换个数据结构,一不小心节约了 591 台机器!
你好呀,我是歪歪。
前段时间,我在 B 站上看到一个技术视频,题目叫做《机票报价高并发场景下的一些解决方案》。
up 主是 Qunar技术大本营,也就是我们耳熟能详的“去哪儿”。
视频链接在这里:
https://www.bilibili.com/video/BV1eX4y1F7zJ?p=2
当时其实我是被他的这个图片给吸引到了(里面的 12 qps 应该是 12k qps):
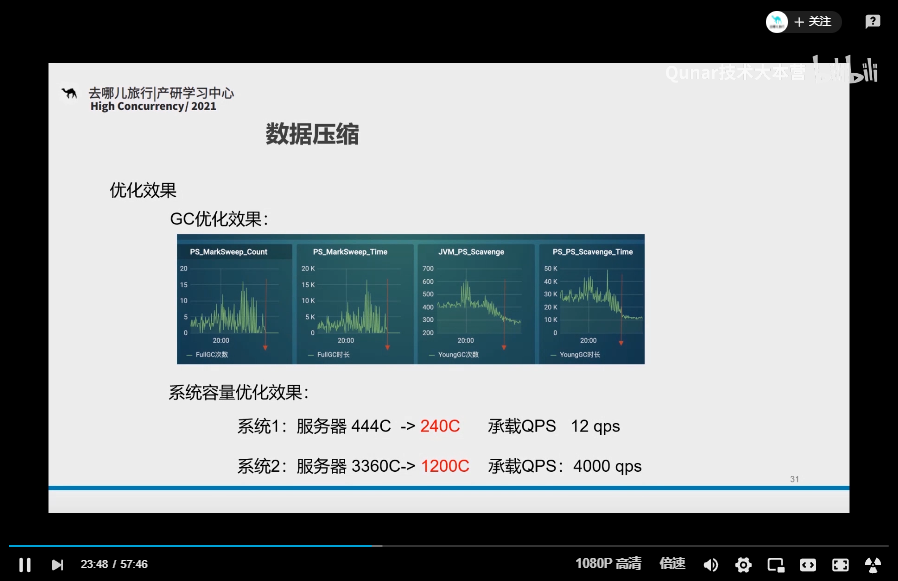
他介绍了两个核心系统在经过一个“数据压缩”的操作之后,分别节约了 204C 和 2160C 的服务器资源。
共计就是 2364C 的服务器资源。
如果按照一般标配的 4C8G 服务器,好家伙,这就是节约了 591 台机器啊,你想想一年就节约了多大一笔开销。

视频中介绍了几种数据压缩的方案,其中方案之一就是用了高性能集合:

因为他们的系统设计中大量用到“本地缓存”,而本地缓存大多就是使用 HashMap 来帮忙。
所以他们把 HashMap 换成了性能更好的 IntObjectHashMap,这个类出自 Netty。
为什么换了一个类之后,就节约了这么多的资源呢?
换言之,IntObjectHashMap 性能更好的原因是什么呢?
我也不知道,所以我去研究了一下。

拉源码
研究的第一步肯定是要找到对应的源码。
你可以去找个 Netty 依赖,然后找到里面的 IntObjectHashMap。
我这边本地刚好有我之前拉下来的 Netty 源码,只需要同步一下最新的代码就行了。
但是我在 4.1 分支里面找这个类的时候并没有找到,只看到了一个相关的 Benchmark 类:
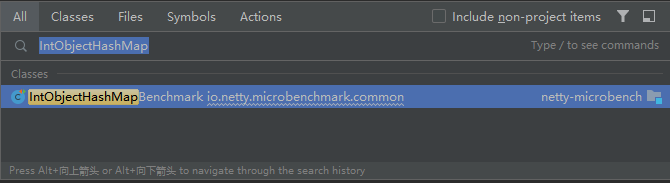
点进去一看,确实没有 IntObjectHashMap 这个类:
很纳闷啊,我反正也没搞懂为啥,但是我直接就是一个不纠结了,反正我现在只是想找到一个 IntObjectHashMap 类而已。
4.1 分支如果没有的话,那么就 4.0 上看看呗:
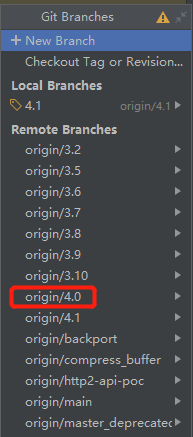
于是我切到了 4.0 分支里面去找了一下,很顺利就找到了对应的类和测试类:
能看到测试类,其实也是我喜欢把项目源码拉下来的原因。如果你是通过引入 Netty 的 Maven 依赖的方式找到对应类的,就看不到测试类了。
有时候配合着测试类看源码,事半功倍,一个看源码的小技巧,送给你。
而我要拉源码的最重要的一个目的其实是这个:
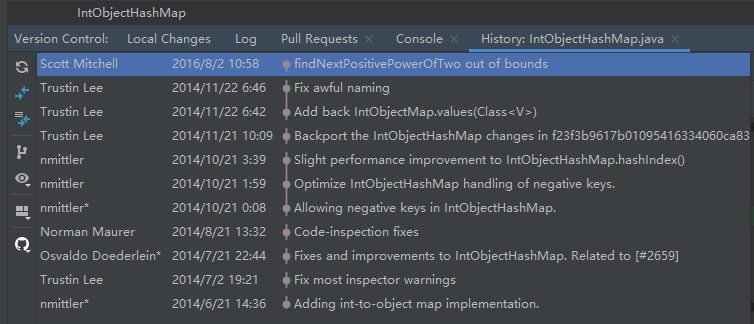
可以看到这个类的提交记录,观察到这个类的演变过程,这个是很重要的。
因为一次提交绝大部分情况下对应着一次 bug 修改或者性能优化,都是我们应该关注的地方。
比如,我们可以看到这个小哥针对 hashIndex 方法提交了三次:
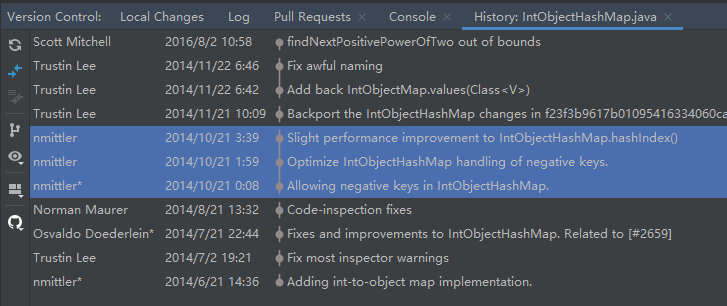
在正式研究 IntObjectHashMap 源码之前,我们先看看只关注 hashIndex 这个局部的方法。
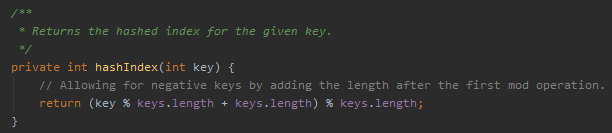
首先,这个地方现在的代码是这样的:
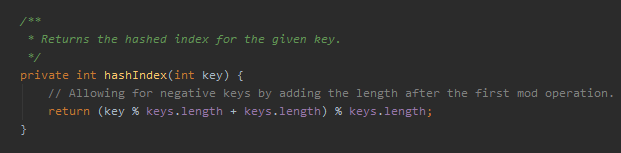
我知道这个方法是获取 int 类型的 key 在 keys 这个数组中的下标,支持 key 是负数的情况。
那么为啥这一行代码就提交了三次呢?
