啥是Gossip协议?
你好呀,我是歪歪。
元旦的时候我看到一个特别离谱的谣言啊,具体是什么内容我就不说了,我怕脏了大家的眼睛。
但是,我看到一个群里传的那叫一个绘声绘色,大家讨论的风生水起的,仿佛大家就在现场似的。
这事吧本来我呵呵一笑也就过了。但是隔了一会我突然大腿一拍:这是个素材啊。

我可以和大家聊一个共识算法呀。
说到共识算法,大家首先想到的应该都是 Raft、Paxos、Zab 算法这类理解起来比较困难的强一致性算法。
但是还有一个弱一致性的共识算法比较好理解,Gossip 协议。
Gossip,先看这个单词,圈起来,要考的啊,这是一个六级词汇,也是考研单词,意思是“流言蜚语”。

接下来就带你简单的看看这个“流言蜚语”到底是怎么回事。
Gossip 协议
Gossip 协议最早提出的时间得追溯到 1987 年发布的一篇论文:《Epidemic Algorithms for Replicated Database Maintenance》
http://bitsavers.trailing-edge.com/pdf/xerox/parc/techReports/CSL-89-1_Epidemic_Algorithms_for_Replicated_Database_Maintenance.pdf
我第一次看到这个论文的名字的时候,我都懵逼了:这也没有 Gossip 的关键词呢。
主要是 Epidemic Algorithms 这两个单词,我又恰好认识。
Algorithms,算法,没啥说的。
Epidemic 是啥?
紧扣当下时事:

所以 Epidemic Algorithms 翻译过来就是流行病算法。
因此 Gossip 的学名应该是又叫做“流行病算法”,只是大家更喜欢叫它 Gossip 而已。毕竟,虽不喜欢听点儿“小道消息”呢?

说论文之前,先简单定个基调。
你觉得一致性协议最基础、最核心、最重要的一个动作是什么?
是不是数据更新?
为了保证各个节点的数据的一致性,必然就涉及到数据的更新操作。
所以,在论文的开篇介绍部分描述了三种方法来进行数据的更新:

Direct mail(直接邮件) Anti-entropy(反熵) Rumor mongering(传谣)
Direct mail(直接邮寄)
废话先不说了,直接上个图:
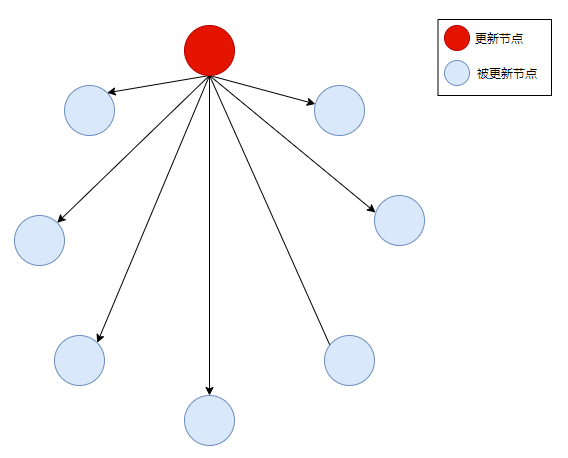
上面这图啥意思呢?
就是一共八个小圆点,假设每个都代表一个服务器,它们之间都是平等的关系,不存在中心节点、主从什么的关系。
其中最上面的红色节点表示该节点有数据变更了,于是把变更的数据直接通知给剩下的节点。
如果其他的节点上发生了数据变更也是同样的道理。
可以简单的理解为一个循环遍历,每发生一次数据变更,为了保持数据的一致性,就得进行一次循环遍历。
这个方案的优点很明显:简单、粗暴、直接。
但是缺点和优点一样明显,我们看看论文里面怎么说:

主要看 but 的部分:
首先不完全可靠,因为这个要求每个站点都必须知道所有站点的存在。但是实际情况是有的站点并不总是知道所有其他站点。
然后,信息(mail)有时会丢失,一旦丢失,就连最终一致性也保证不了,整个凉凉。
其实 Direct mail(直接邮寄)并不是论文里面主要讨论的方案,把它写在第一个起一个抛砖引玉的作用。
主要聊聊 Anti-entropy(反熵)和 Rumor-Mongering(传谣)这两个方案。
先定个整体的基调:
Anti-entropy(反熵),是传播节点上的所有的数据 Rumor-Mongering(传谣),是传播节点上的新到达的、或者变更的数据
说白了,一个是全量,一个是增量。
Anti-entropy(反熵)
部分同学可能对“反熵”这个词感到莫名其妙哈,其实主要是不了解啥是“熵”。
其实说白了,“熵”的通俗理解就是“混乱程度”。
比如你的房间,如果你不去整理那么各自物品的摆放就会越来越混乱,也就是越来越“熵”。而你整理房间的这个操作就是“反熵”。
这个东西你可以简单的先这样理解,我一时半会也给你说不清楚,这东西要聊下去的话得上升到宇宙和哲学的高度。
我主要怕你听不懂。

在论文里面是这样的描述 Anti-entropy 模式的:

每个服务器有规律地随机选择另一个服务器,这二者通过交换各自的内容来抹平它们之间的所有差异,这种方案是非常可靠的。
(but 开始了)但需要检查各自服务器的全量内容,言外之意就是数据量略大,因此不能使用太频繁。
实验表明,反熵虽然可靠,但传播更新的速度比直接邮件慢得多。
如果不同步,那么两者之间的数据差异越来越大,也就是越来越熵。
同步的目的是缩小差异,达到最终一致性,这就是反熵。
定义就是这么个定义。
Rumor mongering(传谣)
比起反熵,传谣从字面上就很好理解了。
比如我是一个大学生,并不能完全认识整个学校的人。但是学校里面的同学之间都有千丝万缕的联系。
假设有一天,我刚好碰见校花一个人走在路上,我就上去和她讨论了一下计算机领域里面的共识算法等相关问题,关于这些问题我们进行了深入的讨论并且交换了彼此的理解和看法。
咱这边就是说,整个过程是越讨论越激烈,不知道怎么走着走着就走到了情人坡。
应该每个大学都有一个叫做情人坡的地方吧。
然后被别的妹子看见了。她就给她闺蜜说:你知道歪歪吗?对,就是大一新生,那个大帅比。我那会看到他和校花在情人坡那边溜达。
然后一传十、十传百。这个消息全校师生都知道了。
“歪歪和校花在情人坡那边溜达”这个消息就通过 gossip 的传谣模式,达到了最终一致性。
“传谣”和“反熵”的差别在于只传递新信息或者发生了变更的信息,而不需要传递全量的信息。
比如上面的这个例子中,只需要同步“歪歪和校花在情人坡那边溜达”这个最新的消息就行。
而不需要同步“歪歪是谁,校花是谁,情人坡在哪”等等这些之前大家早就达成一致性的信息。

在提到“传谣”和“反熵”的时候,论文中还有这么个定义:

simple epidemics:单纯性传染病
在这种模式下,包含两种状态:infective(传染性) 和 susceptible(易感染)。
处于 infective 状态的节点代表其有数据更新,需要把数据分享(传染)给其他的节点。
处于 susceptible 状态的节点代表它还没接受到其他节点的数据更新(没有被感染)。
所以,后面我提到“感染”的时候,你应该要知道我是从这里看到的,不是胡编的。
关于“传谣”和“反熵”,再借用周志明老师《凤凰架构》里面的正经一点的描述,是这样的:
http://icyfenix.cn/distribution/consensus/gossip.html
达到一致性耗费的时间与网络传播中消息冗余量这两个缺点存在一定对立,如果要改善其中一个,就会恶化另外一个。
由此,Gossip 设计了两种可能的消息传播模式:反熵(Anti-Entropy)和传谣(Rumor-Mongering),这两个名字都挺文艺的。
熵(Entropy)是生活中少见但科学中很常用的概念,它代表着事物的混乱程度。
反熵的意思就是反混乱,以提升网络各个节点之间的相似度为目标,所以在反熵模式下,会同步节点的全部数据,以消除各节点之间的差异,目标是整个网络各节点完全的一致。
但是,在节点本身就会发生变动的前提下,这个目标将使得整个网络中消息的数量非常庞大,给网络带来巨大的传输开销。
而传谣模式是以传播消息为目标,仅仅发送新到达节点的数据,即只对外发送变更信息,这样消息数据量将显著缩减,网络开销也相对较小。
一个网站
摊牌了,其实我是看到了这个网站,才决定写这篇文章的。
因为这个网站里面直接有非常仿真的动画模拟 gossip 协议的同步过程,一个动图胜过千言万语。
地址先放在这里,大家可以自己访问玩儿一下:
https://flopezluis.github.io/gossip-simulator/
先给你看一眼它的工作过程:
甭管看没看懂吧,这玩意至少看起来很厉害的样子。
接下来就给你介绍一下它是怎么玩的:
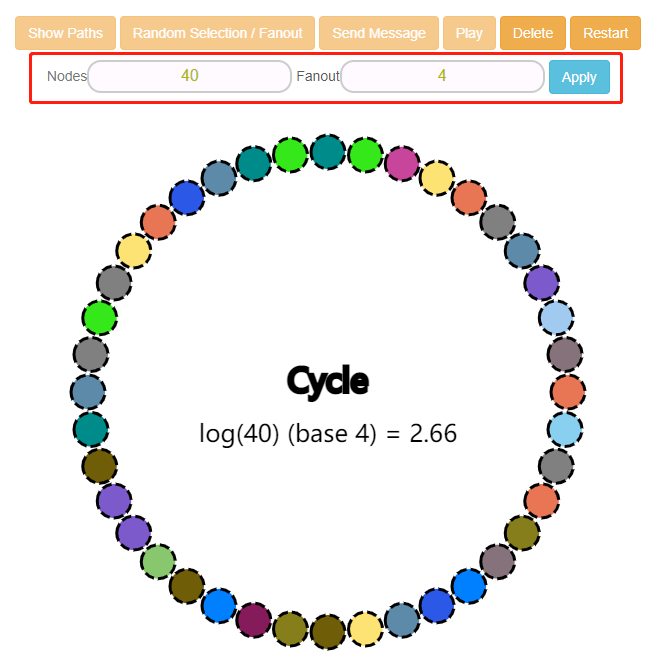
首先我们看这里的 Nodes 和 Fanout。
Nodes 其实很好理解,就是节点数,这里的 40 就代表下面的小圆圈的个数,比如我今年 18 岁,那么我把它改成 18 它就是这样的:

主要是这个 Fanout 是个啥玩意呢?
在这个网页的头部的轮播图里面,第一张图是这样的:
答案就藏在这个 Learn more 里面。
https://managementfromscratch.wordpress.com/2016/04/01/introduction-to-gossip/

