面试官:要不我们聊一下“心跳”的设计?
你好呀,我是歪歪。
是这样的,我最近又看到了这篇文章《工商银行分布式服务 C10K 场景解决方案 》。
为什么是又呢?
因为这篇文章最开始发布的时候我就看过了,当时就觉得写得挺好的,宇宙行(工商银行)果然是很叼的样子。
但是看过了也就看过了,当时没去细琢磨。
这次看到的时候,刚好是在下班路上,就仔仔细细的又看了一遍。
嗯,常读常新,还是很有收获的。
所以写篇文章,给大家汇报一下我再次阅读之后的一下收获。

文章提要
我知道很多同学应该都没有看过这篇文章,所以我先放个链接,《工商银行分布式服务 C10K 场景解决方案 》。
先给大家提炼一下文章的内容,但是如果你有时间的话,也可以先去细细的读一下这篇文章,感受一下宇宙行的实力。
文章内容大概是这样的。
在宇宙行的架构中,随着业务的发展,在可预见的未来,会出现一个提供方为数千个、甚至上万个消费方提供服务的场景。
在如此高负载量下,若服务端程序设计不够良好,网络服务在处理数以万计的客户端连接时、可能会出现效率低下甚至完全瘫痪的情况,即为 C10K 问题。
C10K 问题就不展开讲了,网上查一下,非常著名的程序相关问题,只不过该问题已经成为历史了。
而宇宙行的 RPC 框架使用的是 Dubbo,所以他们那篇文章就是基于这个问题去展开的:
基于 Dubbo 的分布式服务平台能否应对复杂的 C10K 场景?
为此,他们搭建了大规模连接环境、模拟服务调用进行了一系列探索和验证。
首先他们使用的 Dubbo 版本是 2.5.9。版本确实有点低,但是银行嘛,懂的都懂,架构升级是能不动就不动,稳当运行才是王道。
在这个版本里面,他们搞了一个服务端,服务端的逻辑就是 sleep 100ms,模拟业务调用,部署在一台 8C16G 的服务器上。
对应的消费方配置服务超时时间为 5s,然后把消费方部署在数百台 8C16G 的服务器上(我滴个乖乖,数百台 8C16G 的服务器,这都是白花花的银子啊,有钱真好),以容器化方式部署 7000 个服务消费方。

每个消费方启动后每分钟调用 1 次服务。
然后他们定制了两个测试的场景:
.png)
场景 2 先暂时不说,异常是必然的,因为只有一个提供方嘛,重启期间消费方还在发请求,这必然是要凉的。
但是场景 1 按理来说不应该的啊。
你想,消费方配置的超时时间是 5s,而提供方业务逻辑只处理 100ms。再怎么说时间也是够够的了。
需要额外多说一句的是:本文也只聚焦于场景 1。
但是,朋友们,但是啊。
虽然调用方一分钟发一次请求的频率不高,但是架不住调用方有 7000 个啊,这 7000 个调用方,这就是传说中的突发流量,只是这个“突发”是每分钟一次。
所以,偶现超时也是可以理解的,毕竟服务端处理能力有限,有任务在队列里面稍微等等就超时了。
可以写个小例子示意一下,是这样的:

就是搞个线程池,线程数是 200。然后提交 7000 个任务,每个任务耗时 100ms,用 CountDownLatch 模拟了一下并发,在我的 12 核的机器上运行耗时 3.8s 的样子。
也就是说如果在 Dubbo 的场景下,每一个请求再加上一点点网络传输的时间,一点点框架内部的消耗,这一点点时间再乘以 7000,最后被执行的任务理论上来说,是有可能超过 5s 的。
所以偶现超时是可以理解的。
但是,朋友们,又来但是了啊。
我前面都说的是理论上,然而实践才是检验真理的唯一办法。
看一下宇宙行的验证结果:
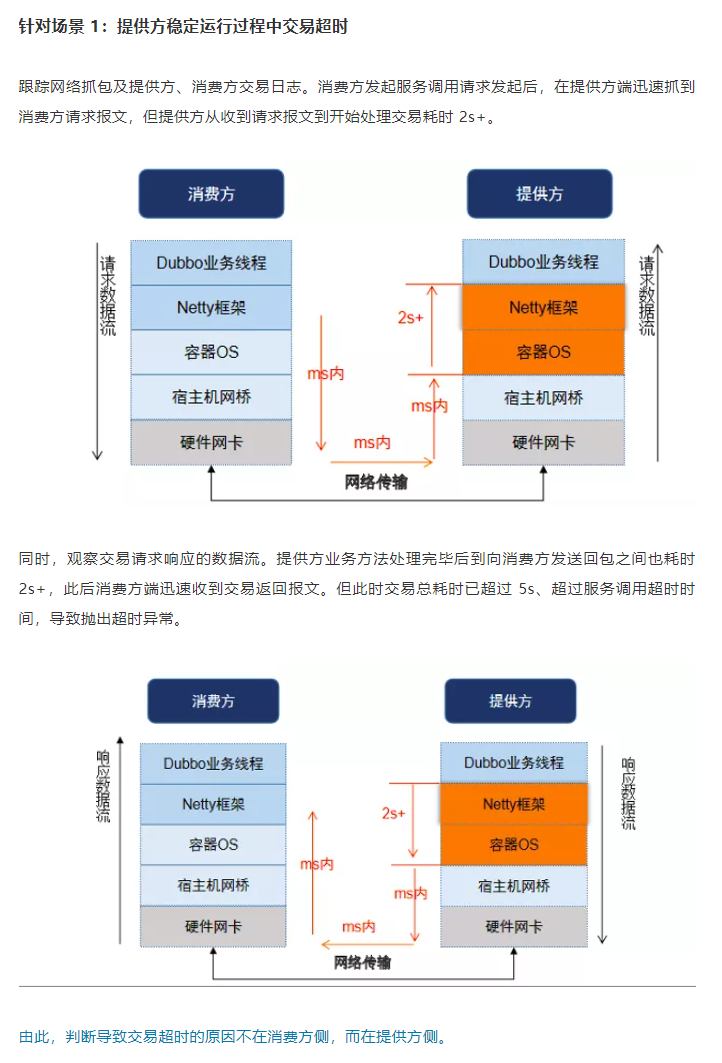
首先我们可以看到消费方不论是发起请求还是处理响应都是非常迅速的,但是卡壳就卡在服务方从收到请求到处理请求之间。
经过抓包分析,他们得出结论:导致交易超时的原因不在消费方侧,而在提供方侧。
这个结论其实也很好理解,因为压力都在服务提供方这边,所以阻塞也应该是在它这里。
其实到这里我们基本上就可以确认,肯定是 Dubbo 框架里面的某一些操作导致了耗时的增加。
难的就是定位到,到底是什么操作呢?
宇宙行通过一系列操作,经过缜密的分析,得出了一个结论:
心跳密集导致 netty worker 线程忙碌,从而导致交易耗时增长。
也就是结论中提到的这一点:

