没有二十年功力,写不出Thread.sleep(0)这一行“看似无用”的代码!
你好呀,我是喜提七天居家隔离的歪歪。
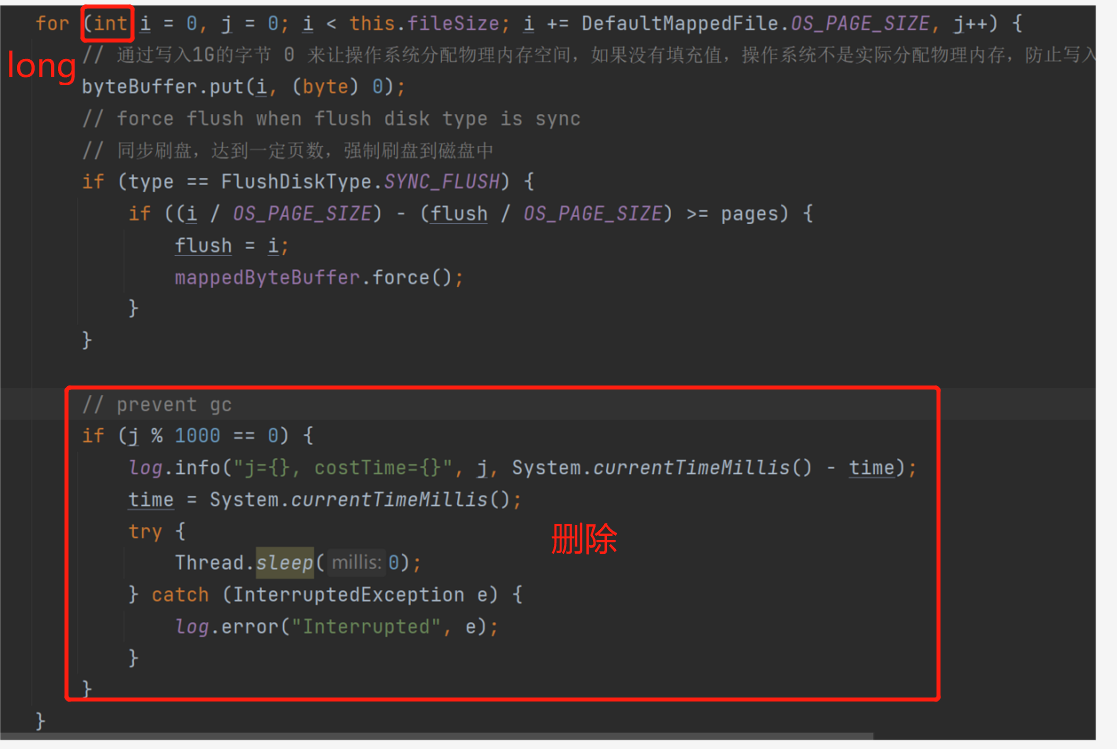
这篇文章要从一个奇怪的注释说起,就是下面这张图:
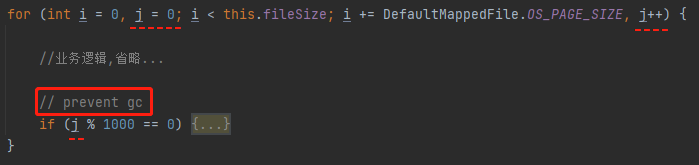
我们可以不用管具体的代码逻辑,只是单单看这个 for 循环。
在循环里面,专门有个变量 j,来记录当前循环次数。
第一次循环以及往后每 1000 次循环之后,进入一个 if 逻辑。
在这个 if 逻辑之上,标注了一个注释:prevent gc.
prevent,这个单词如果不认识的同学记一下,考试肯定要考的:
这个注释翻译一下就是:防止 GC 线程进行垃圾回收。
具体的实现逻辑是这样的:
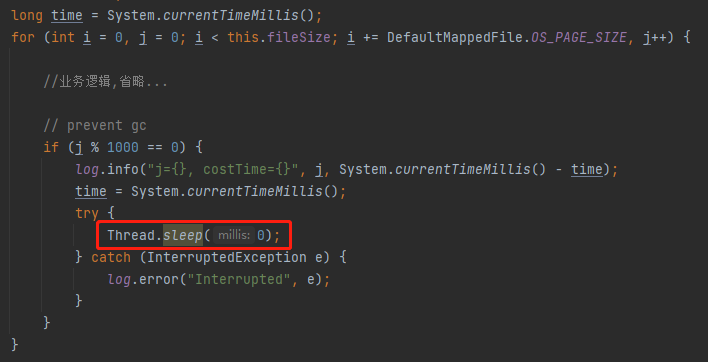
核心逻辑其实就是这样一行代码:
Thread.sleep(0);
这样就能实现 prevent gc 了?

懵逼吗?