我们先看第一次提交:
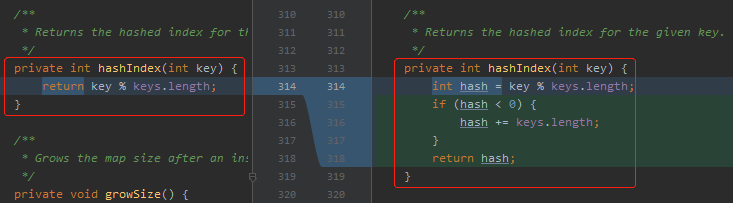
非常清晰,左边是最原始的代码,如果 key 是负数的话,那么返回的 index 就是负数,很明显不符合逻辑。
所以有人提交了右边的代码,在算出 hash 值为负数的时候,加上数组的长度,最终得到一个正数。
很快,提交代码的哥们,发现了一个更好的写法,进行了一次优化提交:

拿掉了小于零的判断。不管 key%length 算出的值是正还是负,都将结果加上一个数组的长度后再次对数组的长度进行 % 运行。
这样保证算出来的 index 一定是一个正数。
第三次提交的代码就很好理解了,代入变量:

所以,最终的代码就是这样的:
return (key % keys.length + keys.length) % keys.length;
这样的写法,不比判断小于零优雅的多且性能也好一点吗?而且这也是一个常规的优化方案。
如果你看不到代码提交记录,你就看不到这个方法的演变过程。我想表达的是:在代码提交记录中能挖掘到非常多比源码更有价值的信息。
又是一个小技巧,送给你。

IntObjectHashMap
接下来我们一起探索一下 IntObjectHashMap 的奥秘。
关于这个 Map,其实有两个相关的类:
其中 IntObjectMap 是个接口。
它们不依赖除了 JDK 之外的任何东西,所以你搞懂原理之后,如果发现自己的业务场景下有合适的场景,完全可以把这两个类粘贴到自己的项目中去,一行代码都不用改,拿来就用。
在研究了官方的测试用例和代码提交记录之后,我选择先把这两个类粘出来,自己写个代码调试一下,这样的好处就是可以随时修改其中的源码,以便我们进行研究。
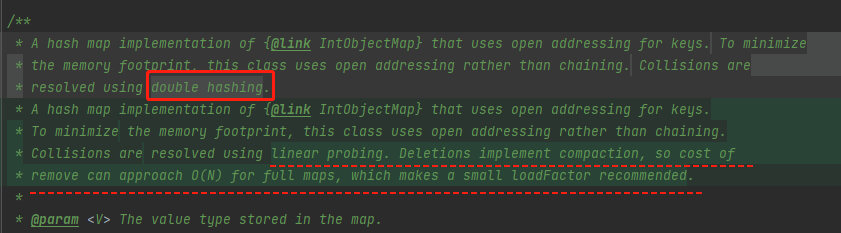
在安排 IntObjectHashMap 源码之前,我们先关注一下它 javadoc 里面的这几句话:
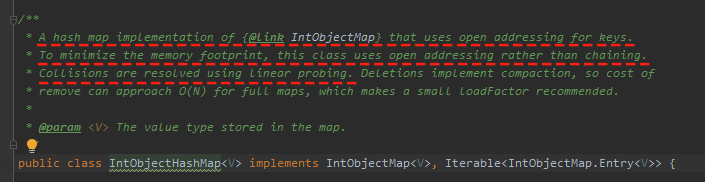
第一句话就非常的关键,这里解释了 IntObjectHashMap 针对 key 冲突时的解决方案:
它对于 key 使用的是 open addressing 策略,也就是开放寻址策略。
为什么使用开放寻址呢,而不是采用和 HashMap 一样挂个链表呢?
这里也回答了这个问题:To minimize the memory footprint,也就是为了最小化内存占用。
怎么就减少了内存的占用呢?
这个问题下面看源码的时候会说,但是这里提一句:你就想想如果用链表,是不是至少得有一个 next 指针,维护这个东西是不是又得占用空间?
不多说了,说回开放寻址。
开放寻址是一种策略,该策略也分为很多种实现方案,比如:
线性探测方法(Linear Probing) 二次探测(Quadratic probing) 双重散列(Double hashing)
从上面划线部分的最后一句话就可以知道,IntObjectHashMap 使用的就是 linear probing,即线性探测。
现在我们基本了解到 IntObjectHashMap 这个 map 针对 hash 冲突时使用的解决方案了。
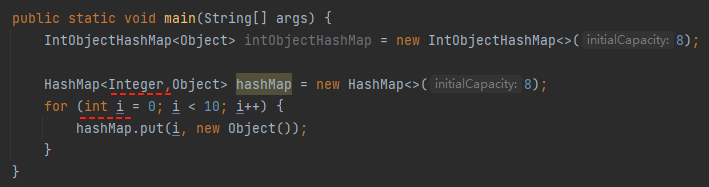
接下来,我们搞个测试用例实操一把。代码很简单,就一个初始化,一个 put 方法:
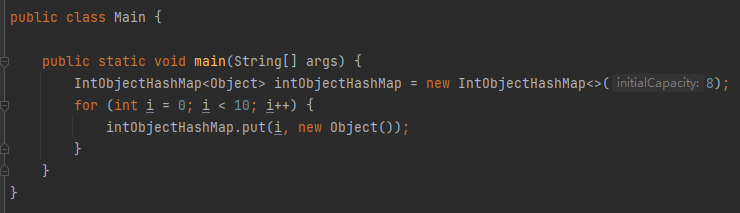
就这么几行代码,一眼望去和 HashMap 好像没啥区别。但是仔细一想,还是发现了一点端倪。
如果我们用 HashMap 的话,初始化应该是这样的:
HashMap<Integer,Object> hashMap = new HashMap<>(10);
你再看看 IntObjectHashMap 这个类定义是怎么样的?
