Redis挂了,流量把数据库也打挂了,怎么办?
你好呀,我是歪歪。
是这样的,前几天有个读者给我发消息,说面试的时候遇到一个场景题:
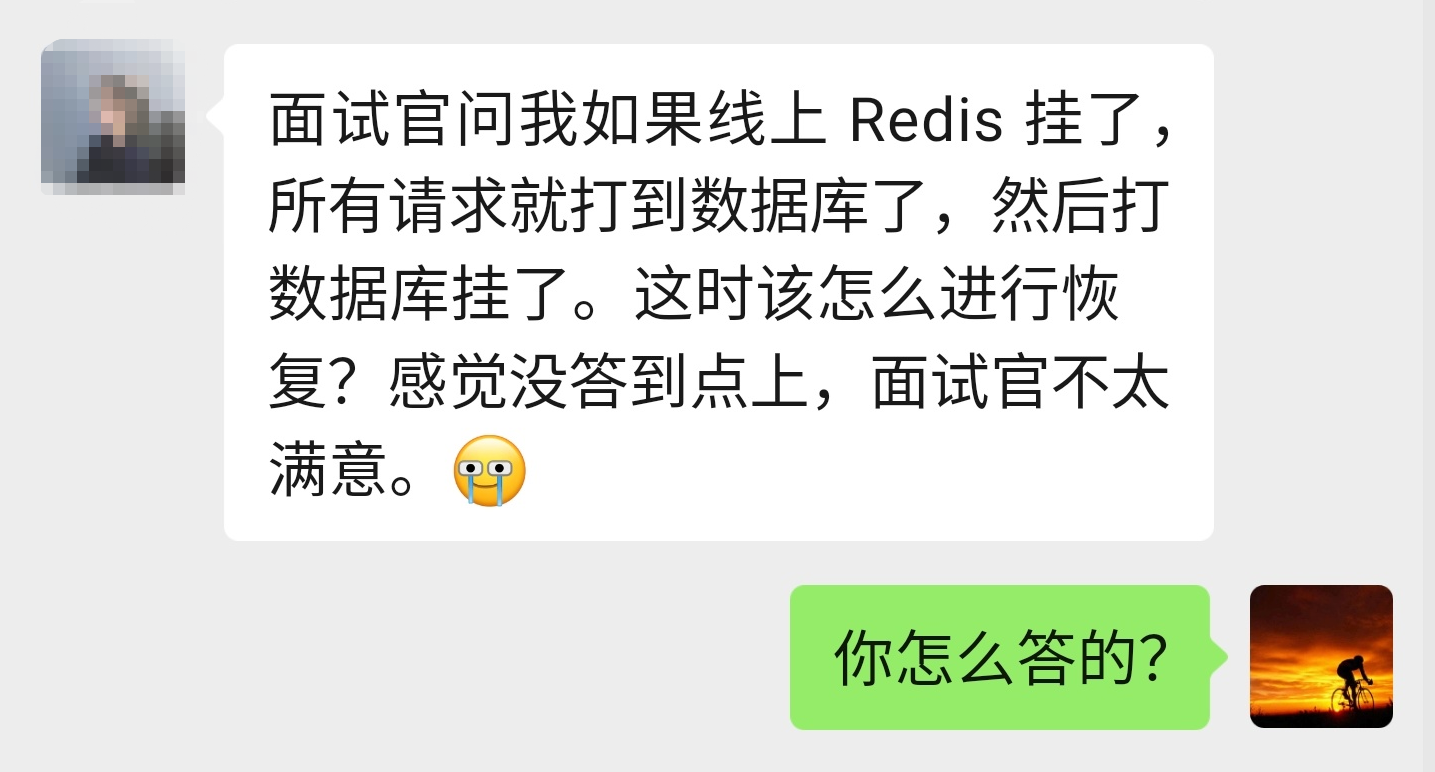
他说他当时,一时间竟然找不到回答问题的角度,感觉自己没有回答到点子上。
我仔细想了一下,确实是感到这个问题有一丝丝的奇怪,有一种让人千言万语,又突然懵逼不知从何说起的神奇力量。
为什么这么说呢?
我们先读题啊,仔细的读一遍题,我给你翻译一下。
如果线上 Redis 挂了。然后所有请求打到数据库导致数据库也挂了。
这是啥?
