这个队列的思路是真的好,现在它是我简历上的亮点了。
你好呀,我是歪歪。
前几天在一个开源项目的 github 里面看到这样的一个 pr:

光是看这个名字,里面有个 MemorySafe,我就有点陷进去了。
我先给你看看这个东西:

这个肯定很眼熟吧?我是从阿里巴巴开发规范中截的图。
为什么不建议使用 FixedThreadPool 和 SingleThreadPool 呢?
因为队列太长了,请求会堆积,请求一堆积,容易造成 OOM。
那么问题又来了:前面提到的线程池用的队列是什么队列呢?
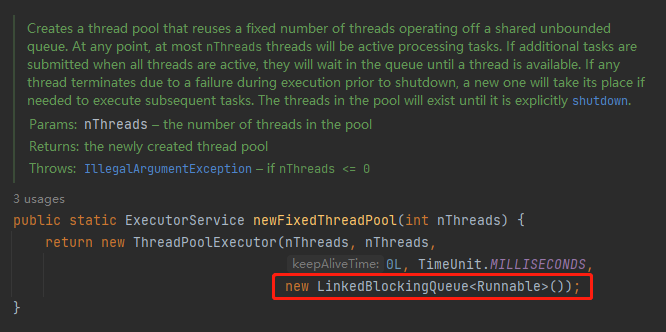
用的是没有指定长度的 LinkedBlockingQueue。
没有指定长度,默认长度是 Integer.MAX_VALUE,可以理解为无界队列了:
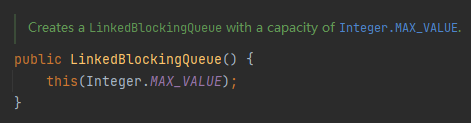
所以,在我的认知里面,使用 LinkedBlockingQueue 是可能会导致 OOM 的。
如果想避免这个 OOM 就需要在初始化的时候指定一个合理的值。
“合理的值”,听起来轻描淡写的四个字,但是这个值到底是多少呢,你说的准吗?
基本上说不准。
所以,当我看到 pr 上的 MemorySafeLinkedBlockingQueue 这个名字的时候,我就陷进去了。
在 LinkedBlockingQueue 前面加上了 MemorySafe 这个限定词。
表示这是一个内存安全的 LinkedBlockingQueue。
于是,我想要研究一下到底是怎么样来实现“安全”的,所以啪的一下就点进去了,很快啊。

MemorySafeLBQ
在这个 pr 里面我们看一下它主要是想干个什么事儿:
https://github.com/apache/dubbo/pull/10021
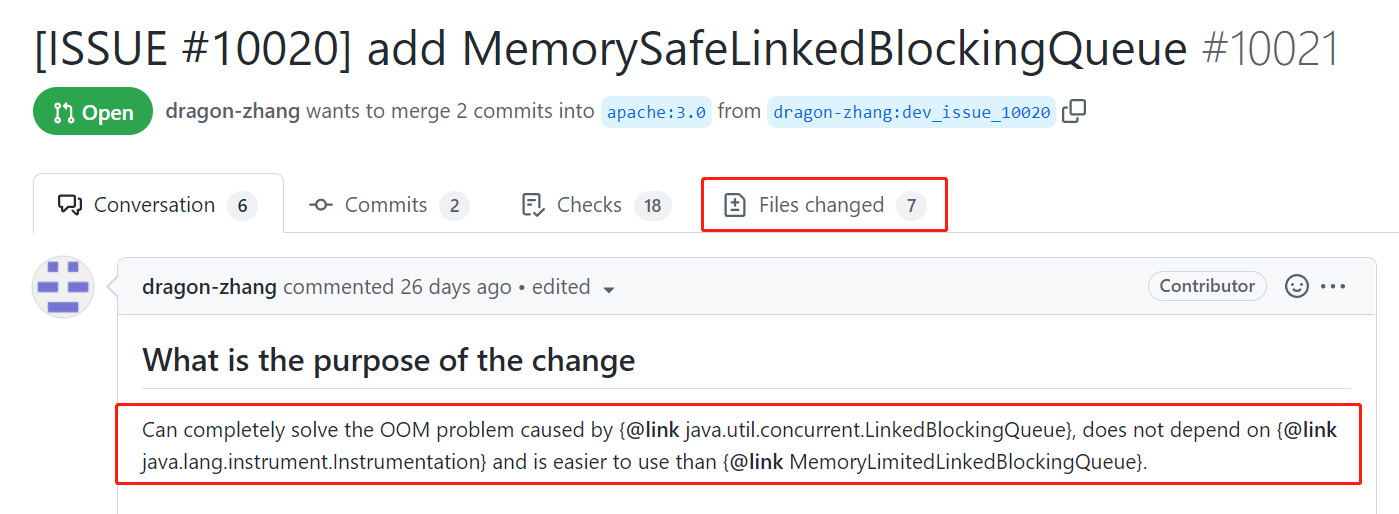
提供代码的哥们是这样描述它的功能的:
可以完全解决因为 LinkedBlockingQueue 造成的 OOM 问题,而且不依赖 instrumentation,比 MemoryLimitedLinkedBlockingQueue 更好用。
然后可以看到这次提交涉及到 7 个文件。
实际上真正核心的代码是这两个:
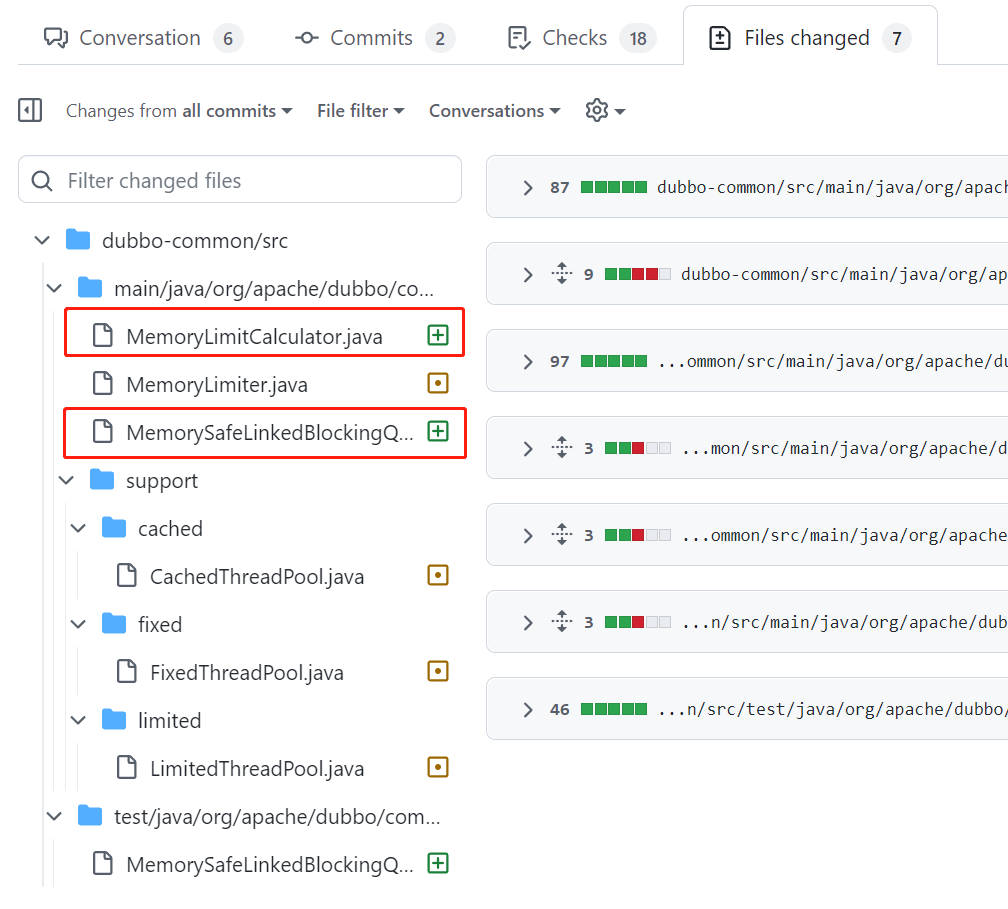
