可以,很强,68行代码实现Bean的异步初始化,粘过去就能用。
你好呀,我是歪歪。
前两天在看 SOFABoot 的时候,看到一个让我眼前一亮的东西,来给大家盘一下。
SOFABoot,你可能不眼熟,但是没关系,本文也不是给你讲这个东西的,你就认为它是 SpringBoot 的变种就行了。
因为有蚂蚁金服背书,所以主要是一些金融类的公司在使用这个框架:

官方介绍是这样的:
SOFABoot 是蚂蚁金服开源的基于 Spring Boot 的研发框架,它在 Spring Boot 的基础上,提供了诸如 Readiness Check,类隔离,日志空间隔离等能力。在增强了 Spring Boot 的同时,SOFABoot 提供了让用户可以在 Spring Boot 中非常方便地使用 SOFA 中间件的能力。
上面这些功能都很强大,但是我主要是分享一下它的这个小功能:
https://help.aliyun.com/document_detail/133162.html
这个功能可以让 Bean 的初始化方法在异步线程里面执行,从而加快 Spring 上下文加载过程,提高应用启动速度。
为什么看到功能的时候,我眼前一亮呢,因为我很久之前写过这篇文章《我是真没想到,这个面试题居然从11年前就开始讨论了,而官方今年才表态。》
里面提到的面试题是这样的:
Spring 在启动期间会做类扫描,以单例模式放入 ioc。但是 spring 只是一个个类进行处理,如果为了加速,我们取消 spring 自带的类扫描功能,用写代码的多线程方式并行进行处理,这种方案可行吗?为什么?
当时通过 issue 找到了官方对于这个问题回复总结起来就是:应该是先找到启动慢的根本原因,而不是把问题甩锅给 Spring。这部分对于 Spring 来说,能不动,就别动。

仅从“启动加速-异步初始化方法”这个标题上来看,Spring 官方不支持的东西 SOFABoot 支持了。所以这玩意让我眼前一亮,我倒要看看你是怎么搞得。
先说结论:SOFABoot 的方案能从一定程度上解决问题,但是它依赖于我们编码的时候指定哪些 Bean 是可以异步初始化的,这样带来的好处是不必考虑循环依赖、依赖注入等等各种复杂的情况了,坏处就是需要程序员自己去识别哪些类是可以异步初始化的。
我倒是觉得,程序员本来就应该具备“识别自己的项目中哪些类是可以异步初始化”的能力。
但是,一旦要求程序员来主动去识别了,就已经“输了”,已经不够惊艳了,在实现难度上就不是一个级别的事情了。人家 Spring 想的可是框架给你全部搞定,顶多给你留一个开关,你开箱即用,啥都不用管。
但是总的来说,作为一次思路演变为源码的学习案例来说,还是很不错的。

我们主要是看实现方案和具体逻辑代码,以 SOFABoot 为抓手,针对其“异步初始化方法”聚焦下钻,把源码当做纽带,协同 Spring,打出一套“我看到了->我会用了->我拿过来->我看懂了->是我的了->写进简历”的组合拳。

Demo
先搞个 Demo 出来,演示一波效果,先让你直观的看到这是个啥玩意。
这个 Demo 非常之简单,几行代码就搞定。
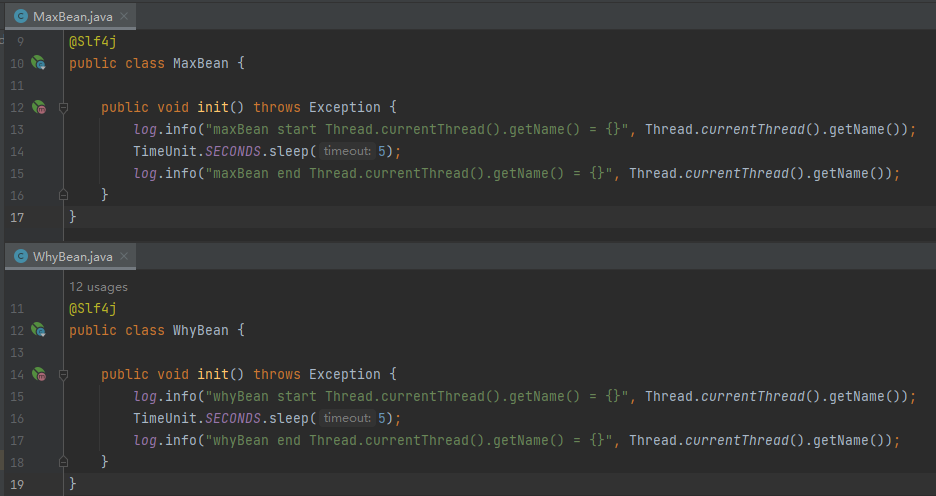
先搞两个 java 类,里面有一个 init 方法:
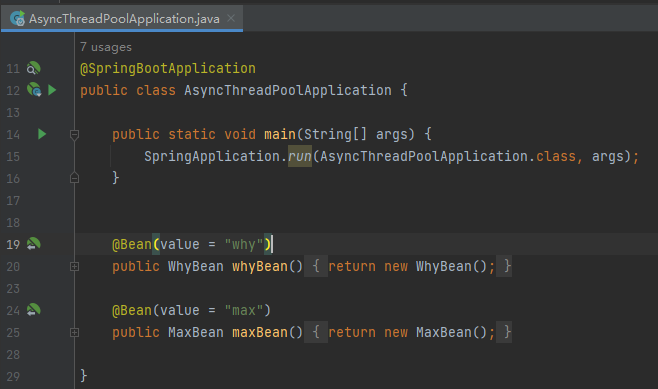
然后把他们作为 Bean 交给 Spring 管理,Demo 就搭建好了:
直接启动项目,启动时间只需要 1.152s,非常丝滑:

然后,注意,我要稍微的变一下形。
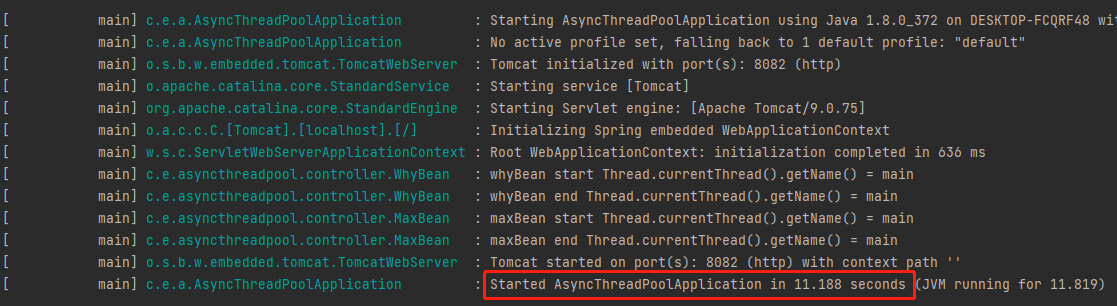
在注入 Bean 的时候触发一下初始化方法,模拟实际项目中在 Bean 的初始化阶段,既在 Spring 项目启动过程中,做一些数据准备、配置拉取等相关操作:

再次重启一下项目,因为需要执行两个 Bean 的初始化动作,各需要 5s 时间,而且是串行执行,所以启动时间直接来到了 11.188s:
那么接下来,就是见证奇迹的时刻了。
我加上 @SofaAsyncInit 这样的一个注解:
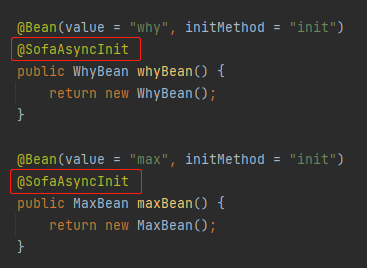
你先别管这个注解是哪里来的,从这个注解的名称你也知道它是干啥的:异步执行初始化。
这个时候我再启动项目:
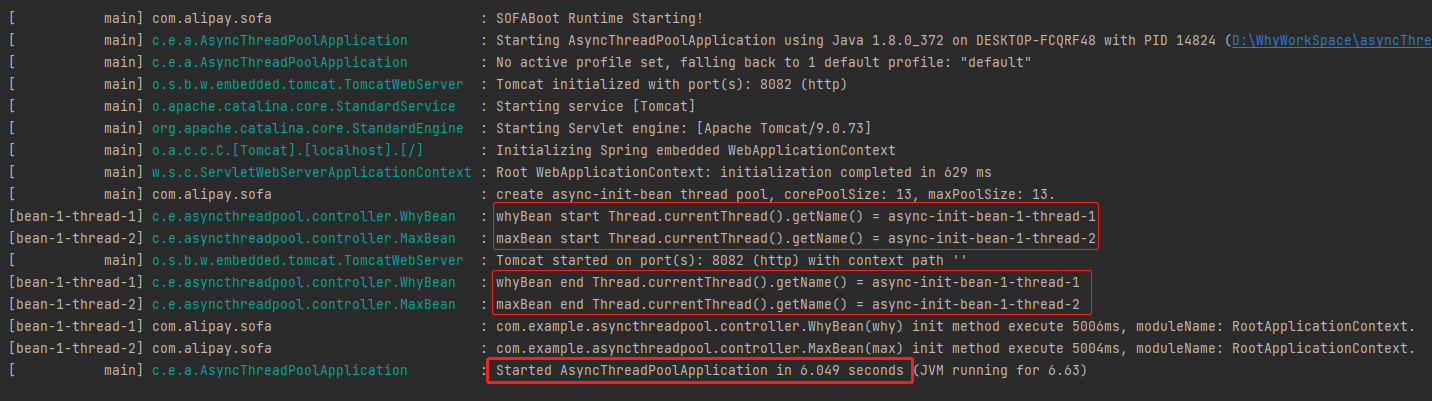
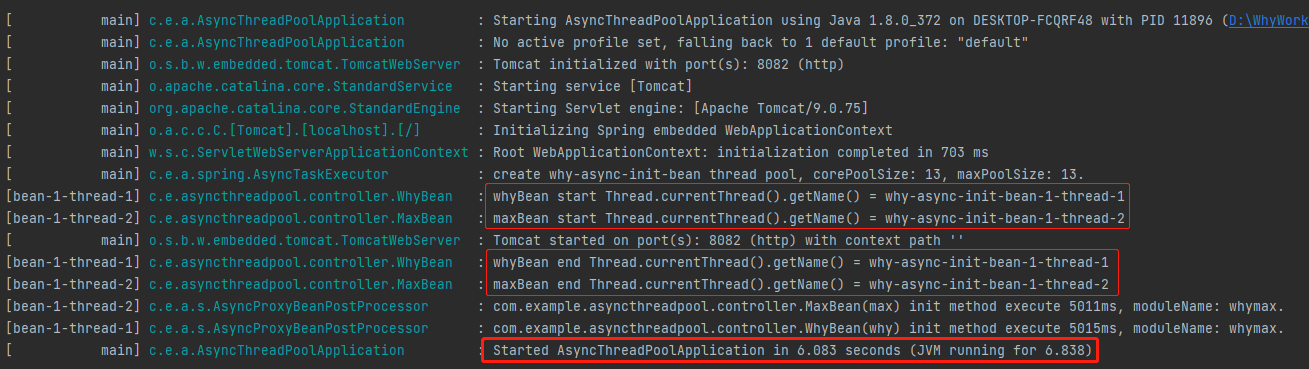
从日志中可以看到:
whyBean 和 maxBean 的 init 方法是由两个不同的线程并行执行的。 启动时间缩短到了 6.049s。
所以 @SofaAsyncInit 这个注解实现了“指定 Bean 的初始化方法实现异步化”。
你想想,如果你有 10 个 Bean,每个 Bean 都需要 1s 的时间做初始化,总计 10s。
但是这些 Bean 之间其实不需要串行初始化,那么用这个注解,并行只需要 1s,搞定。
到这里,你算是看到了这样的东西存在,属于“我看到了”。
接下来,我们进入到“我会用了”这个环节。

怎么来的。
在解读原理之前,我还得告诉你这个注解到底是怎么来的。
它属于 SOFABoot 框架里面的注解,首先你得把你的 SpringBoot 修改为 SOFABoot。
这一步参照官方文档中的“快速开始”部分,非常的简单:
https://www.sofastack.tech/projects/sofa-boot/quick-start/
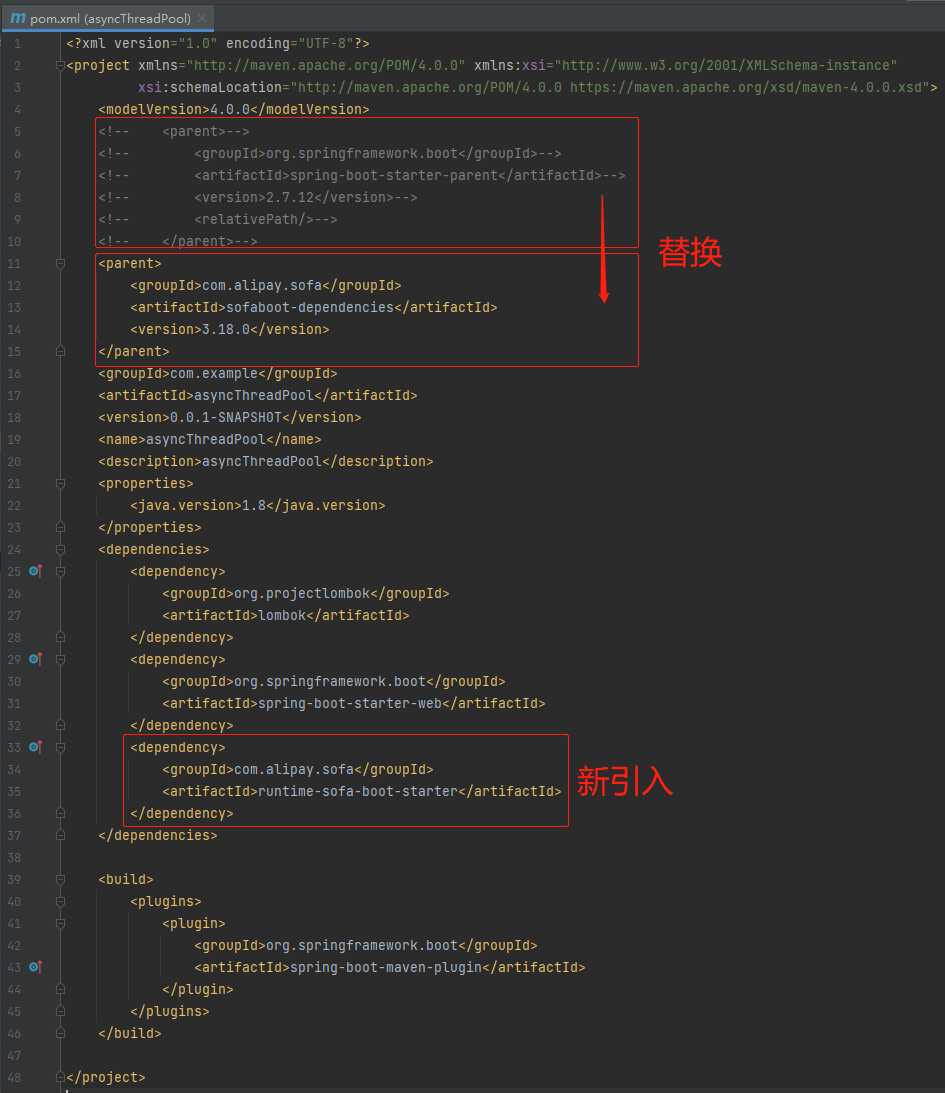
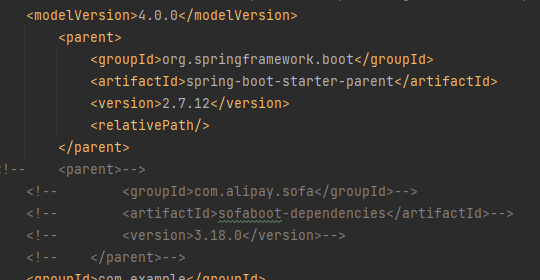
第一步就是把项目中 pom.xml 中的:
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>${spring.boot.version}</version>
<relativePath/>
</parent>
替换为:
<parent>
<groupId>com.alipay.sofa</groupId>
<artifactId>sofaboot-dependencies</artifactId>
<version>${sofa.boot.version}</version>
</parent>
这里的 ${sofa.boot.version} 指定具体的 SOFABoot 版本,我这里使用的是最新的 3.18.0 版本。
然后我们要使用 @SofaAsyncInit 注解,所以需要引入以下 maven:
<dependency>
<groupId>com.alipay.sofa</groupId>
<artifactId>runtime-sofa-boot-starter</artifactId>
</dependency>
对于 pom.xml 文件的变化,就只有这么一点:
最后,在工程的 application.properties 文件下添加 SOFABoot 工程一个必须的参数配置,spring.application.name,用于标示当前应用的名称
# Application Name
spring.application.name=SOFABoot Demo
就搞定了,我就完成了一个从 SpringBoot 切换为 SOFABoot 这个大动作。
当然了,我这个是一个 Demo 项目,结构和 pom 依赖都非常简单,所以切换起来也非常容易。如果你的项目比较大的话,可能会遇到一些兼容性的问题。
但是,注意我要说但是了。
你是在学习摸索阶段,Demo 一定要简单,越小越好,越纯净越好。所以这个切换的动作对你搭建的一个全新的 Demo 项目来说没啥难度,不会遇到任何问题。
这个时候,你就可以使用 @SofaAsyncInit 注解了:
到这里,恭喜你,会用了。
拿来吧你
不知道你看到这里是什么感受。
反正对于我来说,如果仅仅是为了让我能使用这个注解,达到异步初始化的目的,要让我从熟悉的 SpringBoot 修改为听都没听过的 SOFABoot,即使这个框架背后有阿里给它背书,我肯定也是不会这么干的。
所以,对于这一类“人有我无”的东西,我都是采取“拿来吧你”策略。