这段话里面就解释了,什么是 Fanout。同时也简单的介绍了 gossip 协议的基本工作原理。
它说 gossip 协议在概念上非常简单,编码也非常简单。它们背后的基本想法是这样的:
一个节点想与网络中的其他节点分享一些信息。然后,它定期从节点集合中随机选择一个节点并交换信息,收到信息的节点也做同样的事情。
该信息定期发送到 N 个目标,N 被称为扇出(Fanout)。
所以,前面的 Fanout=4,含义就是某个节点,每次会把自己想要分享的信息同步给集群中的另外 4 个节点。
在模拟器中体现出来应该是这样的:
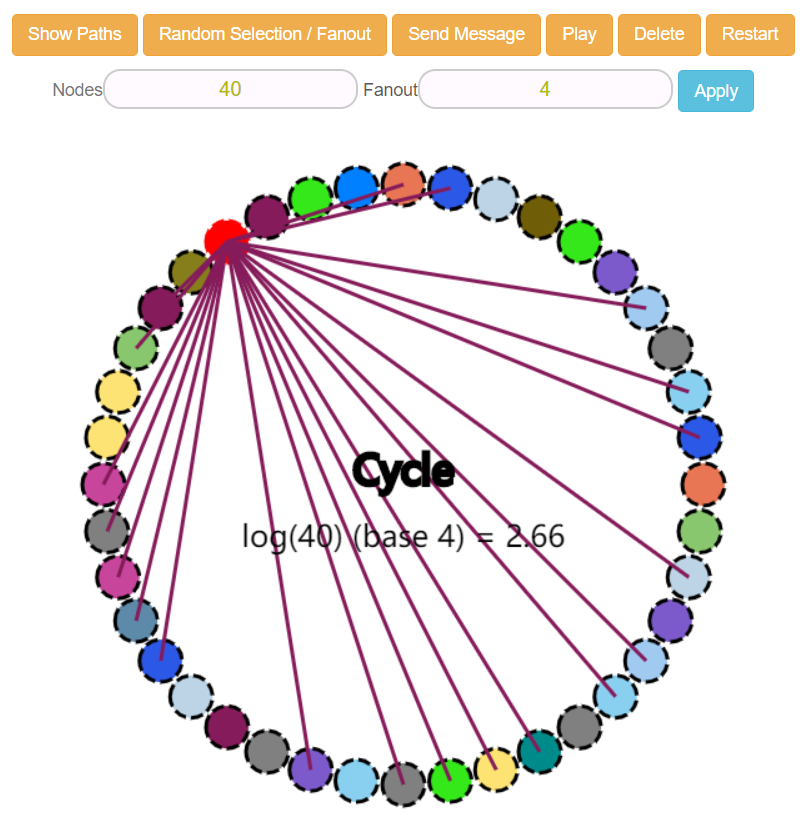
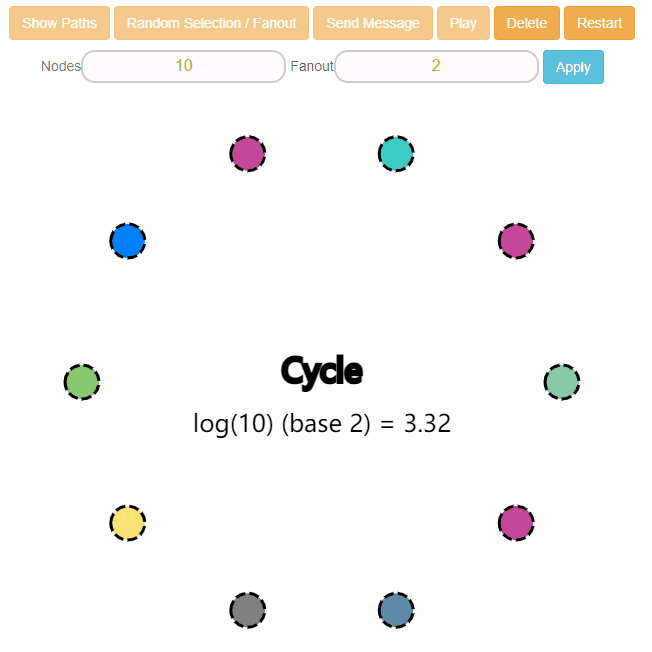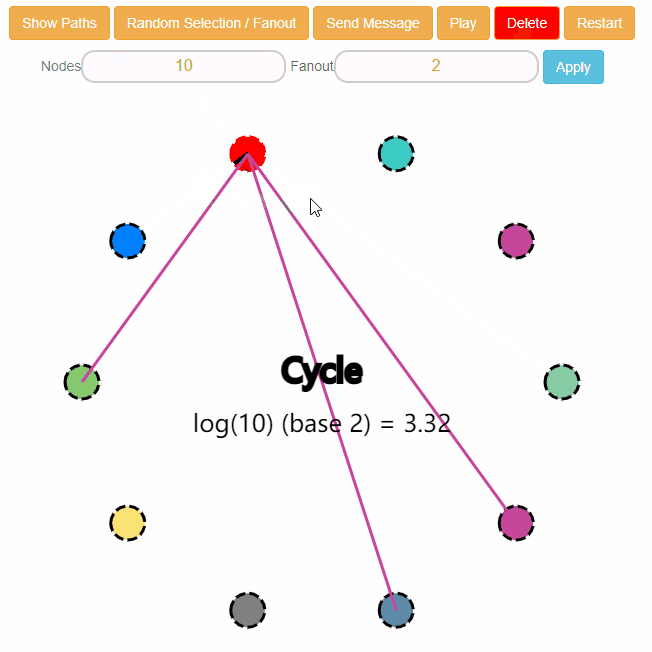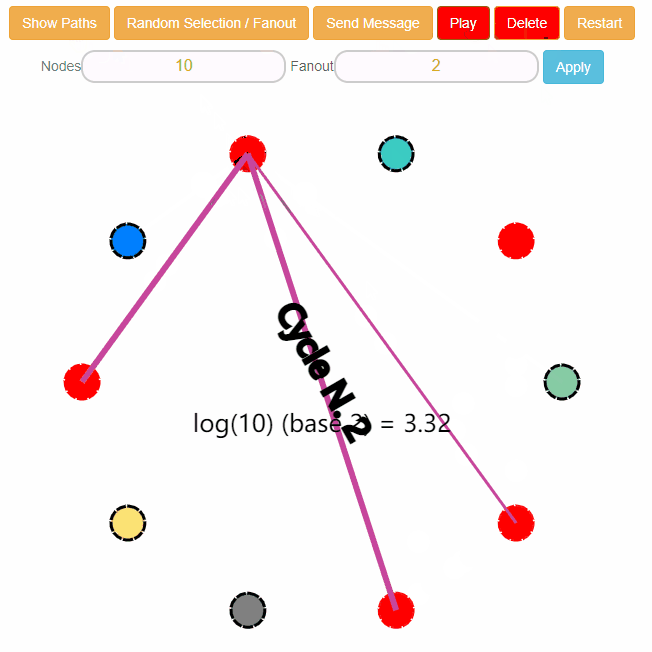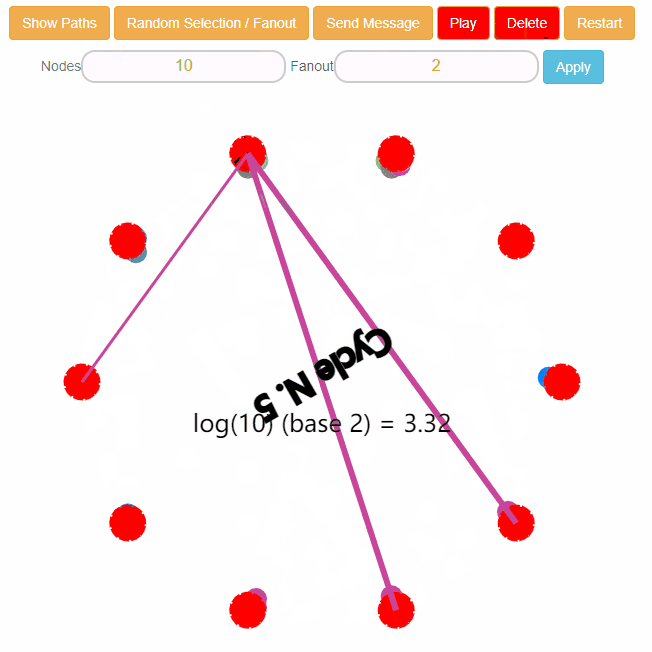
上面这个图你可以看到有很多线,但是它们的起点都是一个红色的节点。
这个红色的节点就是你用鼠标随意点击小圆圈中的一个或者多个都可以,鼠标一点击就会变成红色,就是完犊子了,红码了,表示“被感染”了。
上面的线条是怎么搞出来的呢?
有了一个红色的小圆圈之后,点击上面的“Show Paths”就会出现路径了:
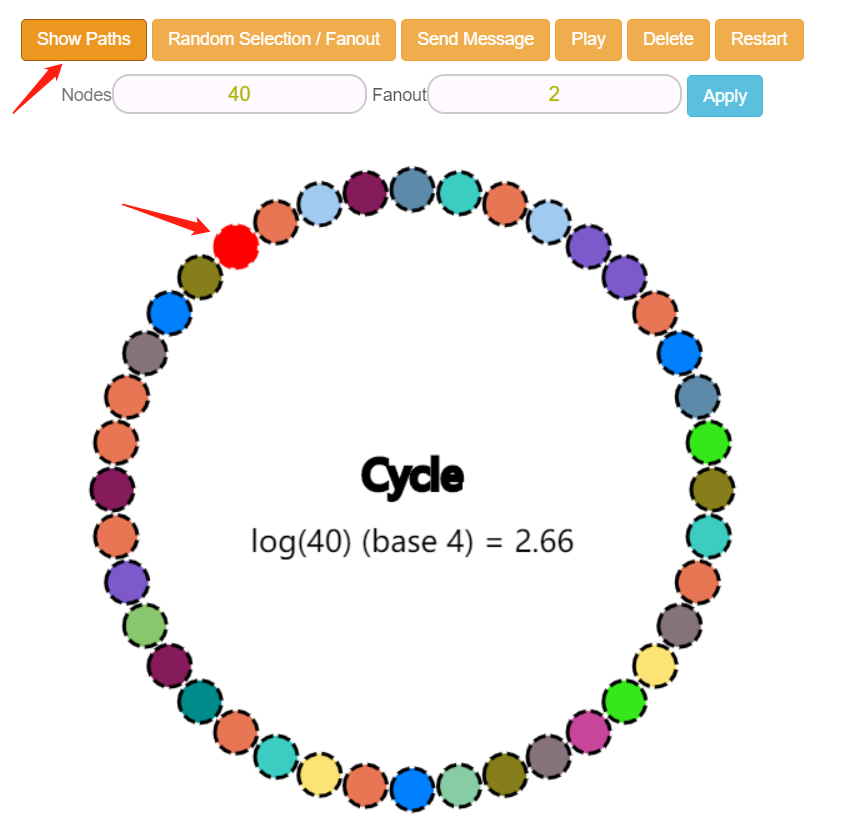
但是不是说好 Fanout=4 吗,为什么怎么多的路径?
因为,虽然这个节点知道这么多其他节点,但是它只会选择其中的 4 个进行感染。
上面这个图还是有点复杂,所以我把参数都调小一点,这样看起来就清爽多了:

集群中有一个节点的信息更新了,这个节点知道其他 5 个节点的存在,但是它只会把信息推送给其中的两个,点击 Send Message 按钮之后就会像是这样:
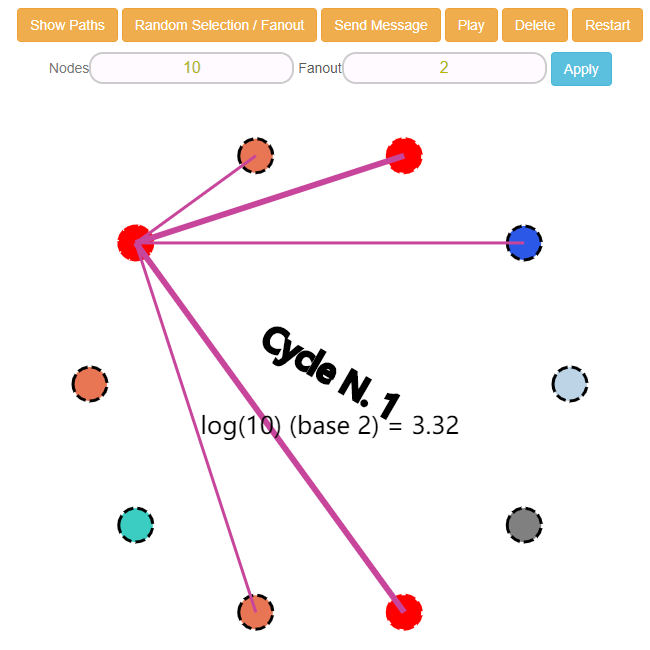
你可以发现上面这个图里面已经有三个红色的节点了,有两条路径变粗了,含义是从这个路径传播过来的。
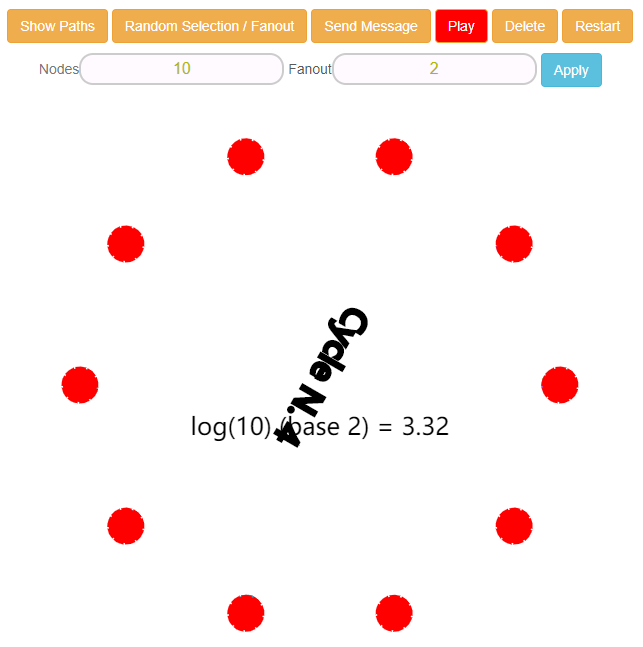
整个集群最终会全部完成“感染”,达成最终一致性:
同时,gossip 协议它也具备容错性:
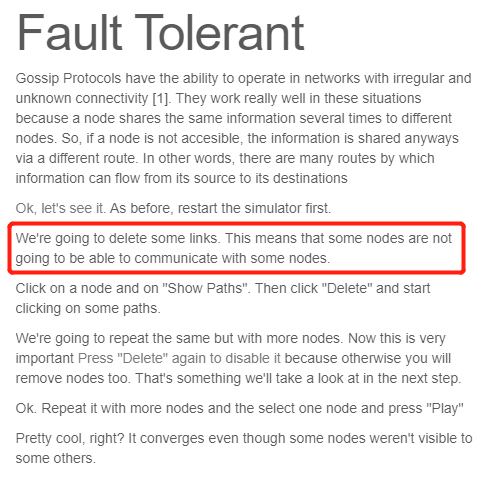
按照页面上的提示,我们是可以通过 “Delete” 按钮删除一部分路径的,比如下面这样:
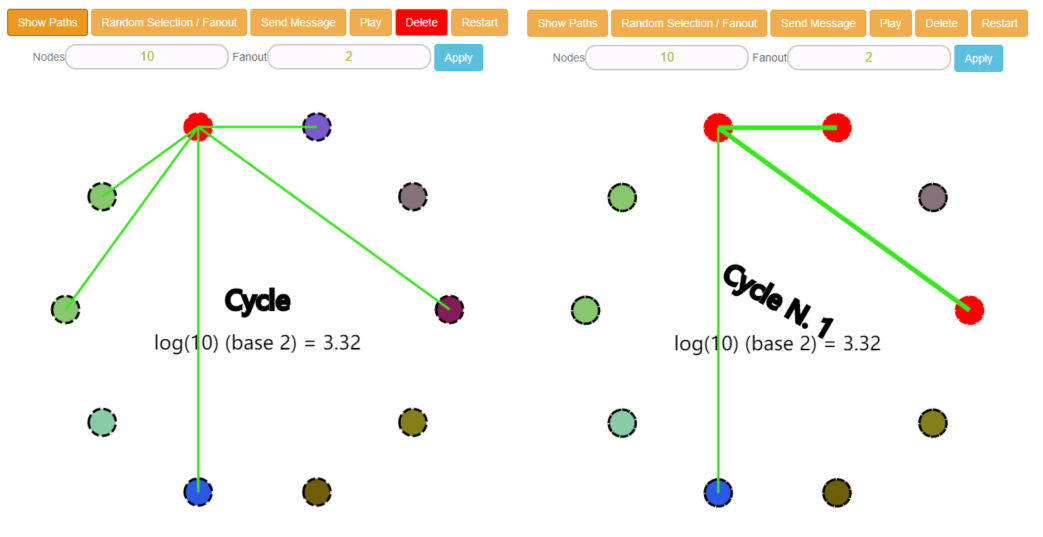
删除两个路径,代表这几个节点之间是不可达的,但是最终这个集群还是会全部被感染。
再来个动图演示一下,可以看到路径删除后,这个节点再也不会给对应的节点通讯,但是整个集群还是达到了收敛:
你自己也可以打开网站去玩一下,还有一个小技巧是这样的:

点击 Play 按钮,是可以随时暂停的,这样就更容易观察到整个传播的过程。
最后,关于这个图里面,还有一个关键的东西没有说,就是里面的这个公式:
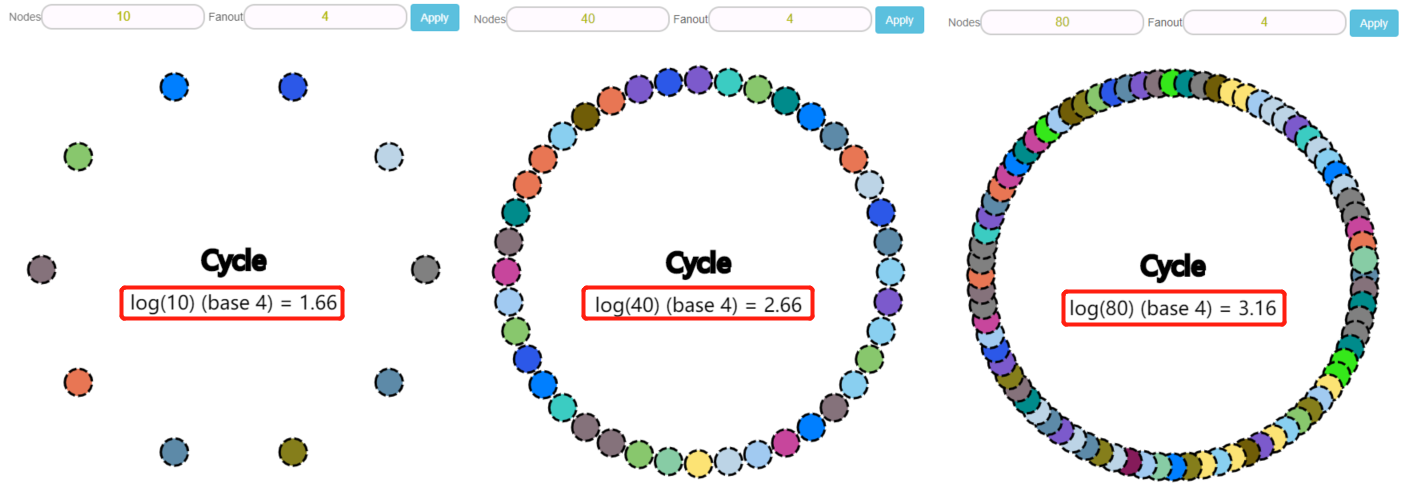
在 Learn More 里面也有提到这个公式,其实它就是 gossip 协议的复杂度,O(logN) :

