我试图通过这篇文章,教会你一种阅读源码的方式。
你好呀,我是歪歪。
是的,正如标题描述的这样,我试图通过这篇文章,教会你如何阅读源码。
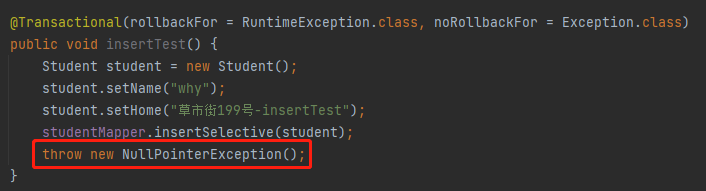
事情大概是这样的,前段时间,我收到了一个读者发来的类似于这样的示例代码:
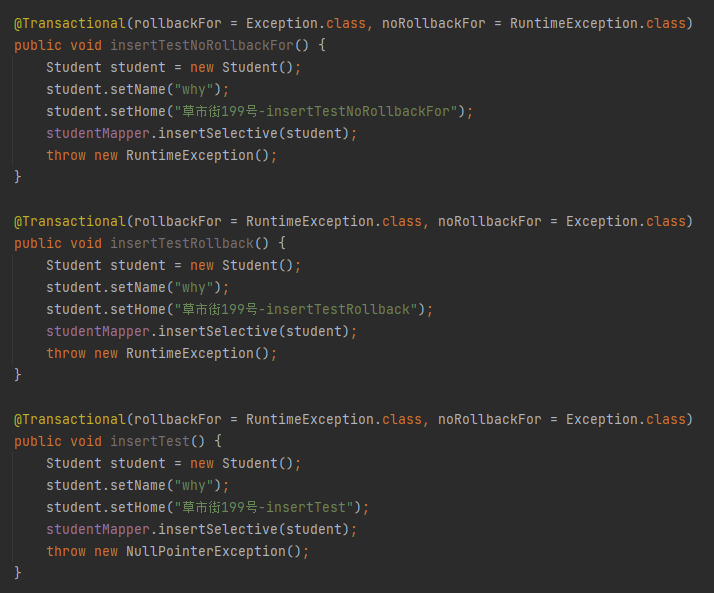
他说他知道这三个案例的回滚情况是这样的:
insertTestNoRollbackFor:不会回滚 insertTestRollback:会回滚 insertTest:会回滚
他说在没有执行代码之前,他也知道前两个为什么一个不会回滚,一个会回滚。因为抛出的异常和 @Transactional 里面的注解呼应上了。
但是第三个到底会不会回滚,没有执行之前,他不知道为什么会回滚。执行之后,回滚了,他也不知道为什么回滚了。
我告诉他:源码之下无秘密。
让他去看看这部分源码,理解它的原理,不然这个地方抛出一个其他的异常,又不知道会不会回滚了。
但是他说他完全不会看源码,找不到下手的角度。
所以,就这个问题,我打算写这样的一篇文章,试图教会你一种阅读源码的方式。让你找到一个好的切入点,或者说突破口。
但是需要事先说明的是,阅读源码的方式非常的多,这篇文章只是站在我个人的角度介绍阅读源码的众多方式中的一种,沧海一粟,就像是一片树林里面的一棵树的树干上的一叶叶片的叶脉中的一个小分叉而已。

对于啃源码这件事儿,没有一个所谓的“一招吃遍天下”的秘诀,如果你非要让我给出一个秘诀的话,那么就只有一句话:
啃源码的过程,一定是非常枯燥的,特别是啃自己接触不多的框架源码的时候,千头万绪,也得下手去捋,所以一定要耐得住寂寞才行。
然后,如果你非得让我再补充一句的话,那么就是:
调试源码,一定要亲!自!动!手!只是去看相关的文章,而没有自己一步步的去调试源码,那你相当于看了个寂寞。
亲自动手的第一步就是搞个 Demo 出来。用“黑话”来说,这个 Demo 就是你的抓手,有了抓手你才能打出一套理论结合实际的组合拳。抓手多了,就能沉淀出可复用的方法论,最终为自己赋能。

搭建 Demo
所以,第一步肯定是先把 Demo 给搭建起来,项目结构非常的简单,标准的三层结构:
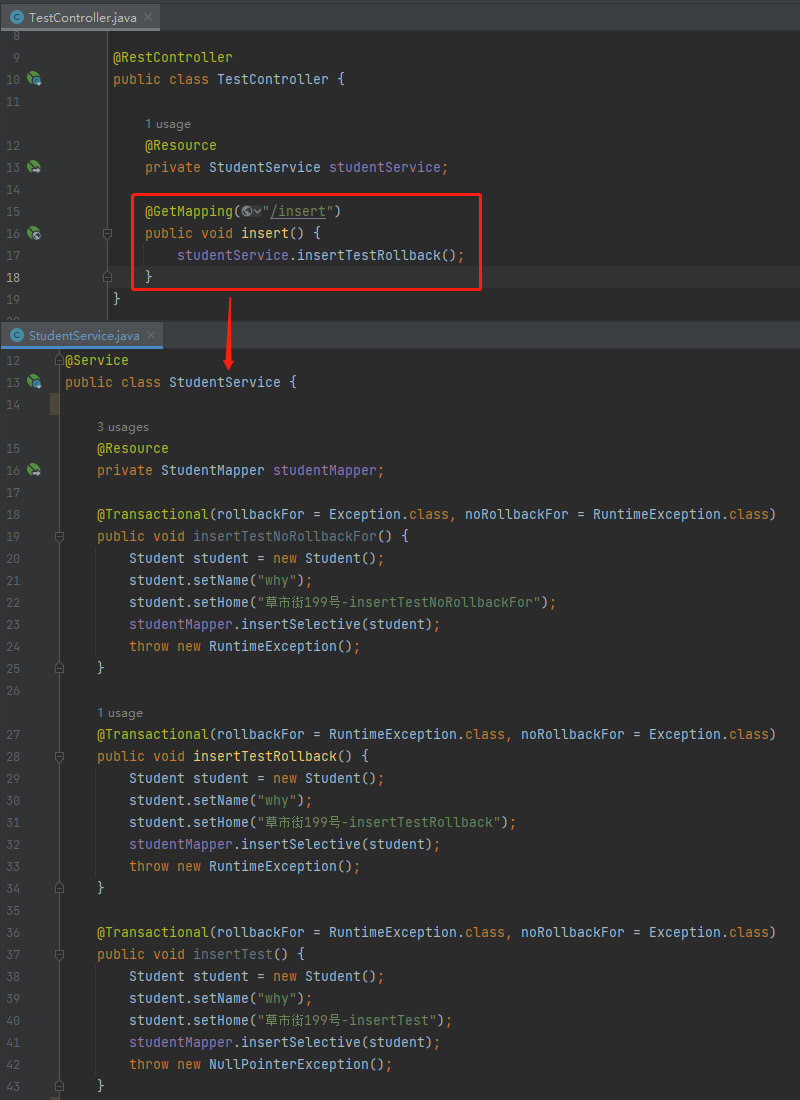
主要是一个 Controller,一个 Service,然后搞个本地数据库给接上,就完全够够的了:
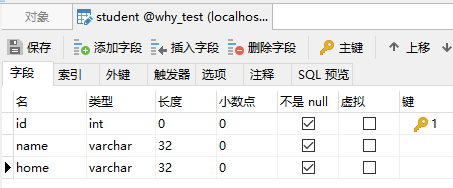
Student 对象是从表里面映射过来的,随便弄了两个字段,主要是演示用:
就这么一点代码,给你十分钟,你是不是就能搭建好了?中间甚至还能摸几分钟鱼。
要是只有这么一点东西的、极其简单的 Demo 你都不想自己亲自动手搭一下,然后自己去调试的话,仅仅是通过阅读文章来肉眼调试,那么我只能说:

在正式开始调试代码之前,我们还得明确一下调试的目的:想要知道 Spring 的 @Transactional 注解对于异常是否应该回滚的判断逻辑具体是怎么样的。
带着问题去调试源码,是最容易有收获的,而且你的问题越具体,收获越快。你的问题越笼统,就越容易在源码里面迷失。
方法论之关注调用栈
自己 Debug 的过程就是不断的打断点的过程。
我再说一次:自己 Debug 的过程就是不断的打断点的过程。
打断点大家都会打,断点打在哪些地方,这个玩意就很讲究了。
在我们的这个 Demo 下,第一个断点的位置非常好判断,就打在事务方法的入口处:
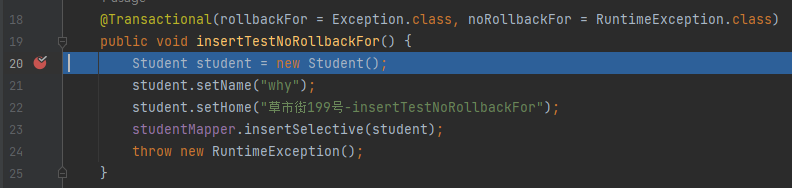
一般来说,大家调试业务代码的时候,都是顺着断点往下调试。但是当你去阅读框架代码的时候,你得往回看。
什么是“往回看”呢?