你想,最开始的我就说了,SOFABoot 是 SpringBoot 的变种,它的底层还是 SpringBoot。
而 SOFABoot 又是开源的,整个项目的源码我都有了:
https://github.com/sofastack/sofa-boot/blob/master/README_ZH.md
从其中剥离出一个基于 SpringBoot 做的小功能,融入到我自己的 SpringBoot 项目中,还玩意难道不是手到擒来的事情?
不过就是稍微高级一点的 cv 罢了。
首先,你得把 SOFABoot 的源码下载下来,或者在另外的一个项目中引用它,把自己的项目恢复为一个 SpringBoot 项目。
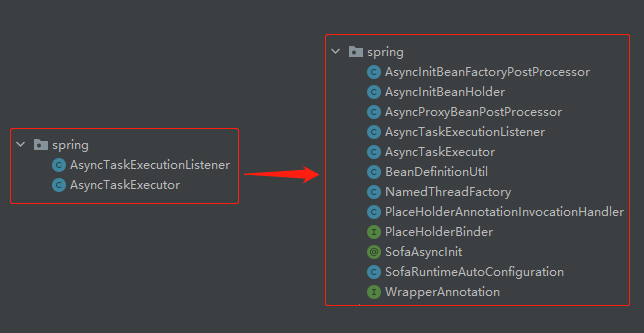
我这边是直接把 SOFABoot 源码搞下来了,先把源码里面的 @SofaAsyncInit 注解粘到项目里面来,然后从 @SofaAsyncInit 注解入手,发现除了测试类只有一个 AsyncInitBeanFactoryPostProcessor 类在对其进行使用:
所以把这个类也搬运过来。
搬运过来之后你会发现有一些类找不到导致报错:
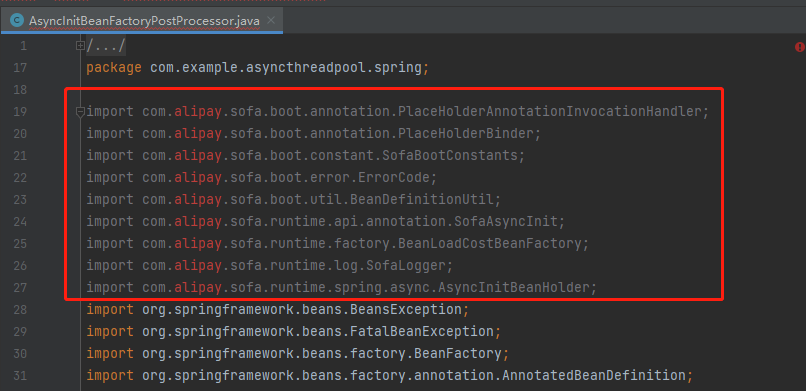
针对这部分类,你可以采取无脑搬运的方式,也可以稍加思考替换一些。
比如我就分为了两种类型:
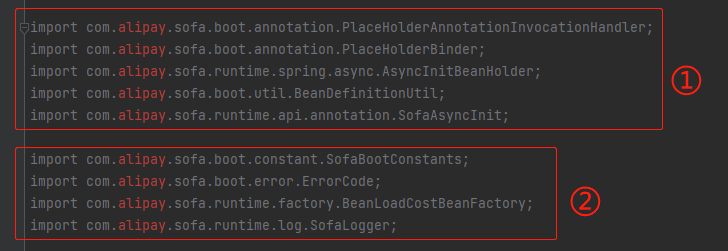
标号为 ① 的部分,我是直接粘贴到自己的项目中,然后使用项目中的类。
标号为 ② 的部分,比如 BeanLoadCostBeanFactory 和 SofaBootConstants,他们的目的是为了获取一个 moduleName 变量:
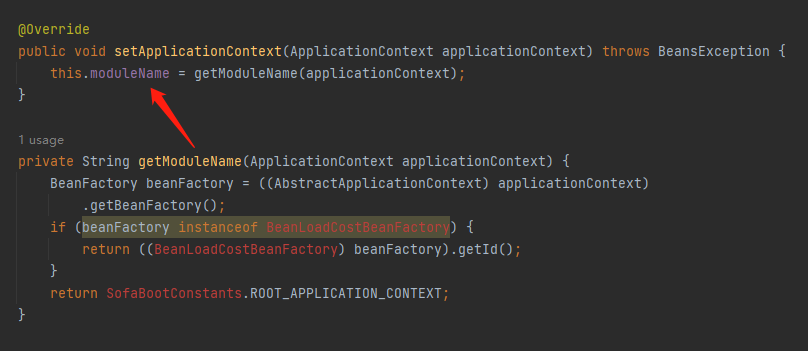
我也不知道这个 moduleName 是啥,所以我采取的策略是自己指定一个:

至于 ErrorCode 和 SofaLogger,日志相关的,就用自己项目里面的日志就行了。
就是这个意思:
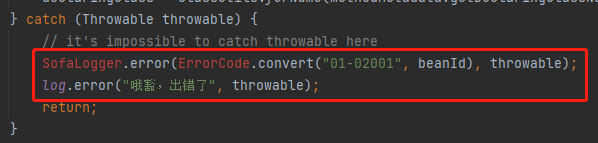
这样处理完成之后,AsyncInitBeanFactoryPostProcessor 类不报错了,接着看这个类在哪里使用到了。
就这样顺藤摸瓜,最后搬运完成之后,就是这些类移过来了:
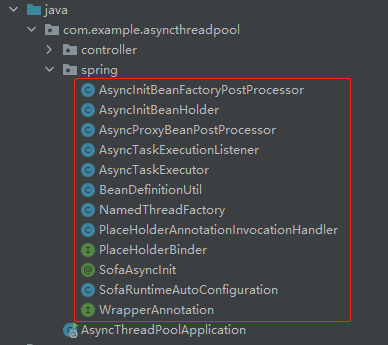
除了这些类之外,你还会把这个 spring.factories 搬运过来,在项目启动时把这几个相关的类加载进去:
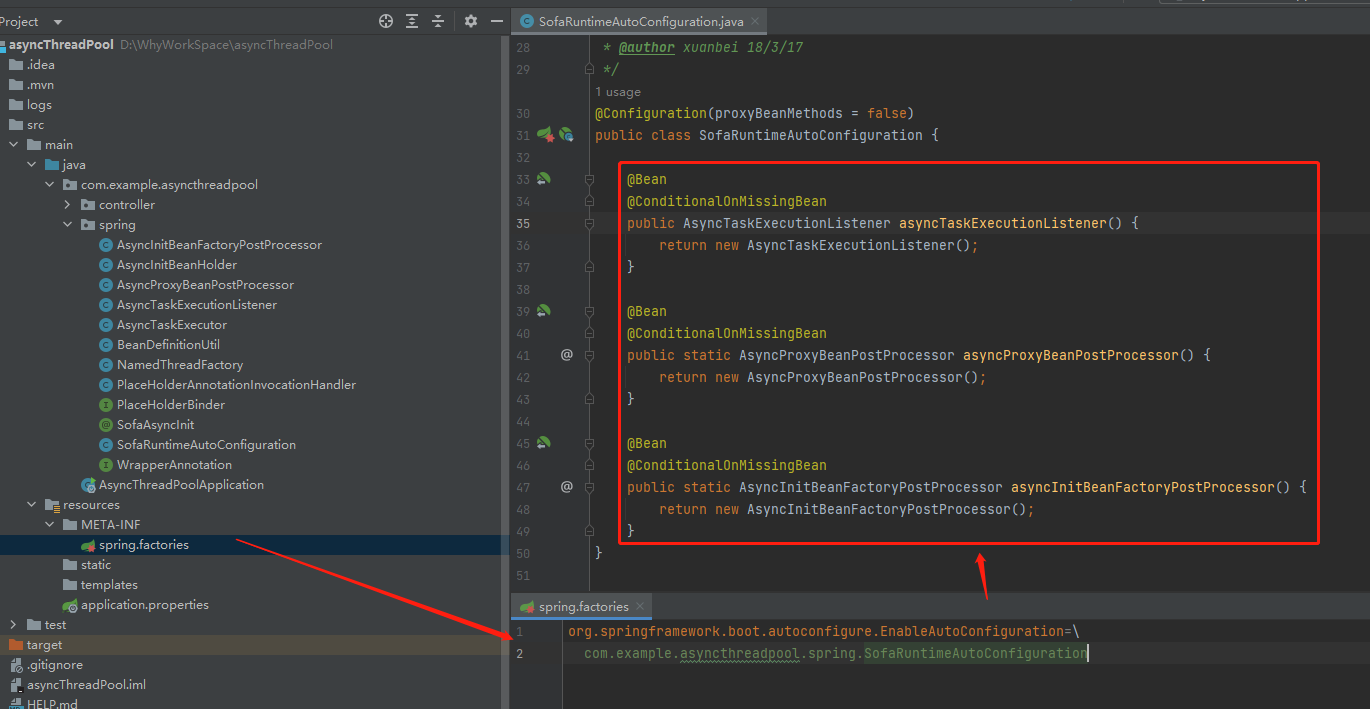
然后再次启动这个和 SOFABoot 没有一点关系的项目:
你会发现,你的项目也具备异步初始化 Bean 的功能了。
你要再进一步,把它直接封装为一个 spring-boot-starter-asyncinitbean,发布到你们公司的私服里面。
其他团队也能开箱即用的使用这个功能了。
别问,问就是你自己独立开发出来的,掌握全部源码,技术风险可控:

啃原理
在开始啃原理之前,我先多比比两句。
我写文章的时候,为什么要把“拿来吧你”这一小节放在“啃原理”之前,我是有考虑的。
当我们把“异步初始化”这个功能点剥离出来之后,你会发现,要实现这个功能,一共也没涉及到几个类。
聚焦点从一整个项目变成了几个类而已,至少从感官上不会觉得那么的难,对阅读其源码产生太大的抗拒心理。
而我之前很多关于源码阅读的文章,都强调过这一点:带着疑问去调试源码,要抓住主干,谨防走偏。
前面这一小节,不过是把这一句话具化了而已。即使没有把这些类剥离出来,你直接基于 SOFABoot 来调试这个功能。在你搞清楚“异步初始化”这个功能的实现原理之前,理论上你的关注点和注意力不应该被上面这些类之外的任何一个类给吸引走。

