看到一个魔改线程池,面试素材加一!
你好呀,我是歪歪。
今天给大家分享一个经过扩展后的线程池,且我觉得扩展的思路非常好的。
放心,我标题党来着,我觉得面试不会有人考这个玩意,但是工作中是有可能真的会遇到相应的场景。
为了引出这个线程池,我先给大家搞个场景,方便理解。
就拿下面这个表情包来做例子吧。

假设我们有两个程序员,就叫富贵和旺财吧。
上面这个表情包就是这两个程序员一天的工作写照,用程序来表示是这样的。
首先我们搞一个对象,表示程序员当时正在做的事儿:
public class CoderDoSomeThing {
private String name;
private String doSomeThing;
public CoderDoSomeThing(String name, String doSomeThing) {
this.name = name;
this.doSomeThing = doSomeThing;
}
}
然后,用代码描述一下富贵和旺财做的事儿:
public class NbThreadPoolTest {
public static void main(String[] args) {
CoderDoSomeThing rich1 = new CoderDoSomeThing("富贵", "启动Idea");
CoderDoSomeThing rich2 = new CoderDoSomeThing("富贵", "搞数据库,连tomcat,crud一顿输出");
CoderDoSomeThing rich3 = new CoderDoSomeThing("富贵", "嘴角疯狂上扬");
CoderDoSomeThing rich4 = new CoderDoSomeThing("富贵", "接口访问报错");
CoderDoSomeThing rich5 = new CoderDoSomeThing("富贵", "心态崩了,卸载Idea");
CoderDoSomeThing www1 = new CoderDoSomeThing("旺财", "启动Idea");
CoderDoSomeThing www2 = new CoderDoSomeThing("旺财", "搞数据库,连tomcat,crud一顿输出");
CoderDoSomeThing www3 = new CoderDoSomeThing("旺财", "嘴角疯狂上扬");
CoderDoSomeThing www4 = new CoderDoSomeThing("旺财", "接口访问报错");
CoderDoSomeThing www5 = new CoderDoSomeThing("旺财", "心态崩了,卸载Idea");
}
}
简单解释一下变量的名称,表明我还是经过深思熟虑了的。
富贵,就是有钱,所以变量名叫做 rich。
旺财,就是汪汪汪,所以变量名叫做 www。
你看我这个类的名称,NbThreadPoolTest,就知道我是要用到线程池了。
实际情况中,富贵和旺财两个人是可以各干各的事儿,互不干扰的,也就是他们应该是各自的线程。
各干各的事儿,互不干扰,这听起来好像是可以用线程池的。
所以,我把程序修改成了下面这个样子,把线程池用起来:
public class NbThreadPoolTest {
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(5);
List<CoderDoSomeThing> coderDoSomeThingList = new ArrayList<>();
coderDoSomeThingList.add(new CoderDoSomeThing("富贵", "启动Idea"));
coderDoSomeThingList.add(new CoderDoSomeThing("富贵", "搞数据库,连tomcat,crud一顿输出"));
coderDoSomeThingList.add(new CoderDoSomeThing("富贵", "嘴角疯狂上扬"));
coderDoSomeThingList.add(new CoderDoSomeThing("富贵", "接口访问报错"));
coderDoSomeThingList.add(new CoderDoSomeThing("富贵", "心态崩了,卸载Idea"));
coderDoSomeThingList.add(new CoderDoSomeThing("旺财", "启动Idea"));
coderDoSomeThingList.add(new CoderDoSomeThing("旺财", "搞数据库,连tomcat,crud一顿输出"));
coderDoSomeThingList.add(new CoderDoSomeThing("旺财", "嘴角疯狂上扬"));
coderDoSomeThingList.add(new CoderDoSomeThing("旺财", "接口访问报错"));
coderDoSomeThingList.add(new CoderDoSomeThing("旺财", "心态崩了,卸载Idea"));
coderDoSomeThingList.forEach(coderDoSomeThing -> {
executorService.execute(() -> {
System.out.println(coderDoSomeThing.toString());
});
});
}
}
上面程序就是把富贵和旺财两人做的事情都封装到了 list 里面,然后遍历这个 list 把里面的东西,即“做的事情”都扔到线程池里面去。
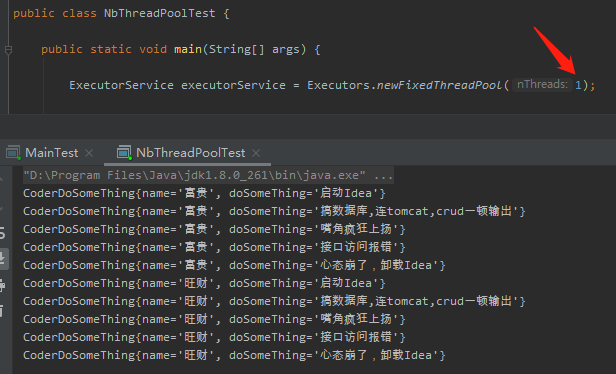
那么上面的程序执行后,一种可能的输出是这样的:
.jpg)
乍一看没问题,富贵和旺财都在同时做事。
但是仔细一看,每个人做的事情的顺序不对了啊。
比如旺财看起来有点“精神分裂”,刚刚启动 Idea,嘴角就开始疯狂上扬了。
所以,到这里可以引出我想要的东西了。
我想要的是什么样的东西呢?