但是不要慌,先眼熟一下这两个类,然后我先按下不表。先追根溯源,从源头上讲。
这两个类的名字太长了,所以先约定一下,在本文中,我用 MemoryLimitedLBQ 来代替 MemoryLimitedLinkedBlockingQueue。用 MemorySafeLBQ 来代替 MemorySafeLinkedBlockingQueue。

可以看到,在 pr 里面它还提到了“比 MemoryLimitedLBQ 更好用”。
也就是说,它是用来替代 MemoryLimitedLBQ 这个类的。
这个类从命名上也看得出来,也是一个 LinkedBlockingQueue,但是它的限定词是 MemoryLimited,可以限制内存的。
我找了一下,这个类对应的 pr 是这个:
https://github.com/apache/dubbo/pull/9722
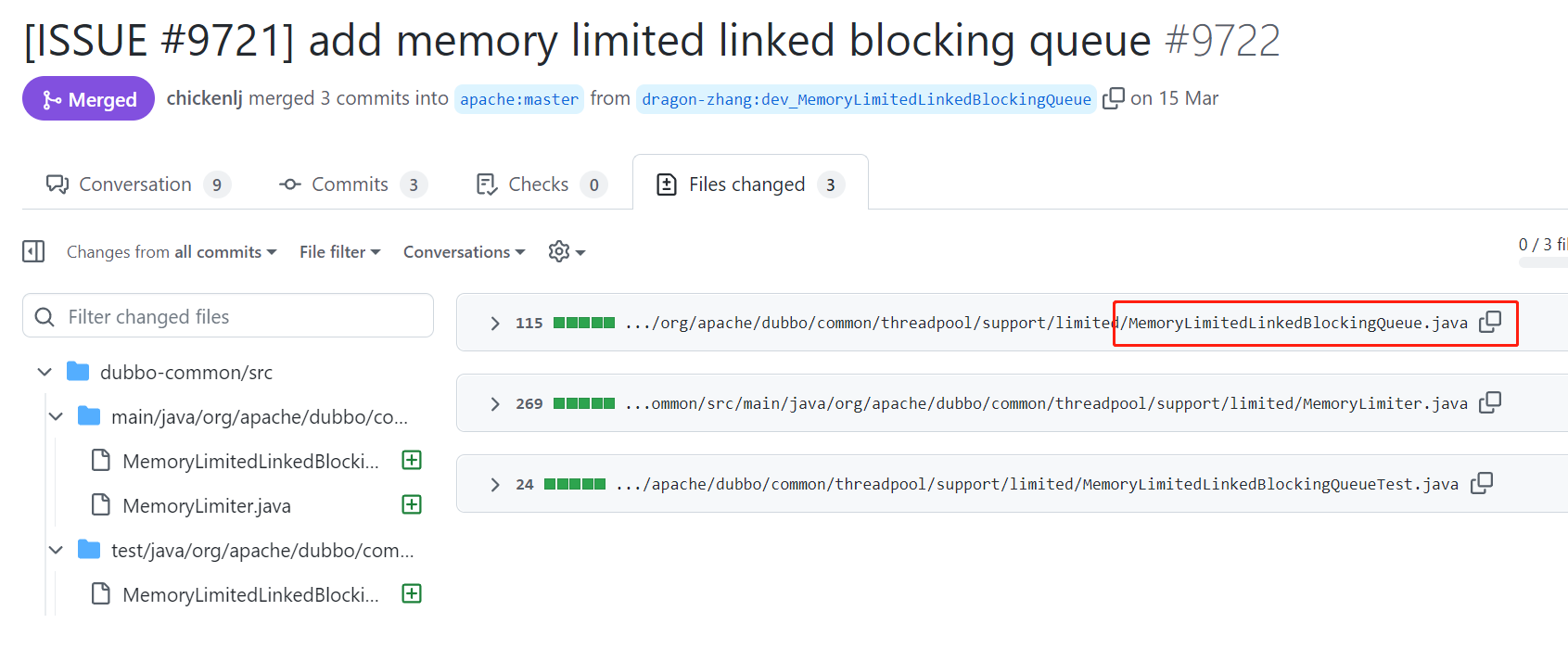
在这个 pr 里面,有大佬问他:

你这个新队列实现的意义或目的是什么?你能不能说出当前版本库中需要被这个队列取代的队列?这样我们才好决定是否使用这个队列。
也就是说他只是提交了一个新的队列,但是并没有说到应用场景是什么,导致官方不知道该不该接受这个 pr。
于是,他补充了一个回复:
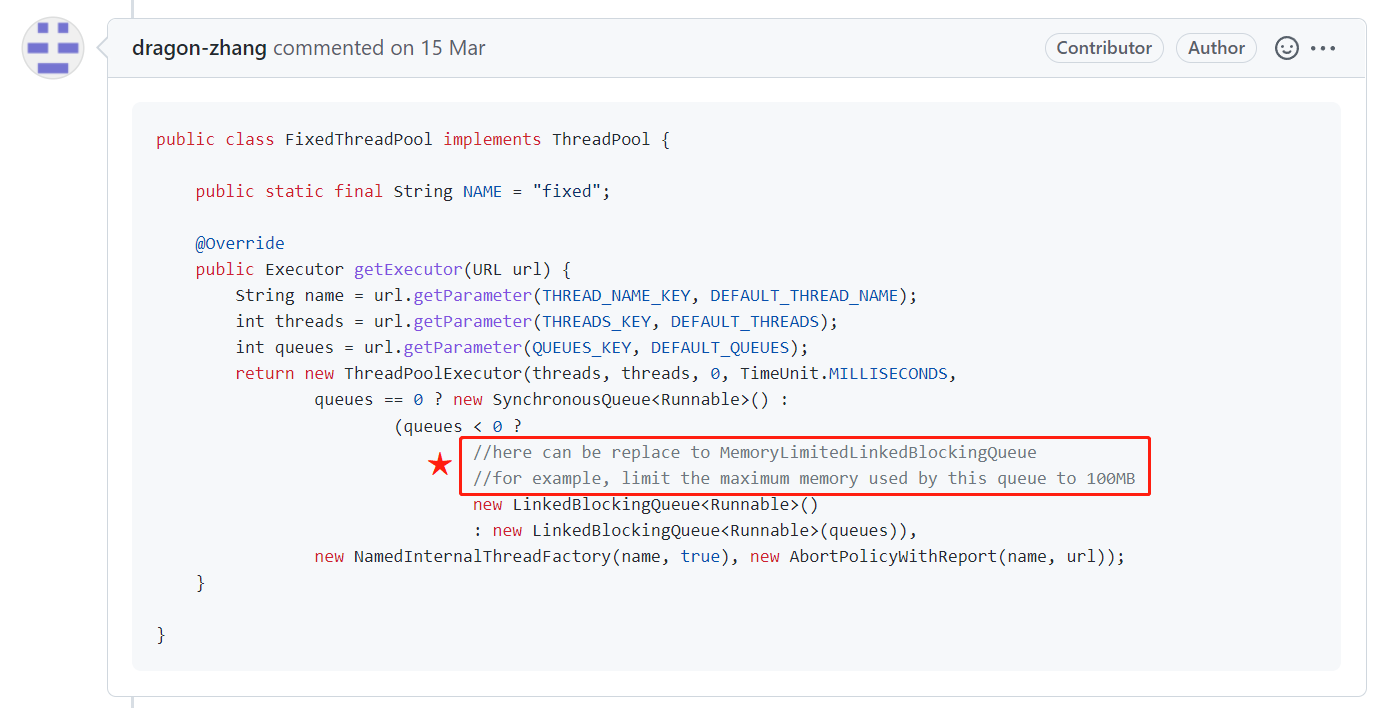
就是拿的 FixedThreadPool 做的示例。
在这个里面,就使用了无参的 LinkedBlockingQueue,所以会有 OOM 的风险。
那么就可以使用 MemoryLimitedLBQ 来代替这个队列。
比如,我可以限制这个队列可以使用的最大内存为 100M,通过限制内存的方式来达到避免 OOM 的目的。
好,到这里我先给你梳理一下。
首先应该是有一个叫 MemoryLimitedLBQ 的队列,它可以限制这个队列最大可以占用的内存。
然后,由于某些原因,又出现了一个叫做 MemorySafeLBQ 的队列,宣称比它更好用,所以来取代它。
所以,接下来我就要梳理清楚三个问题:
MemoryLimitedLBQ 的实现原理是什么? MemorySafeLBQ 的实现原理是什么? MemorySafeLBQ 为什么比 MemoryLimitedLBQ 更好用?