懵逼就对了,懵逼就说明值得把玩把玩。
这个代码片段,其实是出自 RocketMQ 的源码:
org.apache.rocketmq.store.logfile.DefaultMappedFile#warmMappedFile
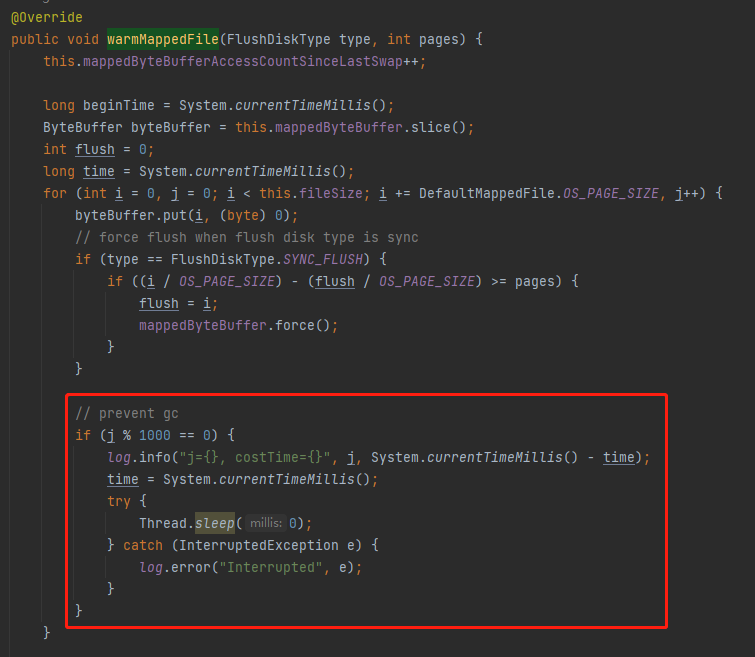
事先需要说明的是,我并没有找到写这个代码的人问他的意图是什么,所以我只有基于自己的理解去推测他的意图。如果推测的不对,还请多多指教。
虽然这是 RocketMQ 的源码,但是基于我的理解,这个小技巧和 RocketMQ 框架没有任何关系,完全可以脱离于框架存在。
我给出的修改意见是这样的:
把 int 修改为 long,然后就可以直接把 for 循环里面的 if 逻辑删除掉了。
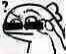
这样一看是不是更加懵逼了?
不要慌,接下来,我给你抽丝剥个茧。
另外,在“剥茧”之前,我先说一下结论:
提出这个修改方案的理论立足点是 Java 的安全点相关的知识,也就是 safepoint。 官方最后没有采纳这个修改方案。 官方采没采纳不重要,重要的是我高低得给你“剥个茧”。

探索
当我知道这个代码片段是属于 RocketMQ 的时候,我想到的第一个点就是从代码提交记录中寻找答案。
看提交者是否在提交代码的时候说明了自己的意图。
于是我把代码拉了下来,一看提交记录是这样的:
我就知道这里不会有答案了。