Redis 挂了,不就是缓存都没了吗?
缓存都没了,不就是缓存雪崩了吗?
缓存雪崩了,不就导致数据库挂了吗?
一提到“缓存雪崩”这四个字,缓存穿透、缓存击穿这几兄弟,是不是就立马条件反射的出现在你的脑海里面了,还顺带着对应的几套解决方案。
然后就像背书似的,什么缓存全没了,什么缓存没有数据库中有,什么缓存和数据库中都没有...

张口就是几分钟不带停顿的。
另外关于缓存击穿和缓存穿透,很多同学都会搞混。
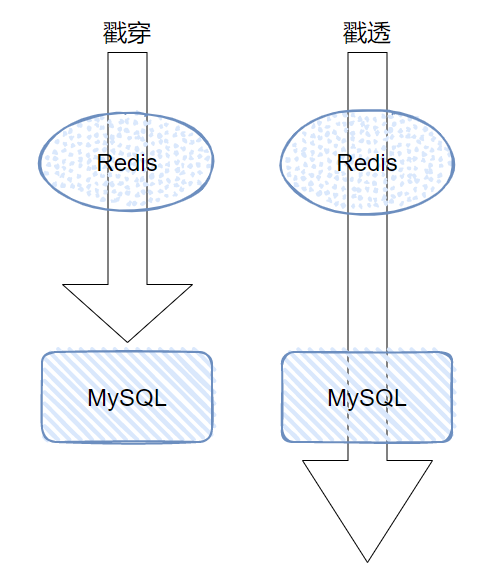
你换一个记法,缓存戳穿、缓存戳透。
穿,只是穿过了缓存。
透,是直接干到底。
你细品,应该就不会记混。
除了上面的“Redis 缓存三连击”这一套八股文之外,还隐藏着另外一个八股文:
Redis 挂了,为什么挂了?怎么就挂了?是不是有单点问题?
这不就是问你 Redis 服务的高可用吗?
说到 Redis 的高可用,脑子里面必须马上蹦出来主从、哨兵和集群吧?
想到这些了,张口又是几分钟不带停顿的。
但是这几分钟的千言万语,马上就被下面这个问题给干懵逼了?
这时该怎么进行恢复?
现在问你怎么恢复,就是事中的事儿了。
你得先说怎么恢复,再说怎么预防。
你要是上来就回答前面说的什么“缓存三连击”、“高可用架构”,还包括大多数同学能想到的多级缓存、限流措施、服务降级、熔断机制,这些都有点牵强。
因为毕竟这些手段都是事前的预防措施,上来就说这些背书痕迹比较明显。
答肯定是要答的,从事中恢复过度到事前预防方案,而且重点就是事前预防,那么我们怎么过度的自然一点呢?
先说事中怎么恢复,其实我觉得几句话就说完了。
服务挂了啊,老哥,还能怎么恢复,当然是重启服务啊。
站在运维人员的角度,当然优先考虑是先把 Redis 和数据库服务重新启动起来啦。
但是启动之前得先做个小操作,把流量摘掉,可以先把流量拦截在入口的地方,比如简单粗暴的通过 Nginx 的配置把请求都转到一个精心设计的错误页面,就是说这么一个意思。
这样做的目的是为了防止流量过大,直接把新启动的服务,启动一个打挂一个的情况出现。
要是启动起来又扛不住了,请在心里默念分布式系统三大利器:

不行就加钱,堆机器嘛。
要觉得堆机器没啥技术含量,你就再从缓存预热的角度答一个。
就是当 Redis 服务重新启动后,通过程序先放点已知的热点 key 进去后,系统再对外提供服务,防止缓存击穿的场景。
而且上面这一系列操作其实和开发人员的关系不大,主要是运维同学干的事儿。
开发同学最多就是在设计服务的时候做到服务无状态,以达到快速水平扩容的目的。
至于怎么去快速水平扩容,那是运维同学的事儿,暂时不要去抢别人的饭碗。
答到这,你就可以用“但是”来过度到事前预防,开始自己的表演了。
故作沉思的对面试官说“but”了:

我觉得从技术方案的角度来说,我们应该做到事前预防。
这一切的问题都是因为 Redis 崩了,也就是发生了缓存雪崩。
在高并发的情况下,除了缓存雪崩,我们还必须得考虑到缓存的击穿、穿透问题。
而且 Redis 为什么会崩了?是不是使用姿势不对?是不是没有保证高可用?