MemoryLimitedLBQ
别看这个玩意我是在 Dubbo 的 pr 里面看到的,但是它本质上是一个队列的实现方式。
所以,完全可以脱离于框架而存在。
也就是说,你打开下面这个链接,然后直接把相关的两个类粘出来,就可以跑起来,为你所用:
https://github.com/apache/dubbo/pull/9722/files
我先给你看看 MemoryLimitedLBQ 这个类,它就是继承自 LinkedBlockingQueue,然后重写了它的几个核心方法。
只是自定义了一个 memoryLimiter 的对象,然后每个核心方法里面都操作了 memoryLimiter 对象:
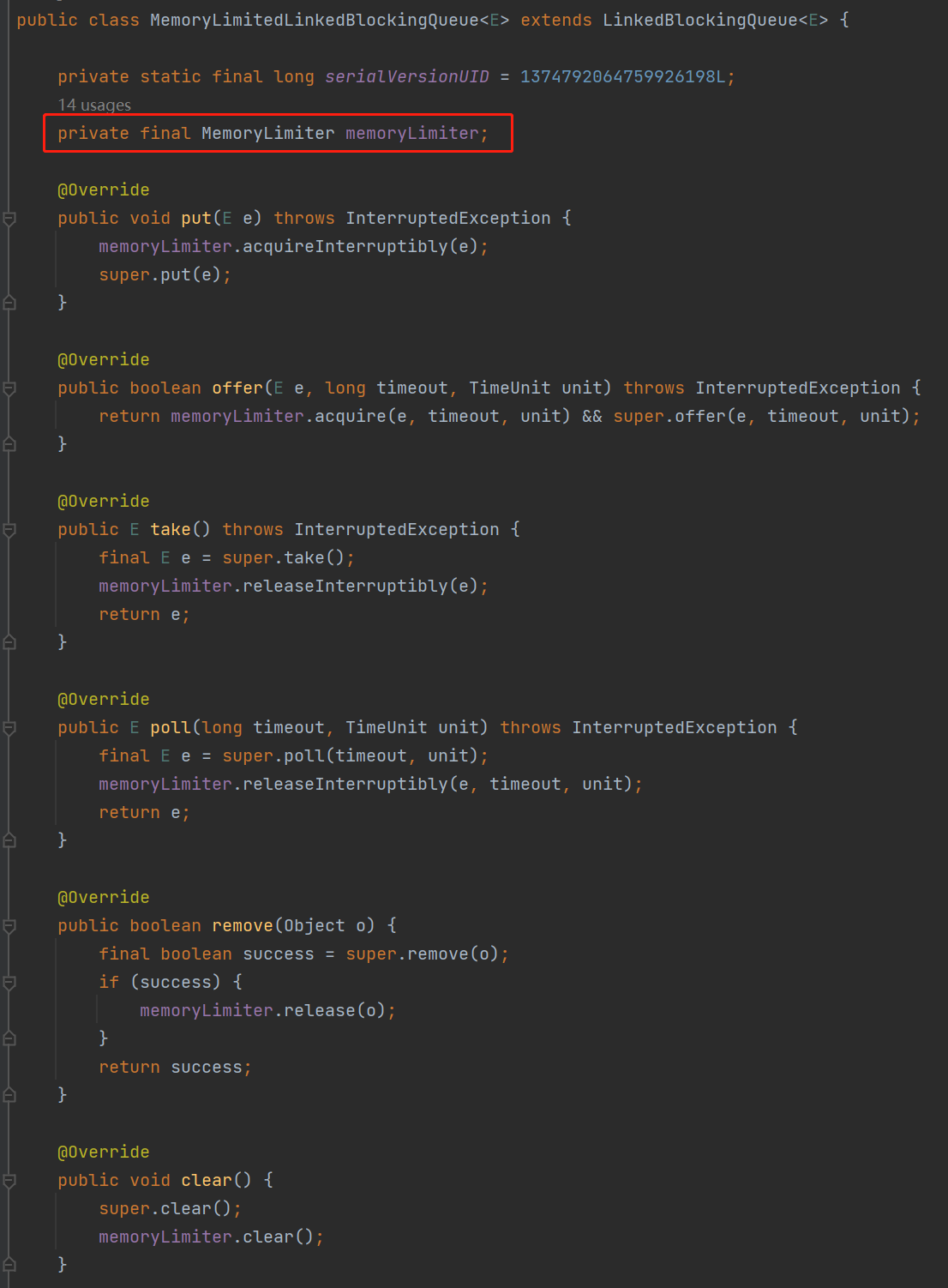
所以真正的秘密就藏在 memoryLimiter 对象里面。
比如,我带你看看这个 put 方法:
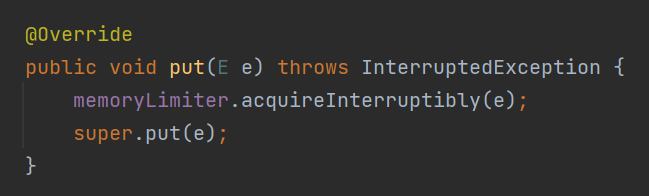
这里面调用了 memoryLimiter 对象的 acquireInterruptibly 方法。
在解读 acquireInterruptibly 方法之前,我们先关注一下它的几个成员变量:
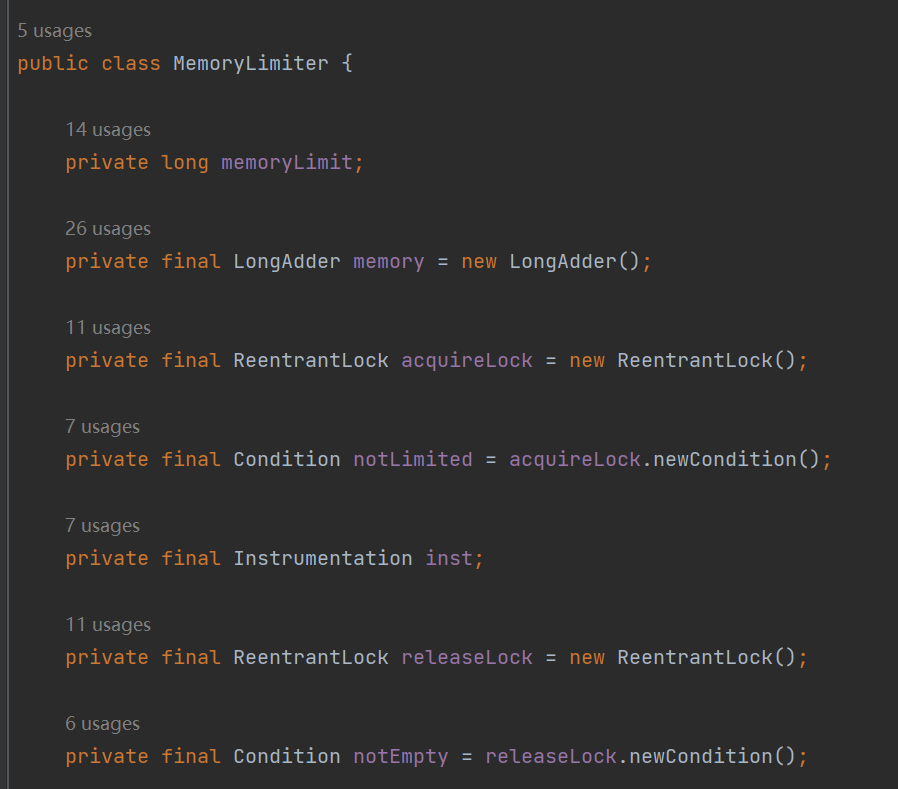
memoryLimit 就是表示这个队列最大所能容纳的大小。 memory 是 LongAdder 类型,表示的是当前已经使用的大小。 acquireLock、notLimited、releaseLock、notEmpty 是锁相关的参数,从名字上可以知道,往队列里面放元素和释放队列里面的元素都需要获取对应的锁。 inst 这个参数是 Instrumentation 类型的。
前面几个参数至少我还很眼熟的,但是这个 inst 就有点奇怪了。