有了结论,找到了病灶就好办了,对症下药嘛。
因为前面说过,本文只聚焦于场景一,所以我们看一下对于场景一宇宙行给出的解决方案:

全都是围绕着心跳的优化处理,处理完成后的效果如下:

其中效果最显著的操作是“心跳绕过序列化”。
消费方与提供方之间平均处理时差由 27ms 降低至 3m,提升了 89%。
前 99% 的交易耗时从 191ms 下降至 133ms,提升了 30%。
好了,写到这,就差不多是把那篇文章里面我当时看到的一些东西复述了一遍,没啥大营养。
只是我还记得第一次看到这篇文章的时候,我是这样的:

我觉得挺牛逼的,一个小小的心跳,在 C10K 的场景下竟然演变成了一个性能隐患。
我得去研究一下,顺便宇宙行给出的方案中最重要的是“心跳绕过序列化”,我还得去研究一下 Dubbo 怎么去实现这个功能,研究明白了这玩意就是我的了啊。
但是...

我忘记当时为啥没去看了,但是没关系,我现在想起来了嘛,马上就开始研究。
心跳如何绕过序列化
我是怎么去研究呢?
直接往源码里面冲吗?
是的,就是往源码里面冲。
但是冲之前,我先去 Dubb 的 github 上逛了一圈:
https://github.com/apache/dubbo
然后在 Pull request 里面先搜索了一下“Heartbeat”,这一搜还搜出不少好东西呢:
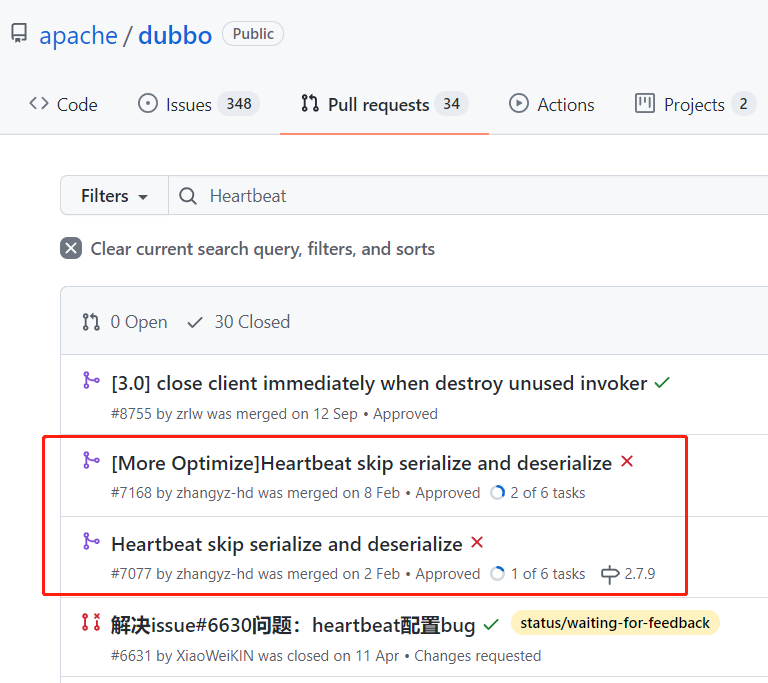
我一眼看到这两个 pr 的时候,眼睛都在放光。
好家伙,我本来只是想随便看看,没想到直接定位了我要研究的东西了。
我只需要看看这两个 pr,就知道是怎么实现的“心跳绕过序列化”,这直接就让我少走了很多弯路。
首先看这个:
https://github.com/apache/dubbo/pull/7077

从这段描述中可以知道,我找到对的地方了。而从他的描述中知道“心跳跳过序列化”,就是用 null 来代替了序列化的这个过程。
同时这个 pr 里面还说明了自己的改造思路:

接着就带大家看一下这一次提交的代码。
怎么看呢?
可以在 git 上看到他对应这次提交的文件:

到源码里面找到对应地方即可,这也是一个去找源码的方法。
我比较熟悉 Dubbo 框架,不看这个 pr 我也大概知道去哪里找对应的代码。但是如果换成另外一个我不熟悉的框架呢?
从它的 git 入手其实是一个很好的角度。
一个翻阅源码的小技巧,送给你。
如果你不了解 Dubbo 框架也没有关系,我们只是聚焦于“心跳是如何跳过序列化”的这一个点。至于心跳是由谁如何在什么时间发起的,这一节暂时不讲。
接着,我们从这个类下手:
org.apache.dubbo.rpc.protocol.dubbo.DubboCodec
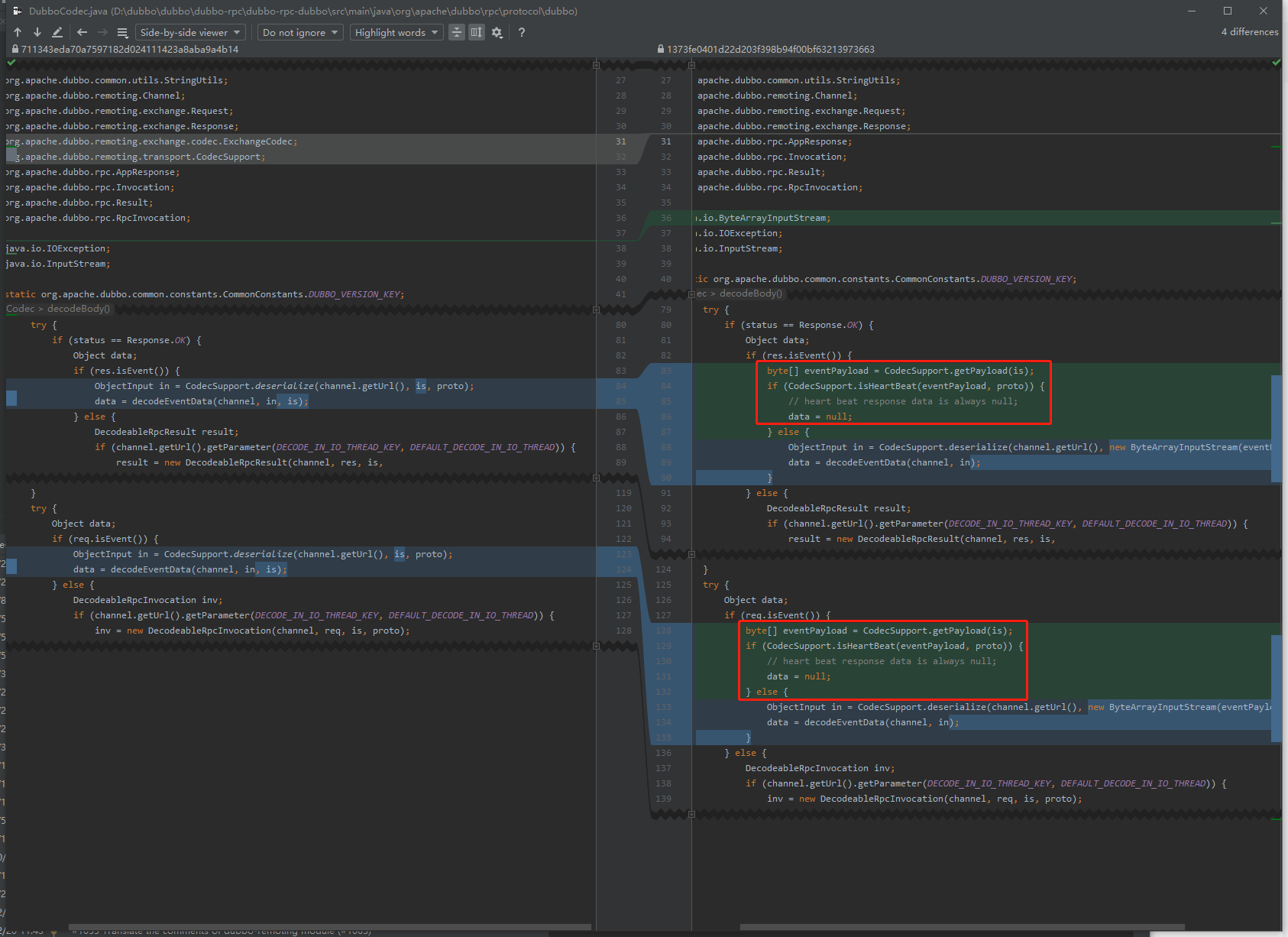
从提交记录可以看出主要有两处改动,且两处改动的代码是一模一样的,都位于 decodeBody 这个方法,只是一个在 if 分支,一个在 else 分支:
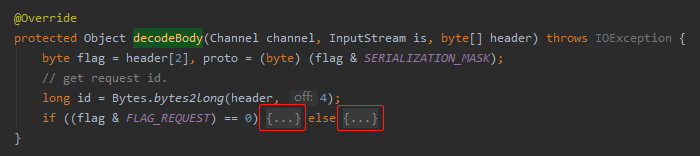
这个代码是干啥的?
你想一个 RPC 调用,肯定是涉及到报文的 encode(编码) 和 decode(解码) 的,所以这里主要就是对请求和响应报文进行 decode 。
一个心跳,一来一回,一个请求,一个响应,所以有两处改动。
所以我带着大家看请求包这一处的处理就行了:
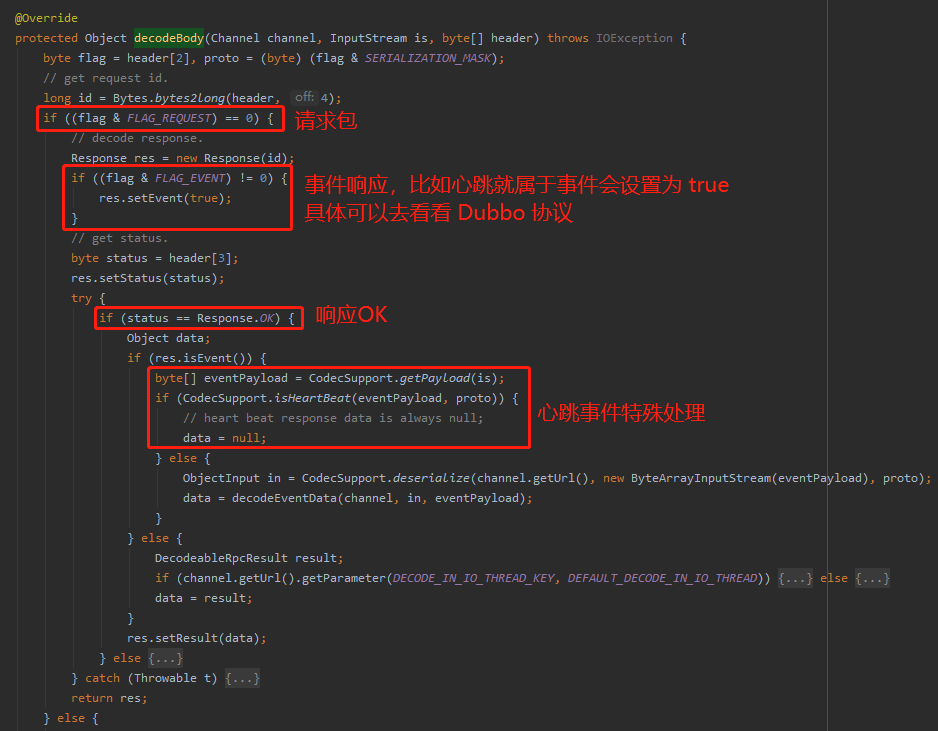
可以看到代码改造之后,对心跳包进行了一个特殊的判断。
在心跳事件特殊处理里面涉及到两个方法,都是本次提交新增的方法。
第一个方法是这样的:
org.apache.dubbo.remoting.transport.CodecSupport#getPayload