服务中是不是需要考虑限流或者熔断机制,最大程度的保护程序的运行?
或者我们是否应该建立多级缓存的机制,防止 Redis 挂掉之后,大批流量直接打到 MySQL 服务导致数据库的崩盘?
至此,“but”完成,答题的方向从事中恢复,转向了事前预防,进入了我们的强项,八股文专场,然后就可以开始“背诵”了。
我这里简单的聊一下缓存问题三连击和 Redis 的高可用。
至于多级缓存,可以看看我之前发的这篇文章:《这波舒服了,落地多级缓存!》。
缓存击穿
先说一下缓存击穿的概念。
缓存击穿是指一个请求要访问的数据,缓存中没有,但数据库中有的情况。

这种情况一般来说就是缓存过期了。
但是这时由于并发访问这个缓存的用户特别多,这是一个热点 key,这么多用户的请求同时过来,在缓存里面没有取到数据,所以又同时去访问数据库取数据,引起数据库流量激增,压力瞬间增大,直接崩溃给你看。
所以一个数据有缓存,每次请求都从缓存中快速的返回了数据,但是某个时间点缓存失效了,某个请求在缓存中没有请求到数据,这时候我们就说这个请求就"击穿"了缓存。
针对这个场景,对应的解决方案一般来说有三种。
第一个就是只放行一个请求到数据库,然后做构建缓存的操作。
多个请求只放行一个,怎么做?
就借助 Redis setNX 命令设置一个标志位就行。设置成功的放行,设置失败的就轮询等待。
第二个解决方案就是后台续命。
这个方案的思想就是,后台开一个定时任务,专门主动更新即将过期的数据。
比如程序中设置 why 这个热点 key 的时候,同时设置了过期时间为 10 分钟,那后台程序在第 8 分钟的时候,会去数据库查询数据并重新放到缓存中,同时再次设置缓存为 10 分钟。
怎么样,是不是有点 Redisson 分布式锁看门狗的味道?
我觉得思想是一脉相承的。
只是方案落地的时候,从代码编写的角度来说稍微麻烦了一点。
我曾经也借助这个思想开发过一个流水号系统。
大概是这样的。
流水号系统,属于非常关键的系统,为了降低数据库异常对服务带来的冲击,所以服务启动后会就会为每种业务系统都预先在缓存中缓存 5000 个流水号。
然后后台 Job 定时检查缓存中还剩下多少流水号,如果小于 1000 个,则再预先生成新的流水号,补充到缓存中,让缓存中的流水号再次回到 5000 个。
这样做的好处就是数据库异常后,我至少保证还有 5000 个缓存可以保证上游业务,我有一定的时间去恢复数据库。
这也算是一种后台续命的思想。
第三个方法就简单了:永不过期。
缓存为什么会被击穿,是不是因为设置了超时时间,然后被回收了?
那我不设置超时时间不就行了?
如果结合实际场景你用脚趾头都能想到这个 key 一定会是个热点 key,会有大量的请求来访问这个数据。而且这个 key 对应的 value 不会发生变化。
对于这样的数据你还设置过期时间干什么?
直接放进去,永不过期。
其实上面的后台续命思想的最终体现是也是永不过期。
只是后台续命的思想,会主动更新缓存,适用于缓存会变的场景。会出现缓存不一致的情况,取决于你的业务场景能接受多长时间的缓存不一致。
总之,具体情况,具体分析。
但是思路要清晰,最终方案都是常规方案的组合或者变种。
缓存穿透
那么啥又是缓存穿透呢?
缓存穿透是指一个请求要访问的数据,缓存和数据库中都没有,而用户短时间、高密度的发起这样的请求,每次都打到数据库服务上,给数据库造成了压力。

一般来说这样的请求属于恶意请求。
就比如说,我这是一个技术公众号,你明明知道我没有,但是你非要来我这里买一瓶啤酒,恶意请求。
怎么解决呢?
