货的场景不一样的是,在这个场景下如果每个 sql 执行成功,则代表业务执行成功。
看起来,似乎没什么问题。
但是我问你一个问题:这一组 SQL 一定会走都 commit 吗?
你好好想想?
肯定不一定嘛,保不齐执行的过程中出什么幺蛾子。
举个最简单的例子,表写错了:
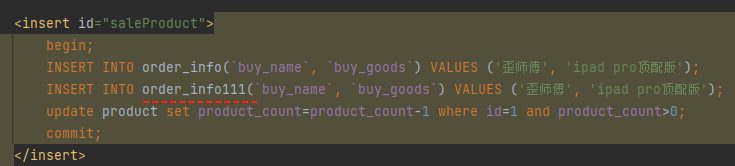
在这个场景下,再次发起调用:
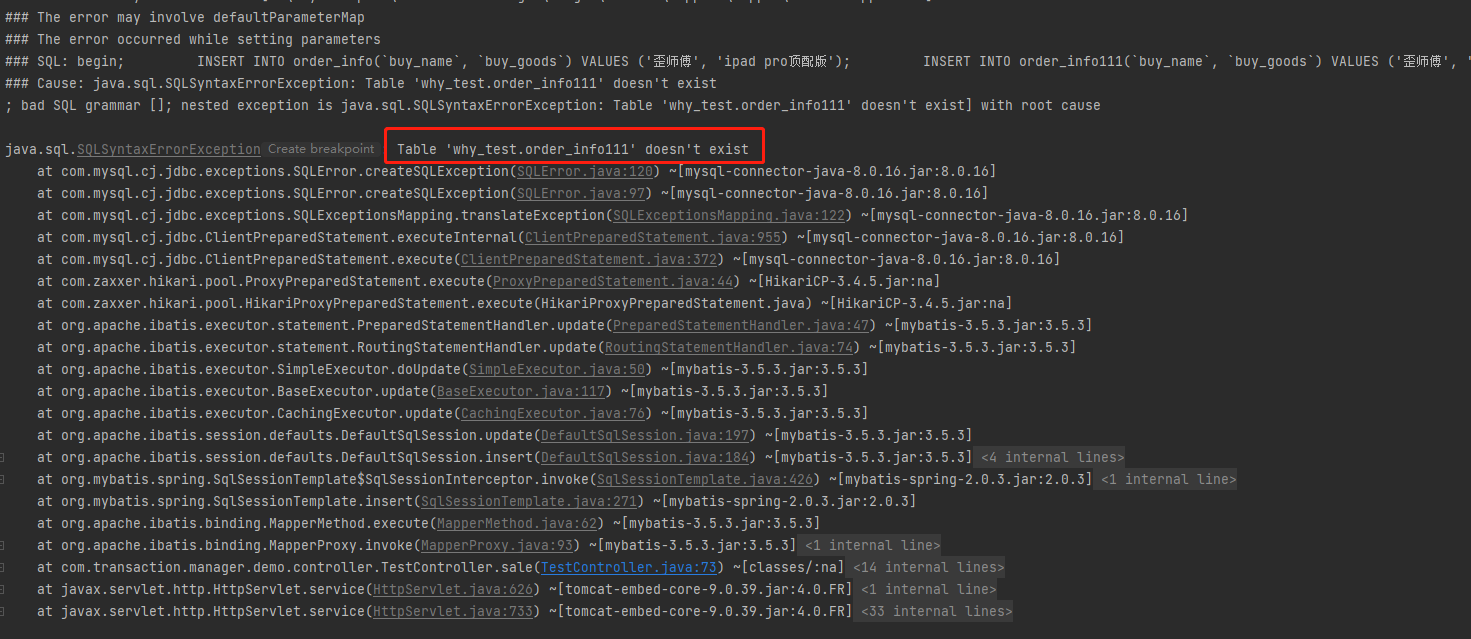
程序报错说找不到这个表。
那么请问:此时,订单表是否应该有数据被插入?
出异常了,肯定不应该有数据插入。我看了数据库,确实也没有新数据插入。
看起来确实没问题。
那么再请问:在这种写法的情况下,当前这个事务是被回滚了还是被提交了?
。。。
。。。
。。。
正确答案是被挂起了。
通过执行下面这个 SQL,我们可以获取到当前事务列表:
SELECT * FROM INFORMATION_SCHEMA.INNODB_TRX;
通过查询结果可以发现,在我们程序抛出异常之后,当前事务还在 RUNNING 状态:
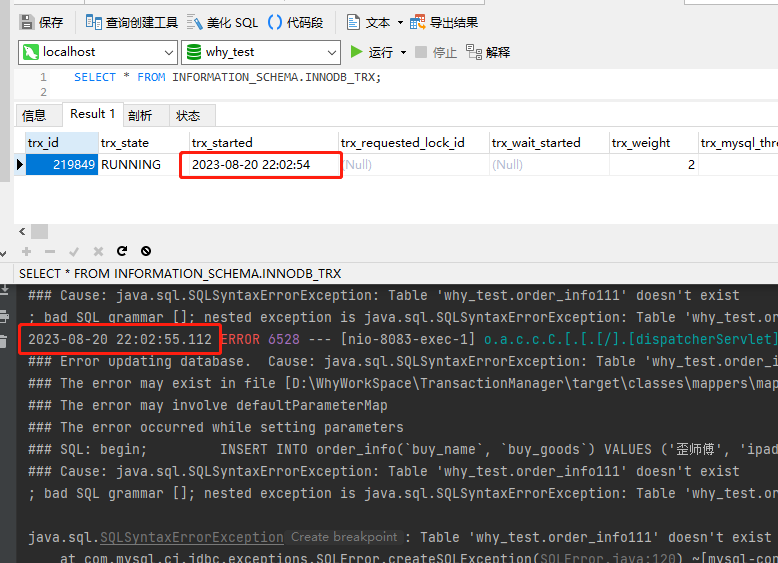
而且,这个事务在服务重启之前,将一直在 RUNNING 状态,即被挂起了。
但仅从程序的角度看,抛出异常,没有数据,符合预期,没有任何毛病。
埋雷了。
所以,听歪师傅一句劝,千万别这样写!
老老实实的写大家都看得懂的 Java 代码,不要在 mapper.xml 里面搞事情。