就是在保证富贵和旺财在同时做事的情况下,还要保证他们的做的事情是有一定顺序的,即按照我投放到线程池里面的顺序来执行。
用正式一点的话来描述是这样的:
我需要这样的一个线程池,它可以确保投递进来的任务按某个维度划分出任务,然后按照任务提交的顺序依次执行。这个线程池可以通过并行处理(多个线程)来提高吞吐量、又要保证一定范围内的任务按照严格的先后顺序来运行。
用我前面的例子,“按某个维度”就是人名,就是富贵和旺财这个维度。
请问你怎么做?

一顿分析
我会怎么做?
首先,我可以肯定的是 JDK 的线程池是干不成这个事儿的。
因为从线程池原理的角度来说,并行和先后顺序它是不能同时满足的。
你明白我意思吧?
比如我要用线程池来保证先后顺序,那么它是这样的:
只有一个线程的线程池,它可以保证先后顺序。
但是这玩意有意义吗?
有点意义,因为它并不占用主线程,但是意义不大,毕竟阉割了重要的“多线程”能力。
所以我们怎么在这个场景下把并行能力给提上去呢?
等等,我们好像已经有一个可以保证先后顺序的线程池了。
那么我们把它横向扩容,多搞几个,不就具备了并行的能力了吗?

然后前面提到的“按某个维度”,如果有多个只有一个线程的线程池了,那我也可以按照这个维度去映射“维度”和“每个线程池”呀。
用程序来说就是这样的:
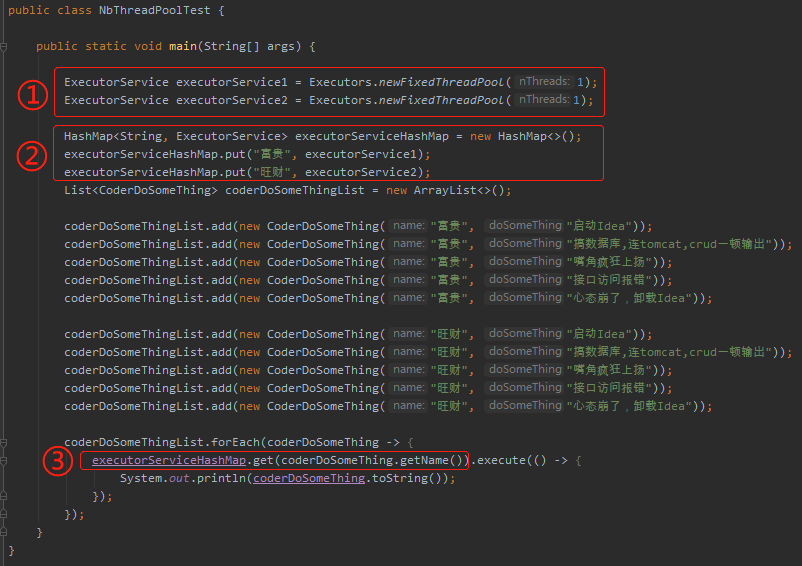
标号为 ① 的地方就是搞了多个只有一个线程的线程池,目的是为了保证消费的顺序性。
标号为 ② 的地方就是通过一个 map 映射人名和线程池之间的关系。这里只是一个示意,比如我们还可以用用户号取模的方式去定位对应的线程池,比如用户号为奇数的用一个线程池,为偶数的用另外一个线程。
所以并不是“某个维度”里面有多少个数据就要定义多少个只有一个线程的线程池,它们也是可以复用的,这个地方有个小弯要转过来。
标号为 ③ 的地方就是根据名称去 map 里面去对应的线程池。
从输出结果来看,也是没有毛病的:
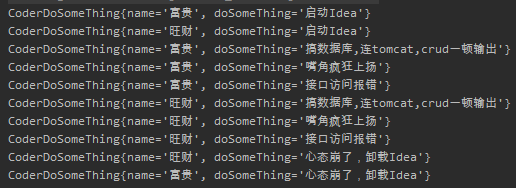
看到这里有的朋友就要说:你这不是作弊吗?