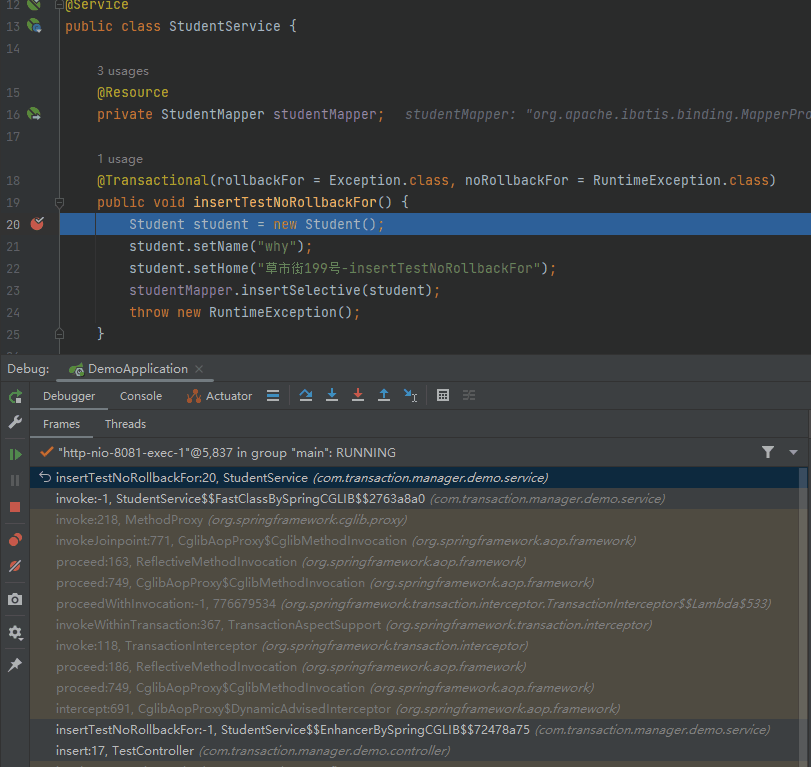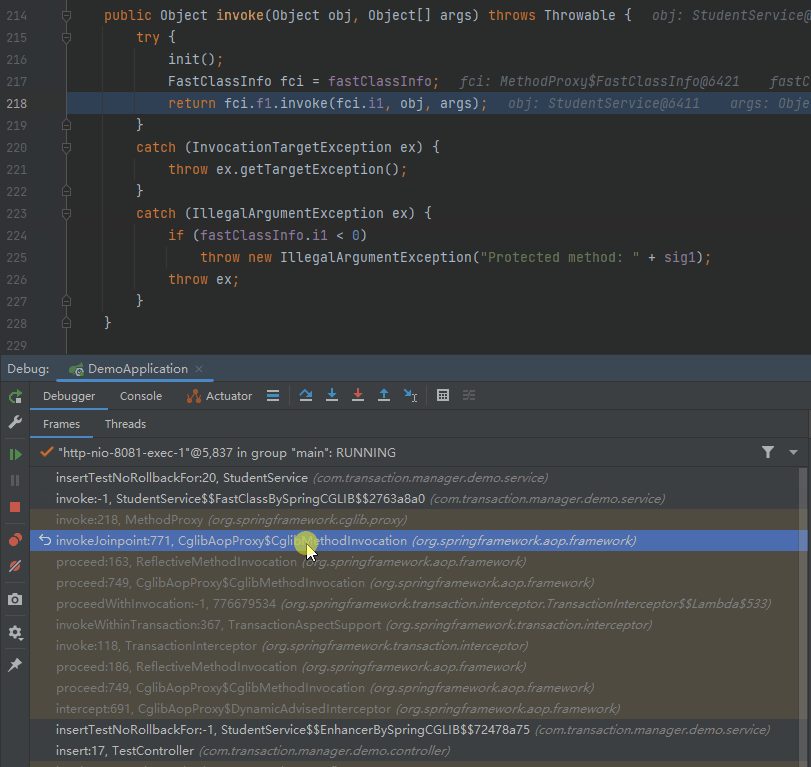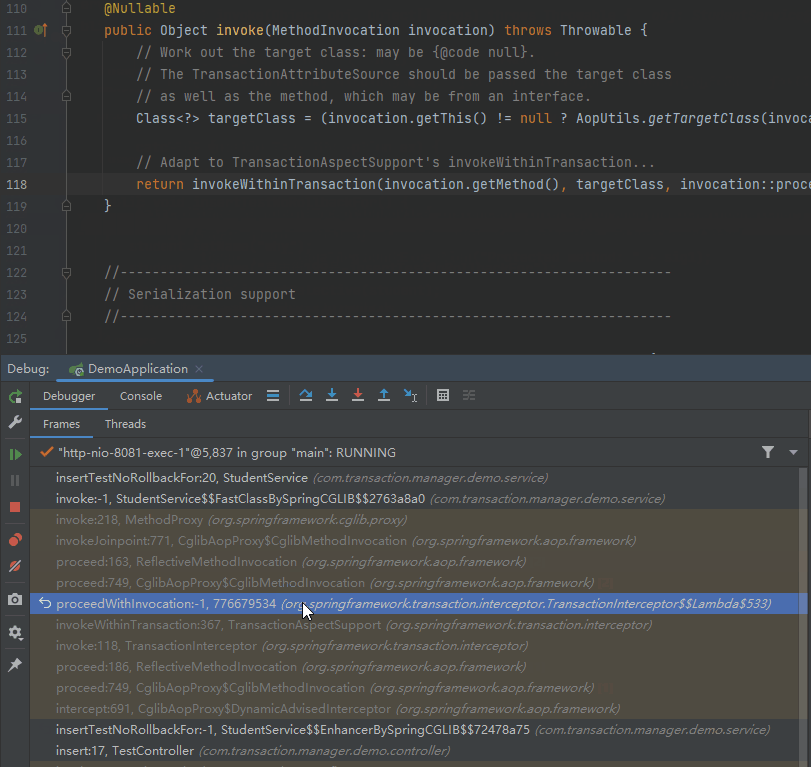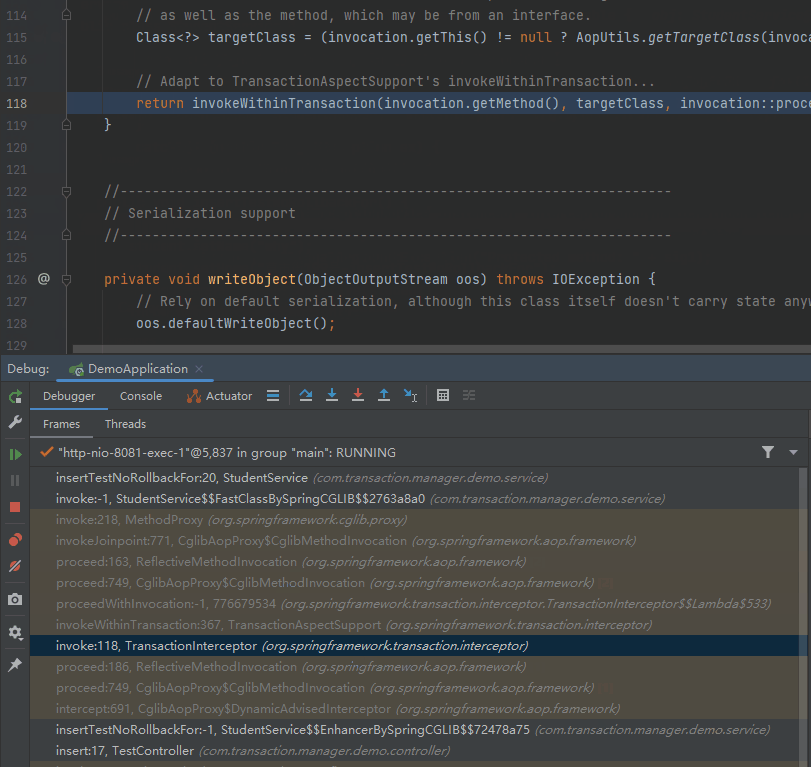
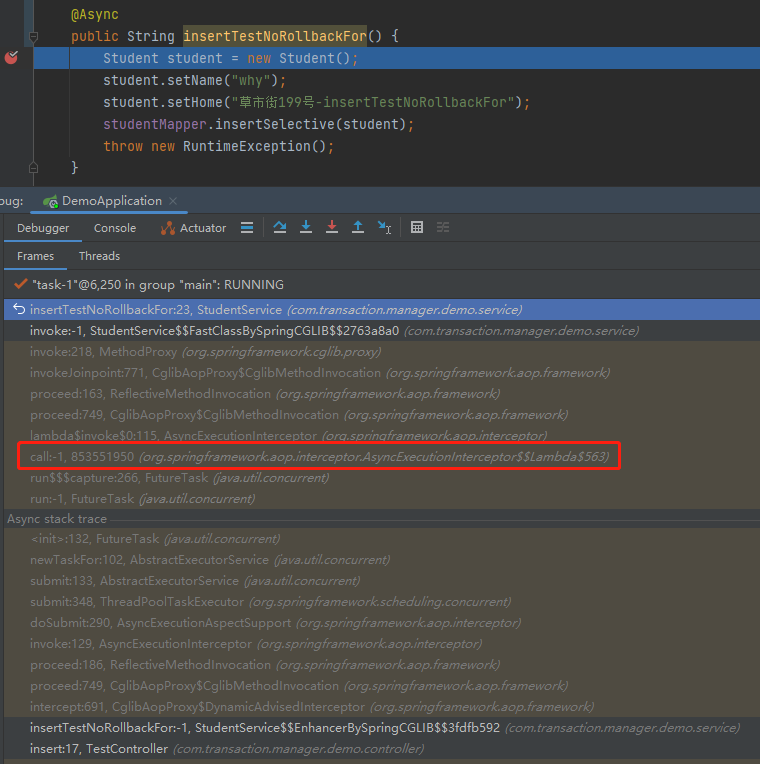
当你的程序在断点处停下的时候,你会发现 IDEA 里面有这样的一个部分:
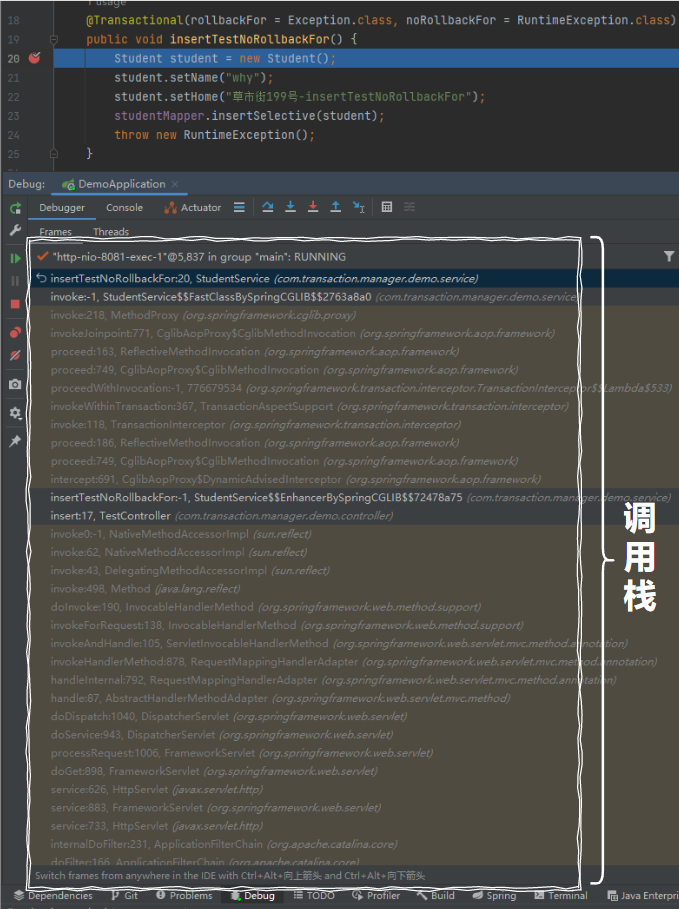
这个调用栈是你在调试的过程中,一个非常非常非常重要的部分。
它表示的是以当前断点位置为终点的程序调用链路。
为了让你彻底的明白这句话,我给你看一张图:
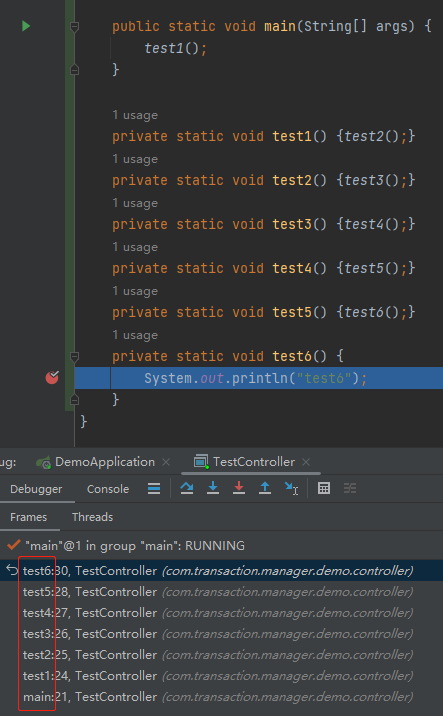
我在 test6 方法中打上断点,调用栈里面就是以 test6 方法为终点到 main 方法为起点的程序调用链接。
当你去点击这个调用栈的时候,你会发现程序也会跟着动:
“跟着动”的这个动作,你可以理解为你站着断点处“往回看”的过程。
当你理解了调用栈是干啥的了之后,我们再具体看看在当前的 Demo 下,这个调用栈里面都有写啥:

标号为 ① 的地方,是 TestController 方法,也就是程序的入口。
标号为 ② 的地方,从包名称可以看出是 String AOP 相关的方法。
标号为 ③ 的地方,就可以看到是事务相关的逻辑了。
标号为 ④ 的地方,是当前断点处。
好,到这里,我想让你简单的回顾一下你来调试代码的目的是什么?