因为这个类第一次提交的时候就已经包含了这个逻辑,而且对应这次提交的代码也非常多,并没有特别说明对应的功能。
从提交记录上没有获得什么有用的信息。
于是我把目光转向了 github 的 issue,拿着关键词 prevent gc 搜索了一番。
除了第一个链接之外,没有找到什么有用的信息:
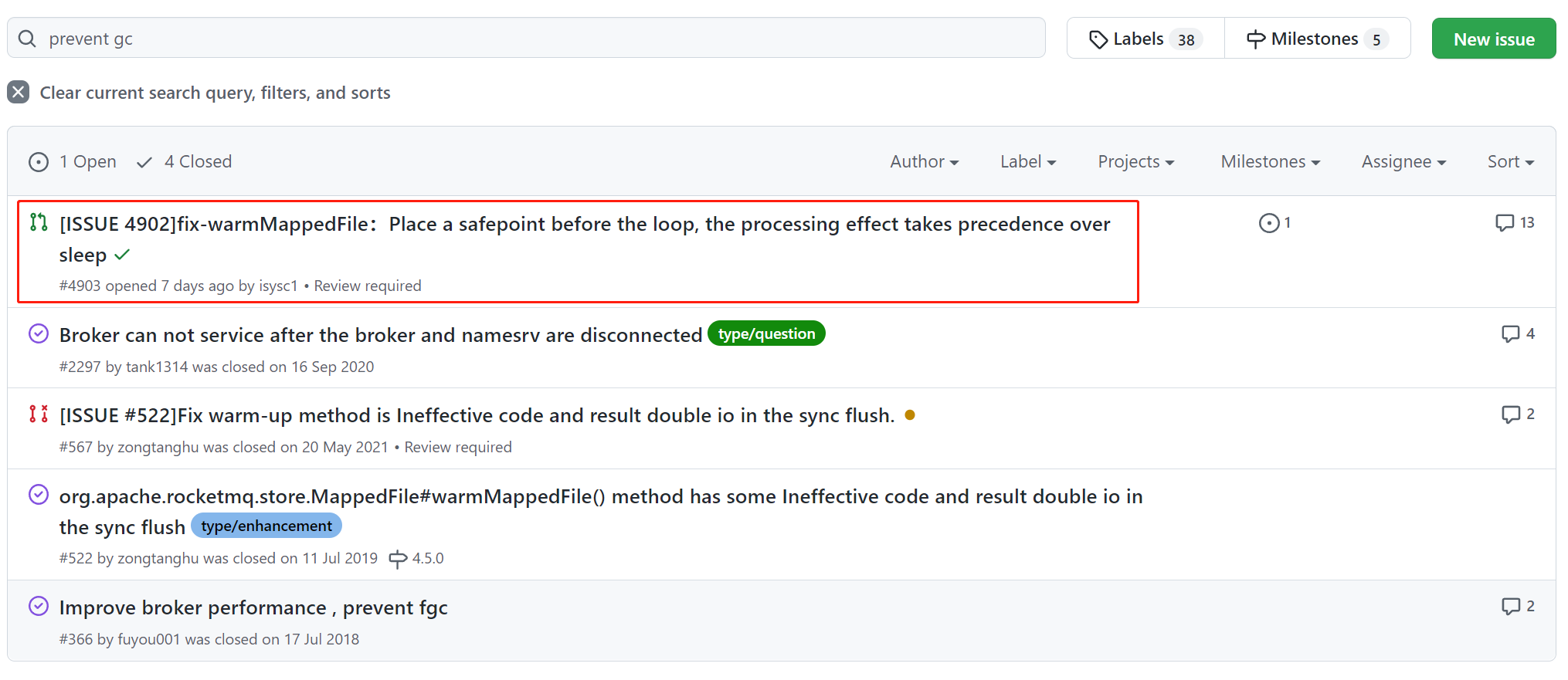
而第一个链接对应的 issues 是这个:
https://github.com/apache/rocketmq/issues/4902
这个 issues 其实就是我们在讨论这个问题的过程中提出来的,也就是前面出现的修改方案:
也就是说,我想通过源码或者 github 找到这个问题权威的回答,是找不到了。
于是我又去了这个神奇的网站,在里面找到了这个 2018 年提出的问题:
https://stackoverflow.com/questions/53284031/why-thread-sleep0-can-prevent-gc-in-rocketmq
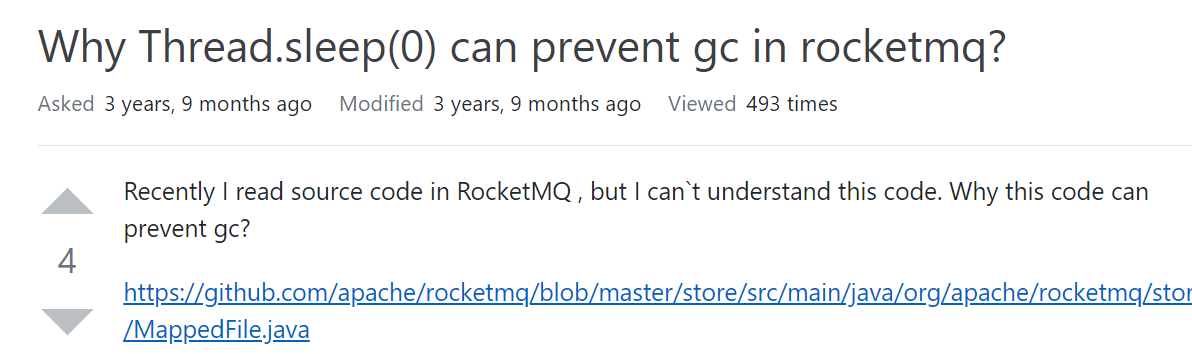
问题和我们的问题一模一样,但是这个问题下面就这一个回答:
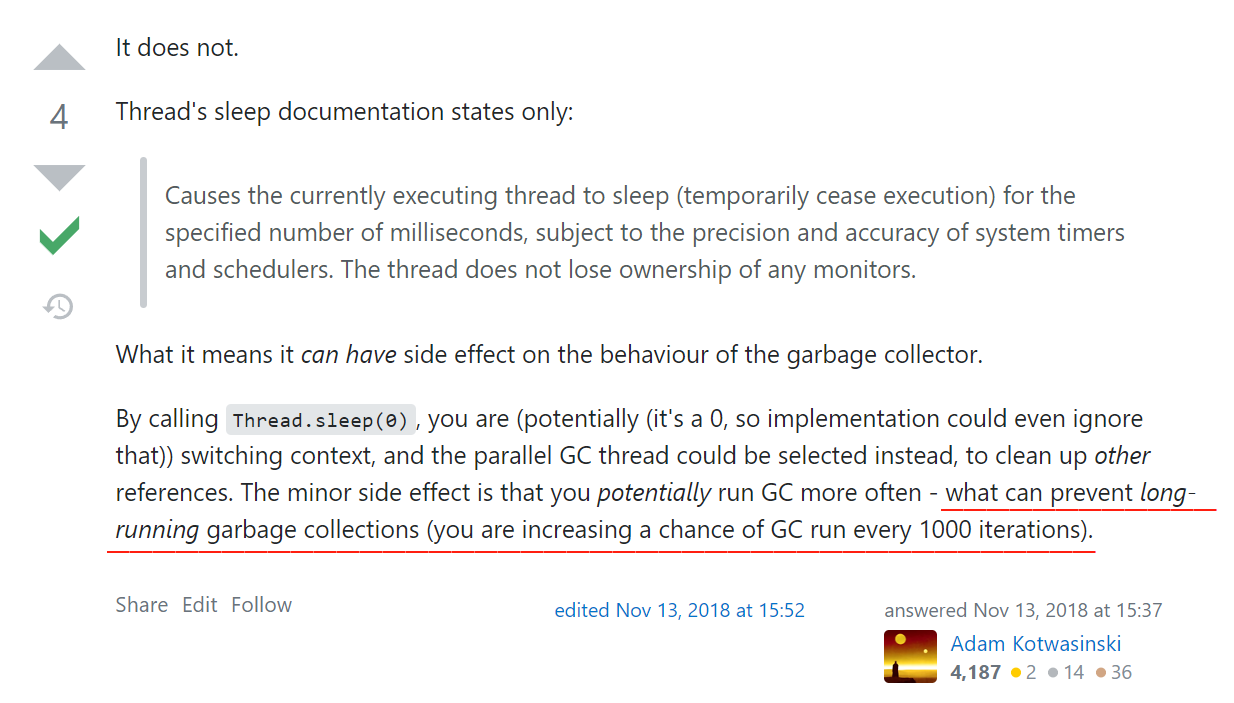
这个回答并不好,因为我觉得没答到点上,但是没关系,我刚好可以把这个回答作为抓手,把差的这一点拉通对齐一下,给它赋能。
先看这个回答的第一句话:It does not(它没有)。
问题就来了:“它”是谁?“没有”什么?