就是把 InputStream 流转换成字节数组,然后把这个字节数组作为入参传递到第二个方法中。
第二个方法是这样的:
org.apache.dubbo.remoting.transport.CodecSupport#isHeartBeat

从方法名称也知道这是判断请求是不是心跳包。
怎么去判断它是心跳包呢?
首先得看一下发起心跳的地方:
org.apache.dubbo.remoting.exchange.support.header.HeartbeatTimerTask#doTask

从发起心跳的地方我们可以知道,它发出去的东西就是 null。
所以在接受包的地方,判断其内容是不是 null,如果是,就说明是心跳包。
通过这简单的两个方法,就完成了心跳跳过序列化这个操作,提升了性能。
而上面两个方法都是在这个类中,所以核心的改动还是在这个类,但是改动点其实也不算多:
org.apache.dubbo.remoting.transport.CodecSupport
在这个类里面有两个小细节,可以带大家再看看。
首先是这里:
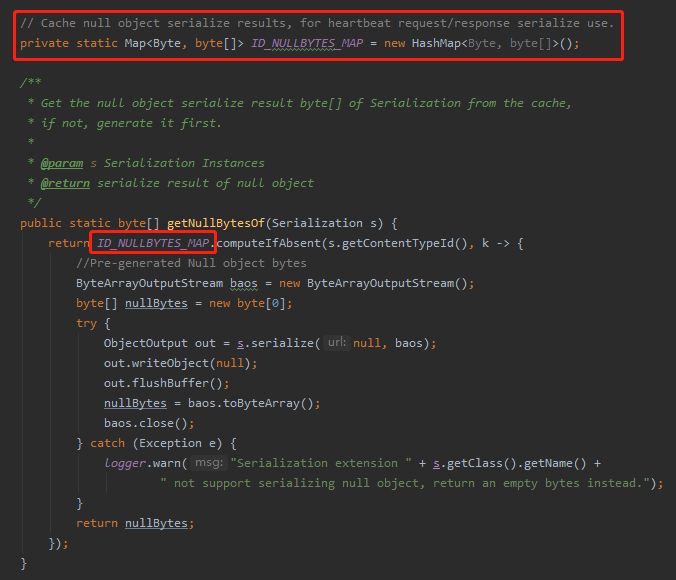
这个 map 里面缓存的就是不同的序列化的方式对应的 null,代码干的也就是作者这里说的这件事儿:

另外一个细节是看这个类的提交记录:

还有一次优化性的提交,而这一次提交的内容是这样的。
首先定义了一个 ThreadLocal,并使其初始化的时候是 1024 字节:

那么这个 ThreadLocal 是用在哪儿的呢?