这玩意日常开发中基本上用不上,但是用好了,这就是个黑科技了。很多工具都是基于这个玩意来实现的,比如大名鼎鼎的 Arthas。
它可以更加方便的做字节码增强操作,允许我们对已经加载甚至还没有被加载的类进行修改的操作,实现类似于性能监控的功能。
可以说 Instrumentation 就是 memoryLimiter 的关键点:
比如在 memoryLimiter 的 acquireInterruptibly 方法里面,它是这样的用的:
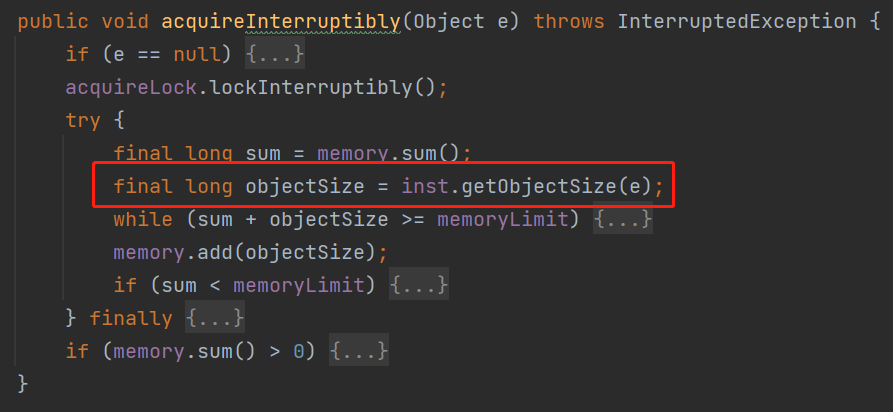
看方法名称你也知道了,get 这个 object 的 size,这个 object 就是方法的入参,也就是要放入到队列里面的元素。
为了证明我没有乱说,我带你看看这个方法上的注释:
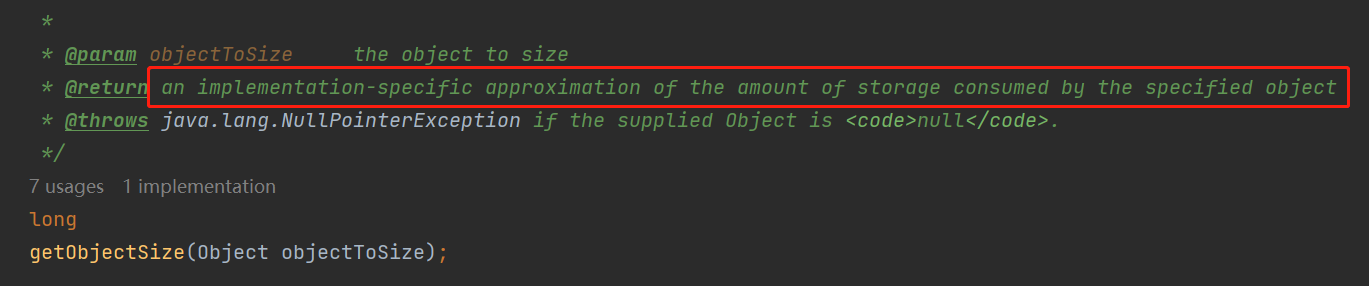
an implementation-specific approximation of the amount of storage consumed by the specified object
注意这个单词:approximation.
这可是正儿八经的四级词汇,还是 a 开头的,你要是不眼熟的话可是要挨板子的。

整句话翻译过来就是:返回指定对象所消耗的存储量的一个特定实现的近似值。
再说的直白点就是你传进来的这个对象,在内存里面到底占用了多长的长度,这个长度不是一个非常精确的值。
所以,理解了 inst.getObjectSize(e) 这行代码,我们再仔细看看 acquireInterruptibly 是怎么样的:
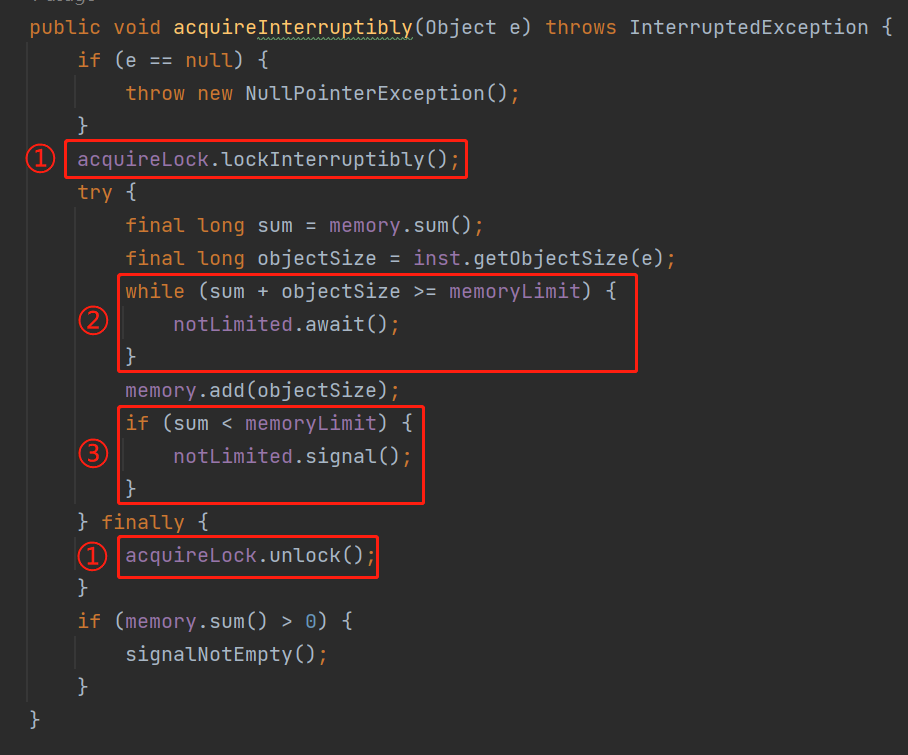
首先,两个标号为 ① 的地方,表示操作这个方法是要上锁的,整个 try 里面的方法是线程安全的。
然后标号为 ② 的里面干了什么事儿?