只有一个 Object:
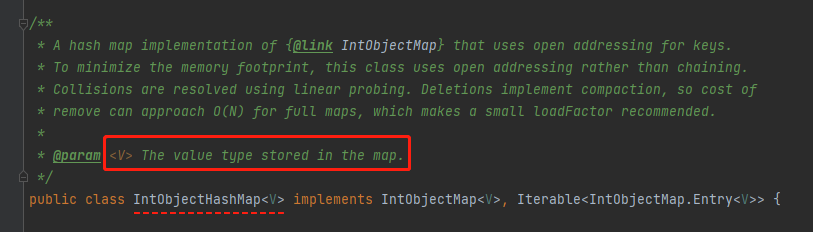
这个 Object 代表的是 map 里面装的 value。
那么 key 是什么,去哪儿了呢?是不是第一个疑问就产生了呢?
查看 put 方法之后,我发现 key 竟然就是 int 类型的值:
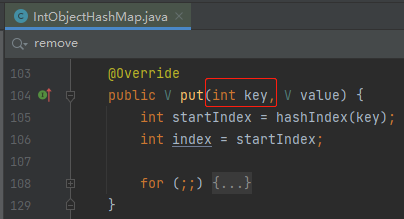
也就是这个类已经限制住了 key 就是 int 类型的值,所以不能在初始化的时候指定 key 的泛型了。
这个类从命名上也已经明确说明这一点了:我是 IntObjectHashMap,key 是 int,value 是 Object 的 HashMap。
那么我为什么用了个“竟然”呢?
因为你看看 HashMap 的 key 是个啥玩意:
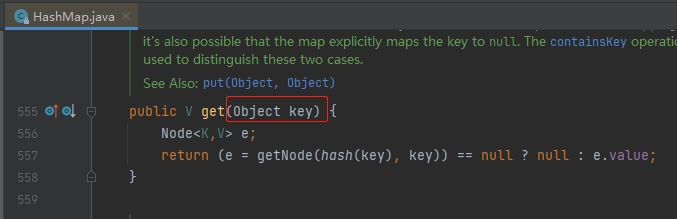
是个 Object 类型。
也就是说,如果我们想这样初始化 HashMap 是不可以的:
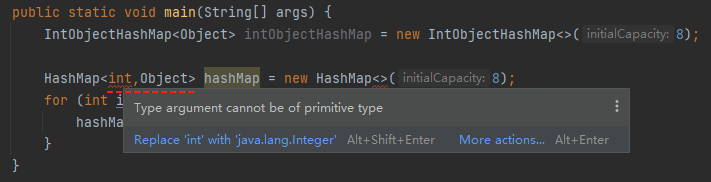 ide 都会提醒你:老弟,别搞事啊,你这里不能放基本类型,你得搞个包装类型进来。
ide 都会提醒你:老弟,别搞事啊,你这里不能放基本类型,你得搞个包装类型进来。
而我们平常编码的时候能这样把 int 类型放进去,是因为有“装箱”的操作被隐藏起来了:
所以才会有一道上古时期的八股文问:HashMap 的 key 可以用基本类型吗?
想也不用想,不可以!
key,从包装类型变成了基本类型,这就是一个性能优化的点。因为众所周知,基本类型比包装类型占用的空间更小。
接着,我们先从它的构造方法入手,主要关注我框起来的部分:
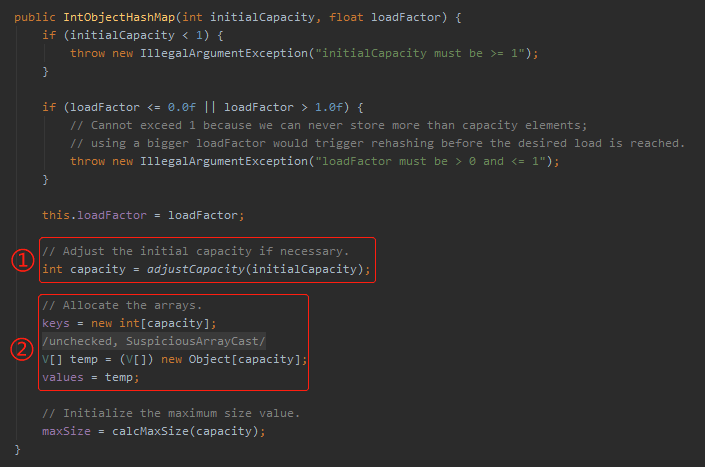
首先进来就是两个 if 判断,对参数合法性进行了校验。
接着看标号为 ① 的地方,从方法名看是要做容量调整:

从代码和方法上的注释可以看出,这里是想把容量调整为一个奇数,比如我给进来 8 ,它会给我调整为 9:
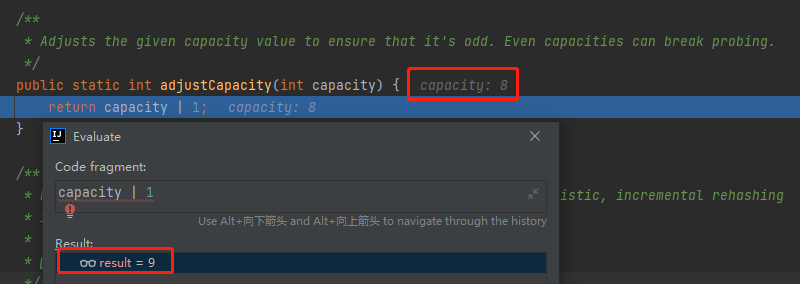
至于容量为什么不能是偶数,从注释上给了一个解释:
Even capacities can break probing.
意思是容量为偶数的时候会破坏 probing,即我们前面提到的线性探测。
额...