“它”,指的就是我们前面出现的代码。
“没有”,是说没有防止 GC 线程进行垃圾回收。
这个的回答说:通过调用 Thread.sleep(0) 的目的是为了让 GC 线程有机会被操作系统选中,从而进行垃圾清理的工作。它的副作用是,可能会更频繁地运行 GC,毕竟你每 1000 次迭代就有一次运行 GC 的机会,但是好处是可以防止长时间的垃圾收集。
换句话说,这个代码是想要“触发”GC,而不是“避免”GC,或者说是“避免”时间很长的 GC。从这个角度来说,程序里面的注释其实是在撒谎或者没写完整。
不是 prevent gc,而是对 gc 采取了“打散运行,削峰填谷”的思想,从而 prevent long time gc。
但是你想想,我们自己编程的时候,正常情况下从来也没冒出过“这个地方应该触发一下 GC”这样想法吧?
因为我们知道,Java 程序员来说,虚拟机有自己的 GC 机制,我们不需要像写 C 或者 C++ 那样得自己管理内存,只要关注于业务代码即可,并没有特别注意 GC 机制。
那么本文中最关键的一个问题就来了:为什么这里要在代码里面特别注意 GC,想要尝试“触发”GC 呢?

先说答案:safepoint,安全点。
关于安全点的描述,我们可以看看《深入理解JVM虚拟机(第三版)》的 3.4.2 小节:

注意书里面的描述:
有了安全点的设定,也就决定了用户程序执行时并非在代码指令流的任意位置都能够停顿下来开始垃圾收集,而是强制要求必须执行到达安全点后才能够暂停。
换言之:没有到安全点,是不能 STW,从而进行 GC 的。
如果在你的认知里面 GC 线程是随时都可以运行的。那么就需要刷新一下认知了。
接着,让我们把目光放到书的 5.2.8 小节:由安全点导致长时间停顿。
里面有这样一段话:

我把划线的部分单独拿出来,你仔细读一遍:
是HotSpot虚拟机为了避免安全点过多带来过重的负担,对循环还有一项优化措施,认为循环次数较少的话,执行时间应该也不会太长,所以使用int类型或范围更小的数据类型作为索引值的循环默认是不会被放置安全点的。这种循环被称为可数循环(Counted Loop),相对应地,使用long或者范围更大的数据类型作为索引值的循环就被称为不可数循环(Uncounted Loop),将会被放置安全点。
意思就是在可数循环(Counted Loop)的情况下,HotSpot 虚拟机搞了一个优化,就是等循环结束之后,线程才会进入安全点。
反过来说就是:循环如果没有结束,线程不会进入安全点,GC 线程就得等着当前的线程循环结束,进入安全点,才能开始工作。
什么是可数循环(Counted Loop)?