在读取 InputStream 的时候,需要开辟一个字节数组,为了避免频繁的创建和销毁这个字节数据,所以搞了一个 ThreadLocal:
有的同学看到这里就要问了:为什么这个 ThreadLocal 没有调用 remove 方法呢,不会内存泄漏嘛?
不会的,朋友们,在 Dubbo 里面执行这个玩意的是 NIO 线程,这个线程是可以复用的,且里面只是放了一个 1024 的字节数组,不会有脏数据,所以不需要移除,直接复用。
正是因为可以复用,所以才提升了性能。
这就是细节,魔鬼都在细节里面。
这一处细节,就是前面提到的另外一个 pr:
https://github.com/apache/dubbo/pull/7168
看到这里,我们也就知道了宇宙行到底是怎么让心跳跳过序列化操作了,其实也没啥复杂的代码,几十行代码就搞定了。
但是,朋友们,又要但是了。
写到这里的时候,我突然感觉到不太对劲。
因为我之前写过这篇文章,Dubbo 协议那点破事。
在这篇文章里面有这样的一个图:

这是当时在官网上截下来的。
在协议里面,事件标识字段之前只有 0 和 1。
但是现在不一样了,从代码看,是把 1 的范围给扩大了,它不一定代表的是心跳,因为这里面有个 if-else

所以,我就去看了一下现在官网上关于协议的描述。
https://dubbo.apache.org/zh/docs/v3.0/concepts/rpc-protocol/#dubbo2
果然,发生了变化:

并不是说 1 就是心跳包,而是改口为:1 可能是心跳包。
严谨,这就是严谨。
所以开源项目并不是代码改完就改完了,还要考虑到一些周边信息的维护。
心跳的多种设计方案
在研究 Dubbo 心跳的时候,我还找到了这样一个 pr。
https://github.com/apache/dubbo/issues/3151
标题是这样的:

翻译过来就是使用 IdleStateHandler 代替使用 Timer 发送心跳的建议。
我定睛一看,好机会,这不是 95 后老徐嘛,老熟人了。
看一下老徐是怎么说的,他建议具体是这样的:
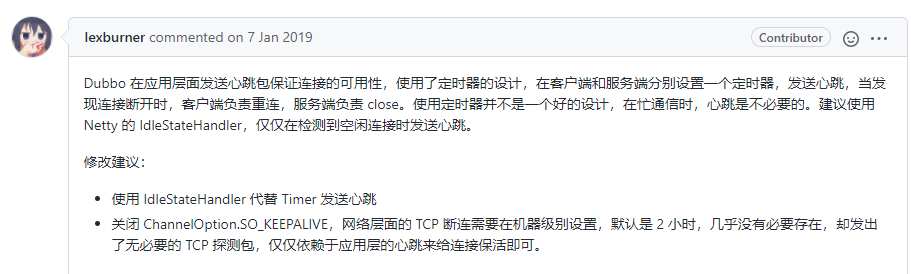
几位 Dubbo 大佬,在这个 pr 里面交换了很多想法,我仔细的阅读之后都受益匪浅。
大家也可以点进去看看,我这里给大家汇报一下自己的收获。
首先是几位老哥在心跳实时性上的一顿 battle。