我并没有考虑明白为什么偶数的容量会破坏线性探测,但是这不重要,先存疑,接着往下梳理主要流程。
从标号为 ② 的地方可以看出这是在做数据初始化的操作。前面我们得到了 capacity 为 9,这里就是初始两个数组,分别是 key[] 和 values[],且这两个数组的容量是一样的,都是 9:
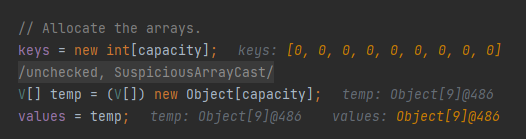
两个数组在构造方法中完成初始化后,是这样的:
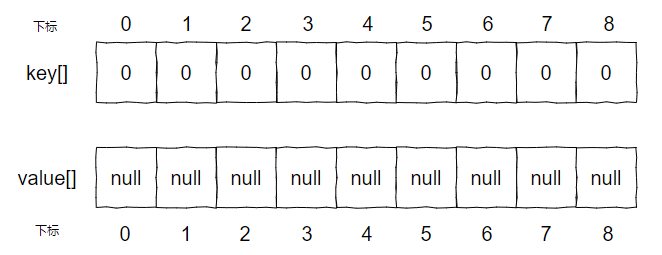
构造方法我们就主要关注容量的变化和 key[]、values[] 这两个数组。
构造方法给你铺垫好了,接着我们再看 put 方法,就会比较丝滑了:
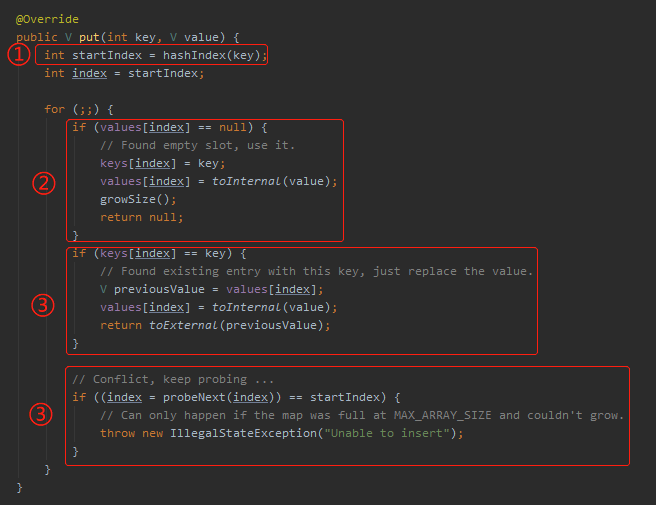
put 方法的代码也没几行,分析起来非常的清晰。
首先是标号为 ① 的地方,hashIndex 方法,就是获取本次 put 的 key 对应在 key[] 数组中的下标。
这个方法文章开始的时候已经分析过了,我们甚至知道这个方法的演变过程,不再多说。
然后就是进入一个 for(;;) 循环。
先看标号为 ② 的地方,你注意看,这个时候的判断条件是 value[index] == null,是判断算出来的 index 对应的 value[] 数组对应的下标是否有值。
前面我专门强调了一句,还给你画了一个图:
key[] 和 values[] 这两个数组的容量是一样的。
为什么不先判断该 index 在 key[] 中是否存在呢?
可以倒是可以,但是你想想如果 value[] 对应下标中的值是 null 的话,那么说明这个位置上并没有维护过任何东西。key 和 value 的位置是一一对应的,所以根本就不用去关心 key 是否存在。
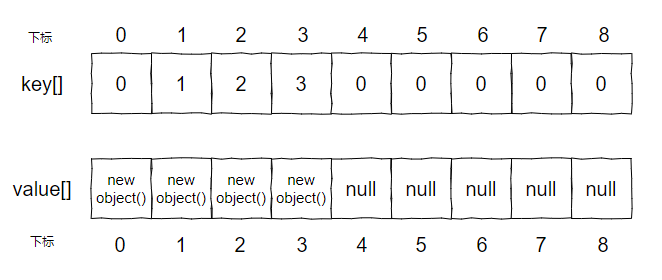
如果 value[index] == null 为 true,那么说明这个 key 之前没有被维护过,直接把对应的值维护上,且 key[] 和 values[] 数组需要分别维护。
假设以我的演示代码为例,第四次循环结束后是这样的:
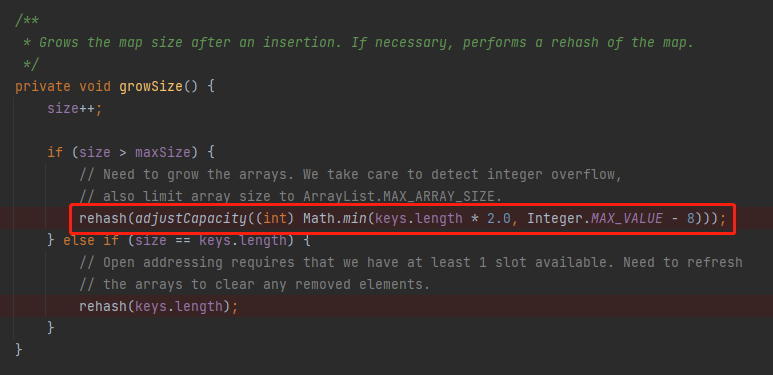
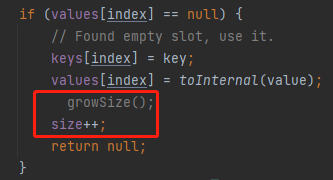
维护完成后,判断一下当前的容量是否需要触发扩容:
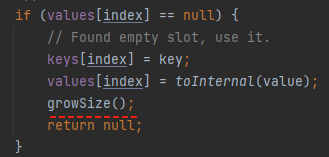
growSize 的代码是这样的:
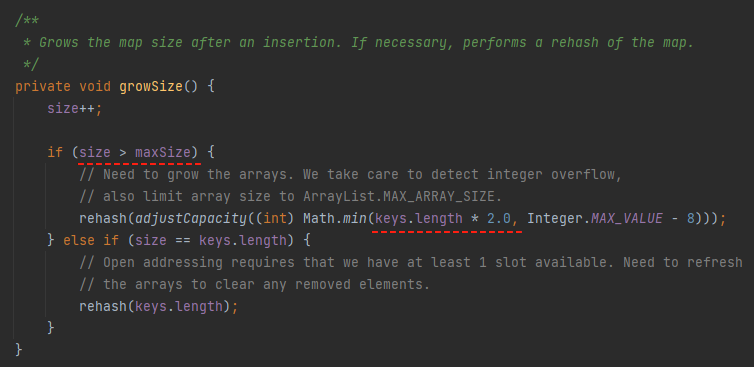
在这个方法里面,我们可以看到 IntObjectHashMap 的扩容机制是一次扩大 2 倍。
额外说一句:这个地方就有点 low 了,源码里面扩大二倍肯定得上位运算,用 length << 1 才对味儿嘛。
但是扩容之前需要满足一个条件:size > maxSize
size,我们知道是表示当前 map 里面放了几个 value 。
那么 maxSize 是啥玩意呢?
