关于“语雀故障公告”的学习与思考:可监控!可灰度!可回滚!
你好呀,我是歪歪。
昨天晚上语雀发布了关于 10 月 23 日的故障公告,公告中关于故障的时间点梳理如下:
这是公告链接:https://mp.weixin.qq.com/s/WFLLU8R4bmiqv6OGa-QMcw
14:07 数据存储运维团队收到监控系统报警,定位到原因是存储在升级中因新的运维工具 bug 导致节点机器下线; 14:15 联系硬件团队尝试将下线机器重新上线; 15:00 确认因存储系统使用的机器类别较老,无法直接操作上线,立即调整恢复方案为从备份系统中恢复存储数据; 15:10 开始新建存储系统,从备份中开始恢复数据,由于语雀数据量庞大,此过程历时较长; 19:00 完成数据恢复,同时为保障数据完整性,在完成恢复后,用时 2 个小时进行数据校验; 21:00 存储系统通过完整性校验,开始和语雀团队联调。 22:00 恢复语雀全部服务,用户所有数据均未丢失。
我们一起盘一下这个时间点,多从别人的事故中总结经验教训,学习避坑指南。

14:07
首先第一个时间点,14:07,数据存储运维团队收到了健康系统的报警,然后开始定位问题。
我翻了一下微博,这个时间点几乎和微博话题“#语雀崩了#”下的一条微博的时间点能对应上,而且还早了 7 分钟。
不要小看这 7 分钟,这说明系统人员先于用户感知到了问题的存在,说明监控系统的预警是有效的。
不知道在其他公司是什么规定,但是在歪师傅所在的公司,一切生产问题,只要是有监控手段、是通过监控系统自主发现的、上报故障时间早于用户反馈的,不管最后的情况又多严重,都会一定程度上的减轻惩罚力度。
甚至对于一些属于严重 BUG 但是没有造成严重后果的,因为有监控的存在,监控及时生效,出了问题你立马就监控出来了的,是可以免责的。
监控,全方面、细粒度、低噪音、高触达的监控,非常非常重要。
这一点,从公告上来,语雀的运维团队是做到了。
但是这一点也不值得表扬,因为这样的监控本来就是应该要做到的。
14:15
这个时间点的操作是“联系硬件团队尝试将下线机器重新上线”。
这句话我确实看不懂,就不乱评论了。
但是我盲猜一个,因为我读到这句话的时候,看到“硬件”两个字的时候就自动联想到了机房里面的硬盘,所以脑海里面浮现出来的一个莫名其妙的画面是这样的:
一个运维老哥,穿着鞋套,带着帽子,站在机房里面,把硬盘一个个的拔出来,吹口气,又一个个的插进去,并仔细的观察着信号灯的情况。

15:00
从 14:15 分到 15:00,中间有 45 分钟的时间。
这 45 分钟我想应该是极其精彩的 45 分钟。
因为在这 45 分钟内,确定了之前制定的“将下线机器重新上线”方案是不可用的,而且不可用肯定不是一句话的事情,硬件团队的负责人或者其他的某个同事,需要给领导大致的汇报清楚,并探讨新的解决方案。
是的,我猜测领导也是在这 45 分钟内才知道发生了这么大的事情,因为当新方案制定出来之后,需要给领导同步一个噩耗:这个方案执行完成,需要很长的时间,乐观估计需要 3 个小时,这 3 个小时内,我们的服务将完全不可用。而且经过讨论,我们当前只有这一个方案可以使用。
所以,这 45 分钟内,发生了几个重要的事情:原方案毙了;新方案讨论;新方案执行时间太长,事件必须升级到上级领导;编写公告,同步用户。
由于运维工具的 BUG 导致当前的存储系统已经不行了,我简单的理解为就是数据库崩了,整个崩的稀碎,里面的数据“死伤无数”,救活的成本比重新搭一个还高。
因此制定出来的新方案就是:从备份系统中恢复存储数据。
所以在官方的公告下,我们才看到了这样的一句话:
预计最晚今天内,最快6点前
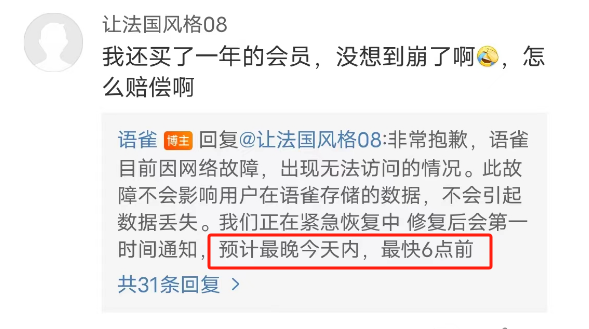
这个时间怎么估算出来的?
15 点到 16 点,3 个小时是给领导汇报的时候最乐观的情况,属于老天开眼,帮一把这个可怜的孩子,恢复数据的过程异常丝滑、毫无疑问的情况。
而最晚今天内,15 点到 24 点,有 9 个小时,多出来的 6 个小时,应该是够处理恢复过程中的异常情况了...吧?