接下来,我们就带你啃一下原理。
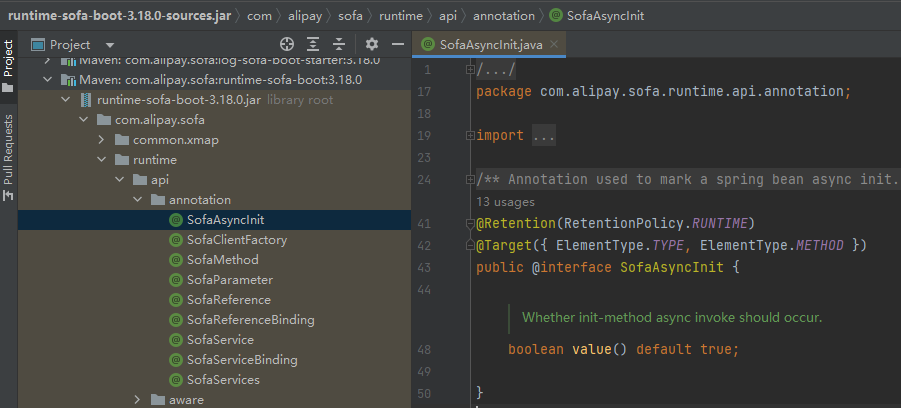
关于原理部分,我们的突破口肯定是看 @SofaAsyncInit 这个注解的在哪个地方被解析的。
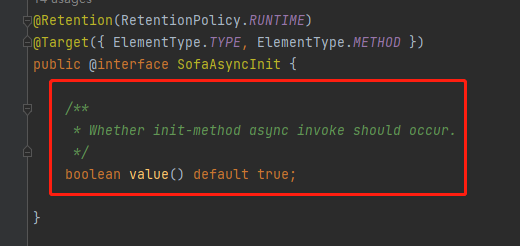
你仔细看这个注解里面有一个 value 属性,默认为 true,上面的注解说:用来标注是否应该对 init 方法进行异步调用。
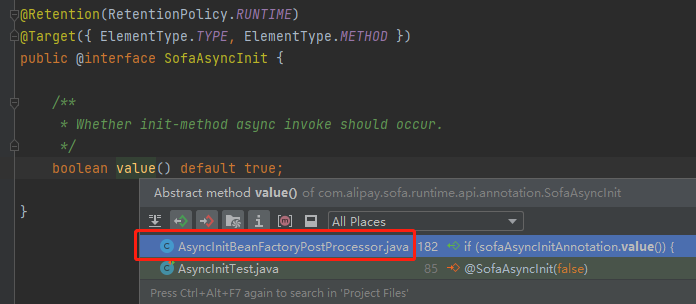
而使用到这个 value 值的地方,就只有下面这一个地方:
com.alipay.sofa.runtime.spring.AsyncInitBeanFactoryPostProcessor#registerAsyncInitBean
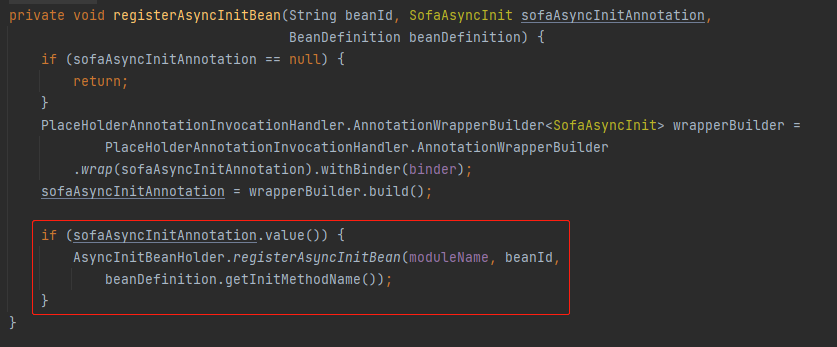
判断为 true 的时候,执行了一个 registerAsyncInitBean 方法。
从方法名称也知道,它是把可以异步执行的 init 方法的 Bean 收集起来。
所以看源码可以看出,这里面是用 Map 来进行的存储,提供了一个 register 和 get 方法:
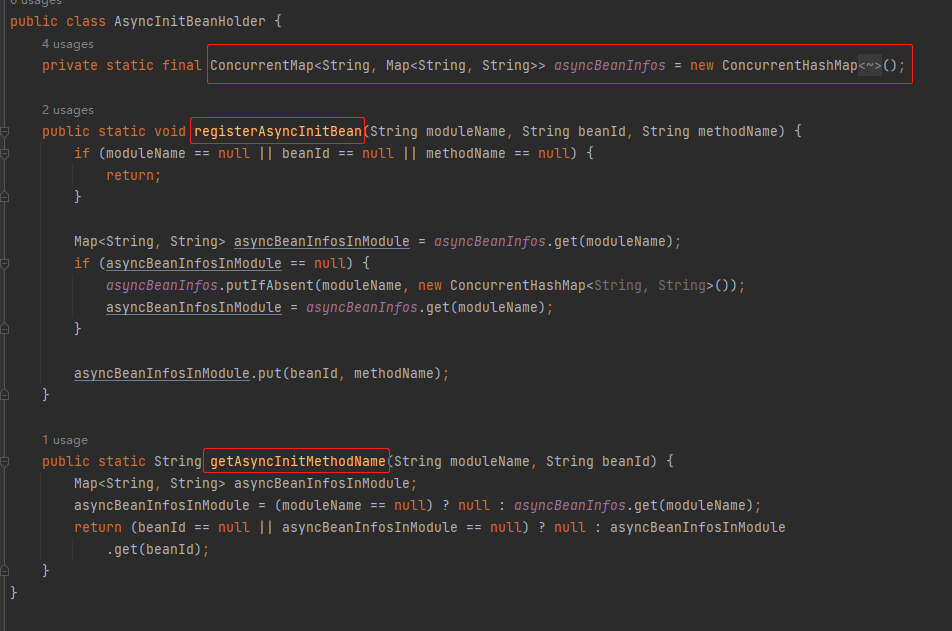
那么这个 Map 里面到底放的是啥呢?
我也不知道,打个断点瞅一眼,不就行了:
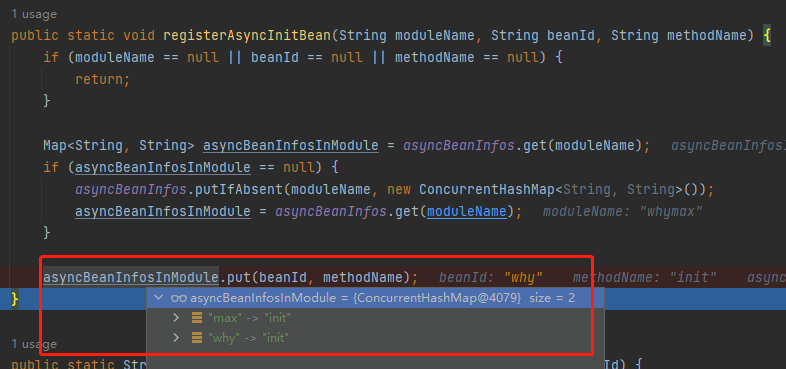
通过断点调试,我们知道这个里面把项目中哪些 Bean 可以异步执行 init 方法通过 Map 存放了起来。
那么问题就来了:它怎么知道哪些 Bean 可以异步执行 init 呢?
很简单啊,因为我在对应的 Bean 上打上了 @SofaAsyncInit 注解。所以可以通过扫描注解的方式找到这些 Bean。
所以你说 AsyncInitBeanFactoryPostProcessor 这个类是在干啥?
肯定核心逻辑就是在解析标注了 @SofaAsyncInit 注解的地方嘛。
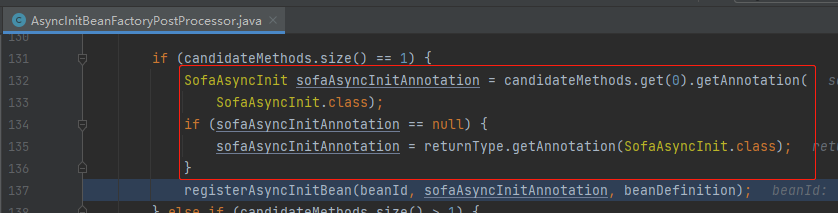
到这里,我们通过注解的 value 属性,找到了 AsyncInitBeanHolder 这个关键类。
知道了这个类里面有一个 Map,里面维护的是所有可以异步执行 init 方法的 Bean 和其对应的 init 方法。
好,你思考一下,接下来应该干啥?
接下来肯定是看哪个地方在从这个 Map 里面获取数据出来,获取数据的时候,就说明是要异步执行这个 Bean 的 init 方法的时候。
不然它把数据放到 Map 里面干啥?玩吗?
调用 getAsyncInitMethodName 方法的地方,也在 AsyncProxyBeanPostProcessor 类里面:
com.alipay.sofa.runtime.spring.AsyncProxyBeanPostProcessor#postProcessBeforeInitialization
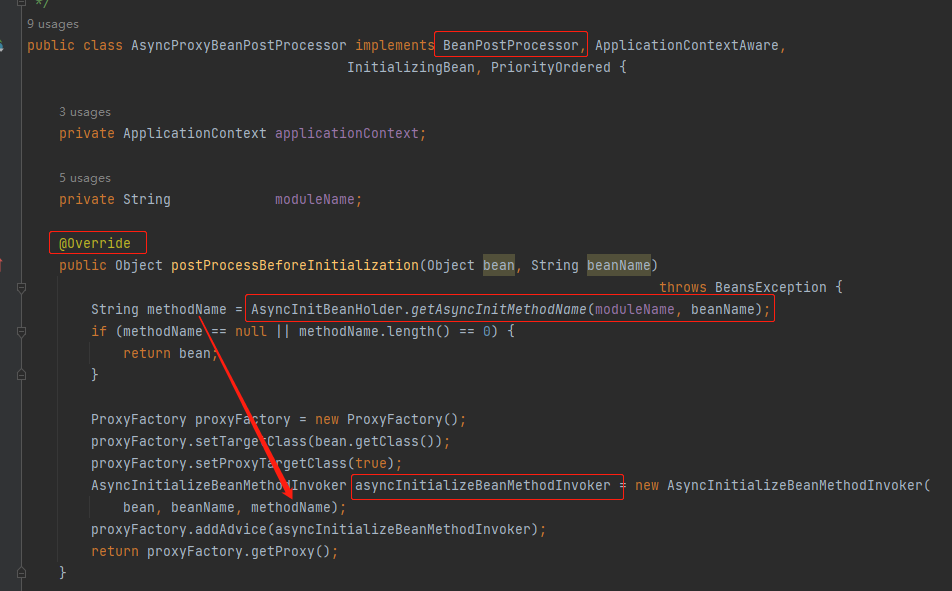
AsyncProxyBeanPostProcessor 类实现了 BeanPostProcessor 接口,并重新了其 postProcessBeforeInitialization 方法。
在这个 postProcessBeforeInitialization 方法里面,执行了从 Map 里面拿对象的动作。
如果获取到了则通过 AOP 编程,编织进一个 AsyncInitializeBeanMethodInvoker 方法。