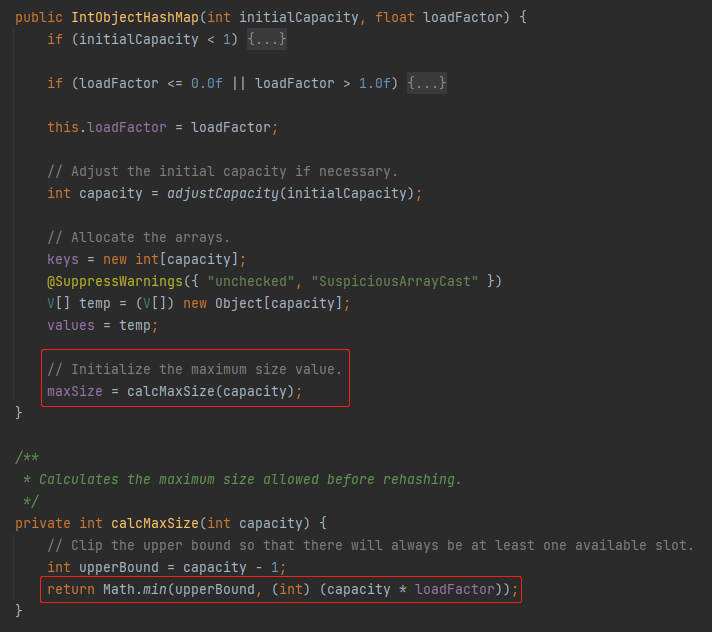
这个值在构造函数里面进行的初始化。比如在我的示例代码中 maxSize 就等于 4:
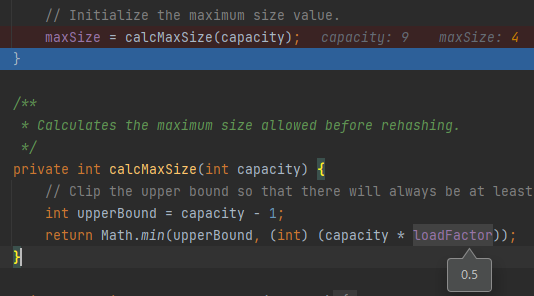
也就是说,如果我再插入一个数据,它就要扩容了,比如我插入了第五个元素后,数组的长度就变成了 19:

前面我们讨论的是 value[index] == null 为 true 的情况。那么如果是 false 呢?
就来到了标号为 ③ 的地方。
判断 key[] 数组 index 下标处的值是否是当前的这个 key。
如果是,说明要覆盖。先把原来该位置上的值拿出来,然后直接做一个覆盖的操作,并返回原值,这个逻辑很简单。
但是,如果不是这个 key 呢?
说明什么情况?
是不是说明这个 key 想要放的 index 位置已经被其他的 key 先给占领了?
这个情况是不是就是出现了 hash 冲突?
出现了 hash 冲突怎么办?

那么就来到了标号为 ③ 的地方,看这个地方的注释:
Conflict, keep probing ...
冲突,继续探测 ...
继续探测就是看当前发生冲突的 index 的下一个位置是啥。
如果让我来写,很简单,下一个位置嘛,我闭着眼睛用脚都能敲出来,就是 index+1 嘛。
但是我们看看源码是怎么写的:

确实看到了 index+1,但是还有一个先决条件,即 index != values.length -1。
如果上述表达式成立,很简单,采用 index+1。
如果上面的表达式不成立,说明当前的 index 是 values[] 数组的最后一个位置,那么就返回 0,也就是返回数组的第一个下标。
要触发这个场景,就是要搞一个 hash 冲突的场景。我写个代码给你演示一下:
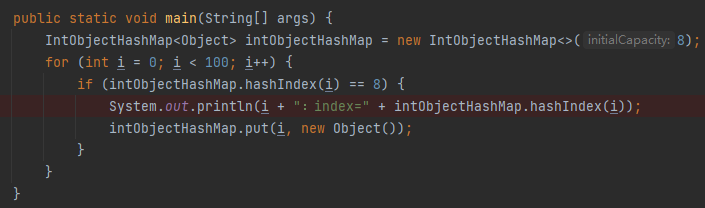
上面的代码只有当算出来的下标为 8 的时候才会往 IntObjectHashMap 里面放东西,这样在下标为 8 的位置就出现了 hash 冲突。
比如 100 之内,下标为 8 的数是这些:
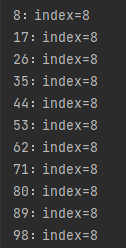
第一次循环之后是这样的:
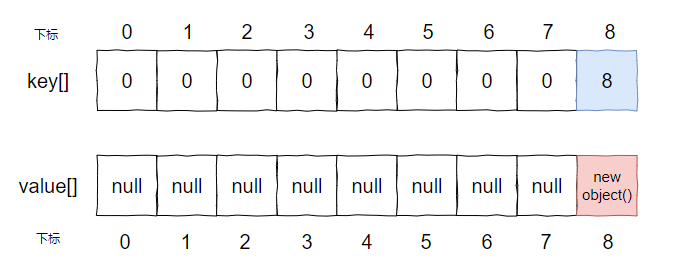
而第二次循环的时候,key 是 17,它会发现下标为 8 的地方已经被占了:
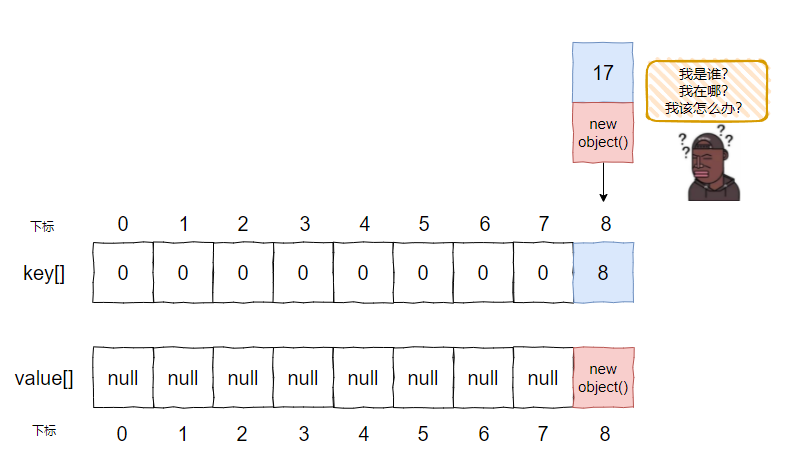
所以,走到了这个判断中:
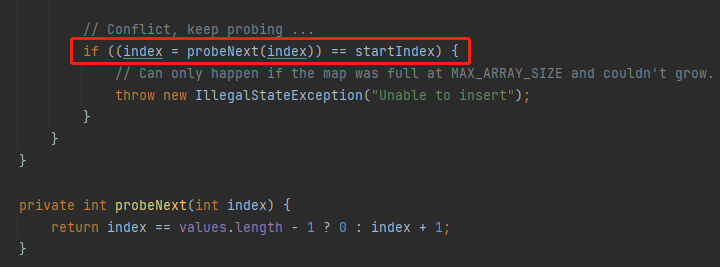
返回 index=0,于是它落在了这个地方:
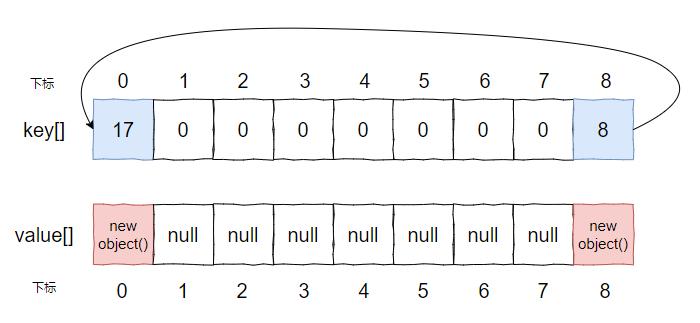
看起来就是一个环,对不对?