不是说好一个线程池吗,你这都弄了多个了。
你要这个角度看问题的话,那就把路走窄了。
你要想着有一个大的线程池,里面又放了很多个只有一个线程的线程池。
这样格局就打开了。

我上面的写法是一个非常简陋的 Demo,主要是引出这个方案的思路。
我要介绍的,就是基于这个思路搞出的一个开源项目。
是一位大公司的大佬写的,我看了一下源码,拍案叫绝:写的真他娘的好。
我先给你上一个使用案例和输出结果:
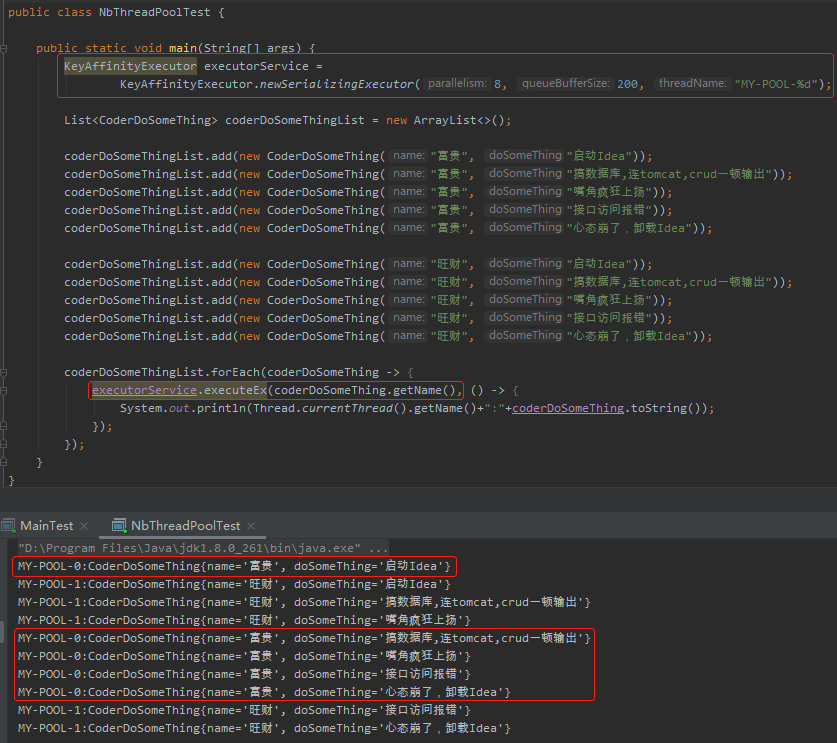
从案例看起来,使用方式也是非常的简单。
和 JDK 原生的用法的差异点就是我框起来的部分。
首先搞一个 KeyAffinityExecutor 的对象,来代替原生的线程池。
KeyAffinityExecutor 其中涉及到一个单词,Affinity。
翻译过来有类同的含义:
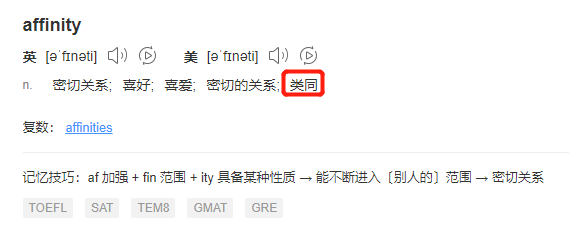
所以 KeyAffinityExecutor 翻译过来就是 key 类同的线程池,当你明白它的功能和作用范围后会觉得这个名字取的是针不戳。
接着是调用了 KeyAffinityExecutor 对象的 executeEx 方法,可以多传入一个参数,这个参数就是区分某一类相同任务的维度,比如我这里就给的是 name 字段。
从使用案例上看来,可以说封装的非常好,开箱即用。

KeyAffinityExecutor用法
先说说这个类的用法吧。
其对应的开源项目地址是这个:
https://github.com/PhantomThief/more-lambdas-java
如果你想把它用起来,得引入下面这个 maven 地址:
<dependency>
<groupId>com.github.phantomthief</groupId>
<artifactId>more-lambdas</artifactId>
<version>0.1.55</version>
</dependency>
其核心代码是这个接口:
com.github.phantomthief.pool.KeyAffinityExecutor
这个接口里面有大量的注释,大家可以拉下来看一下。
我这里主要给大家看一下接口上面,作者写的注释,他是这样介绍自己的这个工具的。
这是一个按指定的 Key 亲和顺序消费的线程池。
KeyAffinityExecutor 是一个特殊的任务线程池。
它可以确保投递进来的任务按 Key 相同的任务依照提交顺序依次执行。在既要通过并行处理来提高吞吐量、又要保证一定范围内的任务按照严格的先后顺序来运行的场景下非常适用。
KeyAffinityExecutor 的内建实现方式,是将指定的 Key 映射到固定的单线程线程池上,它内部会维护多个(数量可配)这样的单线程线程池,来保持一定的任务并行度。
需要注意的是,此接口定义的 KeyAffinityExecutor,并不要求 Key 相同的任务在相同的线程上运行,尽管实现类可以按照这种方式来实现,但它并非一个强制性的要求,因此在使用时也请不要依赖这样的假定。
很多人问,这和自己使用一个线程池的数组,并通过简单取模的方式来实现有什么区别?