书里面的这个案例来自于这个链接:
https://juejin.cn/post/6844903878765314061
HBase实战:记一次Safepoint导致长时间STW的踩坑之旅
如果你有时间,我建议你把这个案例完整的看一下,我只截取问题解决的部分:
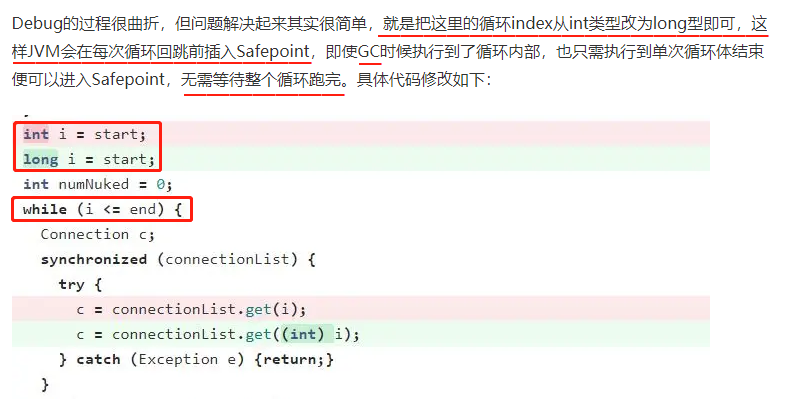
截图中的 while(i < end) 就是一个可数循环,由于执行这个循环的线程需要在循环结束后才进入 Safepoint,所以先进入 Safepoint 的线程需要等待它。从而影响到 GC 线程的运行。
所以,修改方案就是把 int 修改为 long。
原理就是让其变为不可数循环(Uncounted Loop),从而不用等循环结束,在循环期间就能进入 Safepoint。
接着我们再把目光拉回到这里:
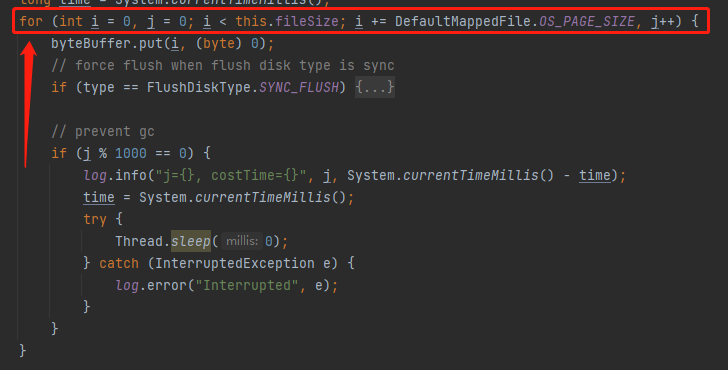
这个循环也是一个可数循环。
Thread.sleep(0) 这个代码看起来莫名其妙,但是我是不是可以大胆的猜测一下:故意写这个代码的人,是不是为了在这里放置一个 Safepoint 呢,以达到避免 GC 线程长时间等待,从而加长 stop the world 的时间的目的?
所以,我接下来只需要找到 sleep 会进入 Safepoint 的证据,就能证明我的猜想。
你猜怎么着?
本来是想去看一下源码,结果啪的一下,在源码的注释里面,直接找到了:
https://hg.openjdk.java.net/jdk8u/jdk8u/hotspot/file/tip/src/share/vm/runtime/safepoint.cpp

注释里面说,在程序进入 Safepoint 的时候, Java 线程可能正处于框起来的五种不同的状态,针对不同的状态有不同的处理方案。
本来我想一个个的翻译的,但是信息量太大,我消化起来有点费劲儿,所以就不乱说了。
主要聚焦于和本文相关的第二点:Running in native code。
When returning from the native code, a Java thread must check the safepoint _state to see if we must block.
第一句话,就是答案,意思就是一个线程在运行 native 方法后,返回到 Java 线程后,必须进行一次 safepoint 的检测。
同时我在知乎看到了 R 大的这个回答,里面有这样一句,也印证了这个点:
https://www.zhihu.com/question/29268019/answer/43762165

那么接下来,就是见证奇迹的时刻了:
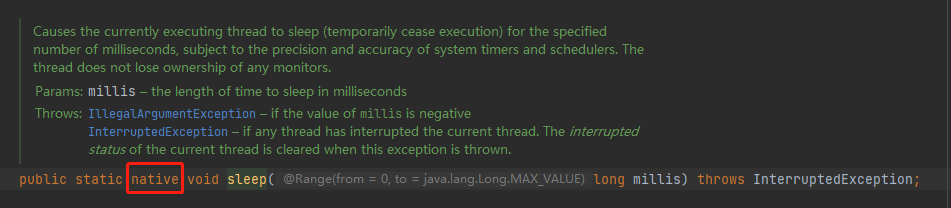
根据 R 大的说法:正在执行 native 函数的线程看作“已经进入了safepoint”,或者把这种情况叫做“在safe-region里”。
sleep 方法就是一个 native 方法,你说巧不巧?
所以,到这里我们可以确定的是:调用 sleep 方法的线程会进入 Safepoint。
另外,我还找到了一个 2013 年的 R 大关于类似问题讨论的帖子:
https://hllvm-group.iteye.com/group/topic/38232?page=2
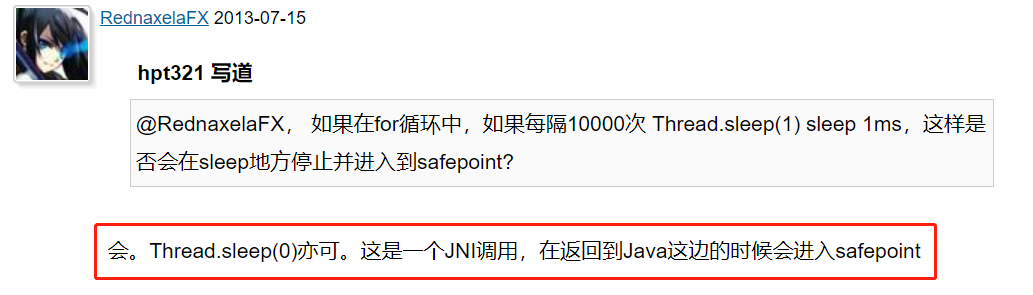
这里就直接点名道姓的指出了:Thread.sleep(0).