是的,它就是一个环。
但是你再细细的看这个判断:

每次计算完 index 后,还要判断是否等于本次循环的 startIndex。如果相等,说明跑了一圈了,还没找到空位子,那么就抛出 “Unable to insert” 异常。
有的朋友马上就跳出来了:不对啊,不是会在用了一半空间以后,以 2 倍扩容吗?应该早就在容量满之前就扩容了才对呀?
这位朋友,你很机智啊,你的疑问和我第一次看到这个地方的疑问是一样的,我们都是心思缜密的好孩子。

但是注意看,在抛出异常的地方,源码里面给了一个注释:
Can only happen if the map was full at MAX_ARRAY_SIZE and couldn't grow.
这种情况只有 Map 已经满了,且无法继续扩容时才会发生。
扩容,那肯定也是有一个上限才对,再看看扩容的时候的源码:
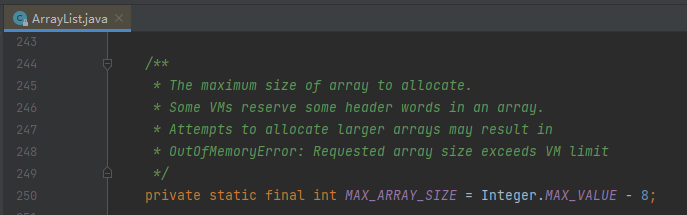
最大容量是 Integer.MAX_VALUE - 8,说明是有上限的。
但是,等等,Integer.MAX_VALUE 我懂,减 8 是什么情况?
诶,反正我是知道的,但是咱就是不说,不是本文重点。你要有兴趣,自己去探索,我就给你截个图完事:
如果我想要验证一下 “Unable to insert” 怎么办呢?
这还不简单吗?源码都在我手上呢。
两个方案,一个是修改 growSize() 方法的源码,把最长的长度限制修改为指定值,比如 8。
第二个方案是直接严禁扩容,把这行代码给它注释了:
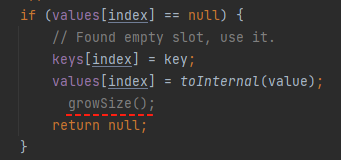
然后把测试用例跑起来:
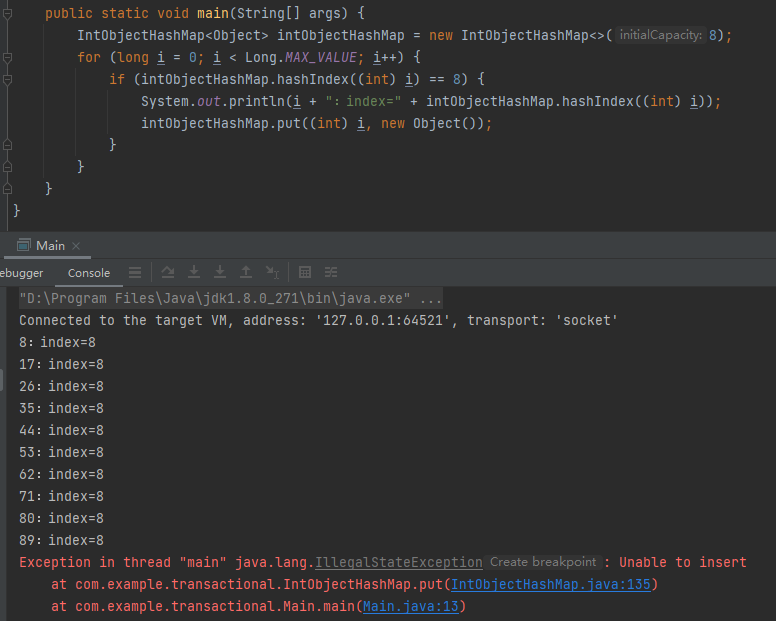
你会发现在插入第 10 个值的时候,抛出了 “Unable to insert” 异常。
第 10 个值,89,就是这样似儿的,转一圈,又走回了 startIndex:
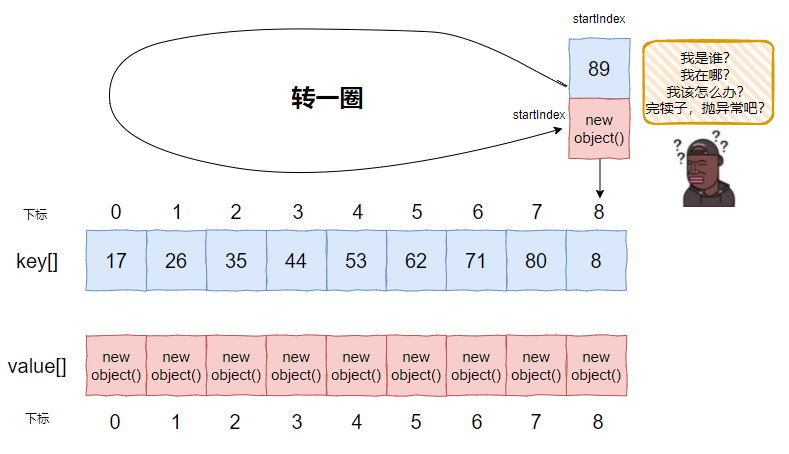
满足这个条件,所以抛出异常:
(index = probeNext(index)) == startIndex
到这里,put 方法就讲完了。你也了解到了它的数据结构,也了解到了它的基本运行原理。
那你还记得我写这篇文章要追寻的问题是什么吗?