把 bean, beanName, methodName 都传递了进去:
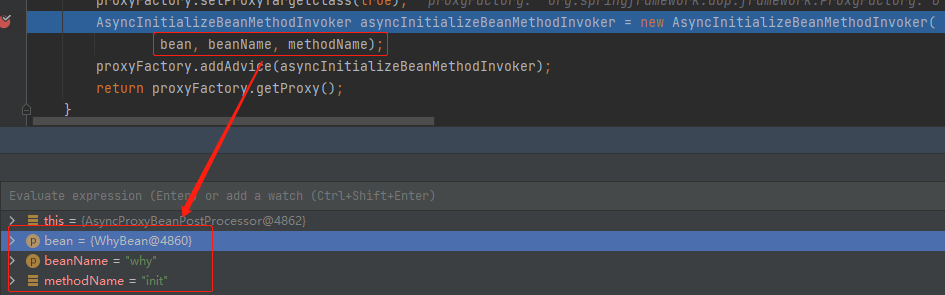
所以关键点,就在 AsyncInitializeBeanMethodInvoker 里面,因为这个里面有真正判断是否要进行异步初始化的逻辑,主要解读一下这个类。
首先,关注一下它的这三个参数:
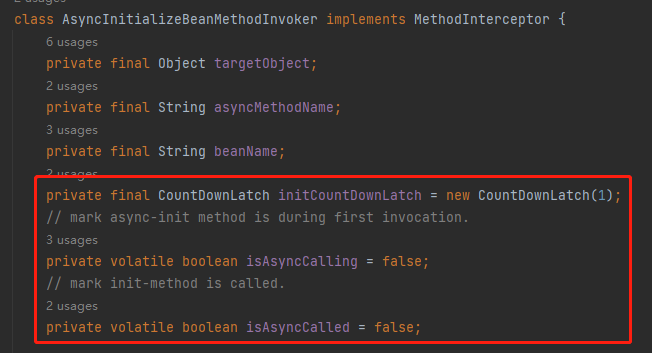
initCountDownLatch:是 CountDownLatch 对象,其中 count 初始化为 1 isAsyncCalling:表示是否正在异步执行 init 方法。 isAsyncCalled:表示是否已经异步执行过 init 方法。
通过这三个字段,就可以感知到一个 Bean 是否已经或者正在异步执行其 init 方法。
这个类的核心逻辑就是把可以异步执行、但是还没有执行 init 方法的 bean ,把它的 init 方法扔到线程池里面去执行:
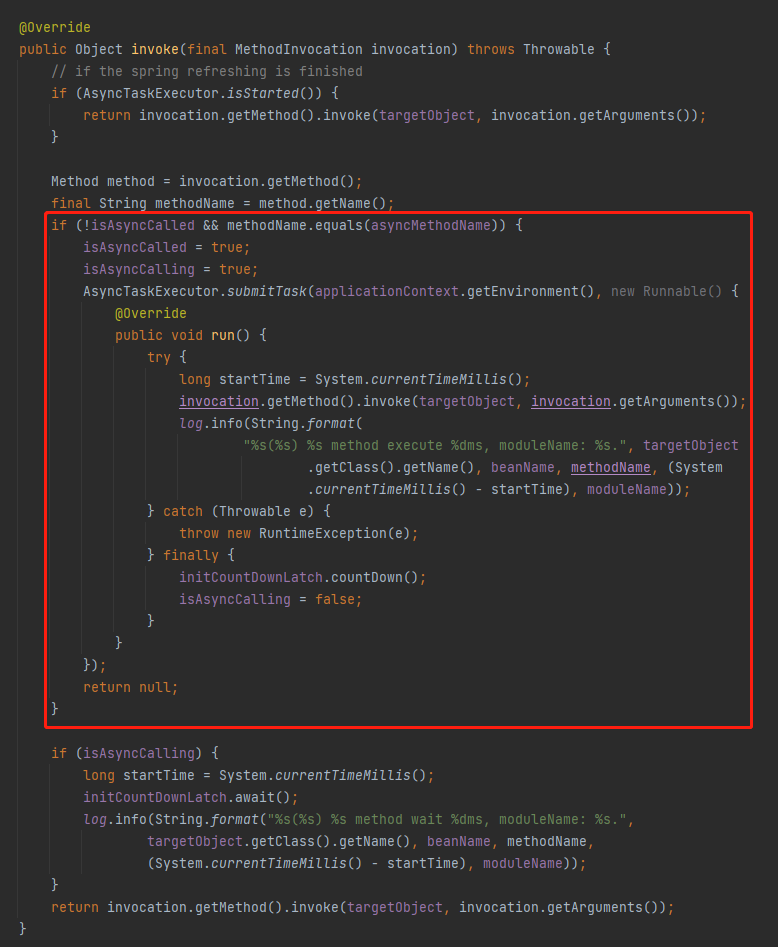
看一下在上面的 invoke 方法中的 if 方法:
if (!isAsyncCalled && methodName.equals(asyncMethodName))
isAsyncCalled,首先判断是否已经异步执行过这个 bean 的 init 方法了。
然后看看 methodName.equals(asyncMethodName),要反射调用的方法是否是之前在 map 中维护的 init 方法。
如果都满足,就扔到线程池里面去执行,这样就算是完成了异步 init。
如果不满足呢?
首先,你想想不满足的时候说明什么情况?
是不是说明一个 Bean 的 init 方法在项目启动过程中不只被调用一次。
就像是这样:
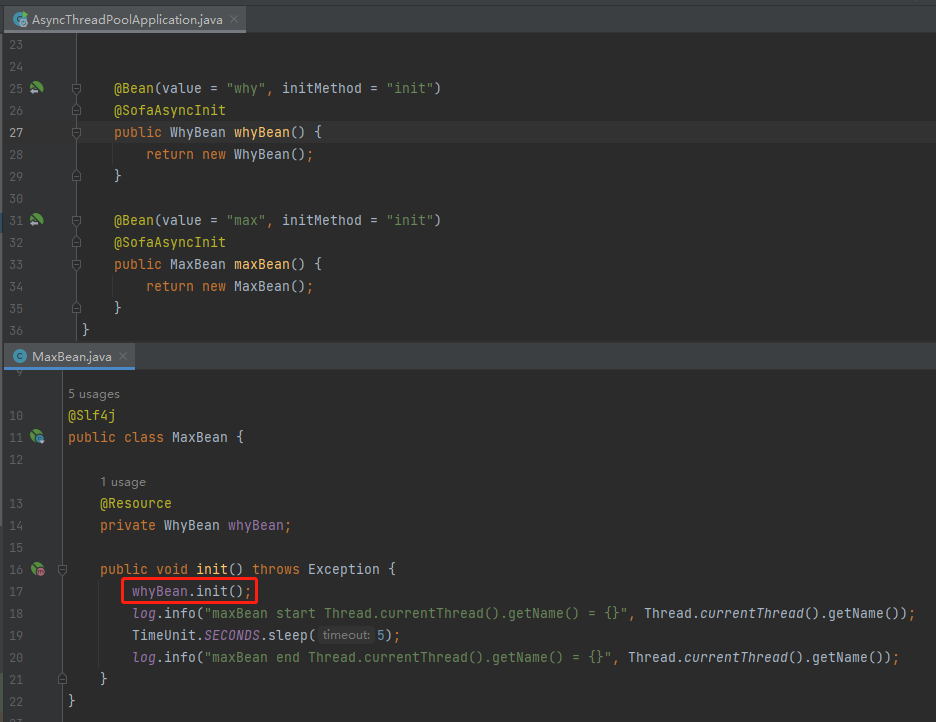
虽然,我不知道为什么一个 Bean 要执行两次 init 方法,大概率是代码写的有问题。
但是我不说,我也不给你抛出异常,我反正就是给你兼容了。
所以,这段代码就是在处理这个情况:
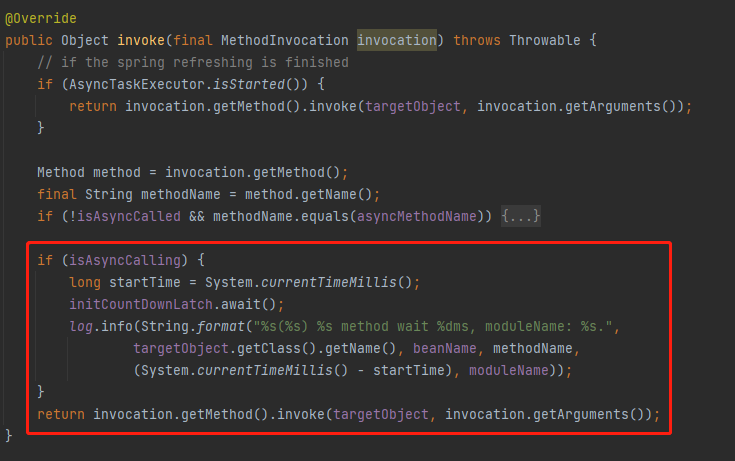
如果发现有多次调用,那么只要第一次异步初始化完成了,即 isAsyncCalling 为 false ,你可以继续执行反射调用初始化方法的动作。
这个 invoke 方法的逻辑就是这样,主要是有一个线程池在里面。
那么这个线程池是哪里来的呢?
com.alipay.sofa.runtime.spring.async.AsyncTaskExecutor
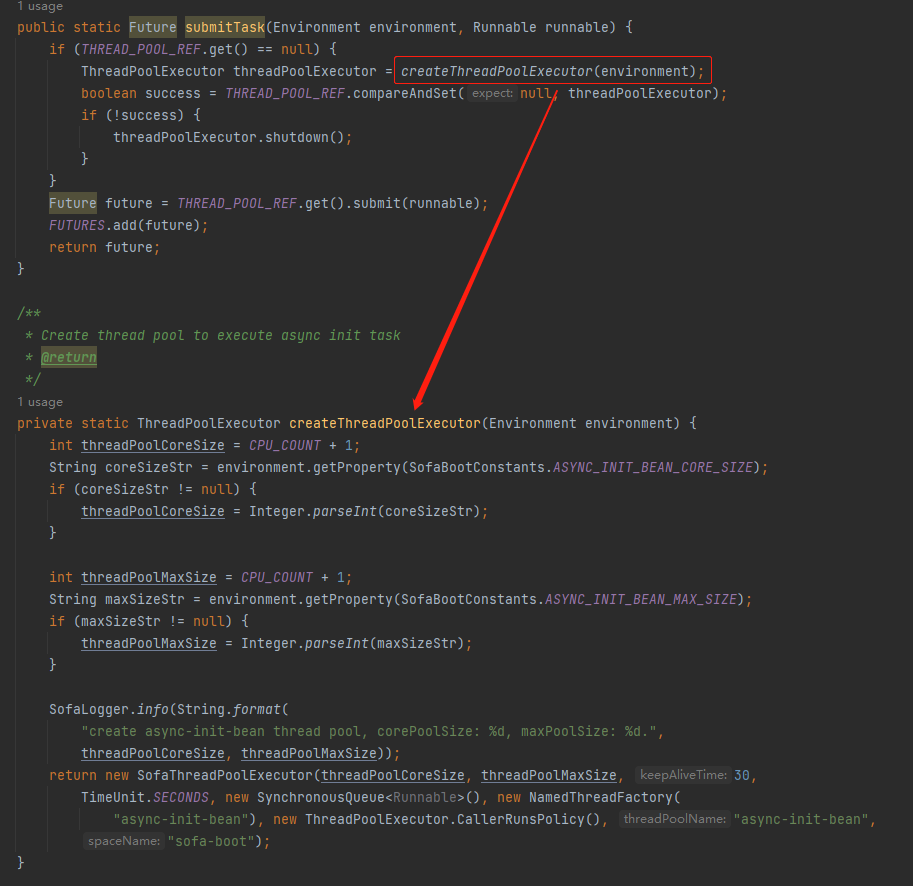
在第一次 submit 任务的时候,框架会帮我们初始化一个线程池出来。
然后通过这个线程池帮我们完成异步初始化的目标。
所以你想想,整个过程是非常清晰的。首先找出来哪些 Bean 上标注了 @SofaAsyncInit 注解,找个 Map 维护起来,接着搞个 AOP 切面,看看哪些 Bean 能在 Map 里面找到,在线程池里面通过动态代理,调用其 init 方法。
就完了。
对不对?
好,那么问题就来了?
为什么我不直接在 init 方法里面搞个线程池呢,就像是这样。
先注入一个自定义线程池,同时注释掉 @SofaAsyncInit 注解:
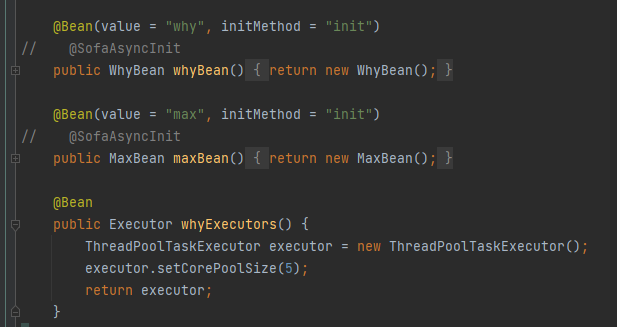
在指定 Bean 的 init 方法中使用该线程池:
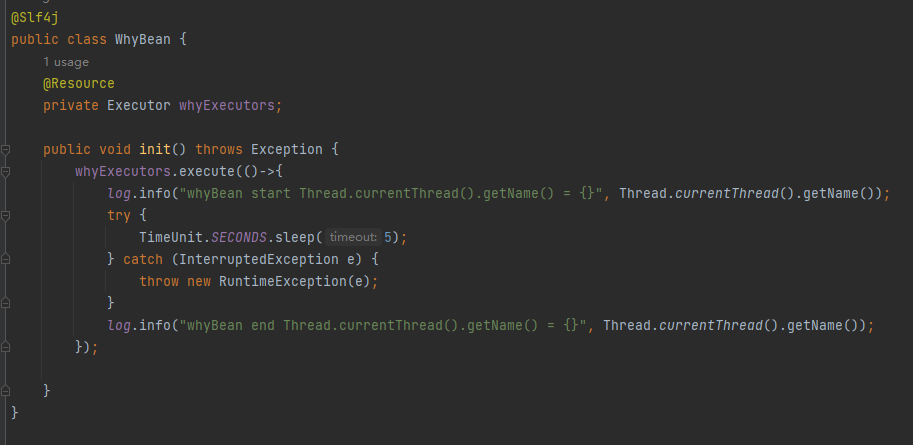
这也不也是能达到“异步初始化”的目的吗?
你说对不对?