事实上,大多数场景的确差异不大,但是当数据倾斜发生时,被散列到相同位置的数据可能会因为热点倾斜数据被延误。
本实现在并发度较低时(阈值可设置),会挑选最闲置的线程池投递,尽最大可能隔离倾斜数据,减少对其它数据带来的影响。
在作者的这段介绍里面,简单的说明了该项目的应用场景和内部原理,和我们前面分析的差不多。
除此之外,还有两个需要特别注意的地方。
第一个地方是这里:
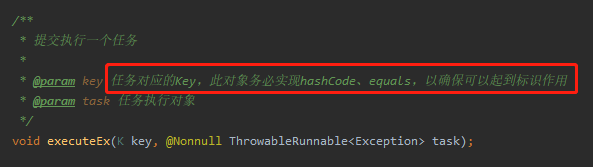
作为区分的任务维度的对象,如果是自定义对象,那么一定要重写其 hashCode、equals,以确保可以起到标识作用。
这一处的提醒就和 HashMap 的 key 如果是对象的话,应该要重写 hashCode、equals 方法的原因是一样一样的。
编程基础,只提一下,不多赘述。
第二个地方得好好说一下,属于他的核心思想。
他没有采用简单取模的方式,因为在简单取模的场景上,数据是有可能发生倾斜的。
我个人是这样理解作者的思路的。
首先说明一下取模的数据倾斜是咋回事,举个简单的例子:

上面的代码片段中,我加入了一个新角色“摸鱼大师”。同时给对象新增了一个 id 字段。
假设,我们对 id 字段用 2 取余:

那么会出现的情况就是大师和富贵对应的 id 取余结果都是 1,它们将同用一个线程池。
很明显,由于大师的频繁操作,导致“摸鱼”变成了热点数据,从而导致编号为 0 的连接池发了倾斜,进而影响到了富贵的正常工作。
而 KeyAffinityExecutor 的策略是什么样的呢?
它会挑选最闲置的线程池进行投递。
怎么理解呢?
还是上面的例子,如果我们构建这样的线程池:
KeyAffinityExecutor executorService =
KeyAffinityExecutor.newSerializingExecutor(3, 200, "MY-POOL-%d");
第一个参数 3,代表它会在这里线程池里面构建 3 个只有一个线程的线程池。
那么当用它来提交任务的时候,由于维度是 id 维度,我们刚好三个 id,所以刚好把这个线程池占满:

这个时候是不存在数据倾斜的。
但是,如果我把前面构建线程池的参数从 3 变成 2 呢?
KeyAffinityExecutor executorService =
KeyAffinityExecutor.newSerializingExecutor(2, 200, "MY-POOL-%d");
提交方式不变,里面加上对 id 为 1 和 2 的任务延迟的逻辑,目的是观察 id 为 3 的数据怎么处理:
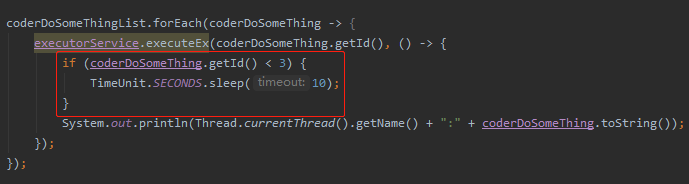
毋庸置疑,当提交执行大师的摸鱼操作的时候线程池肯定不够用了,怎么办?
这个时候,根据作者描述“会挑选最闲置的线程池投递”。
我用这样的数据来说明:

所以,当执行大师摸鱼操作的时候,会去从仅有的两个选项中选一个出来。
怎么选?
谁的并发度低,就选谁。
由于有延迟时间在任务里面,所以我们可以观察到执行富贵的线程的并发度是 5,而执行旺财的线程的并发度是 6。
因此执行大师的摸鱼操作的时候,会选择并发度为 5 的线程进行处理。

这个场景下就出现了数据倾斜。但是倾斜的前提发生了变化,变成了当前已经没有可用线程了。
所以,作者说“尽最大可能隔离倾斜数据”。