是不是想要知道 Spring 的 @Transactional 注解对于异常是否应该回滚的判断逻辑具体是怎么样的。
那么,我们是不是应该主要把关注的重点放在标号为 ③ 的地方?
也就是对应到这一行:
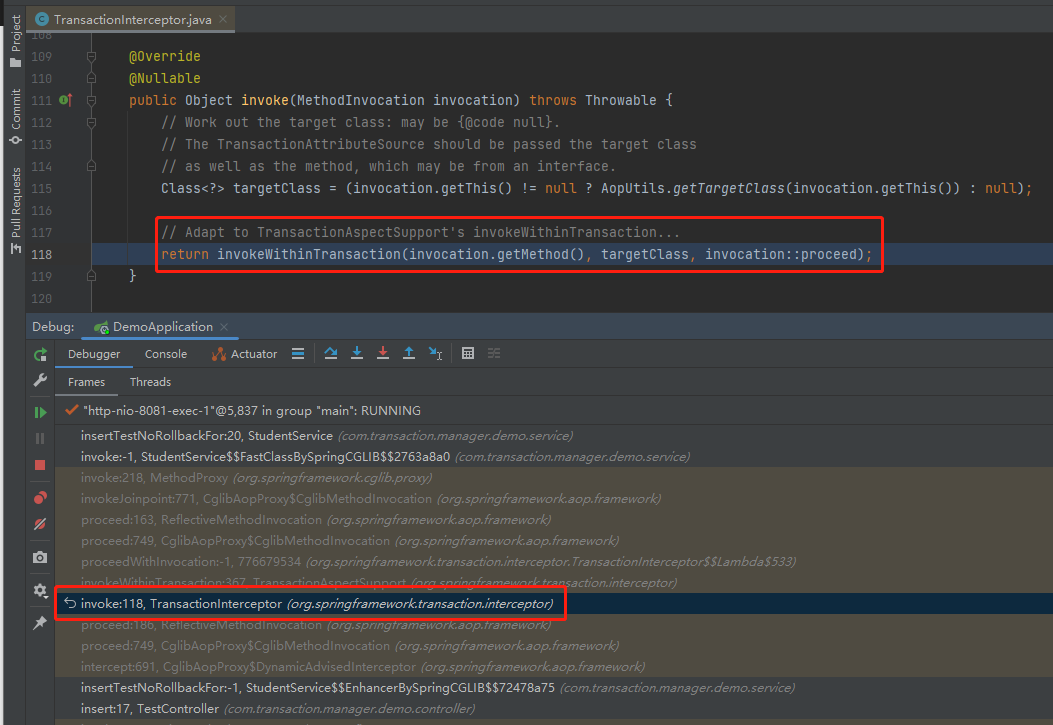
这个地方我一定要特别的强调一下:要保持目标清晰,很多人在源码里面迷失的原因就是不知不觉间被源码牵着走远了。
比如,有人看到标号为 ② 的部分,也就是 AOP 的部分,一想着这玩意我眼熟啊,书上写过 Spring 的事务是基于 AOP 实现的,我去看看这部分代码吧。
当你走到 AOP 里面去的时候,路就开始有点走偏了。你明白我意思吧?
即使在这个过程中,你翻阅了这部分的源码,确实了解到了更多的关于 AOP 和事务之间的关系,但是这个部分并不解决你“关于回滚的判断”这个问题。
然而更多更真实的情况可能是这样的,当你点到 AOP 这部分的时候,你一看这个类名称是 CglibAopProxy:
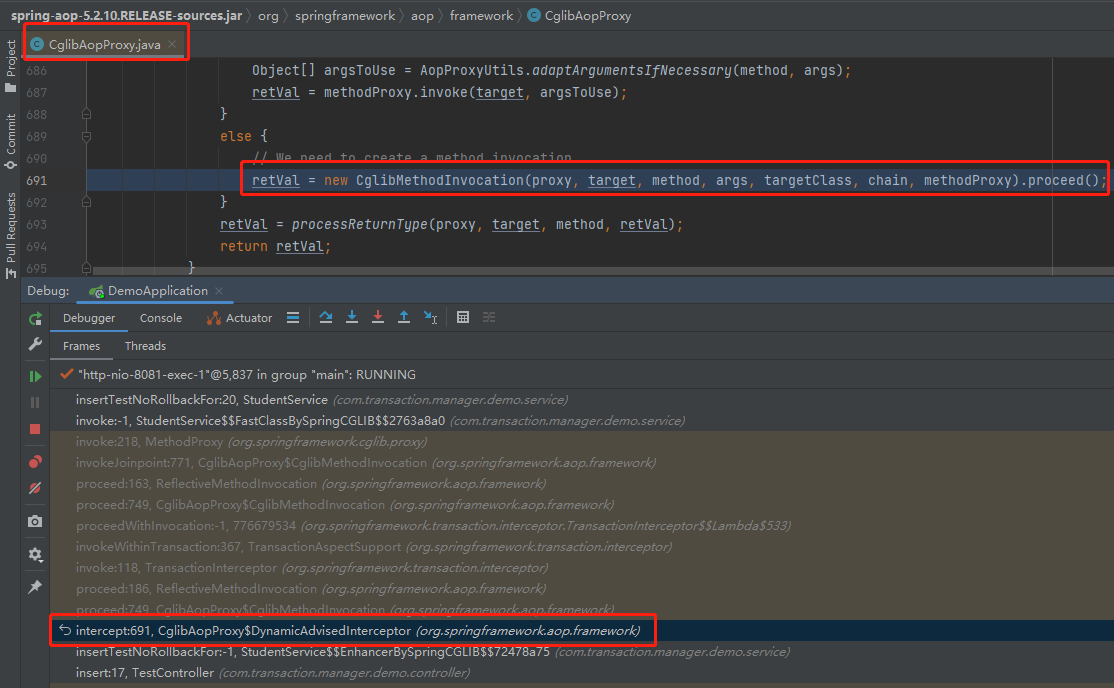
你一细嗦,Cglib 你也熟悉啊,它和 JDK 动态代理是一对好兄弟,都是老八股了。
然后你可能又会点击到 AopProxy 这个接口,找到 JdkDynamicAopProxy:
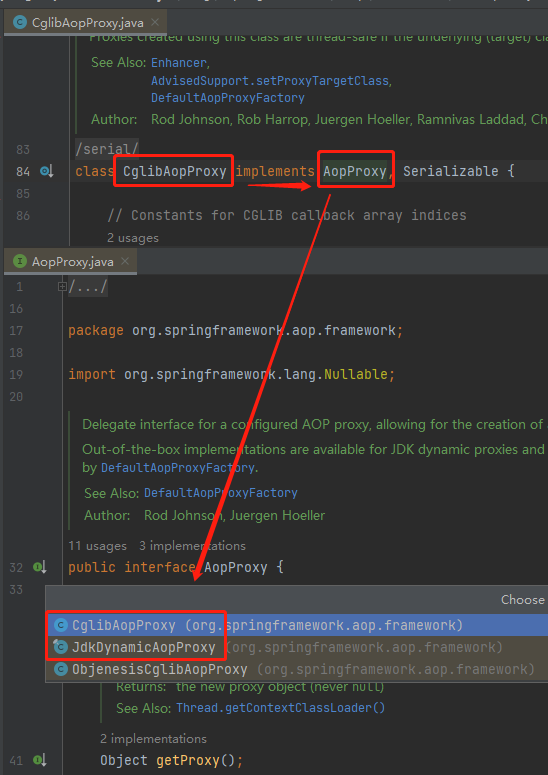
接着你恍然大悟:哦,我在什么都没有配置的情况下,当前版本的 SpringBoot 默认使用的是 Cglib 作为动态代理的实现啊。
诶,我怎么记得我背的八股文默认是使用 JDK 呢?
网上查一下,查一下。
哦,原来是这么一回事儿啊:
SpringBoot 1.x,默认使用的是 JDK 动态代理。 SpringBoot 2.x 开始,为了解决使用 JDK 动态代理可能导致的类型转化异常而默认使用 CGLIB。 在 SpringBoot 2.x 中,如果需要默认使用 JDK 动态代理可以通过配置项spring.aop.proxy-target-class=false来进行修改,proxyTargetClass配置已无效。
刚刚提到了一个 spring.aop.proxy-target-class 配置,这是个啥,咋配置啊?
查一下,查一下...
喂,醒一醒啊,朋友,走远了啊。还记得你调试源码的目的吗?

如果你对于 AOP 这个部分感兴趣,可以先进行简单的记录,但是不要去深入的追踪。
不要觉得自己只是随便看看,不要紧。反正正是因为这些“随便看看”导致你在源码里面忙了半天感觉这波学到了,但是停下来一想:我 TM 刚刚看了些啥来着?我的问题怎么还没解决?