这让我想起以前有个面试题问:Thread.sleep(0) 有什么用。
当时我就想:这题真难(S)啊(B)。现在发现原来是我道行不够,小丑竟是我自己。
还真的是有用。
实践
前面其实说的都是理论。
这一部分我们来拿代码实践跑上一把,就拿我之前分享过的《真是绝了!这段被JVM动了手脚的代码!》文章里面的案例。
public class MainTest {
public static AtomicInteger num = new AtomicInteger(0);
public static void main(String[] args) throws InterruptedException {
Runnable runnable=()->{
for (int i = 0; i < 1000000000; i++) {
num.getAndAdd(1);
}
System.out.println(Thread.currentThread().getName()+"执行结束!");
};
Thread t1 = new Thread(runnable);
Thread t2 = new Thread(runnable);
t1.start();
t2.start();
Thread.sleep(1000);
System.out.println("num = " + num);
}
}
这个代码,你直接粘到你的 idea 里面去就能跑。
按照代码来看,主线程休眠 1000ms 后就会输出结果,但是实际情况却是主线程一直在等待 t1,t2 执行结束才继续执行。
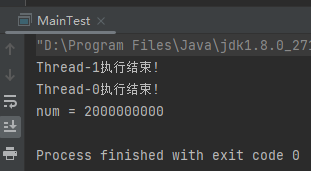
这个循环就属于前面说的可数循环(Counted Loop)。
这个程序发生了什么事情呢?
1.启动了两个长的、不间断的循环(内部没有安全点检查)。 2.主线程进入睡眠状态 1 秒钟。 3.在1000 ms之后,JVM尝试在Safepoint停止,以便Java线程进行定期清理,但是直到可数循环完成后才能执行此操作。 4.主线程的 Thread.sleep 方法从 native 返回,发现安全点操作正在进行中,于是把自己挂起,直到操作结束。
所以,当我们把 int 修改为 long 后,程序就表现正常了:
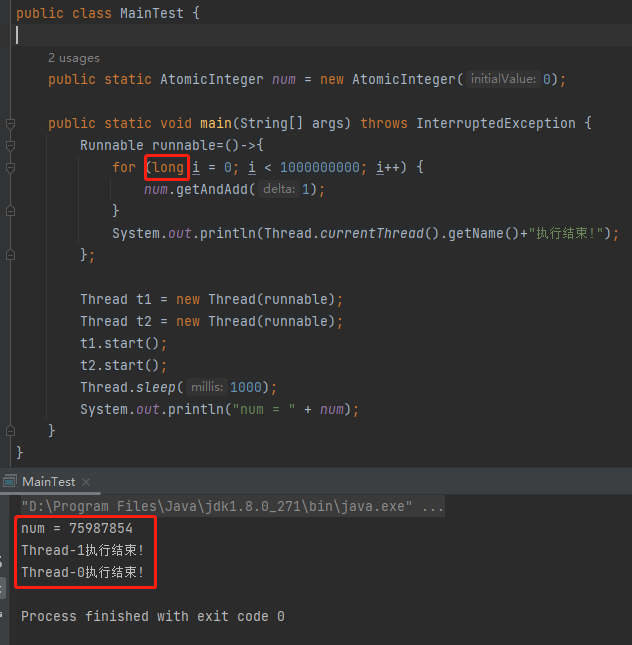
受到 RocketMQ 源码的启示,我们还可以直接把它的代码拿过来:
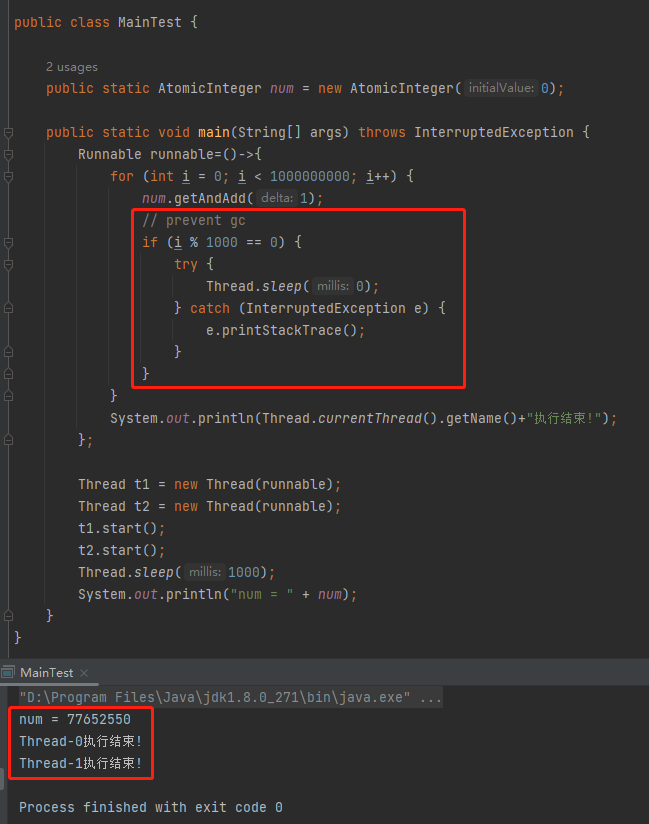
这样,即使 for 循环的对象是 int 类型,也可以按照预期执行。因为我们相当于在循环体中插入了 Safepoint。
另外,我通过不严谨的方式测试了一下两个方案的耗时:
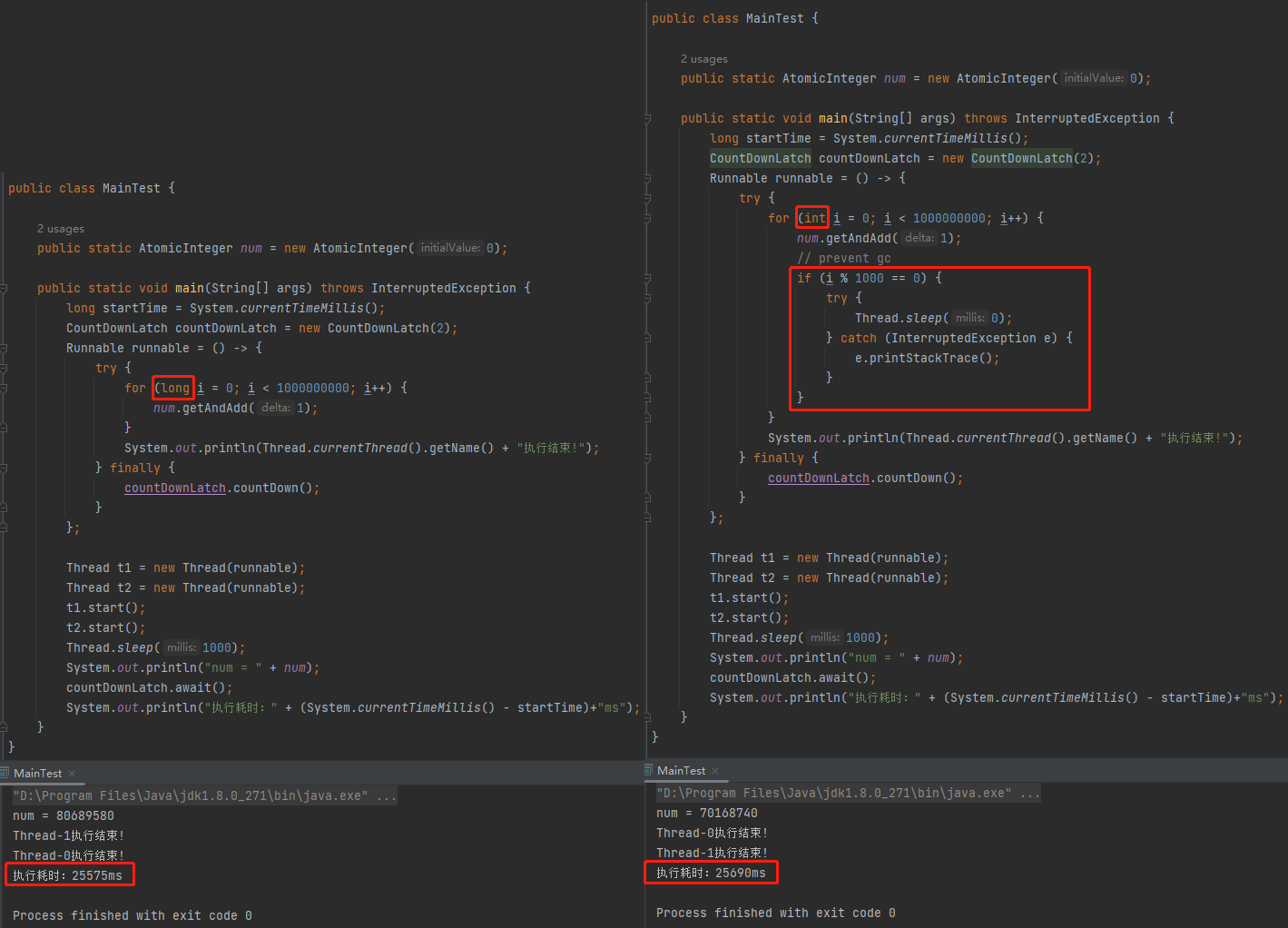
在我的机器上运行了几次,时间上都差距不大。
但是要论逼格的话,还得是右边的 prevent gc 的写法。没有二十年功力,写不出这一行“看似无用”的代码!