这两个方案最大的差异就是对线程资源的利用程度,如果是单纯的取模,那么有可能出现发生数据倾斜的时候,还有可用线程。
如果是 KeyAffinityExecutor 的方式,它可以保证发生数据倾斜的时候,线程池里面的线程一定是已经用完了。
然后,你再品一品这两个方案之间的细微差异。
KeyAffinityExecutor源码
源码不算多,一共就这几个类:
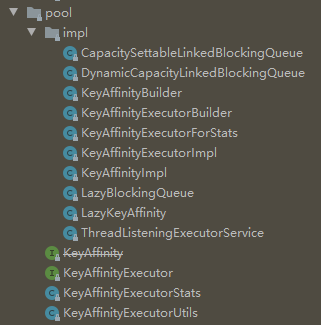
但是他的源码里面绝大部分都是 lambdas 的写法,基本上都是函数式编程,如果你对这方面比较薄弱的话那么看起来会比较吃力一点。
如果你想掌握其源码的话,我建议是把项目拉到本地,然后从他的测试用例入手:
https://github.com/PhantomThief/more-lambdas-java
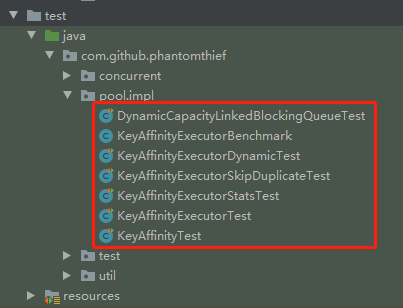
我给大家汇报一下我看到的一些关键的地方,方便大家自己去看的时候梳理思路。
首先肯定是从它的构造方法入手,每一个入参的含义作者都标注的非常清楚了:
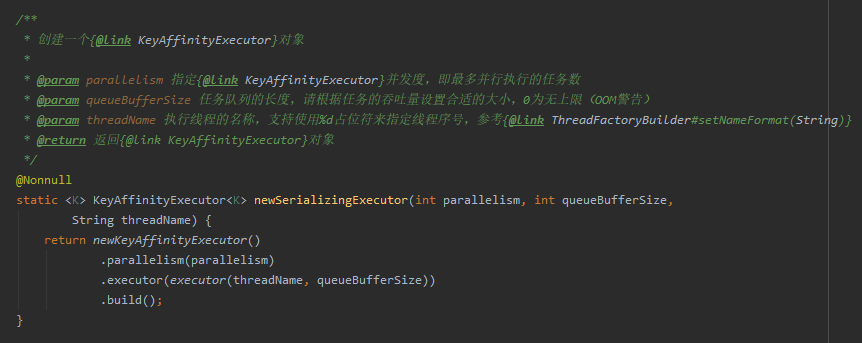
假设我们的构造函数是这样的,含义是构建 3 个只有一个线程的线程池,每个线程池的队列大小是 200:
KeyAffinityExecutor executorService =
KeyAffinityExecutor.newSerializingExecutor(3, 200, "WHY-POOL-%d");
首先我们要找到构建“只有一个线程的线程池”的逻辑在哪。
就藏在构造函数里面的这个方法:
com.github.phantomthief.pool.KeyAffinityExecutorUtils#executor(java.lang.String, int)
在这里可以看到我们一直提到的“只有一个线程的线程池”,队列的长度也可以指定:
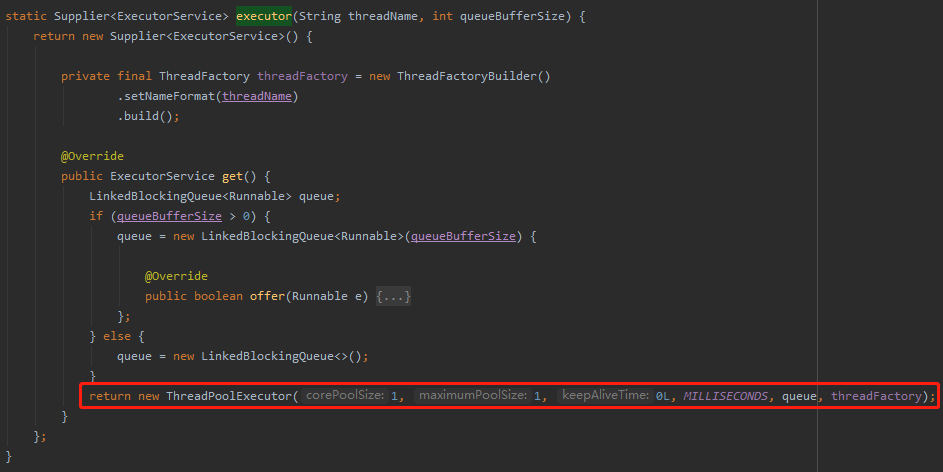
该方法返回的是一个 Supplier 接口,等下就要用到。
接下来,我们要找到 “3” 这个数字是体现在哪儿的呢?
就藏在构造函数的 build 方法里面,该方法最终会调用到这个方法来:
com.github.phantomthief.pool.impl.KeyAffinityImpl#KeyAffinityImpl
你到时候在这个地方打个断点,然后 Debug 看一眼,就非常明确了:

关于框起来的这部分的几个关键参数,我解释一下:
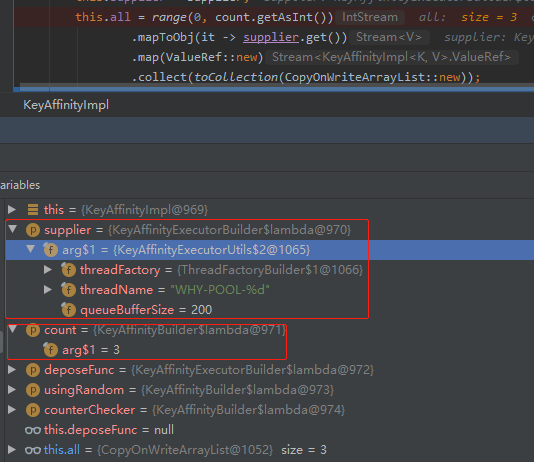
首先是 count 参数,就是我们定义的 3。那么 range(0,3),就是 0,1,2。
然后是 supplier,这玩意就是前面我们说的 executor 方法返回的 supplier 接口,可以看到里面封装的就是个线程池。
接着是里面有一个非常关键的操作 :map(ValueRef::new)。
这个操作里面的 ValueRef 对象,很关键:
com.github.phantomthief.pool.impl.KeyAffinityImpl.ValueRef
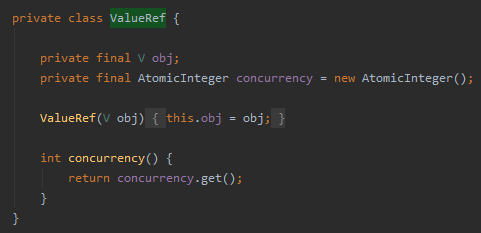
关键的地方就是这个对象里面的 concurrency 变量。
还记得最前面说的“挑选最闲置的执行器(线程池)”这句话吗?