IntObjectHashMap 性能更好的原因是什么呢?
前面提到了一个点是 key 可以使用原生的 int 类型而不用包装的 Integer 类型。
现在我要揭示第二个点了:value 没有一些乱七八糟的东西,value 就是一个纯粹的 value。你放进来是什么,就是什么。
你想想 HashMap 的结构,它里面有个 Node,封装了 Hash、key、value、next 这四个属性:
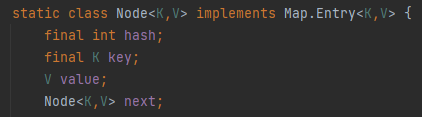
这部分东西也是 IntObjectHashMap 节约出来的,而这部分节约出来的,才是占大头的地方。
你不要看不起着一点点内存占用。在一个巨大的基数面前,任何一点小小的优化,都能被放大无数倍。
不知道你还记不记得《深入理解Java虚拟机》一书里面的这个案例:
.png)
不恰当的数据结构导致内存在占用过大。这个问题,就完全可以使用 Netty 的 LongObjectHashMap 数据结构来解决,只需要换个类,就能节省非常多的资源。
道理,是同样的道理。

额外一个点
最后,我再给你额外补充一个我看源码时的意外收获。
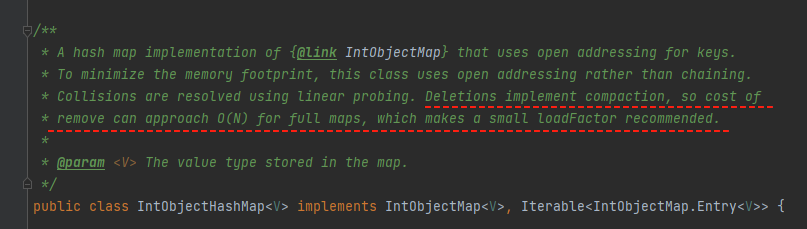
Deletions implement compaction, so cost of remove can approach O(N) for full maps, which makes a small loadFactor recommended.
删除实现了 compaction,所以对于一个满了的 map 来说,删除的成本可能接近 O(N) ,所以我们推荐使用小一点的 loadFactor。
里面有两个单词,compaction 和 loadFactor。
先说 loadFactor 属性,是在构造方法里面初始化的:
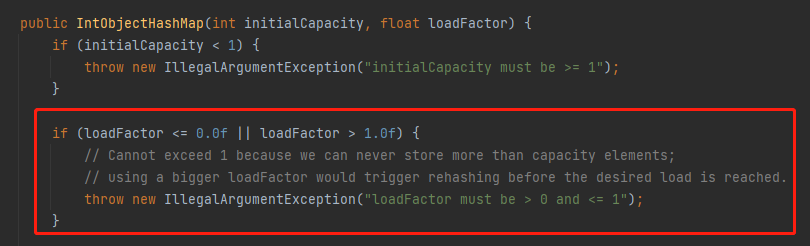
为什么 loadFactor 必须是一个 (0,1] 之间的数呢?
首先要看一下 loadFactor 是在什么时候用的:
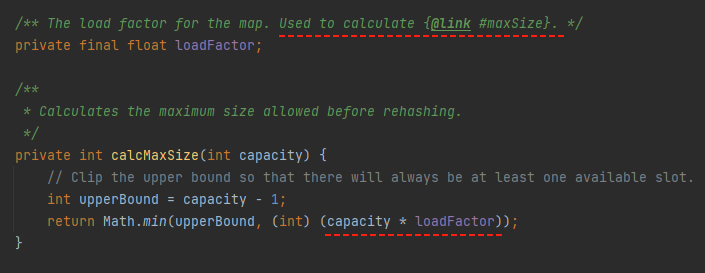
只会在计算 maxSize 的时候用到,是用当前 capacity 乘以这个系数。
如果这个系数是大于 1 的,那么最终算出来的值,也就是 maxSize 会大于 capacity。