15:10
开始架势,正式从备份文件中开始恢复数据。
在官方的公告中说到“由于语雀数据量庞大”,这个庞大到底到了什么级别就不得而知了。
反正数据恢复的事件和数据量的大小成正比。
昨天我在微博看到一个评论说的是:8 个小时,我重新开始把服务全部部署一遍也绰绰有余了。
是的,服务部署是分分钟的事情,哪怕是人肉运维也服务全部重启一边也要不了 8 个小时。
其实当时我心里就在嘀咕:不会是数据方面的问题吧。
歪师傅也算是一个久经沙场的程序猿了,以我浅薄的经验来说,对一个生产事故,定位生产 BUG,修复生产 BUG 是一件相对容易的事情,最难受的一个环节就是修复由于 BUG 导致的数据问题。
这玩意,谁遇到过,谁就知道有多痛了。
我曾经遇到过一个生产 BUG,由于参数配置错误,导致跨了好几个系统的一串数据全都算错了,而且数据的量级还不少,而且还叠加了正常业务下这些数据还在动态变化的 BUFF,要把这一批数据修复正确,我搞了半个月的时间,基本上每天都搞到 23 点之后。
从第二周的时候,心态就完全崩成渣渣了,一边搞数据一边嘟囔着:这波搞完了,我 TM 的必须要离职了,太难受了。
后来你猜怎么着?
数据搞完之后,心情一下就舒畅了,发现自己又能支棱起来了,同事私下问感受如何,我也只是轻描淡写的说了一句:这能有啥感受,能通过修数修复的问题,都不是大问题。
所以我非常理解这个“恢复时间”长的原因,涉及到数据了,没办法,急也没用。

19:00
从 15 点开始恢复,到 19 点恢复完成,用时 4 个小时,比乐观预计时间只长了一小时而已,可以说是老天保佑了,没出啥大岔子。
数据修复完成之后,语雀干了一件什么事情?
看看公告上的这句话:为保障数据完整性,在完成恢复后,用时 2 个小时进行数据校验。
首先我不管他们是真的在进行数据校验,还是为了从公告上缩短恢复数据的时间,或者其实这个时间段内还有其他步骤,或者其他什么不方便透露的原因等等,我都不关心。
我只关心这个动作:在完成恢复后,用时 2 个小时进行数据校验。
这个动作真的是太重要了,你想想,如果语雀团队在数据修复完成之后,不做这个事情,或者说只是花了几分钟时间进行了一些极其简单的验证,最后导致用户发现他的数据丢了,势必会掀起更加疯狂的舆论浪潮,导致更加严重的用户流失和口诛笔伐。
所以我认为这两个小时虽然很长,但是是非常重要的一环,哪怕最后验证的结果是确实没有数据丢失,也是非常值得的,团队心里有了底。
而在时间已经到了 19 点,宕机 6 个小时的情况下,愿意拍板再拿出 2 小时时间进行数据完整性校验的人,是个团队大心脏,稳得一笔。
处理生产事件,大家都是火急火燎的,这个时候出来一个说话有分量的人说:大家千万别急,既然事情已经发生了,我们就一点点的把事情做好,不要引入新的问题,防止事态进一步扩散。
这个人,他简直就是在发光。

之后的这两个时间点,就不再展开说了:
21:00 存储系统通过完整性校验,开始和语雀团队联调。 22:00 恢复语雀全部服务,用户所有数据均未丢失。
语雀再次强调了“用户所有数据均未丢失”,这点确实很重要,从各个平台的反馈来看,也没有看到有用户反馈数据丢失的情况。
(但是歪师傅还是不明白,明明是从备份中恢复的数据,怎么可能不丢失数据呢?哪怕一小时一备份,也至少丢一小时的数据呀。)
关于改进措施

这里面以这次故障为抓手,结合各团队通力协作,上下游拉通对齐,打出了一套组合拳,对焦本次事故,沉淀出了一份可复用的方法论,想要给系统更好的赋能:
保命箴言:可监控,可灰度,可回滚 能力建设:从同 Region 多副本容灾升级为两地三中心的高可用能力 定时演练:进行定期的容灾应急演练
在改进措施的部分,我建议所有开发,运维,包括测试同学,都应该把“可监控,可灰度,可回滚”这九个字贴在工位上,刻在脑子里,做方案、写代码、提测前、上线前都把这九个字拿出来咂摸一下。

这九个字,说起来简单,但是落地是真的难。
虽然落地难,但是是真的可以保命的,至少保过我的命。
另外这次事件从描述上来看,是运维人员的锅,所以改进措施里面也多次提到了“运维”这个关键词。
不知道这个运维老哥是否被开除了,这很难说。
但是通过这个事情,或者我遇到过的一些生产事故来说,我想要表达的,如果一个公司或者团队,遇到事情之后,第一反应是找对应的责任人出来处罚、开除某些人、扣某些人的绩效等等这些惩罚手段,那么带来的后果是大家再次遇到事情的时候,第一反应就是先甩锅,把自己撇干净,或者先隐瞒,瞒住了就过去了,瞒不住就导致更大的问题,这样很不好。
正确的做法应该是拿着相关人员进行整个事件的复盘,看看这次事件到底暴露了哪些问题。
就拿语雀的这次事件来说:生产运维操作,运维工具有 BUG,那么是否经过充分的测试?是否留有足够的灰度观察时间?是否有双人复核机制?是否有生产紧急事件预案?等等...
这些都是流程上的问题,而不是某个运维人员的问题。
或者说应该是先找流程上的问题,那么最后才是找到某个具体的人身上。
有了流程,经过了流程评审,形成了规则制度,宣讲了规章制度,操作的人没有按照流程来,那么这个人确实该罚。
而且这个流程,应该是通过一次又一次大大小小的事件不断演进优化的流程。
最后
以上就是歪师傅通过语雀这个事情的一点看法吧,它的严重生产故障,对于我来说也是一个学习的过程。
最后,语雀给的赔偿方案还是比较有诚意的,直接给六个月会员:

那没啥说的了,反正对我没有产生什么实质上的影响,还蹭到了一波热度《语雀,这波故障,放眼整个互联网也是炸裂般的存在。》
还免费领了六个月会员。
好了,我就当没事发生了。