我为什么要把这部分非常详尽,甚至于接近啰嗦的写一遍,就是因为这个就是初看源码的朋友最容易犯的错误。
特别强调一下:抓住主要矛盾,解决主要问题。
好,回到我们通过调用栈找到的这个和事务相关的方法中:
org.springframework.transaction.interceptor.TransactionInterceptor#invoke
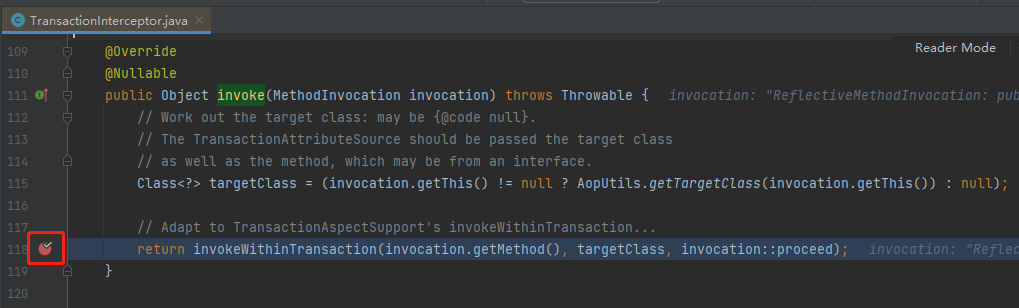
这个方法,就是我们要打第二个断点,或者说这才是真正的第一个断点的地方。
然后,重启项目,重新发起请求,从这个地方就可以进行正向的调试,也就是从框架代码一步步的往业务代码执行。
比如这个方法接着往下 Debug,就来到了这个地方:
org.springframework.transaction.interceptor.TransactionAspectSupport#invokeWithinTransaction
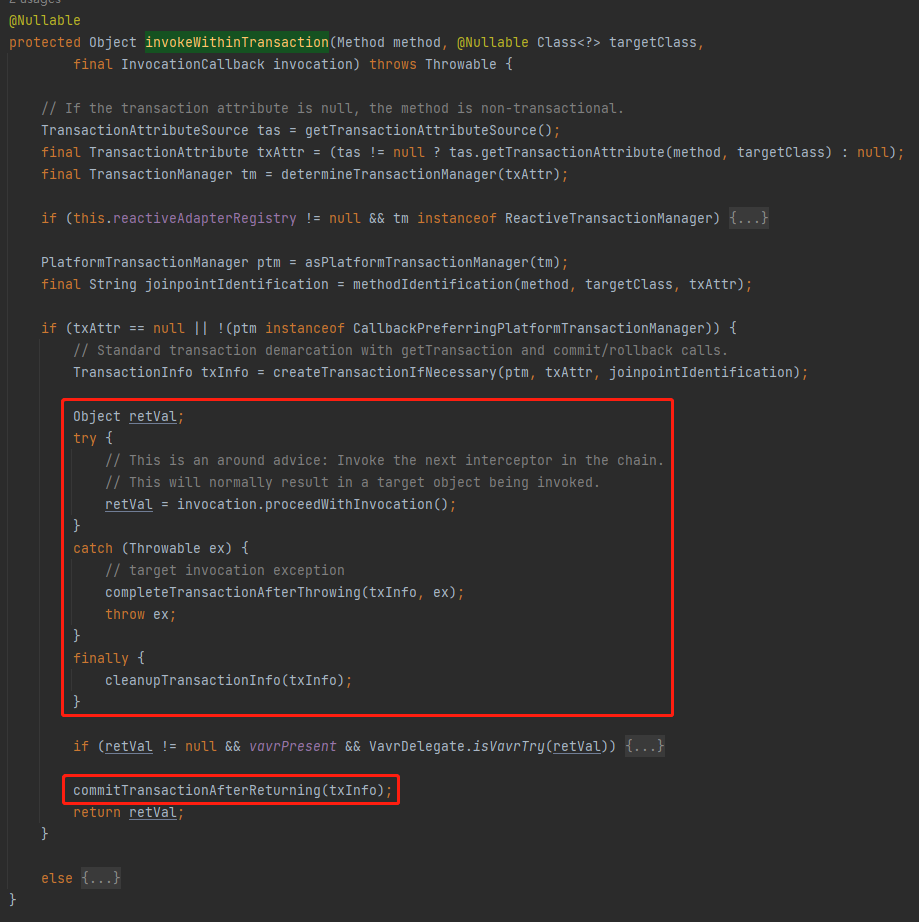
找到了这个地方,你就算是无限的接近于问题的真相了。
这个部分我肯定会讲的,但是在这里先按下不表,毕竟这并不是本文最重要的东西。
本文最重要的是,我再次重申一遍:我试图想要教会你一种阅读源码的方式,让你找到一个好的切入点,或者说突破口。
由于这个案例比较简单,所以很容易找到真正的第一个利于调试的断点。
如果遇到一些复杂的场景、响应式的编程、异步的调用等等,可能会循环往复的执行上面的动作。
分析调用栈,打断点,重启。
再分析调用栈,再打断点,再重启。
方法论之死盯日志
其实我发现很少有人会去注意框架打印的日志,就像是很少有人会去仔细阅读源码上的 Javadoc 一样。
但是其实通过观察日志输出,也是一个很好的寻找阅读源码突破口的方式。
我们要做的,就是保证 Demo 尽量的单纯,不要有太多的和本次排查无关的代码和依赖引入。
然后把日志级别修改为 debug:
logging.level.root=debug
接着,就是发起一次调用,然后耐着性子去看日志。
还是我们的这个 Demo,发起一次调用之后,控制台输出了很多的日志,我给你搞个缩略图看看:

我们已知的是这里面大概率是有线索的,有没有什么方法尽量快的找出来呢?
有,但是通用性不强。所以如果经验不够丰富的话,那么最好的方法就是一行行的去找。
前面我也说过了:啃源码的过程,一定是非常枯燥的。
所以你一定会找到这样的日志输出:
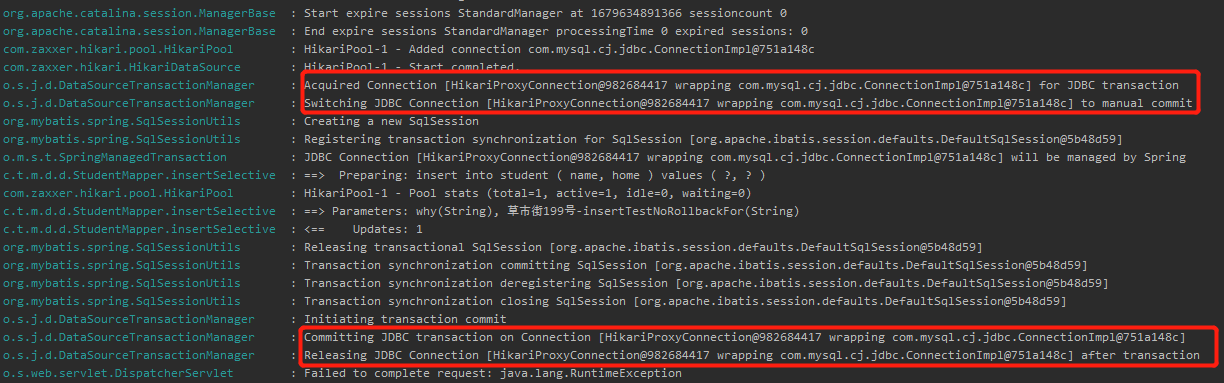
Acquired Connection [HikariProxyConnection@982684417 wrapping com.mysql.cj.jdbc.ConnectionImpl@751a148c] for JDBC transaction
Switching JDBC Connection [HikariProxyConnection@982684417 wrapping com.mysql.cj.jdbc.ConnectionImpl@751a148c] to manual commit
...
==> Preparing: insert into student ( name, home ) values ( ?, ? )
HikariPool-1 - Pool stats (total=1, active=1, idle=0, waiting=0)
==> Parameters: why(String), 草市街199号-insertTestNoRollbackFor(String)
<== Updates: 1
...
Committing JDBC transaction on Connection [HikariProxyConnection@982684417 wrapping com.mysql.cj.jdbc.ConnectionImpl@751a148c]
Releasing JDBC Connection [HikariProxyConnection@982684417 wrapping com.mysql.cj.jdbc.ConnectionImpl@751a148c] after transaction
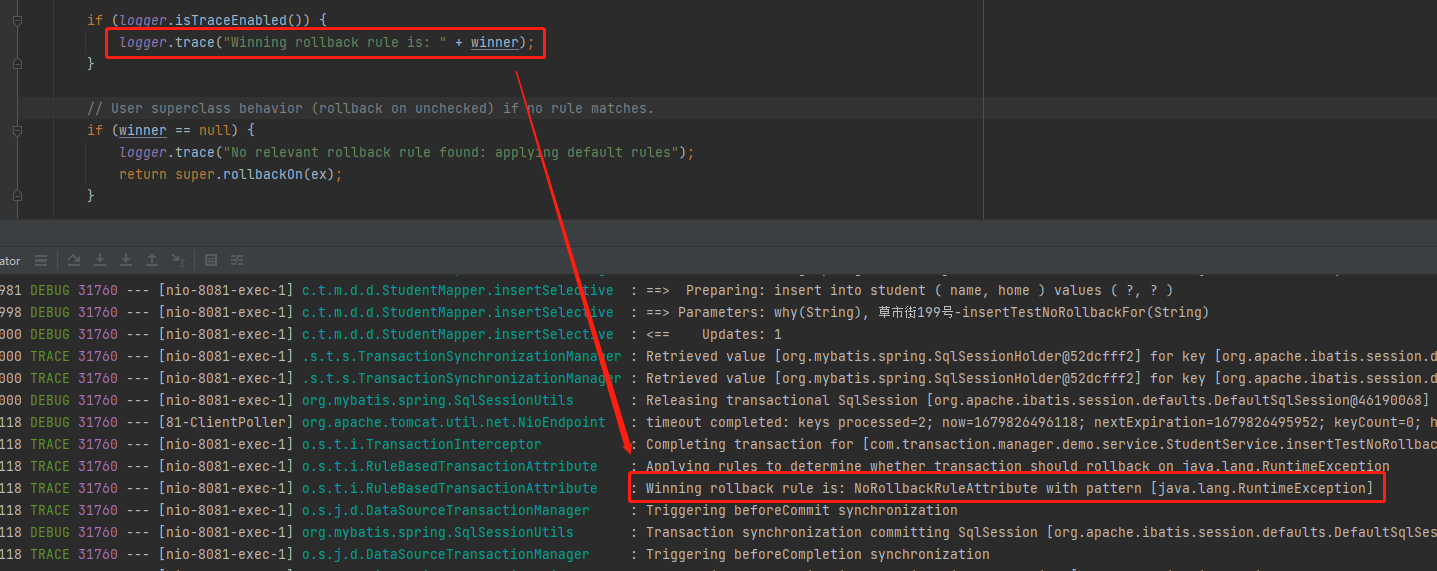
这几行日志,不就是正对应着 Spring 事务的开启和提交吗?