就是计算 memory 这个 LongAdder 类型的 sum 值加上当前这个对象的值之后,是不是大于或者等于 memoryLimit。
如果计算后的值真的超过了 memoryLimit,那么说明需要阻塞一下下了,调用 notLimited.await() 方法。
如果没有超过 memoryLimit,说明还能往队列里面放东西,那么就更新 memory 的值。
接着到了标号为 ③ 的地方。
来到这里,再次判断一下当前已经使用的值是否没有超过 memoryLimit,如果是的话,就调用 notLimited.signal() 方法,唤醒一下之前由于 memoryLimit 参数限制导致不能放入的对象。
整个逻辑非常的清晰。
而整个逻辑里面的核心逻辑就是调用 Instrumentation 类型的 getObjectSize 方法获得当前放入对象的一个 size,并判断当前已经使用的值加上这个 size 之后,是否大于了我们设置的最大值。
所以,你用脚趾头猜也能猜到了,在 release 方法里面,肯定也是计算当前对象的 size,然后再从 memory 里面减出去:
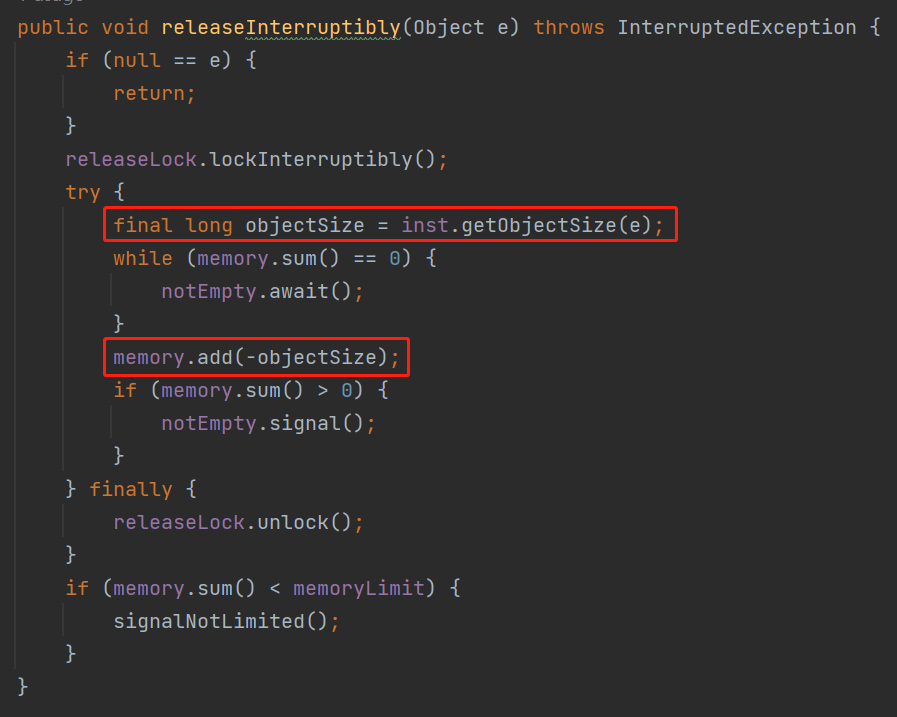
说穿了,也就这么屁大点事儿。

然后,你再次审视一下这个 acquireInterruptibly 方法的 try 代码块里面的逻辑,你有没有发现什么 BUG:
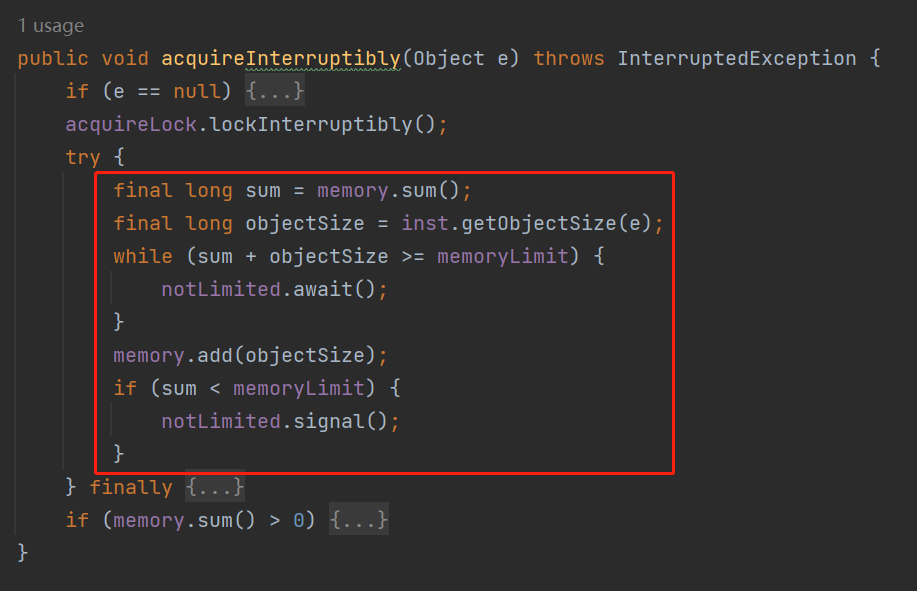
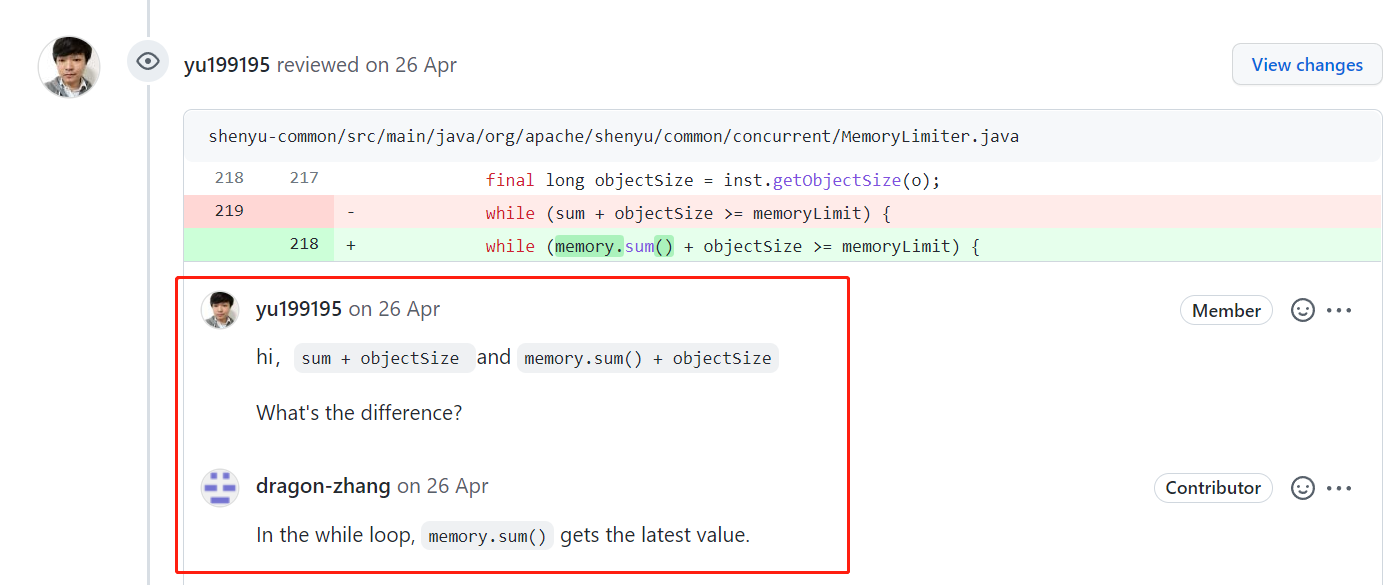
如果你没反映过来,那我再提个醒:你认真的分析一下 sum 这个局部变量是不是有点不妥?