总之,大家知道 Dubbo 的心跳检测是有一定延时的,因为是基于时间轮做的,相当于是定时任务,触发的时效性是不能保证实时触发的。
这玩意就类似于你有一个 60 秒执行一次的定时任务,在第 0 秒的时候任务启动了,在第 1 秒的时候有一个数据准备好了,但是需要等待下一次任务触发的时候才会被处理。因此,你处理数据的最大延迟就应该是 60 秒。
这个大家应该能明白过来。
额外说一句,上面讨论的结果是“目前是 1/4 的 heartbeat 延时”,但是我去看了一下最新的 master 分支的源码,怎么感觉是 1/3 的延时呢:
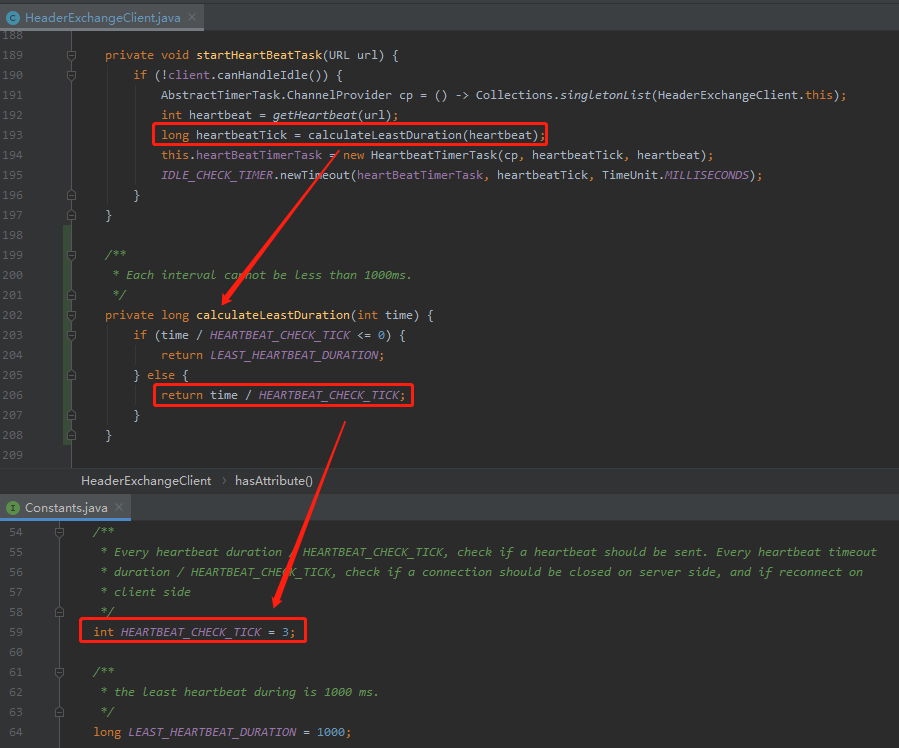
从源码里可以看到,计算时间的时候 HEARTBEAT_CHECK_TICK 参数是 3。所以我理解是 1/3 的延时。
但是不重要,这不重要,反正你知道是有延时的就行了。
而 kexianjun 老哥认为如果基于 netty 的 IdleStateHandler 去做,每次检测超时都重新计算下一次检测的时间,因此相对来说就能比较及时的检查到超时了。
这是在实时性上的一个优化。
而老徐觉得,除了实时性这个考虑外,其实 IdleStateHandler 更是一个针对心跳的优雅的设计。但是呢,由于是基于 Netty 的,所以当通讯框架使用的不是 Netty 的时候,就回天无力了,所以可以保留 Timer 的设计来应对这种情况。
很快,carryxyh 老哥就给出了很有建设性的意见:
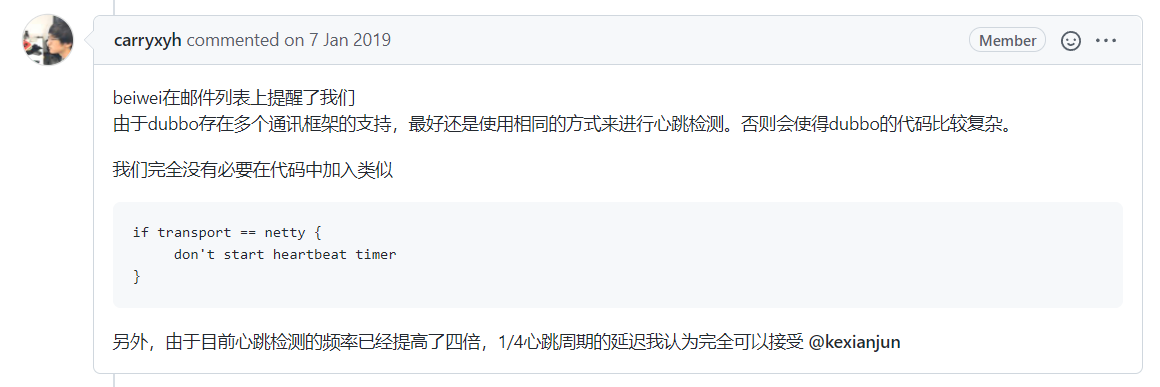
由于 Dubbo 是支持多个通讯框架的。
这里说的“多个”,其实不提我都忘记了,除了 Netty 之外,它还支持 Girzzly 和 Mina 这两种底层通讯框架,而且还支持自定义。
但是我寻思都 2021 年了,Girzzly 和 Mina 还有人用吗?
从源码中我们也能找到它们的影子:
org.apache.dubbo.remoting.transport.AbstractEndpoint
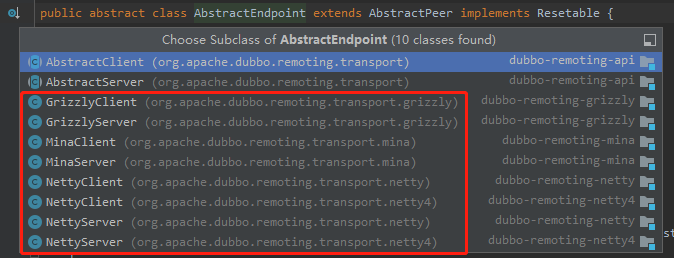
Girzzly、Mina 和 Netty 都各有自己的 Server 和 Client。
其中 Netty 有两个版本,是因为 Netty4 步子迈的有点大,难以在之前的版本中进行兼容,所以还不如直接多搞一个实现。
但是不管它怎么变,它都还是叫做 Netty。
好了,说回前面的建设性意见。
如果是采用 IdleStateHandler 的方式做心跳,而其他的通讯框架保持 Timer 的模式,那么势必会出现类似于这样的代码:
if transport == netty {
don't start heartbeat timer
}
这是一个开源框架中不应该出现的东西,因为会增加代码复杂度。
所以,他的建议是最好还是使用相同的方式来进行心跳检测,即都用 Timer 的模式。
正当我觉得这个哥们说的有道理的时候,我看了老徐的回答,我又瞬间觉得他说的也很有道理:
我觉得上面不需要我解释了,大家边读边思考就行了。
接着看看 carryxyh 老哥的观点:

这个时候对立面就出现了。
老徐的角度是,心跳肯定是要有的,只是他觉得不同通讯框架的实现方式可以不必保持一致(现在都是基于 Timer 时间轮的方式),他并不认为 Timer 抽象成一个统一的概念去实现连接保活是一个优雅的设计。
在 Dubbo 里面我们主要用的就是 Netty,而 Netty 的 IdleStateHandler 机制,天生就是拿来做心跳的。
所以,我个人认为,是他首先觉得使用 IdleStateHandler 是一种比较优雅的实现方式,其次才是时效性的提升。
但是 carryxyh 老哥是觉得 Timer 抽象的这个定时器,是非常好的设计,因为它的存在,我们才可以不关心底层是netty还是mina,而只需要关心具体实现。
而对于 IdleStateHandler 的方案,他还是认为在时效性上有优势。但是我个人认为,他的想法是如果真的有优势的话,我们可以参考其实现方式,给其他通讯框架也赋能一个 “Idle” 的功能,这样就能实现大统一。
看到这里,我觉得这两个老哥 battle 的点是这样的。
首先前提是都围绕着“心跳”这个功能。
一个认为当使用 Netty 的时候“心跳”有更好的实现方案,且 Netty 是 Dubbo 主要的通讯框架,所以应该可以只改一下 Netty 的实现。
一个认为“心跳”的实现方案应该统一,如果 Netty 的 IdleStateHandler 方案是个好方案,我们应该把这个方案拿过来。
我觉得都有道理,一时间竟然不知道给谁投票。
但是最终让我选择投老徐一票的,是看了他写的这篇文章:《一种心跳,两种设计》。
这篇文章里面他详细的写了 Dubbo 心跳的演变过程,其中也涉及到部分的源码。
最终他给出了这样的一个图, 心跳设计方案对比:

然后,是这段话:
.png)
老徐是在阿里搞中间件的,原来搞中间件的人每天想的是这些事情。
有点意思。
看看代码
带大家看一下代码,但是不会做详细分析,相当于是指个路,如果想要深入了解的话,自己翻源码去。
首先是这里:
org.apache.dubbo.remoting.exchange.support.header.HeaderExchangeClient

可以看到在 HeaderExchangeClient 的构造方法里面调用了 startHeartBeatTask 方法来开启心跳。
同时这里面有个 HashedWheelTimer,这玩意我熟啊,时间轮嘛,之前分析过的。
然后我们把目光放在这个方法 startHeartBeatTask:
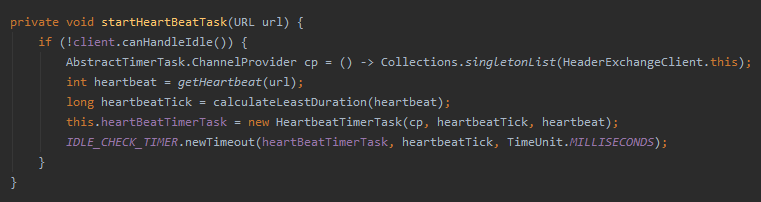
这里面就是构建心跳任务,然后扔到时间轮里面去跑,没啥复杂的逻辑。
这一个实现,就是 Dubbo 对于心跳的默认处理。
但是需要注意的是,整个方法被 if 判断包裹了起来,这个判断可是大有来头,看名字叫做 canHandleIdle,即是否可以处理 idle 操作,默认是 false:
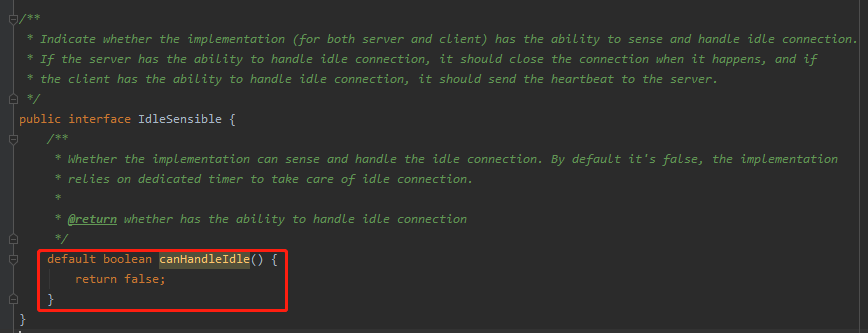
所以,前面的 if 判断的结果是 true。
那么什么情况下 canHandleIdle 是 true 呢?
在使用 Netty4 的时候是 true。
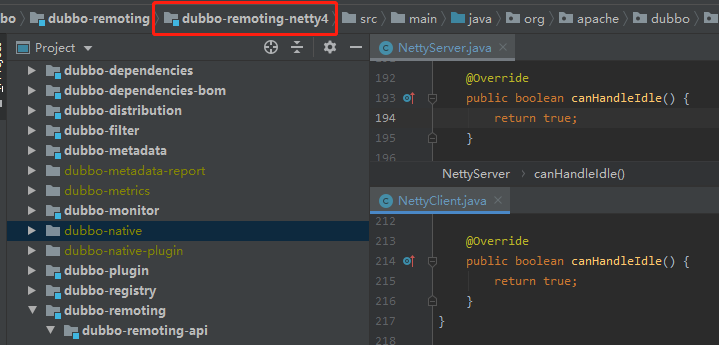
也就是 Netty4 不走默认的这套心跳实现。
那么它是怎么实现的呢?
由于服务端和客户端的思路是一样的,所以我们看一下客户端的代码就行。
关注一下它的 doOpen 方法:
org.apache.dubbo.remoting.transport.netty4.NettyClient#doOpen
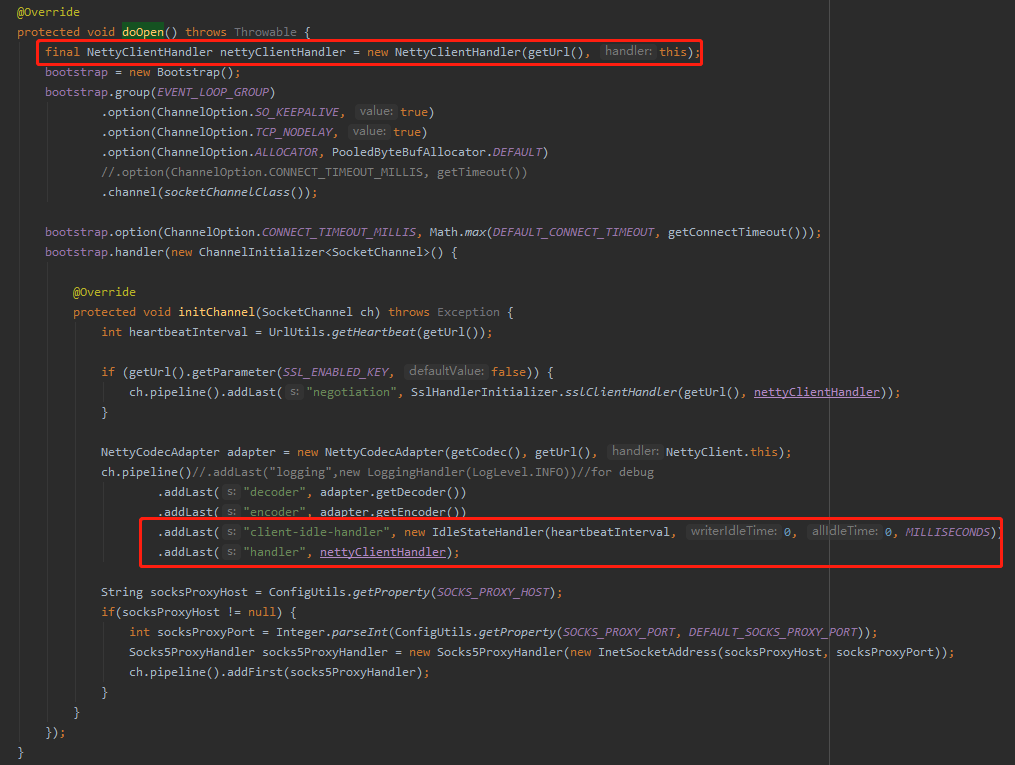
在 pipeline 里面加入了我们前面说到的 IdleStateHandler 事件,这个事件就是如果 heartbeatInterval 毫秒内没有读写事件,那么就会触发一个方法,相当于是一个回调。
heartbeatInterval 默认是 6000,即 60s。
然后加入了 nettyClientHandler,它是干什么呢?
看一眼它的这个方法:
org.apache.dubbo.remoting.transport.netty4.NettyClientHandler#userEventTriggered