怎么判断是否闲置?
靠的就是 concurrency 变量。
其对应的代码在这:
com.github.phantomthief.pool.impl.KeyAffinityImpl#select
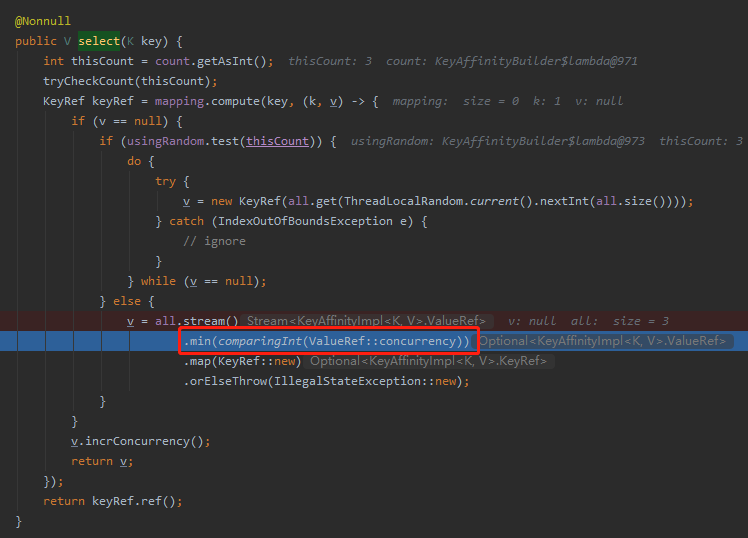
能走到断点的地方,说明当前这个 key 是之前没有被映射过的,所以需要为其指定一个线程池。
而指定这个线程池的操作,就是循环这个 all 集合,集合里面装的就是 ValueRef 对象:

所以,comparingInt(ValueRef::concurrency) 方法就是在选当前所有的线程池,并发度最小的一个。
如果这个线程池从来没有用过或者目前没有任务在使用,那么并发度必然是 0 ,所有会被选出来。
如果所有线程池正在被使用,就会选 concurrency 这个值最低的线程池。
我这里只是给大家说一个大概的思路,如果要深入了解的话,自己去翻源码去。
如果你非常了解 lambdas 的用法的话,你会觉得写的真的很优雅,看起来很舒服。
如果你不了解 lambdas 的话...
那你还不赶紧去学?
另外我还发现了两个熟悉的东西。
朋友们,请看这是什么:

这难道不就是线程池参数的动态调整吗?
第二个是这样的:
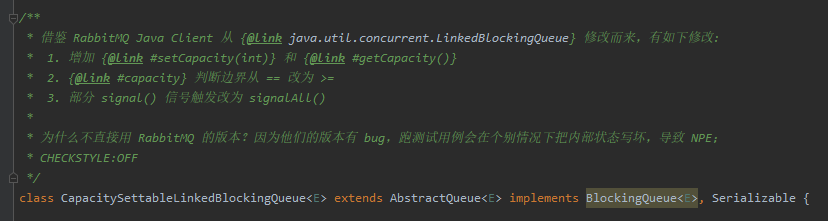
RabbitMQ 里面的动态调整我也写过啊,也是强调过这三处地方:
增加 {@link #setCapacity(int)} 和 {@link #getCapacity()} {@link #capacity} 判断边界从 == 改为 >= 部分 signal() 信号触发改为 signalAll()
另外作者还提到了 RabbitMQ 的版本里面会有导致 NPE 的 BUG 的问题。
这个就没细研究了,有兴趣的可以去对比一下代码,就应该能知道问题出在哪里。
说说 Dubbo
为什么要说一下 Dubbo 呢?
因为我似乎在 Dubbo 里面也发现了 KeyAffinityExecutor 的踪迹。
为什么说是似乎呢?