你要是还没反应过来,那我直接给你上个代码。后面有一次提交,是把 sum 修改为了 memory.sum() :
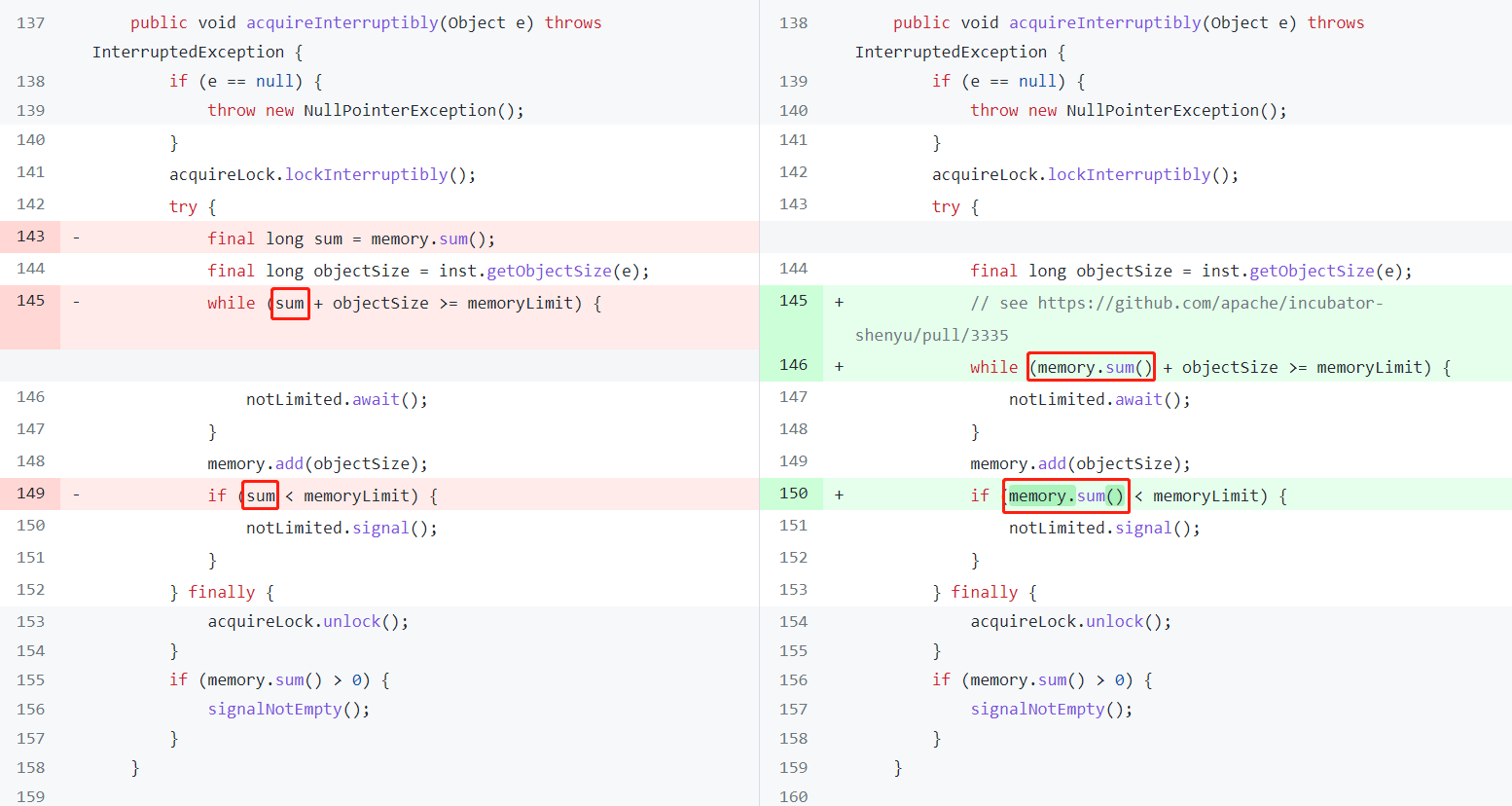
为什么这样改呢?
我给你说个场景,假设我们的 memoryLimit 是 1000,当前已经使用的 memory 是 800,也就是 sum 是 800。这个时候我要放的元素计算出来的 size 是 300,也就是 objectSize 是 300。
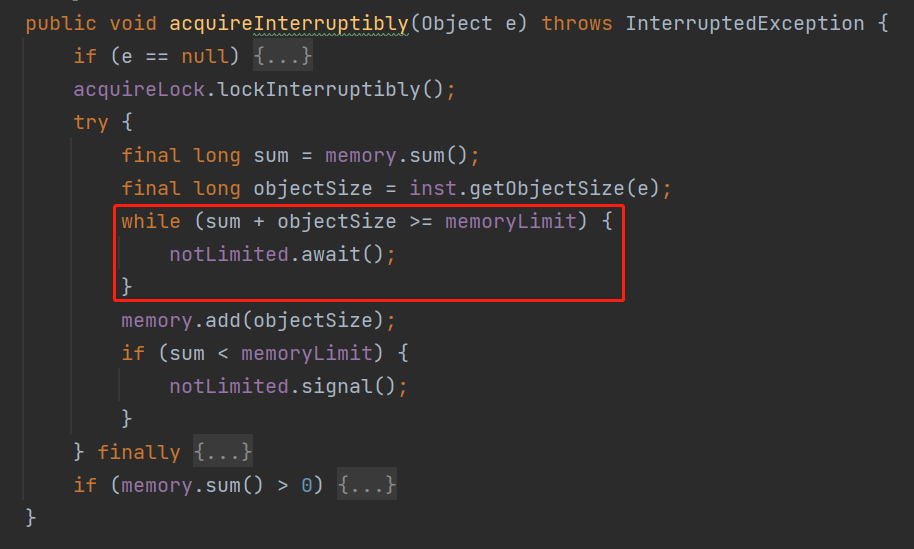
sum+objectSize=1100,比 memoryLimit 的值大,是不是在这个 while 判断的时候被拦截住了:
之后,假设队列里面又释放了一个 size 为 600 的对象。
这个时候执行 memory.add(-objectSize) 方法,memory 变为 200:
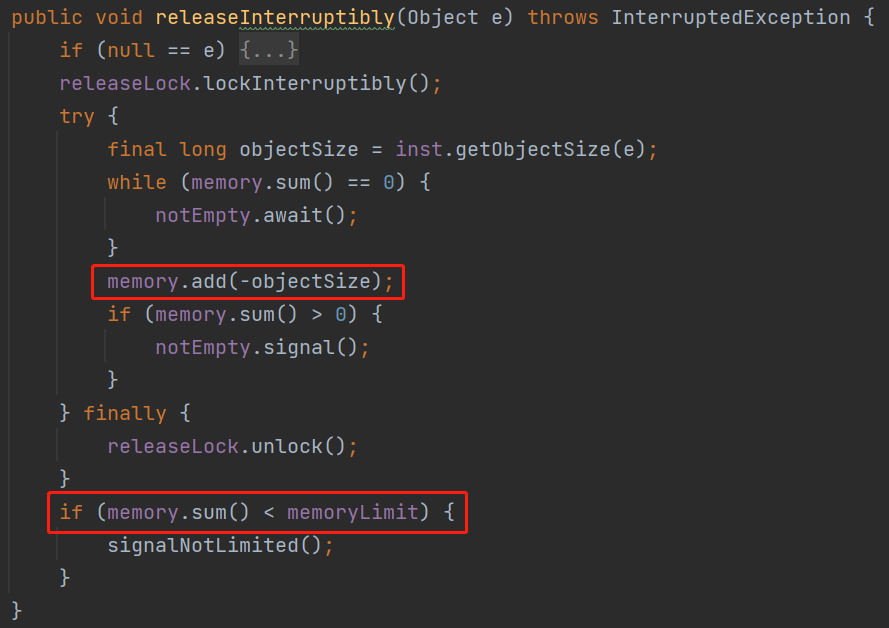
那么会调用 signalNotLimited 方法,唤醒这个被拦截的这个哥们:
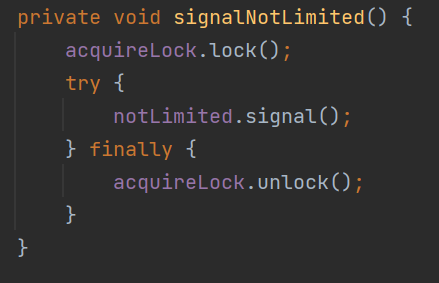
这个哥们一被唤醒,一看代码:
while (sum + objectSize >= memoryLimit) {
notLimited.await();
}
心里想:我这里的 sum 是 800,objectSize 是 300,还是大于 memoryLimit 啊,把我唤醒干啥玩意,傻逼吗?
那么你说,它骂的是谁?

这个地方的代码肯定得这样,每次都查看最新的 memory 值才行:
while (memory.sum() + objectSize >= memoryLimit) {
notLimited.await();
}
所以,这个地方是个 BUG,还是个死循环的 BUG。
前面代码截图中还出现了一个链接,就是说的这个 BUG:
https://github.com/apache/incubator-shenyu/pull/3335
另外,你可以看到链接中的项目名称是 incubator-shenyu,这是一个开源的 API 网关:

本文中的 MemoryLimitedLBQ 和 MemorySafeLBQ 最先都是出自这个开源项目。
MemorySafeLBQ
前面了解了 MemoryLimitedLBQ 的基本原理。
接下来我带你看看 MemorySafeLBQ 这个玩意。
它的源码可以通过这个链接直接获取到:
https://github.com/apache/dubbo/pull/10021/files
也是拿出来就可以放到自己的项目跑,把文件作者修改为自己的名字的那种。
让我们回到最开始的地方:
这个 pr 里面说了,我搞 MemorySafeLBQ 出来,就是为了替代 MemoryLimitedLBQ 的,因为我比它好用,而且我还不依赖于 Instrumentation。
但是看了源码之后,会发现其实思路都是差不多的。只不过 MemorySafeLBQ 属于是反其道而行之。
怎么个“反其道”法呢?