额外提一句
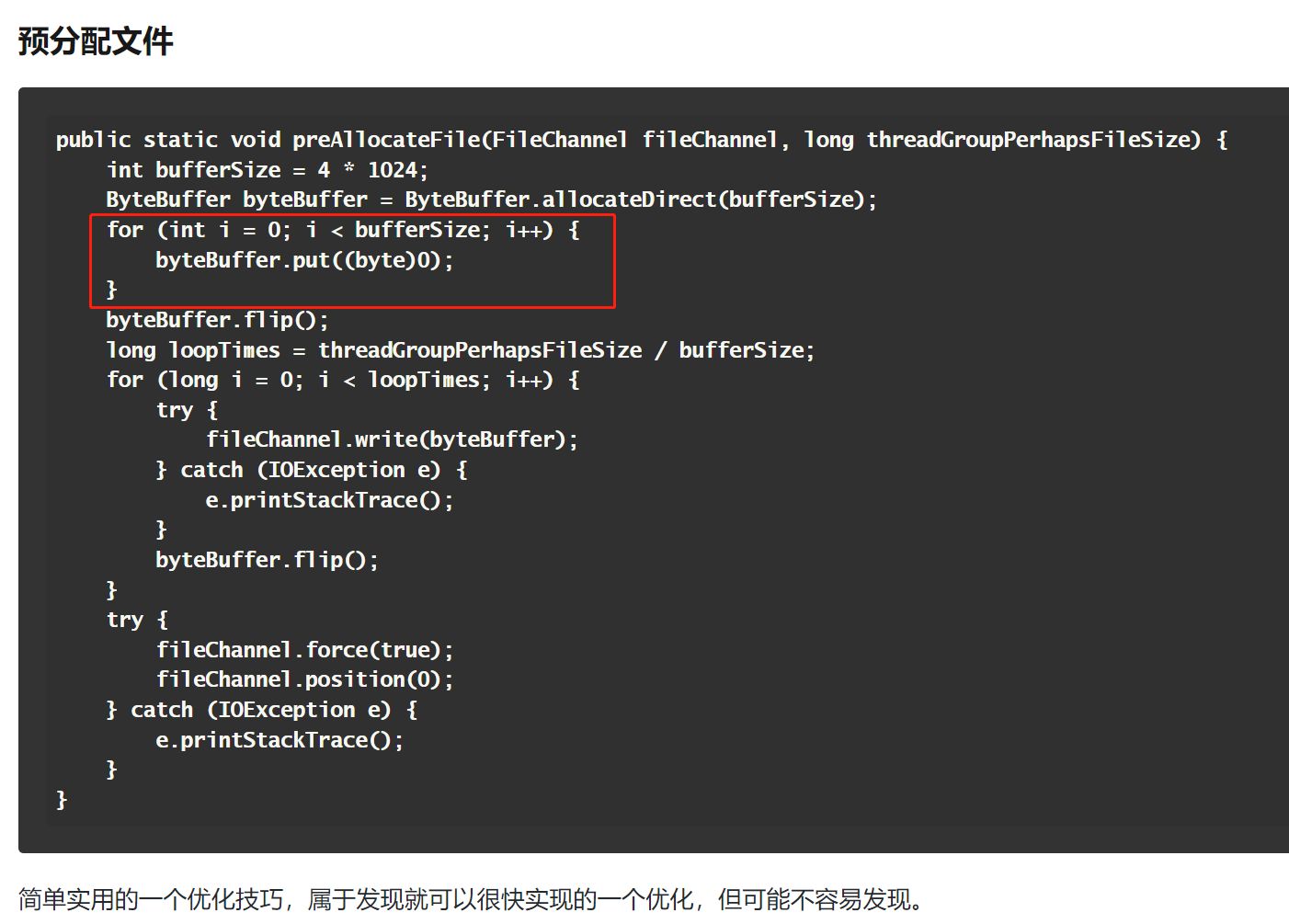
再说一个也是由前面的 RocketMQ 的源码引起的一个思考:
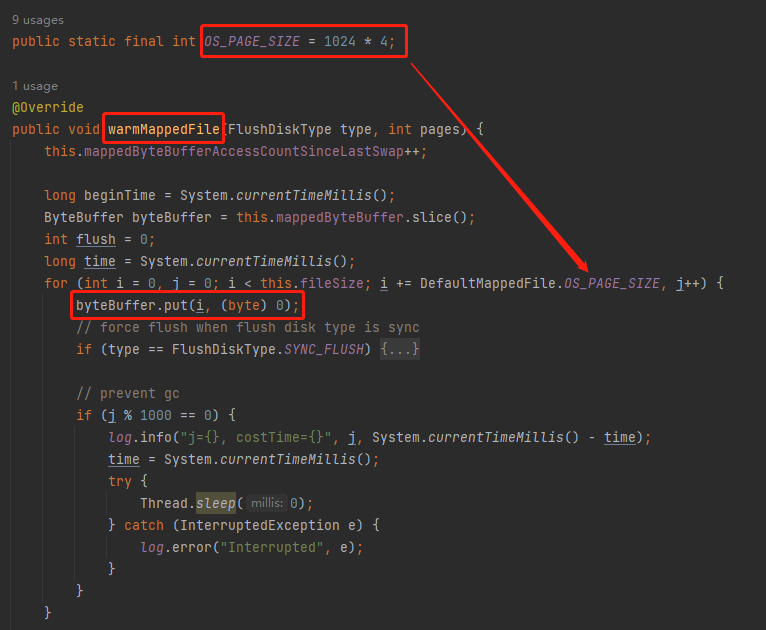
这个方法是在干啥?
预热文件,按照 4K 的大小往 byteBuffer 放 0,对文件进行预热。
byteBuffer.put(i, (byte) 0);
为什么我会对这个 4k 的预热比较敏感呢?
去年的天池大赛有这样的一个赛道:
https://tianchi.aliyun.com/competition/entrance/531922/information

其中有两个参赛选大佬都提到了“文件预热”的思路。
我把链接放在下面了,有兴趣的可以去细读一下:
https://tianchi.aliyun.com/forum/postDetail?spm=5176.12586969.0.0.13714154spKjib&postId=300892

https://tianchi.aliyun.com/forum/postDetail?spm=5176.21852664.0.0.4c353a5a06PzVZ&postId=313716

最后,感谢你阅读我的文章。欢迎关注公众号【why技术】,文章全网首发哦。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号