这个方法里面在发送心跳事件。
也就是说你这样写,含义是在 60s 内,客户端没有发生读写时间,那么 Netty 会帮我们触发 userEventTriggered 方法,在这个方法里面,我们可以发送一次心跳,去看看服务端是否正常。
从目前的代码来看, Dubbo 最终是采用的老徐的建议,但是默认实现还是没变,只是在 Netty4 里面采用了 IdleStateHandler 机制。
这样的话,其实我就觉得更奇怪了。
同样是 Netty,一个采用的是时间轮,一个采用的 IdleStateHandler。
同时我也很理解,步子不能迈的太大了,容易扯着蛋。

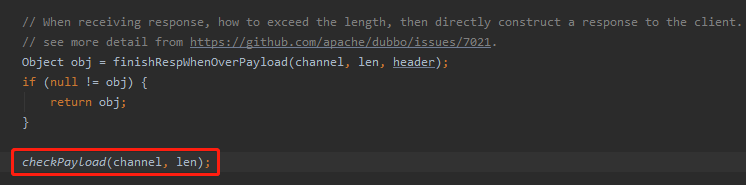
但是,在翻源码的过程中,我发现了一个代码上的小问题。
org.apache.dubbo.remoting.exchange.codec.ExchangeCodec#decode(org.apache.dubbo.remoting.Channel, org.apache.dubbo.remoting.buffer.ChannelBuffer, int, byte[])
在上面这个方法中,有两行代码是这样的:

你先别管它们是干啥的,我就带你看看它们的逻辑是怎么样的:

可以看到两个方法都执行了这样的逻辑:
int payload = getPayload(channel);
boolean overPayload = isOverPayload(payload, size);
如果 finishRespWhenOverPayload 返回的不是 null,没啥说的,返回 return 了,不会执行 checkPayload 方法。
如果 finishRespWhenOverPayload 返回的是 null,则会执行 checkPayload 方法。
这个时候会再次做检查报文大小的操作,这不就重复了吗?
所以,我认为这一行的代码是多余的,可以直接删除。
你明白我意思吧?
又是一个给 Dubbo 贡献源码的机会,送给你,可以冲一波。
最后,再给大家送上几个参考资料。
第一个是可以去了解一下 SOFA-RPC 的心跳机制。 SOFA-PRC 也是阿里开源出来的框架。
在心跳这块的实现就是完完全全的基于 IdleStateHandler 来实现的。
可以去看一下官方提供的这两篇文章:
https://www.sofastack.tech/search/?page=1&query=%E5%BF%83%E8%B7%B3&type=all
第二个是极客时间《从0开始学微服务》,第 17 讲里面,老师在关于心跳这块的一点分享,提到的一个保护机制,这是我之前没有想到过的:

反正我是觉得,我文章中提到的这一些链接,你都去仔仔细细的看了,那么对于心跳这块的东西,也就掌握的七七八八了,够用了。
好了,就到这吧。
本文已收录至个人博客,欢迎大家来玩。
https://www.whywhy.vip/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号