因为最终没有被合并到代码库里面去。
其对应的链接是这里:
https://github.com/apache/dubbo/pull/8975
这一次提交一共提交了这么多文件:
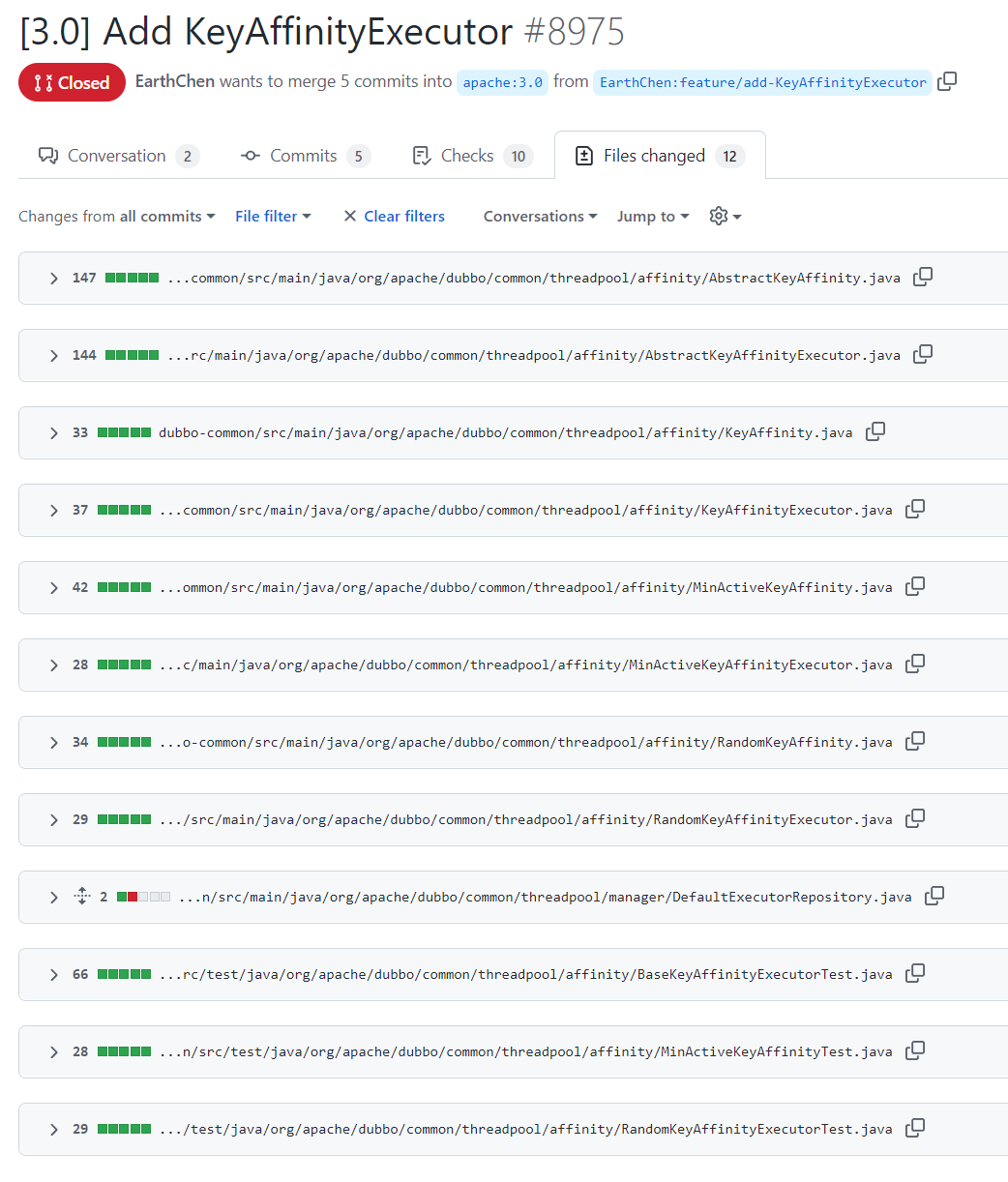
里面是可以找到我们熟悉的东西:
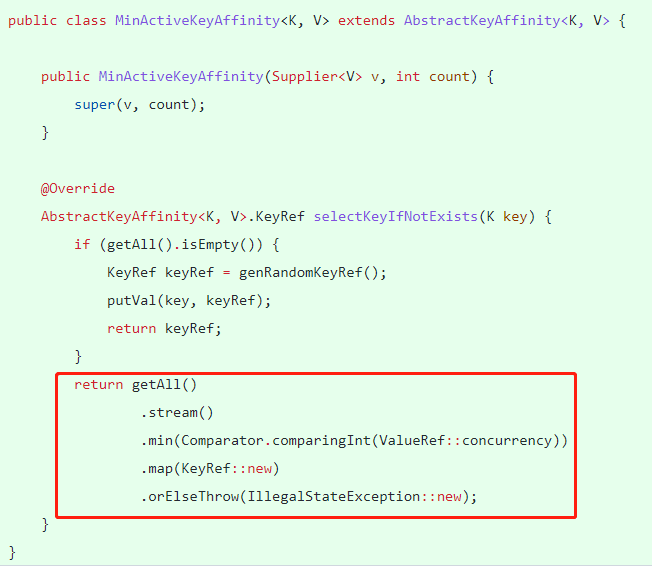
其实思路都是一样的,但是你会发现即使是思路一样,但是两个不同的人写出来的代码结构还是很不一样的。
Dubbo 这里把代码的层次分的更加明显一点,比如定义了一个抽象的 AbstractKeyAffinity 对象,然后在去实现了随机和最小并发两种方案。
在这些细节处上是有不同的。
但是这个代码的提供者最终没有用这些代码,而是拿出了一个替代方案:
https://github.com/apache/dubbo/pull/8999
在这一次提交里面,他主要提交了这个类:
org.apache.dubbo.common.threadpool.serial.SerializingExecutor
这个类从名字上你就知道了,它强调的是串行化。
带大家看看它的测试用例,你就知道它是怎么用的了:
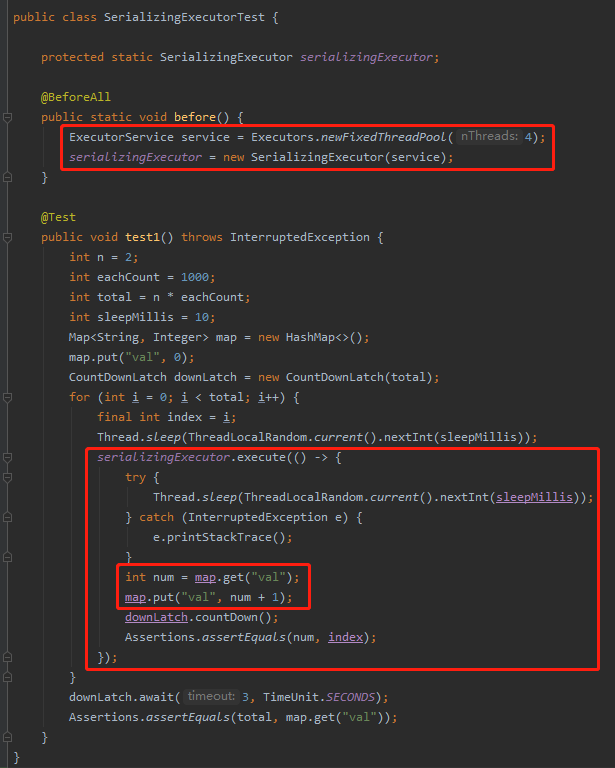
首先是它的构造方法入参是另外一个线程池。
然后提交任务的时候用 SerializingExecutor 的 execute 方法进行提交。
在任务内部,干的事就是从 map 里面取出 val 对应的 key ,然后进行加 1 操作再放回去。