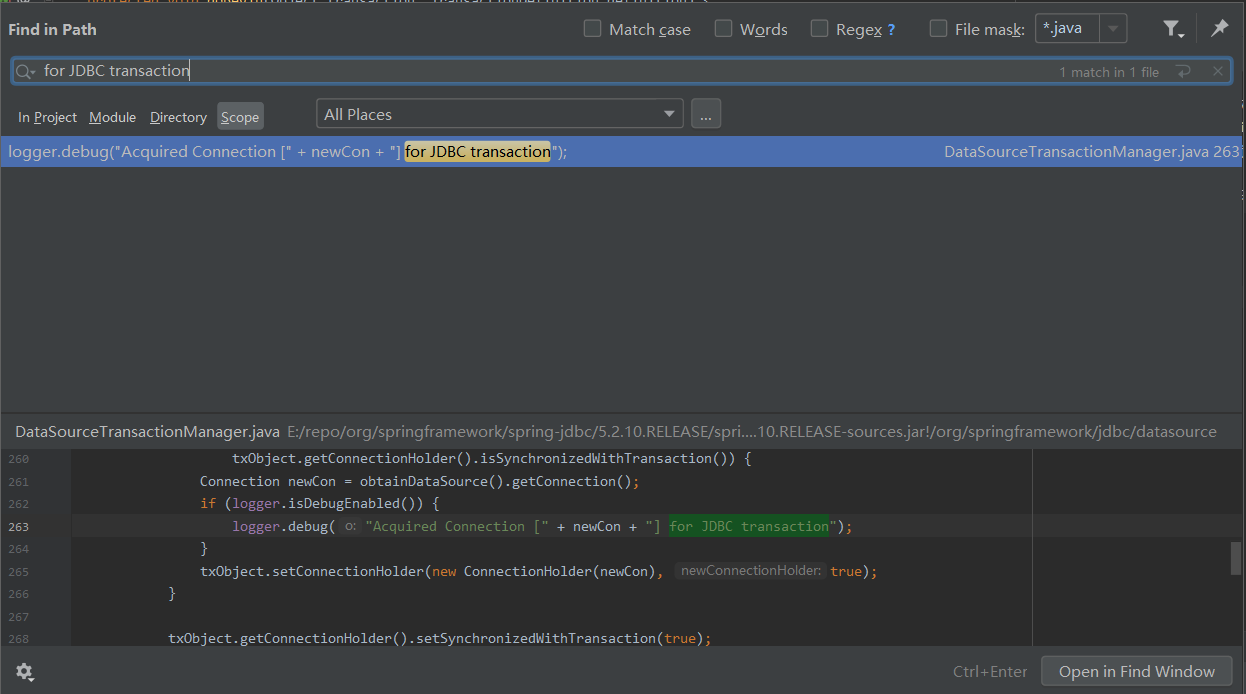
有了日志,我们完全可以基于日志去找对应的日志输出的地方,比如我们现在要找这一行日志输出对应的代码:
o.s.j.d.DataSourceTransactionManager : Acquired Connection [HikariProxyConnection@982684417 wrapping com.mysql.cj.jdbc.ConnectionImpl@751a148c] for JDBC transaction
首先,我们可以根据日志知道对应输出的类是 DataSourceTransactionManager 这个类。
然后找到这个类,按照关键词搜索:
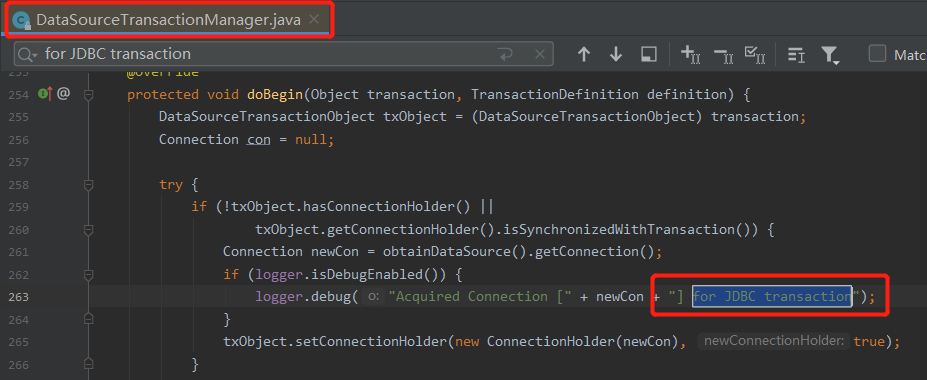
不就找到这一行代码了吗?
或者我们直接秉承大力出奇迹的真理,来一个暴力的全局搜索,也是能搜到这一行代码的:
再或者修改一下日志输出格式,把行号也搞出来嘛。
当我们把日志格式修改为这样之后:
logging.pattern.console=%d{dd-MM-yyyy HH:mm:ss.SSS} %magenta([%thread]) %highlight(%-5level) %logger.%M:%L - %msg%n
控制台的日志就变成了这样:
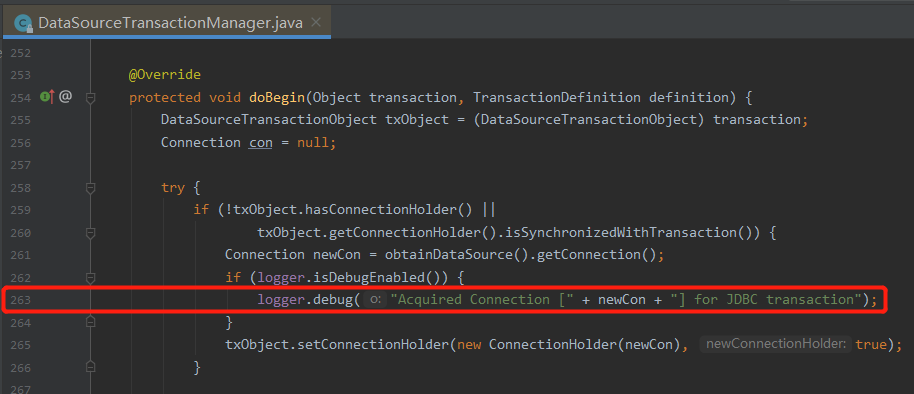
org.springframework.jdbc.datasource.DataSourceTransactionManager.doBegin:263 - Acquired Connection [HikariProxyConnection@1569067488 wrapping com.mysql.cj.jdbc.ConnectionImpl@19a49539] for JDBC transaction
很直观的就看出来了,这行日志是 DataSourceTransactionManager 类的 doBegin 方法,在 263 行输出的。
然后你找过去,发现没有任何毛病,这就是案发现场:
我前面给你说这么多,就是为了让你找到这一行日志输出的地方。
现在,找到了,然后呢?
然后肯定就是在这里打断点,然后重启程序,重新发起调用了啊。
这样,你又能得到一个调用栈:
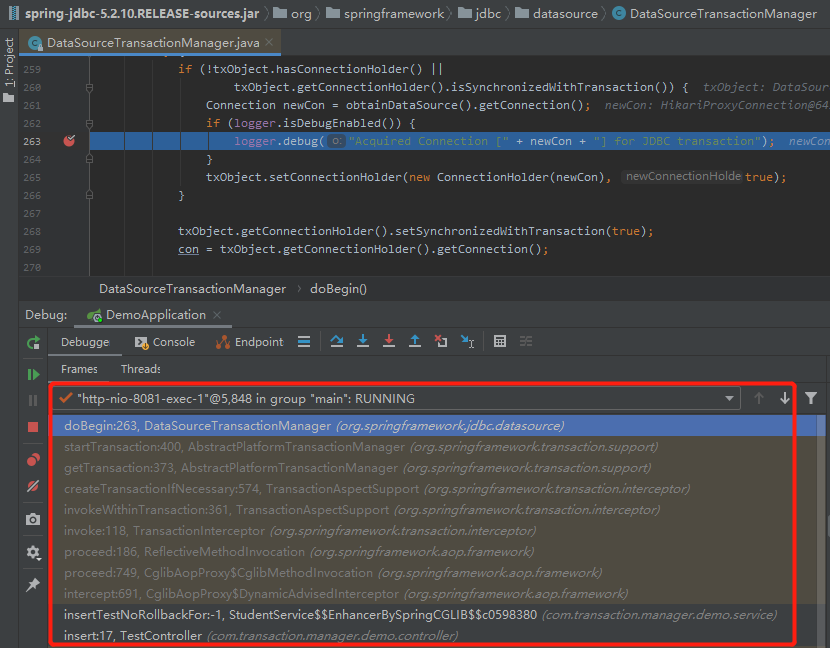
然后,你会从调用栈中看到一个我们熟悉的东西:
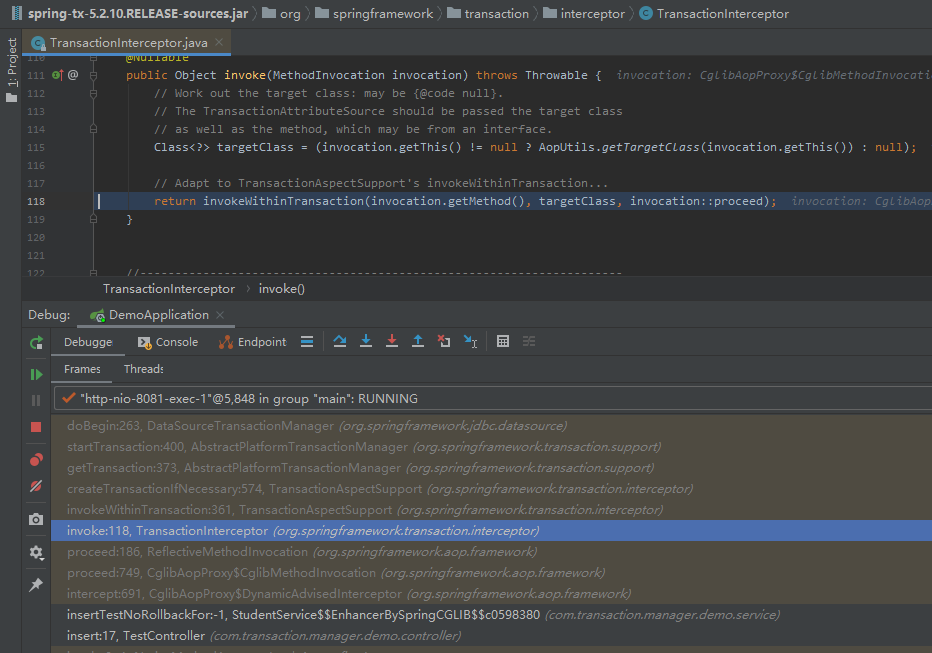
朋友,这不就和前面写的“方法论之关注调用栈”呼应起来了吗?
这不就是一套组合拳吗,不就是沉淀出的可复用的方法论吗?