两个方案。
第一个缓存空对象。
就是在数据库即使没有查询到数据,我们也把这次请求当做 key 缓存起来,value 可以是 NULL。
下次同样请求就会命中这个 NULL,缓存层就处理了这个请求,不会对数据库产生压力。
这样实现起来简单,开发成本很低。
但这样随之而来的一个面试题必须要注意一下:
对于恶意攻击,请求的时候key往往各不相同,且只请求一次,那你要把这些 key 都缓存起来的话,因为每个 key 都只请求一次,那还是每次都会请求数据库,没有保护到数据库呀?
这个问题,布隆过滤器,了解一下?
关于布隆过滤器我之前写过这篇文章,可以看看:《布隆,牛逼!布谷鸟,牛逼!》
布隆过滤器的特性是说某个值存在时,这个值可能不存在。当它说不存在时,那就肯定不存在。
所以可以基于这个特性,把已有数据都构建到布隆过滤器里面去。
然后它可以帮忙挡住绝大部分的攻击。
但是还有个比较容易忽视的连环炮问题:
面试官:布隆过滤器容量有限且不支持删除,随着里面内容的增加,误判率就会随之上升。请问,这个问题你们是怎么解决的?
也是两个答题方向。
首先,不支持删除的话,就换一个支持删除的布隆过滤器的轮子咯。
比如我前面的文章中提到的布谷鸟过滤器。
或者就是提前重构布隆过滤器。
比如在容量达到 50% 的时候,就申请一个新的更大的布隆过滤器来替换掉之前的过滤器。
只是需要注意的是,重建你得知道有那些数据需要进行重建的,所以你得有个地方来记录。
比如就是 Redis、数据库,甚至内存缓存都可以。
没落地过没关系,你底气十足的回答就行了。
你要相信,面试官八成也没落地过,你们看的说不定都是同一份资料呢。

缓存雪崩
缓存雪崩是指缓存中大多数的数据在同一时间到达过期时间,而查询数据量巨大,这时候,又是缓存中没有,数据库中有的情况了。

请求都打到数据库上,引起数据库流量激增,压力瞬间增大,直接崩溃给你看。
和前面讲的缓存击穿不同的是,缓存击穿指大量的请求并发查询同一条数据。
缓存雪崩是不同数据都到了过期时间,导致这些数据在缓存中都查询不到,
雪崩,还是用的很形象的。
防止雪崩的方案简单来说就是错峰过期。
在设置 key 过期时间的时候,在加上一个短的随机过期时间,这样就能避免大量缓存在同一时间过期,引起的缓存雪崩。
如果发了雪崩,我们可以有服务降级、熔断、限流手段来拒绝一些请求,保证服务的正常。
但是,这些对用户体验是有一定影响的。假设我们的程序有这的逻辑,也是拿来兜底的,从用户的角度来说,是不希望走到这样的逻辑中去。
所以,还是以预防雪崩为主。
最后还有一种雪崩,就是整个 Redis 服务都挂了。
所以,接下来就要聊聊 Redis 服务的高可用架构了。
Redis 高可用架构
聊到 Redis 高可用架构,大家基本上都能想到主从、哨兵、集群这三种模式。
主从结构很简单,就不说了,其弊端主要是出现故障的时候需要人工介入干预,需要人工介入的,就不是真正的高可用。
哨兵和集群这两种是写在官网上的方案:
https://redis.io/topics/introduction

上面划线的话翻译过来就是:Redis 通过 Redis 哨兵(Sentinel)和 Cluster 集群提供高可用性(high availability)。
其中,哨兵是官方推荐的高可用方案(official high availability solution):

所以主要说一下哨兵模式。
哨兵是用来管理多个 Redis 服务器的,我从《Redis开发与运维》一书中,拍个照片给你看看:
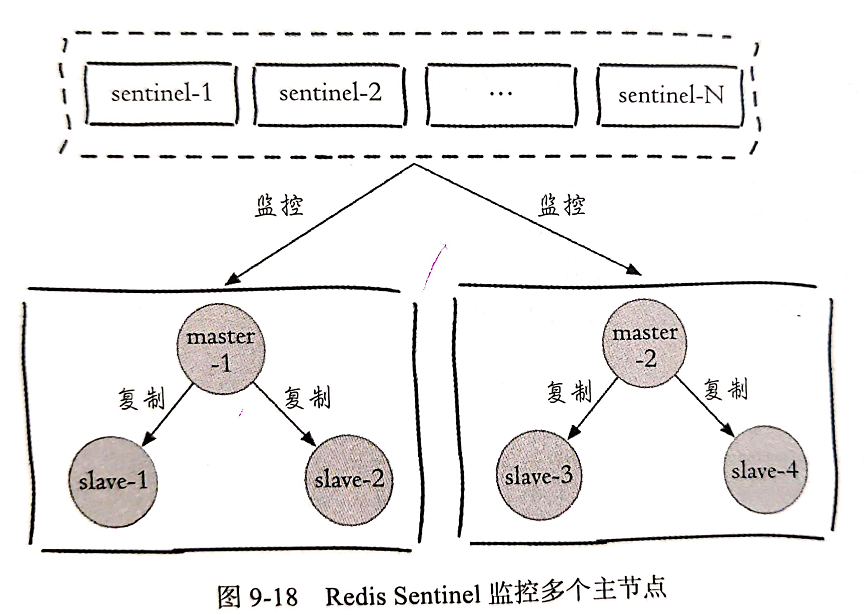
它主要执行三种类型的任务:
监控(Monitoring): Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。 提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。 自动故障迁移(Automatic failover): 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作, 它会将失效主服务器的其中一个从服务器升级为新的主服务器, 并让失效主服务器的其他从服务器改为复制新的主服务器; 当客户端试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址, 使得集群可以使用新主服务器代替失效服务器。
哨兵其实也是一个分布式系统,我们可以运行多个哨兵。
然后这些哨兵之间需要相互通气,交流信息,通过投票来决定是否执行自动故障迁移,以及选择哪个从服务器作为新的主服务器。
哨兵之间采用的协议是 gossip,是一种去中心化的协议,达成的是最终一致性,非常有意思,
之前写过的凤凰架构里面有关于 gossip 协议的介绍,可以看看:

https://icyfenix.cn/distribution/consensus/gossip.html
另外,如果主节点挂了,哨兵到底通过什么规则选择新的主节点,也就是选举过程大致是怎么样的,也偶现于面试环节。
我以前就被问到过,幸好当时背的熟练。
简单说一下规则,无它,背诵就完事了:
在挂了的主节点下挂的从节点中,被标记为主观下线、已断线、或者最后一次回复 PING 命令的时间大于五秒钟的从节点都没有资格参与选举。 在挂了的主节点下挂的从节点中,那些与挂了的主节点连接断开的时长超过 down-after 配置指定的时长十倍的从节点都没有资格参与选举。 经过上面这两轮淘汰之后,剩下来的从服务器中,选出复制偏移量(replication offset)最大的那个从服务器作为新的主服务器。如果复制偏移量不可用,或者从服务器的复制偏移量相同,那么带有最小运行 ID 的那个从服务器成为新的主服务器。
其实执行上面这些操作的,是一个哨兵。而我们的哨兵一般是三个以上,那么那个哨兵来执行这些操作呢?