看一下源码:
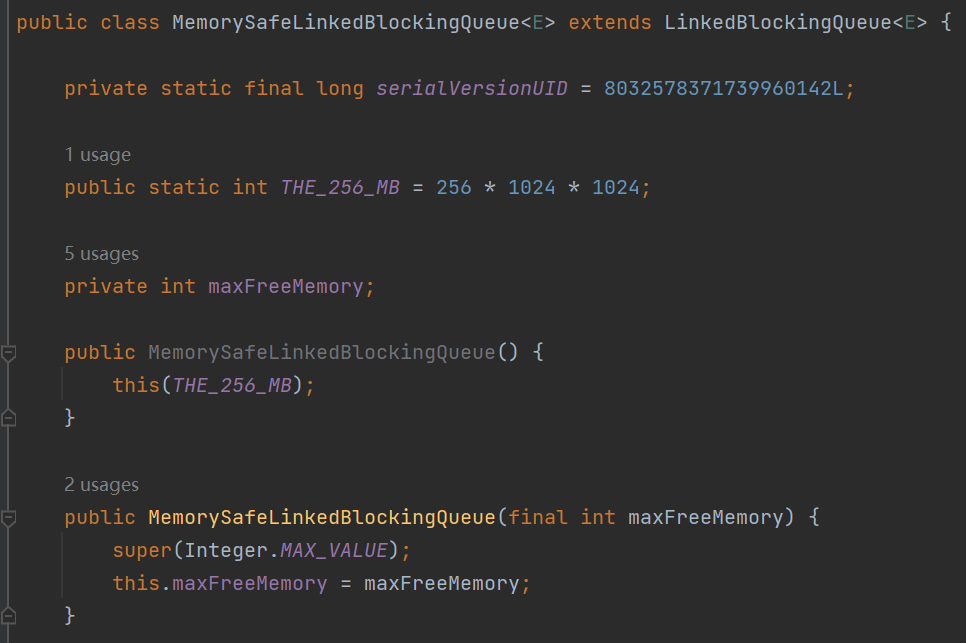
MemorySafeLBQ 还是继承自 LinkedBlockingQueue,只是多了一个自定义的成员变量,叫做 maxFreeMemory,初始值是 256 * 1024 * 1024。
这个变量的名字就非常值得注意,你再细细品品。maxFreeMemory,最大的剩余内存,默认是 256M。
前面一节讲的 MemoryLimitedLBQ 限制的是这个队列最多能使用多少空间,是站在队列的角度。
而 MemorySafeLBQ 限制的是 JVM 里面的剩余空间。比如默认就是当整个 JVM 只剩下 256M 可用内存的时候,再往队列里面加元素我就不让你加了。
因为整个内存都比较吃紧了,队列就不能无限制的继续添加了,从这个角度来规避了 OOM 的风险。
这样的一个反其道而行之。
另外,它说它不依赖 Instrumentation 了,那么它怎么检测内存的使用情况呢?

使用的是 ManagementFactory 里面的 MemoryMXBean。
这个 MemoryMXBean 其实你一点也不陌生。
JConsole 你用过吧?
下面这个界面进去过吧?
这些信息就是从 ManagementFactory 里面拿出来的:
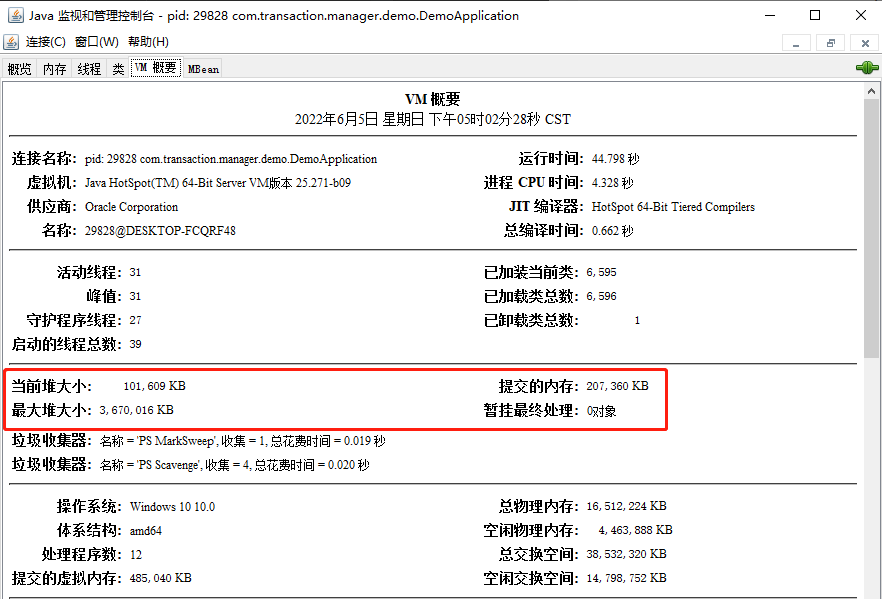
所以,确实它没有使用 Instrumentation,但是它使用了 ManagementFactory。
目的都是为了获取内存的运行状态。
那么怎么看出来它比 MemoryLimitedLBQ 更好用呢?
我看了,关键方法就是这个 hasRemainedMemory,在调用 put、offer 方法之前就要先调用这个方法:
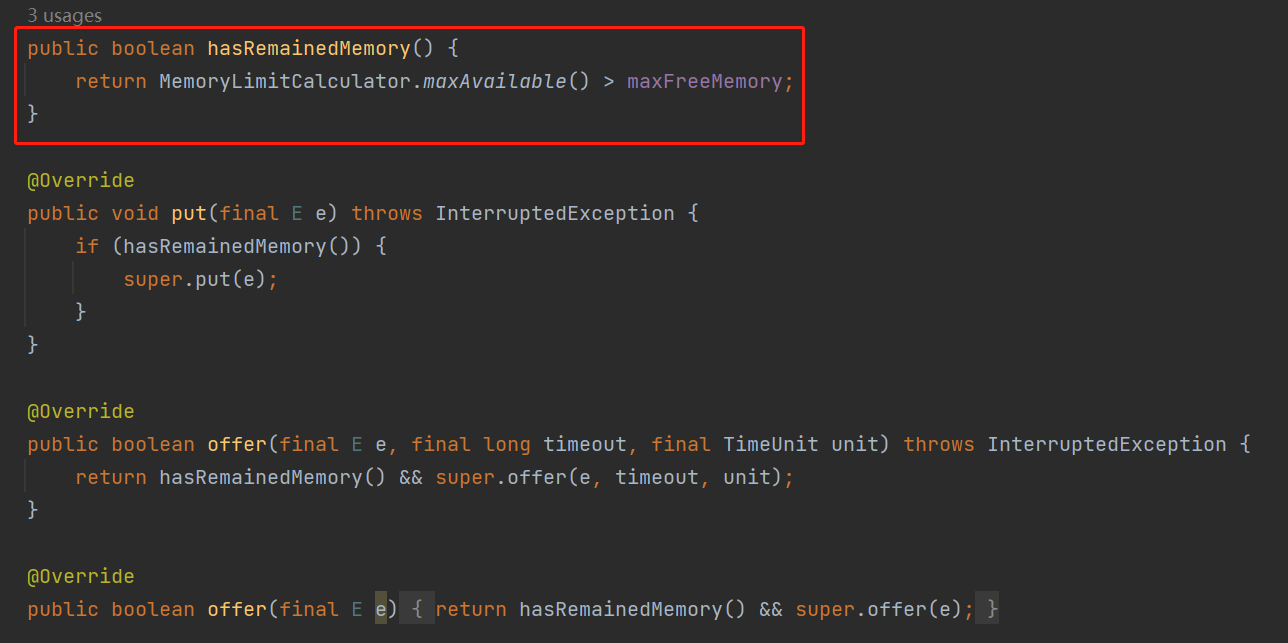
而且你看 MemorySafeLBQ 只是重写了放入元素的 put、offer 方法,并不关注移除元素。
为什么呢?