黑话,咱们也是可以整两句的。
方法论之查看被调用的地方
除了前面两种方法之外,我有时候也会直接看我要阅读部分的方法,在框架中被哪些地方调用了。
比如在我们的 Demo 中,我们要阅读的代码非常的明确,就是 @Transactional 注解。
于是直接看一下这个注解在哪些地方用到了:
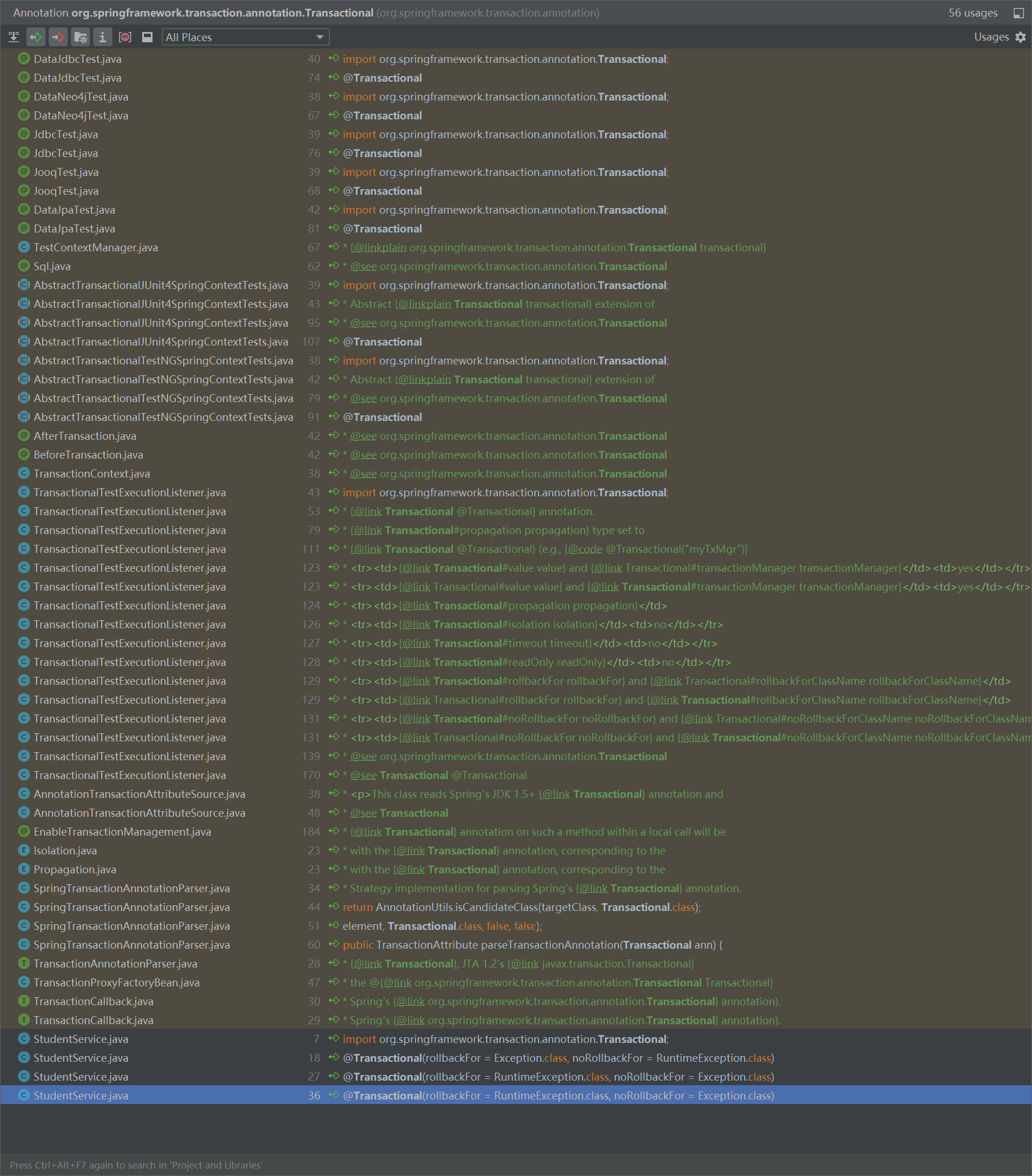
有的时候调用的地方会非常的少,甚至只有一两处,那么直接在调用的地方打上断点就对了。
虽然 @Transactional 注解一眼望去也是有很多的调用,但是仔细一看大多是测试类。排除测试类、JavaDoc 里面的备注和自己项目中的使用之后,只剩下很明显的这三处:

看起来很接近真相,但是很遗憾,这里只是在项目启动的时候解析注解而已。和我们要调研的地方,差的还有点远。
这个时候就需要一点经验了,一看苗头不对,立马转换思路。
什么是苗头不对呢?
你在这几个地方打上断点了,只是在项目启动的过程中断点起作用了,发起调用的时候并没有在断点处停下,说明发起调用的时候并不会触发这部分逻辑,苗头不对。
顺着这个思路想,在我的 Demo 中抛出了异常,那么 rollbackFor 和 noRollbackFor 这两个参数大概率是会在调用的时候被用到,对吧?
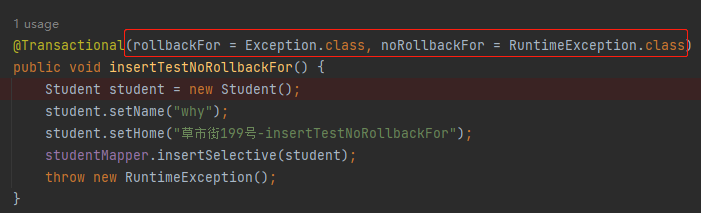
所以当你去看 rollbackFor 被调用的时候只有我们自己写的业务代码在调用:
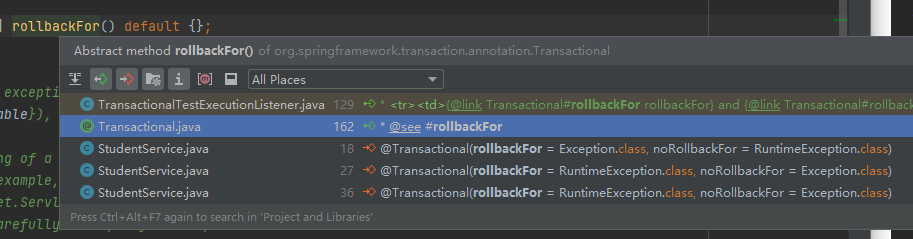
怎么办呢?
这个时候就要靠一点运气了。
是的,靠运气。
你都点到 rollbackFor 这个方法来了,你也看了它被调用的地方,在这个过程中你大概率会瞟到几眼它对应的 JavaDoc:
org.springframework.transaction.annotation.Transactional#rollbackFor
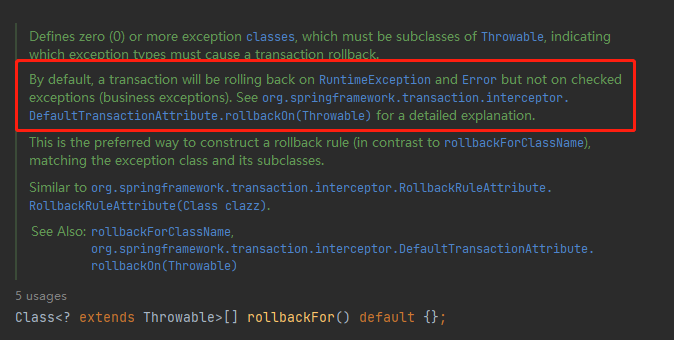
然后你会发现在 JavaDoc 里面提到了 rollbackOn 这个方法:
org.springframework.transaction.interceptor.DefaultTransactionAttribute.rollbackOn(Throwable)
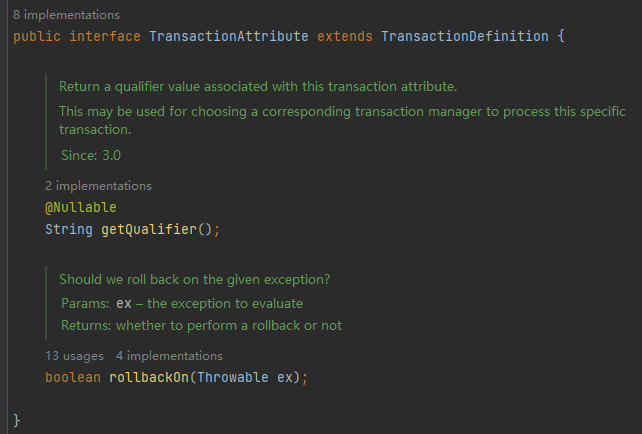
到这里一看,你发现这是一个接口,它有好多个实现类:
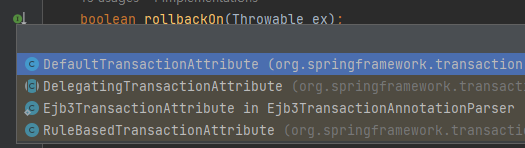
怎么办呢?
早期的时候,由于不知道具体的实现类是哪个,我是在每个实现类的入口处都打上断点,虽然是笨办法,但是总是能起作用的。
后来我才发现,原来可以直接在接口上打断点:
然后,重启项目,发起调用,第一次会停在我们方法的入口:
F9,跳过当前断点之后,来到了这个地方:
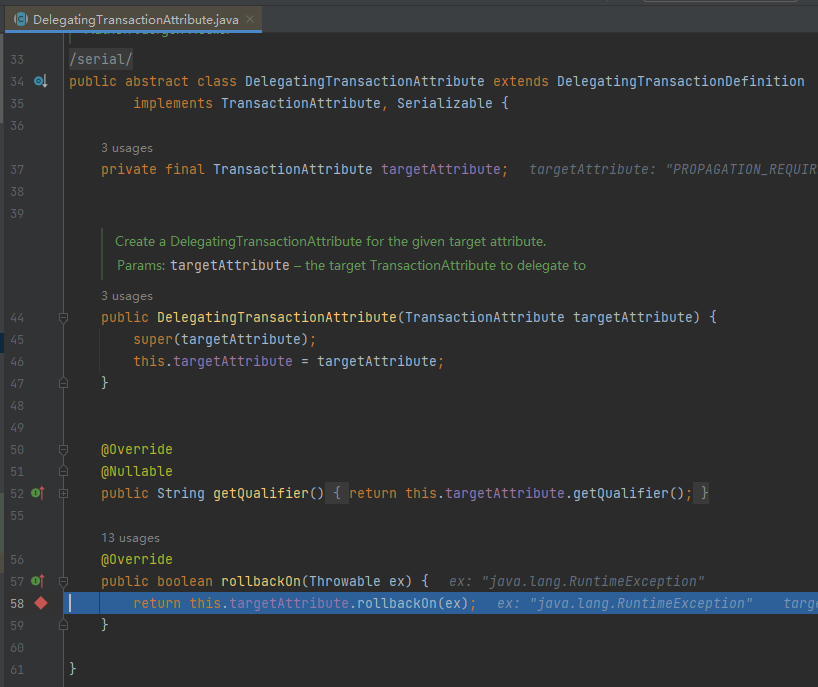
这里就是我前面在接口上打的方法断点,走到了这个实现类中:
org.springframework.transaction.interceptor.DelegatingTransactionAttribute
然后,关键的就来了,我们又有一个调用栈了,又从调用栈中看到一个我们熟悉的东西:
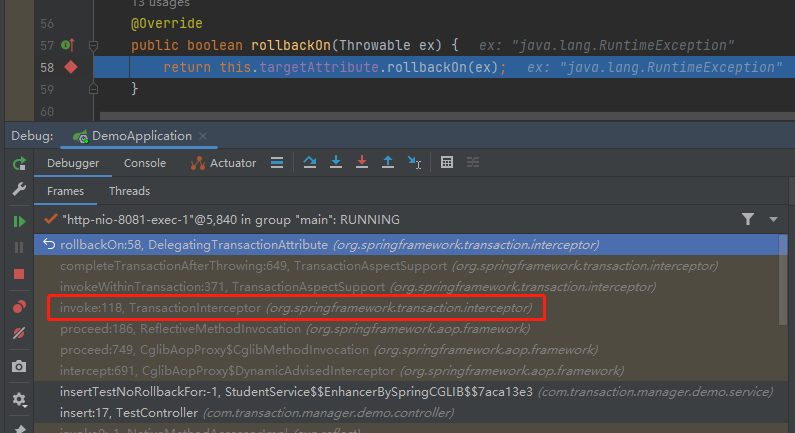
朋友,组合拳这不又打起来了?突破口不就又找到了?