比如,每次都设置为 Fanout=4,那么节点数和预估传播轮次之间的关系是这样的:
40 个节点,2.66 轮 80 个节点,3.16 轮 160 个节点,3.66 轮 320 个节点,4.16 轮 640 个节点,4.66 轮 ...
可以看到,随着节点数的翻倍增加,传播轮次并没有明显的增加。
这就是前面 Learn More 截图里面提到的这个词:Scalable
这是个四级词汇啊,会考的,记住了,是“可伸缩”的意思。
采用 gossip 协议的集群,Scalable is very 的 nice。

其他注意点
在这个网站上,最重要的就是它的动图模拟功能了,但是也不要忽略了它里面的其他部分的描述。
比如这一段话,我就觉得非常的重要。
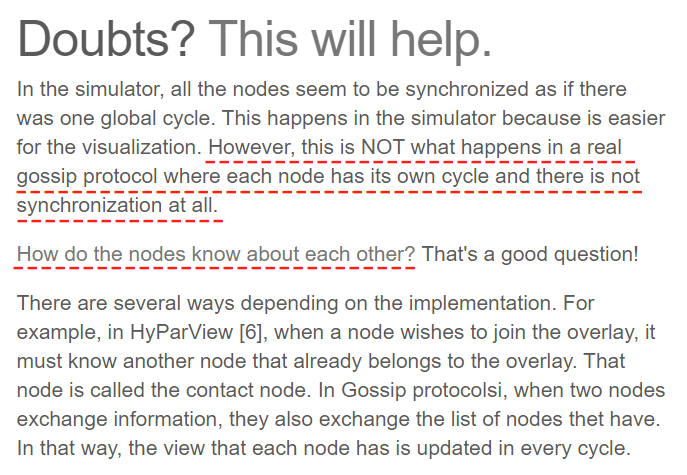
这一段话里面提到了两个问题,我一个个的说。
首先它说在网站模拟的过程中,所有节点发送消息似乎都是同步的,就像有一个全局循环一样。
在模拟中这样做,是因为这样看起来更加的直观。
但是,在一个真正的 gossip 协议中,每个节点都有自己的周期,它们之间根本没有也不需要同步。
上面是说什么意思呢?
我再说的直白一点,每个节点往外同步消息的时候,是按照自己的周期来处理的,比如每 10 秒一次。根本就不关心其他节点什么时候触发同步消息的操作,只需要管好自己就行了。
第二问题我认为就很重要了:
How do the nodes know about each other?
节点之间怎么知道其他节点的存在的?
其中一个方式就是当节点加入集群时,必须知道该集群中的一个节点的信息。通过前面的动图我们知道,如果一个节点被另外一个节点知道,那么它最终也一定会被感染。
那问题就来了:新节点加入时又是如何知道集群中一个节点信息的呢?
很简单,我知道的一个方案就是人工指定。
Redis 集群采用的就是 gossip 协议来交换信息。当有新节点要加入到集群的时候,需要用到一个 meet 命令。
http://www.redis.cn/commands/cluster-meet.html