扩展
其实我觉得吧,前面都属于卵用不大的知识点,因为大家一般都不会这样去写。
但是既然都写到这里了,场景也有了,我也给大家扩展一个稍微有点用的知识。
还是在卖货的场景下。
订单加一,库存减一是这样的。
begin;
INSERT INTO order_info(`buy_name`, `buy_goods`) VALUES ('歪师傅', 'ipad pro顶配版');
update product set product_count=product_count-1 where id=1 and product_count>0;
commit;
而库存减一,订单加一是这样的:
begin;
update product set product_count=product_count-1 where id=1 and product_count>0;
INSERT INTO order_info(`buy_name`, `buy_goods`) VALUES ('歪师傅', 'ipad pro顶配版');
commit;
都是包裹在事务里面,为了简化代码,我们假设库存非常够用,先不考虑 rollback 的场景。
请问是“订单加一,库存减一”的性能好,还是“库存减一,订单加一”的性能好,还是说这二者没有什么区别?

首先,从执行结果上看,这二者确实是没有什么区别的,都能保证业务场景的正确性。
但是当你考虑性能的时候,肯定是“订单加一,库存减一”的性能更好。
如果你没想明白的话,我给你一个简单的提示:在业务正确的前提下,加锁的代码越靠近解锁的代码,是不是性能越好?
如果你还没想明白的话,我再给你一个提示:库存减一,它会加锁吗?你不管它是加表锁、间隙锁还是记录锁,我就问你它加不加锁?
如果你还没反应过来的话,说明你对于 MySQL 的加锁机制掌握的有点薄弱,可以去加固一下。
我直接公布答案了:
update product set product_count=product_count-1 where id=1 and product_count>0;
因为 where 条件中是 id=1,所以锁是加在唯一索引上的,而且表中存在该记录,所以只会对 id=1 这行记录加锁。
针对 id=1 这一个产品来说,如果它是一个热点商品,我们采取“订单加一,库存减一”的写法,性能会更高一点。
因为在加锁频率相同的情况下,解锁越快的,性能越高。
上个图你就明白了:
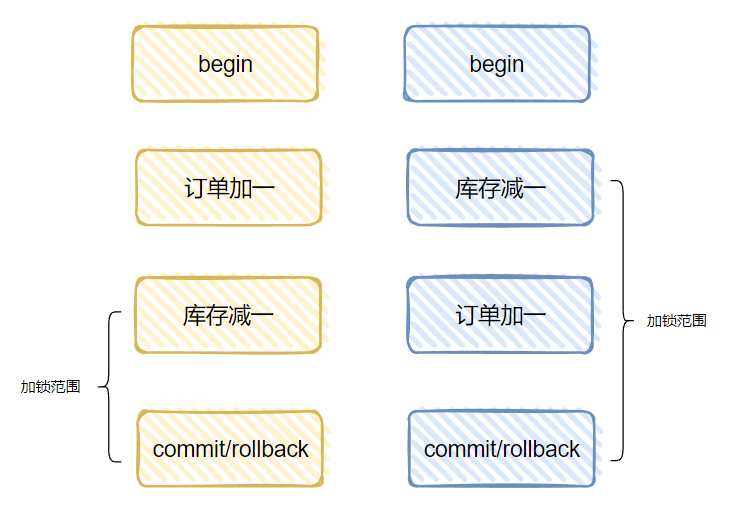
调换一个 SQL 的事儿,性能就上去了,我就问你舒不舒服?
最后,再说个不相关的:
我在文章最开始的地方给了这样的一个图片:
你不觉得别扭吗?
sela 是什么鬼?
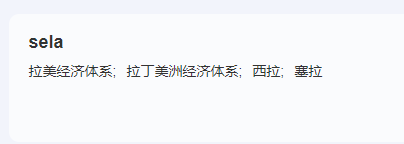
很明显,这个地方是一个单纯的拼写错误,想要打出的单词是 sale:

请问,当你在程序里面看到这样的拼写的时候,你会怎么办?
如果是我,我会主动把 selaProduct 修改为 saleProduct,其他什么都不会动。
这就是我在之前的文章中提到的一个编码规则,童子军军规:

修改一个拼写错误的方法名、变量名,在代码里面也是一件很重要的小事。
这不是代码洁癖,这是基本的职业道德。
因为你也不想下一个接手你代码的人,因为看到一堆叫做“succeess、createTiem、lastUpdataBy、bussinessDate、proudectName”等等这些变量名而血压上升,气大伤身。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号