不对啊,对个锤子对。
你看启动日志:

服务已经启动完成了,但是 4s 之后,Bean 的 init 方法才执行完毕。
在这期间,如果有请求要使用对应的 Bean 怎么办?
拿着一个还未执行完成 init 方法的 Bean 框框一顿用,这画面想想就很美。
所以怎么办?
我也不知道,看一下 SOFABoot 里面是怎么解决这个问题的。
在我们前面提到的线程池里面,有这样的一个方法:
com.example.asyncthreadpool.spring.AsyncTaskExecutor#ensureAsyncTasksFinish
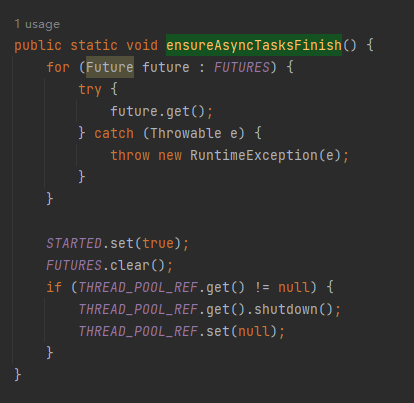
在这个方法里面,调用了 future 的 get 方法进行阻塞等待。当所有的 future 执行完成之后,会关闭线程池。
这个 FUTURES 是什么玩意,怎么来的?
它就是执行 submitTask 方法时,维护进行去的,里面装的就是一个个异步执行的 init 方法:

所以它通过这个方法可以确保能感知到所有的通过这个线程池执行的 init 方法都执行完毕。
现在,方法有了,你先思考一下,我们什么时候触发这个方法的调用呢?
是不是应该在 Spring 容器告诉你:小老弟,我这边所有的 Bean 都搞定了,你这边啥情况了?
这个时候你就需要调用一下这个方法。
而 Spring 容器加载完成之后,会发布这样的一个事件。也就是它:
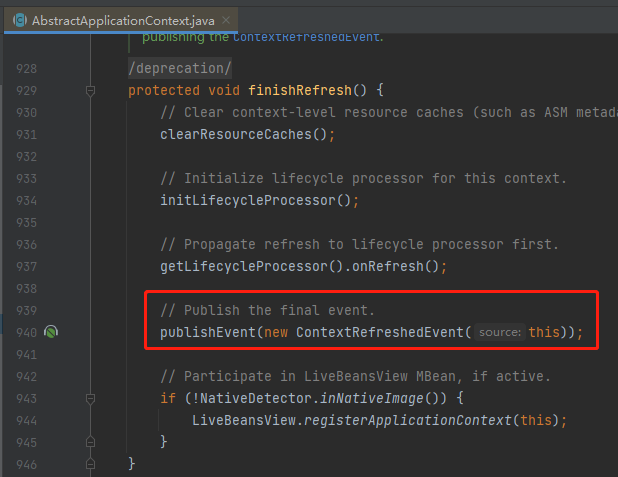
所以,SOFABoot 的做法就是监听这个事件:
com.example.asyncthreadpool.spring.AsyncTaskExecutionListener
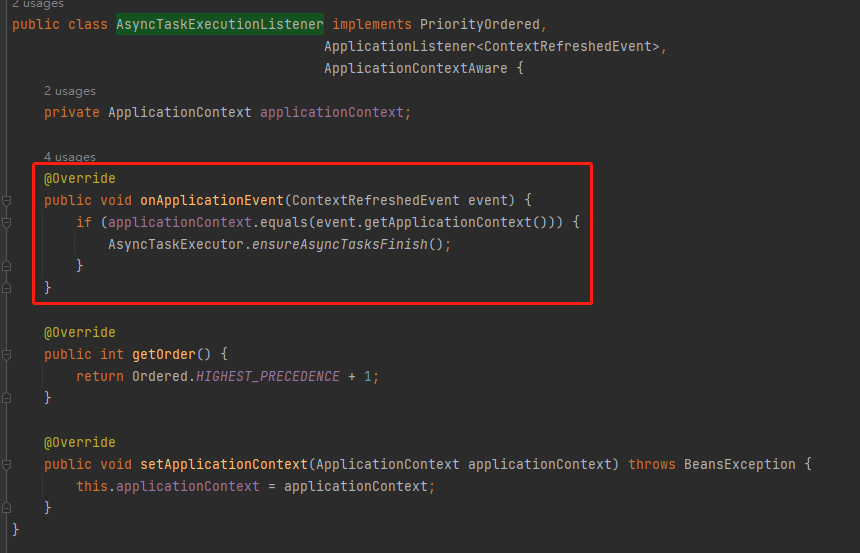
这样,即可确保在异步线程中执行的 init 方法的 Bean 执行完成之后,容器才算启动成功,对外提供服务。
到这里,原理部分我算是讲完了。
但是写到这里的时候,我突然冒出了一个写之前没有过的想法:在整个实现的过程中,最关键的有两个东西:
一个 Map:里面维护的是所有可以异步执行 init 方法的 Bean 和其对应的 init 方法。 一个线程池:异步执行 init 方法。
而这个 Map 是怎么来的?
不是通过扫描 @SofaAsyncInit 注解得到的吗?
那么扫描出来的 @SofaAsyncInit 怎么来的?
不就是我写代码的时候主动标注上去的吗?
所以,我们是不是可以完全不用 Map ,直接使用异步线程池:
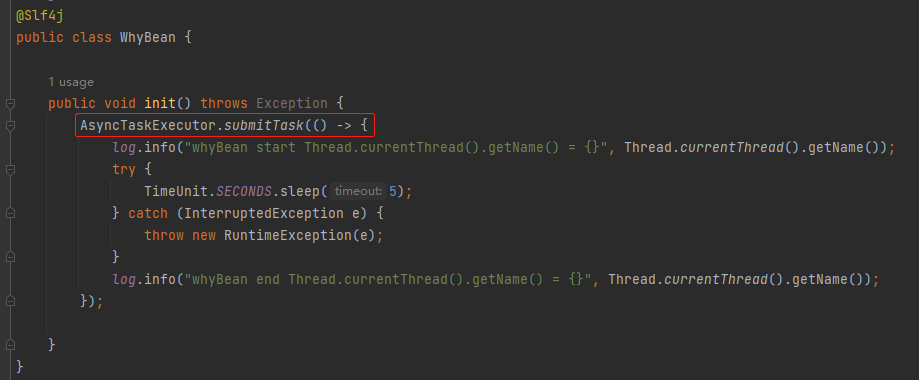
剩去中间环节,直接一步到位,只需要留下两个类即可:
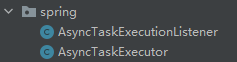
我这里把这个两个类贴出来。
AsyncTaskExecutionListener:
public class AsyncTaskExecutionListener implements PriorityOrdered,
ApplicationListener<ContextRefreshedEvent>,
ApplicationContextAware {
private ApplicationContext applicationContext;
@Override
public void onApplicationEvent(ContextRefreshedEvent event) {
if (applicationContext.equals(event.getApplicationContext())) {
AsyncTaskExecutor.ensureAsyncTasksFinish();
}
}
@Override
public int getOrder() {
return Ordered.HIGHEST_PRECEDENCE + 1;
}
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
this.applicationContext = applicationContext;
}
}
AsyncTaskExecutor:
@Slf4j
public class AsyncTaskExecutor {
protected static final int CPU_COUNT = Runtime.getRuntime().availableProcessors();
protected static final AtomicReference<ThreadPoolExecutor> THREAD_POOL_REF = new AtomicReference<ThreadPoolExecutor>();
protected static final List<Future> FUTURES = new ArrayList<>();
public static Future submitTask(Runnable runnable) {
if (THREAD_POOL_REF.get() == null) {
ThreadPoolExecutor threadPoolExecutor = createThreadPoolExecutor();
boolean success = THREAD_POOL_REF.compareAndSet(null, threadPoolExecutor);
if (!success) {
threadPoolExecutor.shutdown();
}
}
Future future = THREAD_POOL_REF.get().submit(runnable);
FUTURES.add(future);
return future;
}
private static ThreadPoolExecutor createThreadPoolExecutor() {
int threadPoolCoreSize = CPU_COUNT + 1;
int threadPoolMaxSize = CPU_COUNT + 1;
log.info(String.format(
"create why-async-init-bean thread pool, corePoolSize: %d, maxPoolSize: %d.",
threadPoolCoreSize, threadPoolMaxSize));
return new ThreadPoolExecutor(threadPoolCoreSize, threadPoolMaxSize, 30,
TimeUnit.SECONDS, new LinkedBlockingQueue<>(), new ThreadPoolExecutor.CallerRunsPolicy());
}
public static void ensureAsyncTasksFinish() {
for (Future future : FUTURES) {
try {
future.get();
} catch (Throwable e) {
throw new RuntimeException(e);
}
}
FUTURES.clear();
if (THREAD_POOL_REF.get() != null) {
THREAD_POOL_REF.get().shutdown();
THREAD_POOL_REF.set(null);
}
}
}
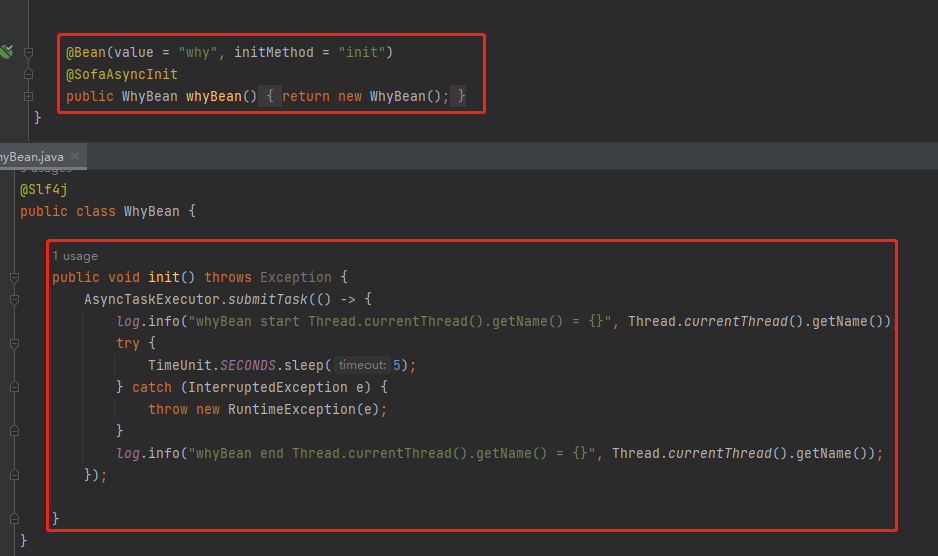
你只需要把这两个类,一共 68 行代码,粘到你的项目中,然后把 AsyncTaskExecutionListener 以 @Bean 的方式注入:
@Bean
public AsyncTaskExecutionListener asyncTaskExecutionListener() {
return new AsyncTaskExecutionListener();
}
恭喜你,你项目中的 Bean 也可以异步执行 init 方法了,使用方法就像这样式儿的:

但是,如果你要对比这两种写的法的话:
肯定是选注解嘛,优雅的一比。
所以,我现在问你一个问题:清理聊聊异步初始化 Bean 的思路。
然后在追问你一个问题:如果通过自定义注解的方式实现?需要用到 Spring 的那些扩展点?
 还思考个毛啊,不就是这个过程吗?
还思考个毛啊,不就是这个过程吗?
回想一下前面的内容,是不是品出点味道了,是不是有点感觉了,是不是觉得自己又行了?
其实说真的,这个方案,当需要人来主动标识哪些 Bean 是可以异步初始化的时候,就已经“输了”,已经不够惊艳了。
但是,你想想本文只是想教你“异步初始化”这个点吗?
不是的,只是以“异步初始化”为抓手,试图教你一种源码解读的方法,找到撕开 Spring 框架的又一个口子,这才是重要的。
最后,前两天阿里开发者公众号也发布了一篇叫《Bean异步初始化,让你的应用启动飞起来》的文章,想要达成的目的一样,但是最终的落地方案可以说差距很大。这篇文章没有具体的源码,但是也可以对比着看一下,取长补短,融会贯通。
行了,我就带你走到这了,我只是给你指个路,剩下的路就要你自己走了。
天黑路滑,灯火昏暗,抓住主干,及时回头。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号