其实这个哨兵也是需要从多个哨兵中被选举一个出来的,被选出来的这个哨兵就是领头哨兵(leader Sentinel)。
选举领头哨兵的时候,采取的是 Raft 算法。
至于哨兵模式的搭建,一般来说是运维干的事儿。
但是网上的搭建教程很多,能自己跟着教程亲自搭一波那就更好了。
相信我,搭建的过程中你一定会碰到各种各样的问题,而这些问题就是你的收获。
回到开始
这一小节,我们回到最开始的这个面试题:
其实看到这个问题的时候,我就想到了老是被爆来爆去的微博。
刚好,这周又吃了一波吴某凡的瓜,当时还正在看女排的直播,看到报道的时候,表情大概是这样的:
.png)
周六的晚上基本上就是带着这个表情瓜田里面上蹿下跳的,真是太好吃了。
但是凡凡这一波,不知道是凡凡的流量不行了,还是微博的架构经受住了考验。
微博竟然还比较顺滑,没有出现大范围的、非常明显的服务挂掉的现象。
我印象中最近一次微博挂的死死的,就是鹿晗关晓彤那事了。
倒不是因为我关注他们,而是我关注到了那天正在结婚的程序员。
要说这位丁振凯同学也真是太惨了。
结婚的时候碰上鹿晗公布恋情。海外度假时撞上双宋官宣。老婆待产的时候撞上华晨宇承认和张碧晨未婚生有一女。
这次我去看了,表现比较淡定。应该是在一手抱娃,一手扩容,顺便吃瓜。
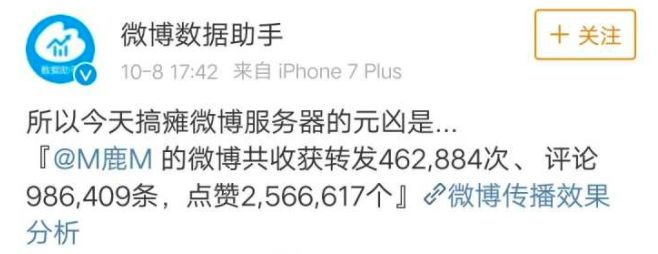
当年鹿晗这事,微博助手说挂掉是因为单条微博转发、评论次数太多了。
这是不全面的,单纯的转发评论多,并不能压垮大微博。而且鹿晗的那天微博应该也不是他所以的微博中转发评论最多的一条。
是因为转发、评论并发太高太高太高了,是我一辈子都接触不到的瞬间流量。
吃瓜群众也蜂拥而至,短时间内同时在线迅速爆涨,把服务器干掉了:
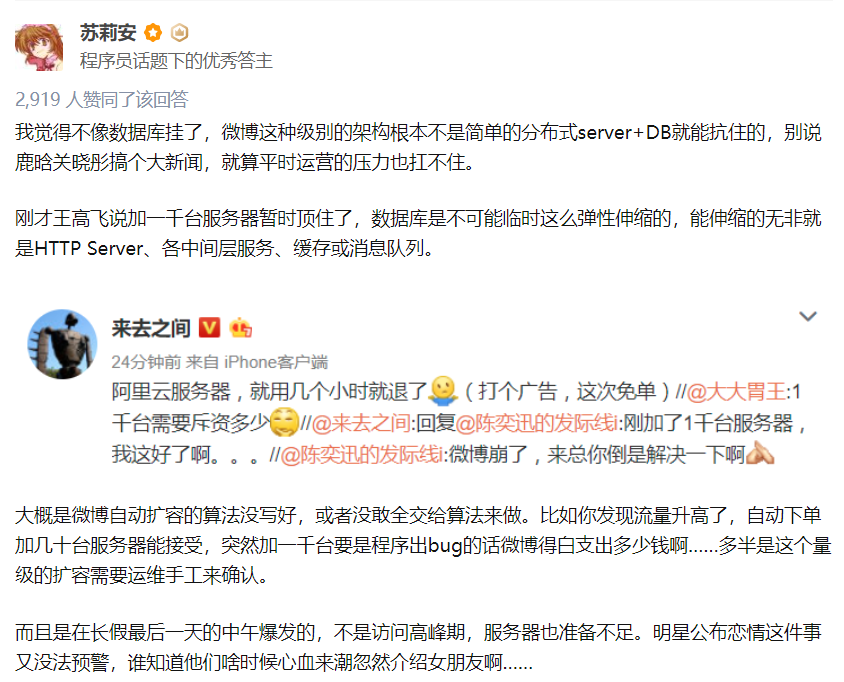
关于这个问题,我在知乎上看到一个评论,我觉得挺好的,搬运截图一下:
https://www.zhihu.com/question/66346687
你看,这个场景和面试官问的问题是不是有点相似?
强如微博,也是加了 1000 台服务器来应对这次流量洪峰。
所以,服务挂了怎么办?
重启。
重启还不行怎么办?
加钱,扩机器。
要是鹿晗关晓彤事件,著名狗仔卓伟能提前爆个料,打个提前量。
也许,微博就能抵抗的住那一波流量洪峰。
要是吴签这事,北京警方能和微博提前通通气,在发布之前先通知一下微博的相关人员,哪怕提前10分钟呢?
也许,就有更多的人能顺畅丝滑的吃瓜。
最后说一句(求关注)
好了,看到了这里安排个关注吧,周更很累的,需要一点正反馈。
感谢您的阅读,我坚持原创,十分欢迎并感谢您的关注。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号