关于“瞟到几眼对应的 JavaDoc ,然后就可能找到突破口”的这个现象,早期对我来说确实是运气,但是现在已经是一个习惯了。一些知名框架的 JavaDoc 真的写的很清楚的,里面隐藏了很多关键信息,而且是最权威的正确信息,读官网文档,比读技术博客稳当的多。
探索答案
前面我介绍的都是找到代码调试突破口的方法。
现在突破口也有了,接下来应该怎么办呢?
很简单,调试,反复的调试。从这个方法开始,一步一步的调试:
org.springframework.transaction.interceptor.TransactionInterceptor#invoke
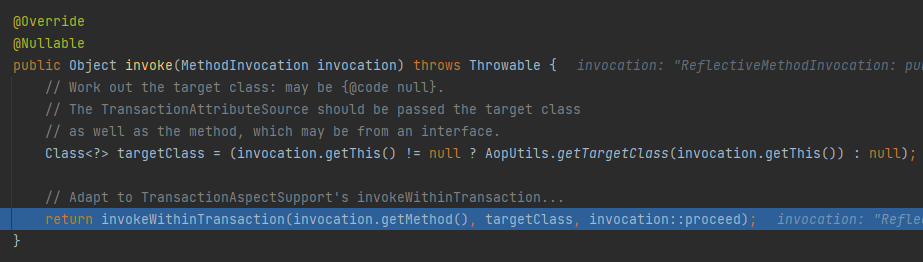
如果你真的想要有所收获的话,这是一个需要你亲自去动手的步骤,必须要有逐行阅读的一个过程,然后才能知道大概的处理流程。
我就不进行详细解读了,只是把重点给大家画一下:
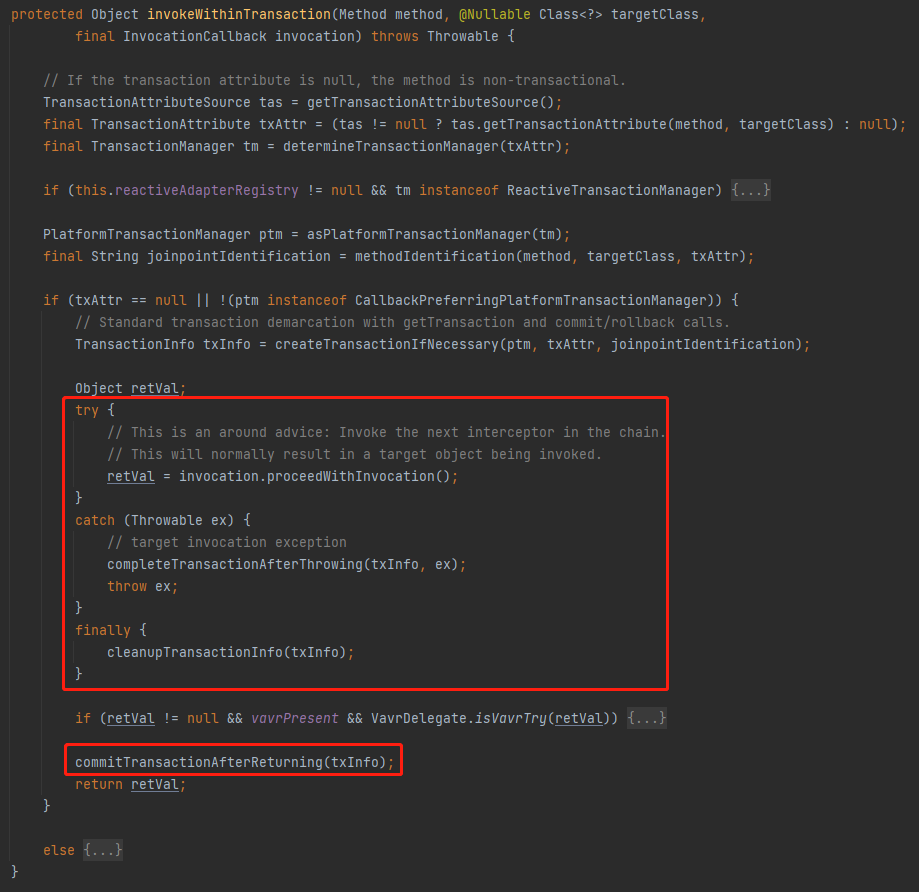
框起来的部分,就是去执行业务逻辑,然后基于业务逻辑的处理结果,去走不同的逻辑。
抛异常了,走这个方法:completeTransactionAfterThrowing
正常执行完毕了,走这个方法:commitTransactionAfterReturning
所以,我们问题的答案就藏在 completeTransactionAfterThrowing 里面。
继续调试,进入这个方法之后,可以看到它拿到了事务和当前异常相关的信息:

在这个方法里面,大体的逻辑是当标号为 ① 的地方为 true 的时候,就在标号为 ② 的地方回滚事务,否则就在标号为 ③ 的地方提交事务:
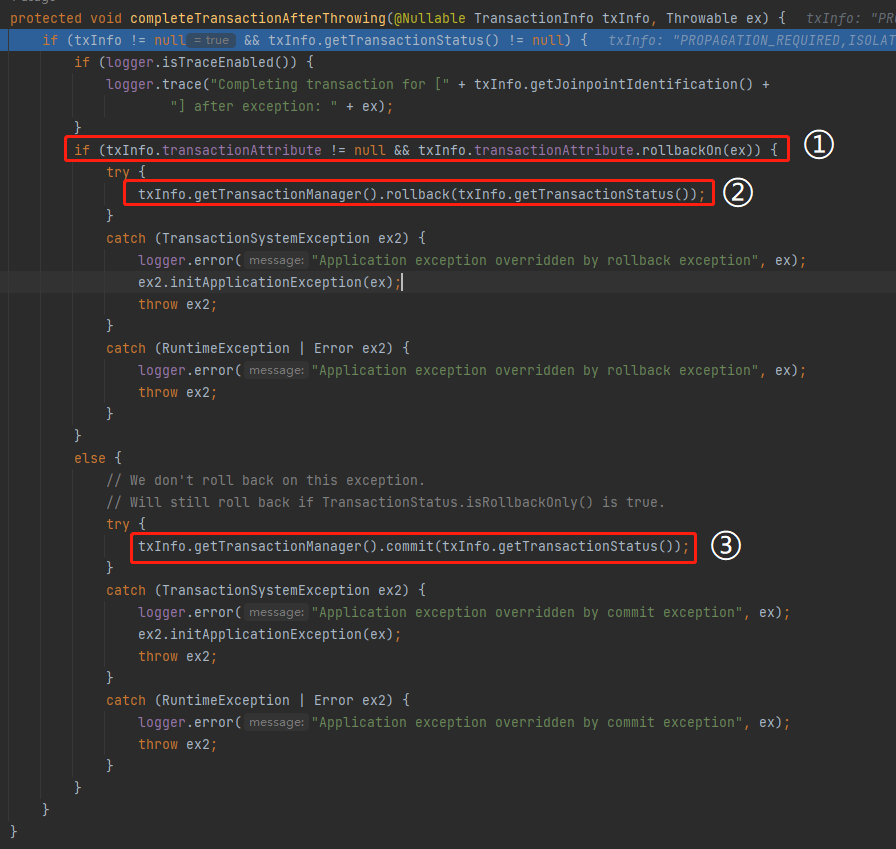
因此,标号为 ① 的部分就很重要了,这里面就藏着我们问题的答案。
另外,在这里多说一句,在我们的案例中,这个方法,也就是当前调试的方法是不会回滚的:
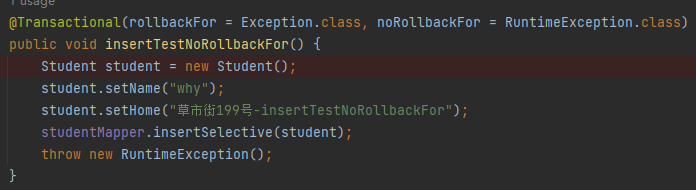
而这个方法是会回滚的:

也就是这两个方法在这个地方会走不同的逻辑,所以你在调试的时候遇到 if-else 就需要注意,去构建不同的案例,以覆盖尽量多的代码逻辑。
继续往下调试,会进入到标号为 ① 的 rollbackOn 方法里面,来到这个方法:
org.springframework.transaction.interceptor.RuleBasedTransactionAttribute#rollbackOn
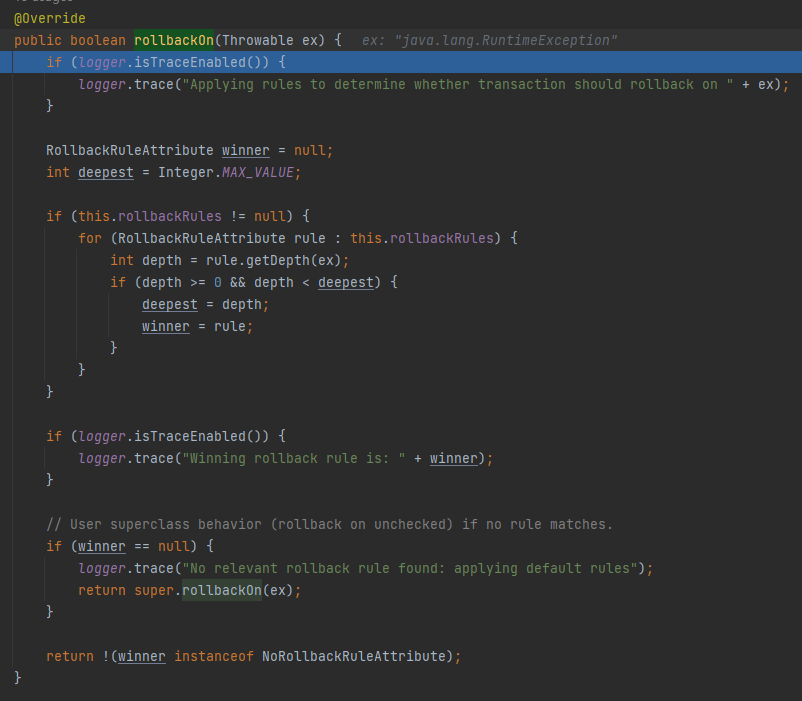
这里,就藏着问题的终极答案,而且这里面的代码逻辑相对比较的绕。
核心逻辑就是通过循环 rollbackRules,这里面装的是我们在代码中配置的回滚规则,在循环体中拿 ex,也就是我们程序抛出的异常,去匹配规则,最后选择一个 winner:
如果 winner 为空,则走默认逻辑。如果是 RuntimeException 或者是 Error 的子类,就要进行回滚:
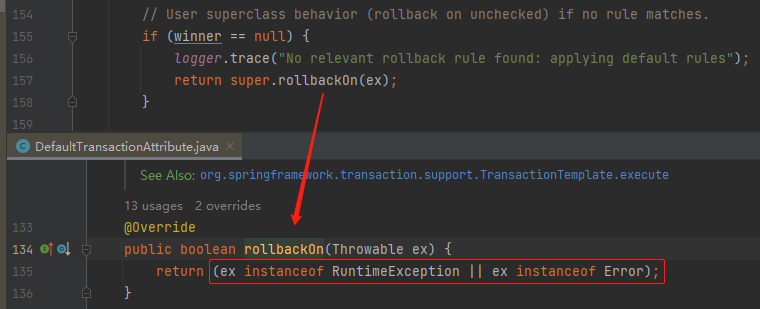
如果有 winner,判断 winner 是否是不用回滚的配置,如果是,则取反,返回 false,表示不进行回滚:
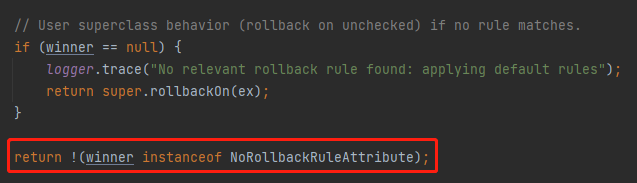
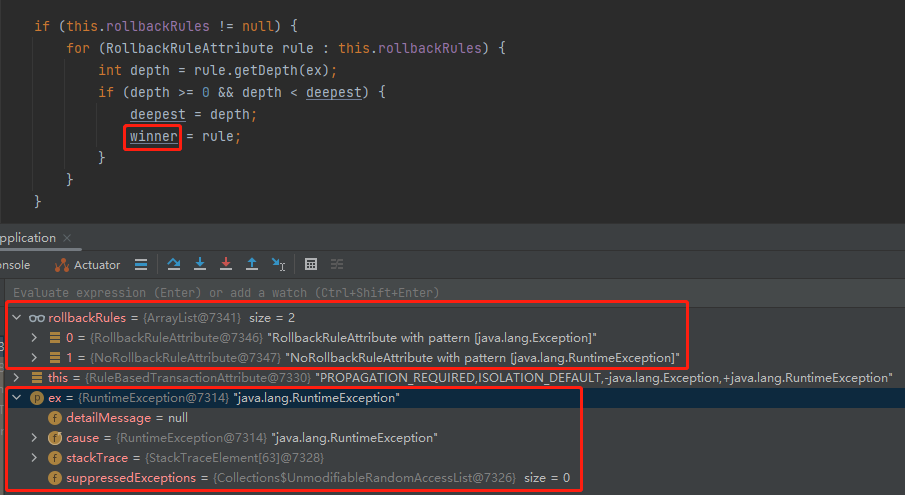
那么问题的冠军就在于:winner 怎么来的?