因为它的设计理念是只关心添加元素时候的剩余空间大小,它甚至都不会去关注当前这个元素的大小。
而还记得前面讲的 MemoryLimitedLBQ 吗?它里面还计算了每个元素的大小,然后搞了一个变量来累加。
MemoryLimitedLBQ 的 hasRemainedMemory 方法里面也只有一行代码,其中 maxFreeMemory 是类初始化的时候就指定好了。那么关键的代码就是 MemoryLimitCalculator.maxAvailable()。
所以我们看看 MemoryLimitCalculator 的源码。
这个类的源码写的非常的简单,我全部截完都只有这么一点内容,全部加起来也就是 20 多行代码:
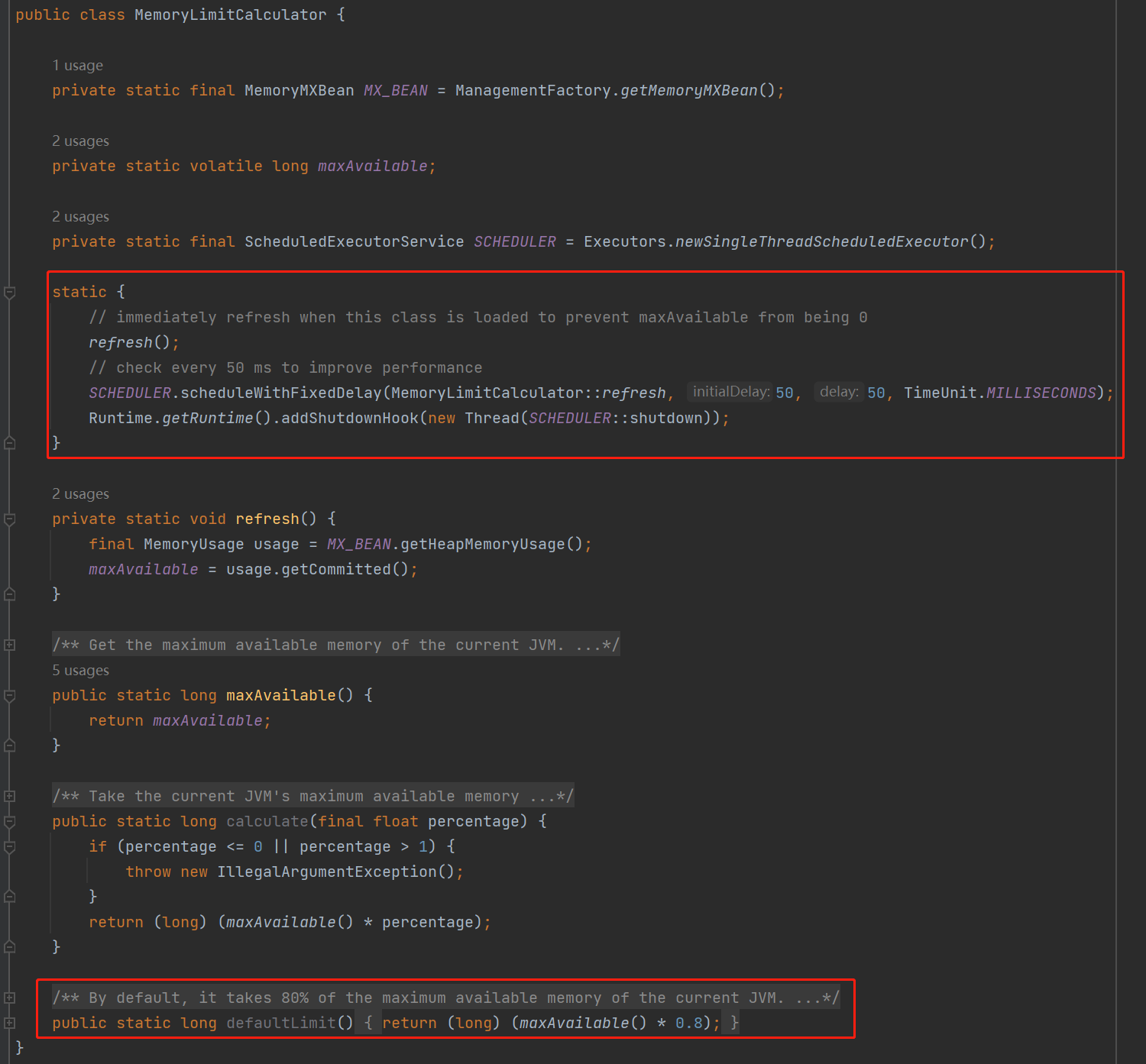
而整个方法的核心就是我框起来的 static 代码块,里面一共有三行代码。
第一行是调用 refresh 方法,也就是对 maxAvilable 这个参数进行重新赋值,这个参数代表的意思是当前还可以使用的 JVM 内存。
第二行是注入了一个每 50ms 运行一次的定时任务。到点了,就触发一下 refresh 方法,保证 maxAvilable 参数的准实时性。
第三行是加入了 JVM 的 ShutdownHook,停服务的时候需要把这个定时任务给停了,达到优雅停机的目的。
核心逻辑就这么点。
从我的角度来说,确实是比 MemoryLimitedLBQ 使用起来更简单,更好用。
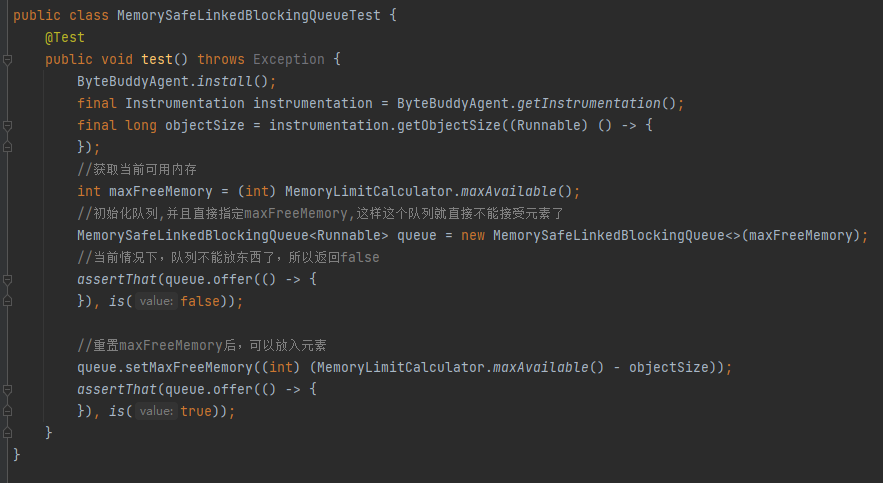
最后,再看看作者提供的 MemorySafeLBQ 测试用例,我补充了一点注释,很好理解,自己去品,不再多说:
它是你的了
文章里面提到的 MemoryLimitedLBQ 和 MemorySafeLBQ,我说了,这两个玩意是完全独立于框架的,代码直接粘过来就可以用。
代码也没几行,不管是用 Instrumentation 还是 ManagementFactory,核心思想都是限制内存。
思路扩展一下,比如我们有的项目里面用 Map 来做本地缓存,就会放很多元素进去,也会有 OOM 的风险,那么通过前面说的思路,是不是就找到了一个问题的解决方案?
所以,思路是很重要的,掌握到了这个思路,面试的时候也能多掰扯几句嘛。
再比如,我看到这个玩意的时候,联想到了之前写过的线程池参数动态调整。
就拿 MemorySafeLBQ 这个队列来说,它里面的 maxFreeMemory 这个参数,可不可以做成动态调整的?

不外乎就是把之前的队列长度可调整修改为了队列占用的内存空间可调整。一个参数的变化而已,实现方案可以直接套用。
这些都是我从开源项目里面看到的,但是在我看到的那一刻,它就是我的。
现在,我把它写出来,分享给你,它就是你的了。
不客气,来个三连就行。