这玩意就是人工指定。
还有一个可以注意一下的是这个:

这里提到了另外一个模拟的网站:
https://www.serf.io/docs/internals/simulator.html
它可以通过控制这几个参数,来测算集群达成一致性的时间。
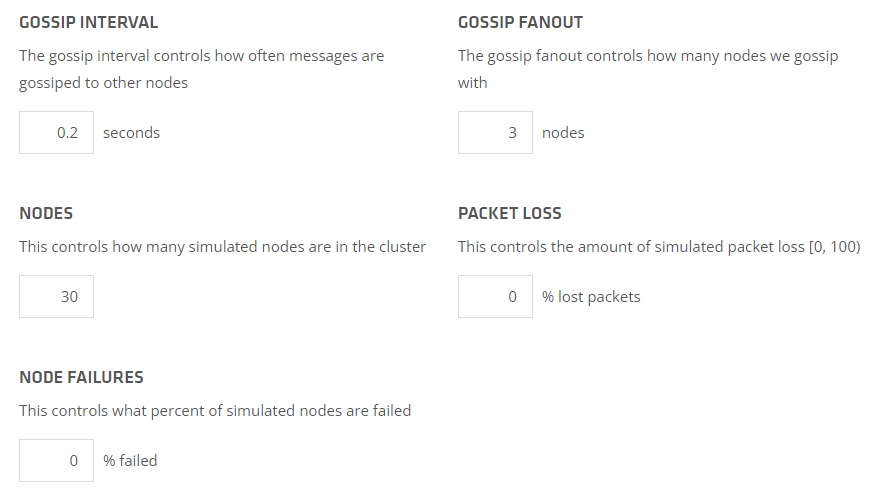
上面这个图表示的就是在信息交换频率(GOSSIP INTERVAL)为 0.2s,Fanout 节点数为 3,总节点数为 30,丢包率和节点失败率为 0 的这个情况。
在这个情况下,对应的到达最终一致性的时间图长这样:

基本上在一秒的时间就搞定了。
你也可以自己去修改一下参数,看看对应的时间图的变化。
比如,我只修改节点数,把它从 30 修改为 3000,时间图变成了这样:

在 1.75s 左右完成了收敛。
节点扩大 100 倍,但是时间增加不到 1s,确实是很优秀。
这玩意好是好,但是给你看个刺激的,来感受一下这恐怖的传播规模:
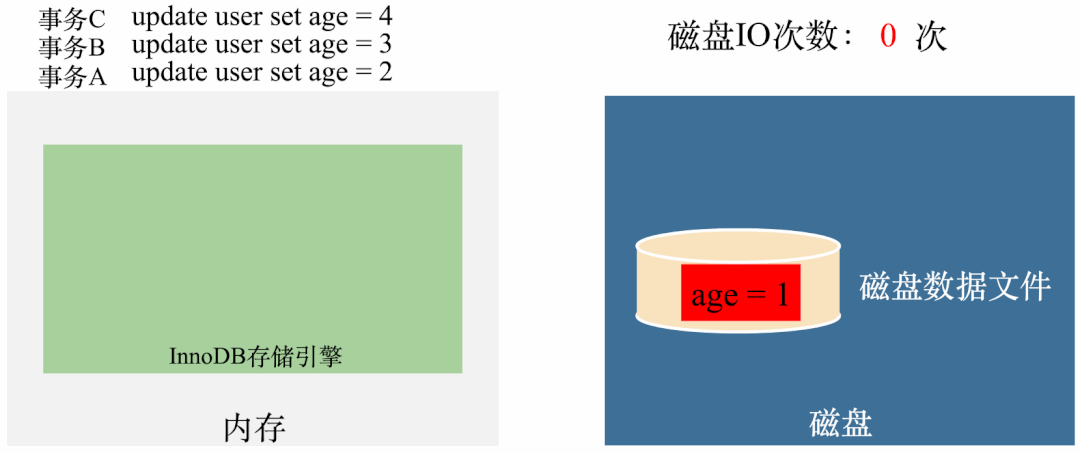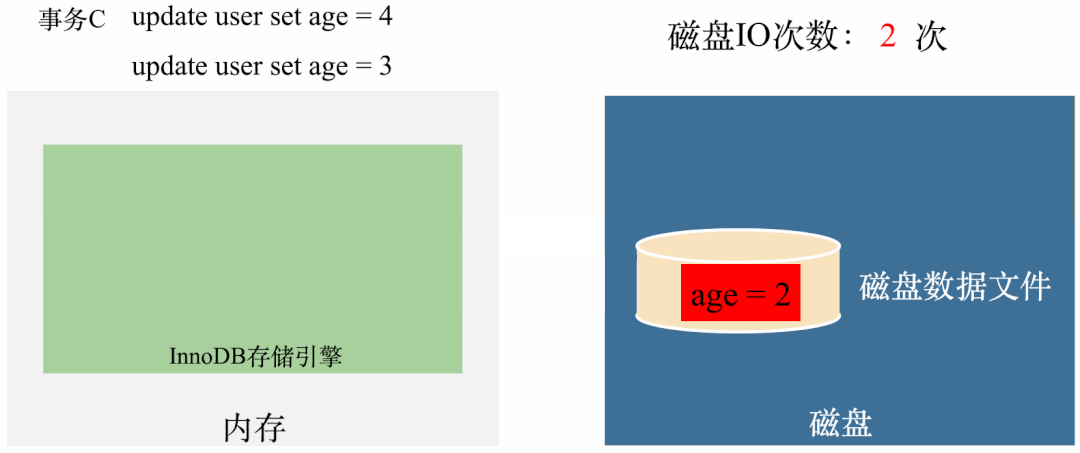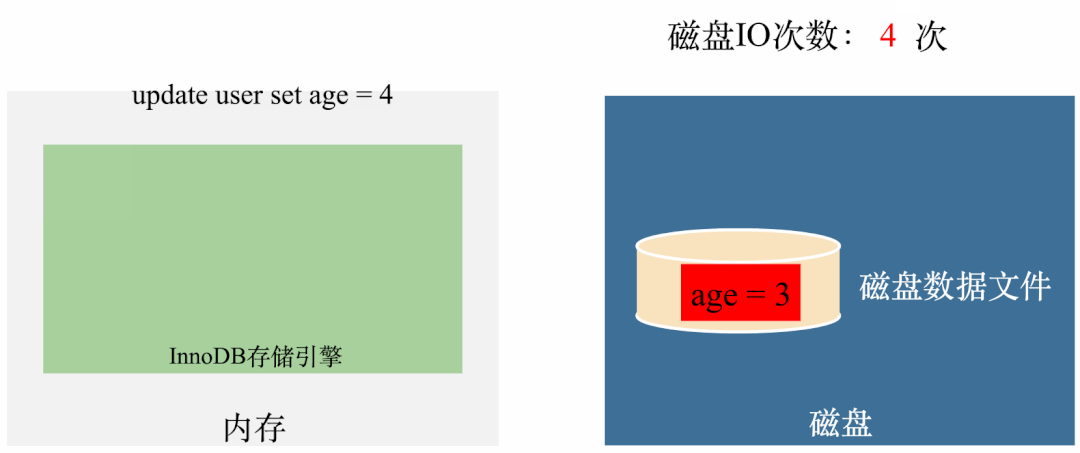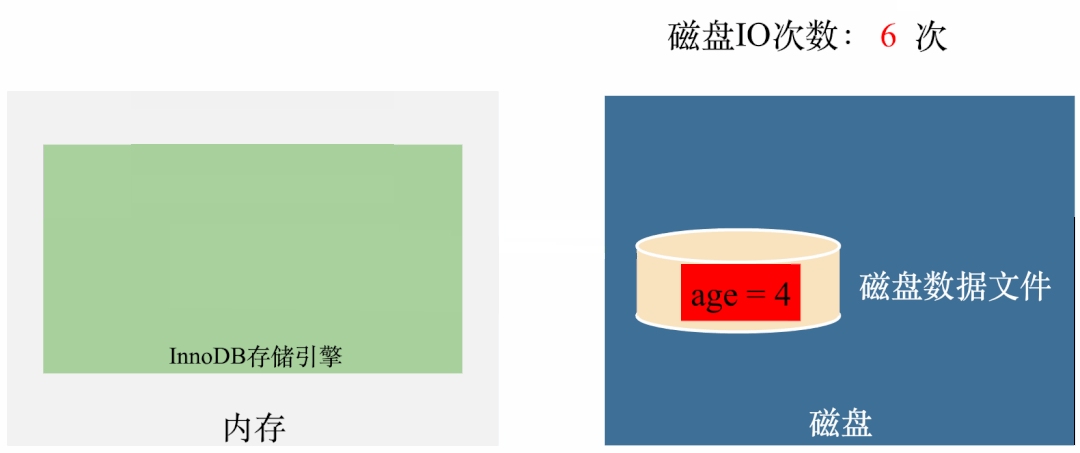
从动图中可以看出,前面一两次传播还好,至少眼睛还能看出个大概,但是到了后几轮,大多数节点都被感染了,但是还在继续对外传播消息。
这消息数量,简直是看的让人头皮发麻。
六度分隔理论
最后再说一个有意思的东西,叫做“六度分隔理论”:
1967年,哈佛大学的心理学教授Stanley Milgram想要描绘一个连结人与社区的人际连系网。做过一次连锁信实验,结果发现了“六度分隔”现象。简单地说:“你和任何一个陌生人之间所间隔的人不会超过六个,也就是说,最多通过六个人你就能够认识任何一个陌生人。
六度分割理论,也叫小世界理论。这其实和 Gossip 协议也有千丝万缕的联系。
我在小破站上看到一个相关的视频,我觉得解释的还是挺清楚的,你如果有兴趣的话可以去看看:
https://www.bilibili.com/video/BV1b7411B7D2?t=31
.png)
在视频里面,有这样的一个画面:

好家伙,这不是我们前面的网站上面的翻版嘛,看起来可太亲切了。
这个理论刚刚提出来的时候还是“最多通过六个人你就能够认识任何一个陌生人”。
但是随着这几年社交网络的急速发展,地球都被拉小到了一个“村”的概念了。
所以这个数字在逐渐的减少:
.png)
而且如果把这个范围拉小一点,比如局限在程序员这个小范围内,那就更小了。
有时候拉个业务对接群,进去一看好家伙还有前同事,你说这个圈子能有多大。

本文已收录到个人博客,欢迎大家来玩。
https://www.whywhy.vip/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号