答案就藏着这个递归调用中:
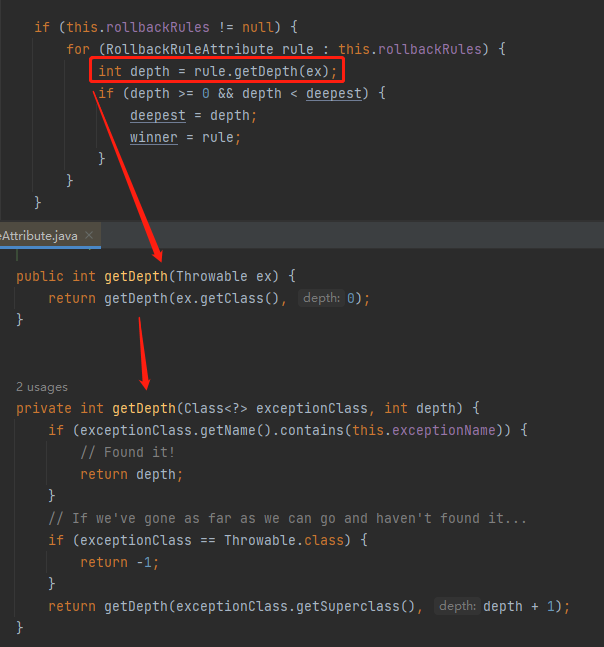
一句话描述就是:看当前抛出的异常和配置的规则中的 rollbackFor 和 noRollbackFor 谁距离更近。这里的距离指的是父类和子类之间的关系。
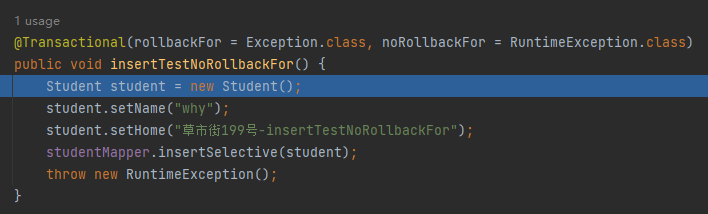
比如,还是这个案例:
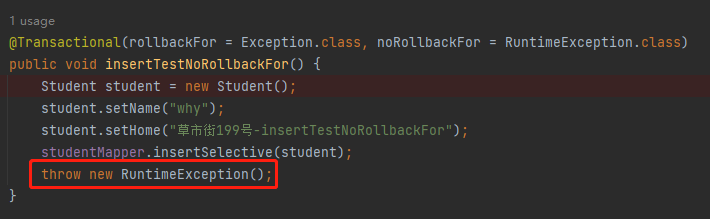
我们抛出的是 RuntimeException,它距离 noRollbackFor=RuntimeException.class 为 0。RuntimeException 是 Exception 的子类,所以距离 rollbackFor = Exception.class 为 1。
所以,winner 是 noRollbackFor,能明白吧?
然后,我们再看一下这个案例:
根据前面的“距离”的分析,NullPointerException 是 RuntimeException 的子类,它们之间的距离是 1。而 NullPointerException 到 Exception 的距离是 2:
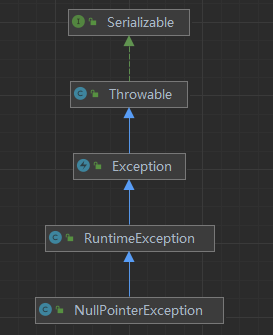
所以,rollbackFor=RuntimeException.class 这个的距离更短,所以 winner 是 rollbackFor。
而把 winner 放到这个判断中,返回是 true:
return !(winner instanceof NoRollbackRuleAttribute);
所以,这就是它为什么会回滚的原因:
好了,到这里你有可能是晕的,晕就对了,去调试这部分代码,亲自摸一遍,你就搞的明明白白了。
最后,再给“死盯日志”的方法论打个补丁吧。
前面我说了,日志级别调整到 Debug 也许会有意外发现。现在,我要再给你说一句,如果 Debug 没有查到信息,可以试着调整到 trace:
logging.level.root=trace
比如,当我们调整到 trace 之后,就可以看到“ winner 到底是谁”这样的信息了:
当然了,trace 级别下日志更多了。
所以,来,再跟我大声的读一遍:
啃源码的过程,一定是非常枯燥的,特别是啃自己接触不多的框架源码的时候,千头万绪,也得下手去捋,所以一定要耐得住寂寞才行。
作业
我前面主要是试图教你一种阅读源码时,寻找突破点的技能。这个突破点,说白了就是第一个有效的断点到底应该打在哪里。
你用前面我教的方法,也能把 @Cacheable 和 @Async 都玩明白。因为它们的底层逻辑和 @Transactional 是一样的。
所以,现在布置两个作业。
拿着这套组合拳,去上手玩一玩 @Cacheable 和 @Async 吧,沉淀出属于自己的方法论。

@Cacheable:
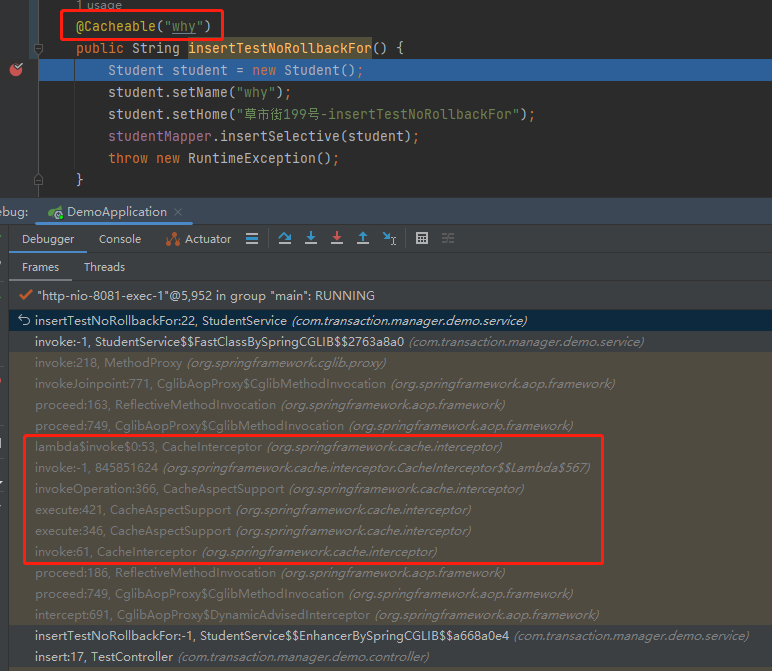
@Async:
最后,再附上几个我之前写过的文章,里面也用到了前面提到的几个方法定位源码,老舒服了。有兴趣可以看看:
《我是真没想到,这个面试题居然从11年前就开始讨论了,而官方今年才表态。》
《关于Request复用的那点破事儿。研究明白了,给你汇报一下。》
好了,本文就到这里啦。如果你觉得对你有一丝丝帮助的话,求个免费的赞,不过分吧?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号