大家都知道上面的这个操作在多线程的情况是线程不安全的,最终加出来的结果一定是小于循环次数的。
但是,如果是单线程的情况下,那肯定是没问题的。
那么怎么把线程池映射为单线程呢?
SerializingExecutor 干得就是这事。
而且它的原理特别简单,核心代码就几行。
首先它自己搞了个队列:
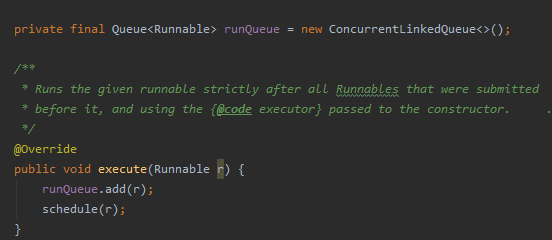
提交进来的任务都扔到队列里面去。
接下来再一个个的执行。
怎么保证一个个的执行呢?
方法有很多,它这里是搞了个 AtomicBoolean 对象来控制:
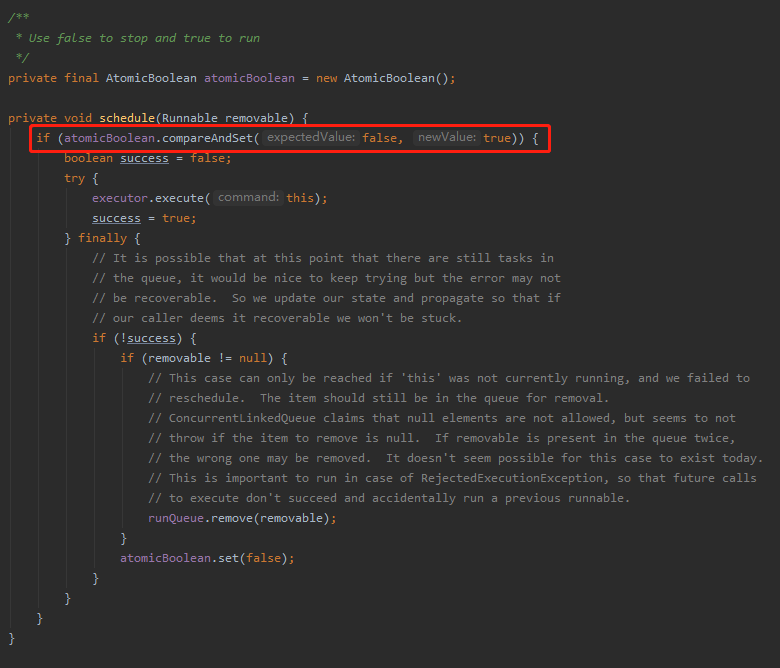
这样就实现了把多线程任务搞成串行化的场景。
只是让我奇怪的是 SerializingExecutor 这个类目前在 Dubbo 里面并没有使用场景。
但是,如果你时候你就要实现这样奇怪的功能,比如别人给你一个线程池,但是到你的流程里面出入某种考虑,需要把任务串行化,这个时候肯定是不能动别人的线程池的,那么你可以想起 Dubbo 这里有一个现成的,比较优雅的、逼格较高的解决方案。
最后说一句
好了,看到了这里了, 转发、在看、点赞随便安排一个吧,要是你都安排上我也不介意。写文章很累的,需要一点正反馈。
给各位读者朋友们磕一个了:

本文已收录至个人博客,欢迎大家来玩。
https://www.whywhy.vip/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号