假设我们的 loadFactor 设置为 1.5,capacity 设置为 21,那么计算出来的 maxSize 就是 31,都已经超过 capacity 了,没啥意义。
总之:loadFactor 是用来计算 maxSize 的,而前面讲了 maxSize 是用来控制扩容条件的。也就是说 loadFactor 越小,那么 maxSize 也越小,就越容易触发扩容。反之,loadFactor 越大,越不容易扩容。loadFactor 的默认值是 0.5。
接下来我来解释前面注释中有个单词 compaction,翻译过来的话叫做这玩意:

可以理解为就是一种“压缩”吧,但是“删除实现了压缩”这句话就很抽象。
不着急,我给你讲。
我们先看看删除方法:
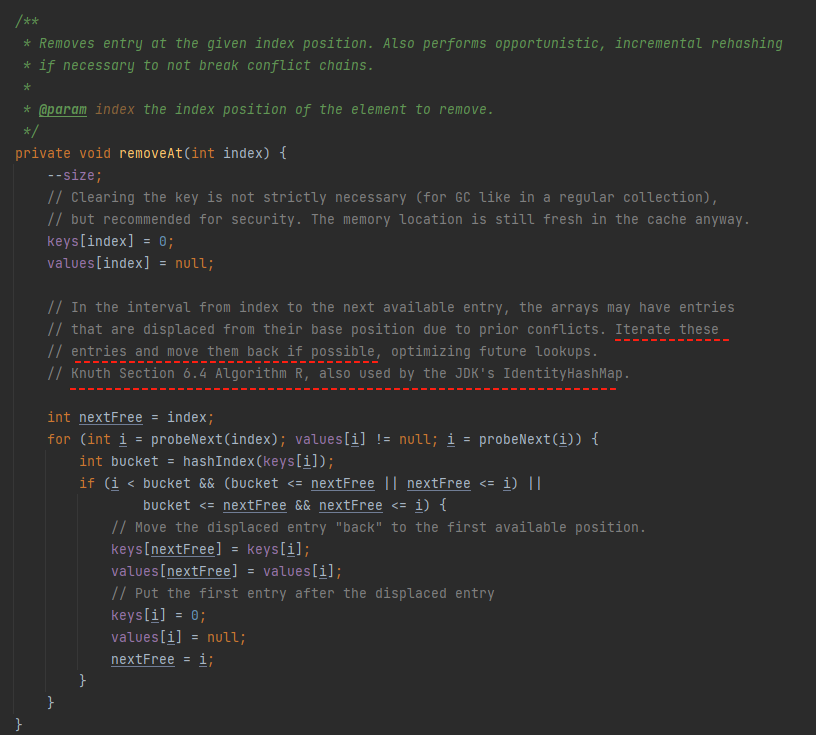
删除方法的逻辑有点复杂,如果要靠我的描述给你说清楚的话有点费解。
所以,我决定只给你看结果,你拿着结果去反推源码吧。
首先,前面的注释中说了:哥们,我推荐你使用小一点的 loadFactor。
那么我就偏不听,直接给你把 loadFactor 拉满到 1。
也就是说当这个 map 满了之后,再往里面放东西才会触发扩容。
比如,我这样去初始化:
new IntObjectHashMap<>(8,1);
是不是说,当前这个 map 初始容量是可以放 9 个元素,当你放第 10 个元素的时候才会触发扩容的操作。
诶,巧了,我就偏偏只想放 9 个元素,我不去触发扩容。且我这 9 个元素都是存在 hash 冲突的。
代码如下:
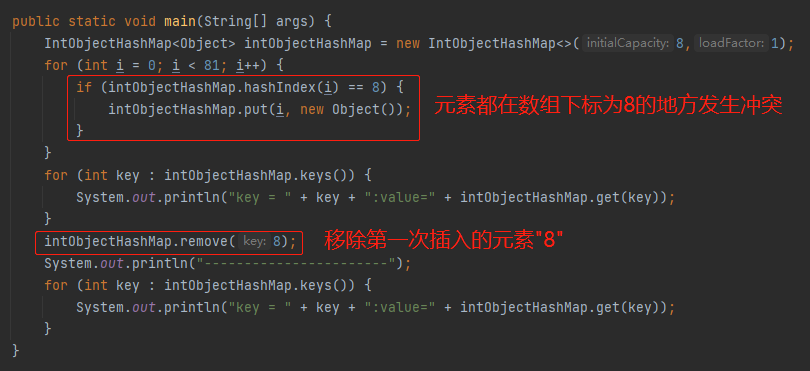
这些 value 本来都应该在下标为 8 的位置放下,但是经过线性探测之后,map 里面的数组应该是这个情况:
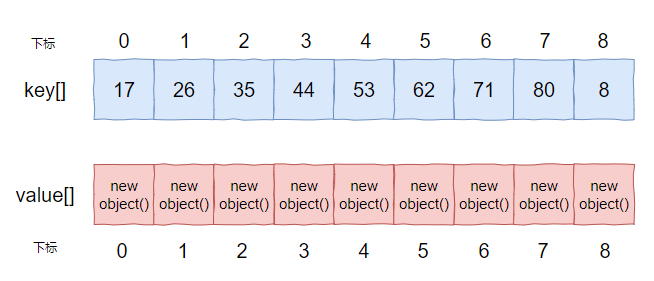
此时我们移除 8 这个 key,正常来说应该是这样的:
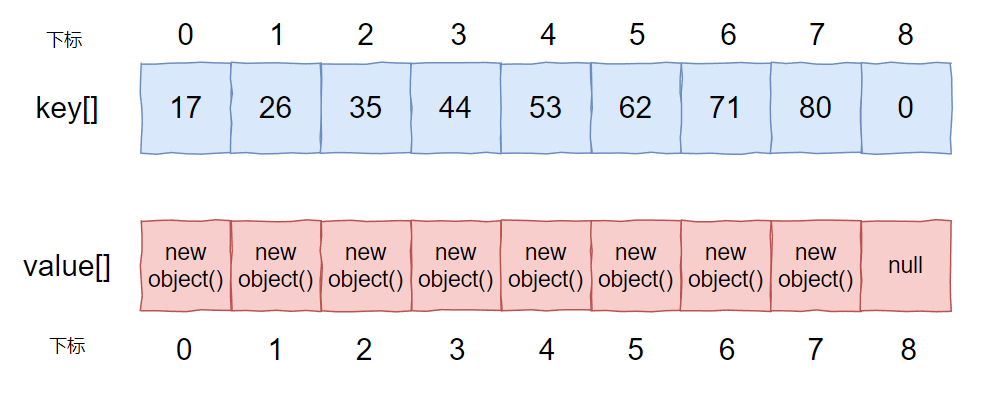
但是实际上却是这样的:
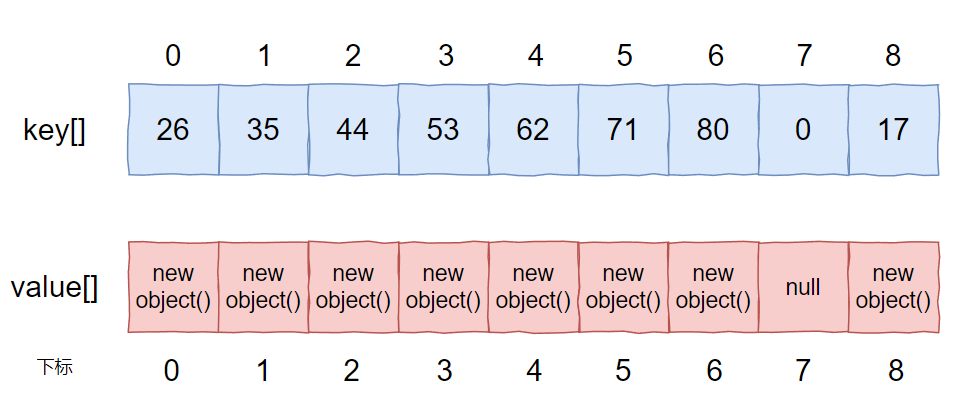
会把前面因为 hash 冲突导致发生了位移的 value 全部往回移动。
这个过程,我理解就是注释里面提到的“compaction”。
上面程序的实际输出是这样的:
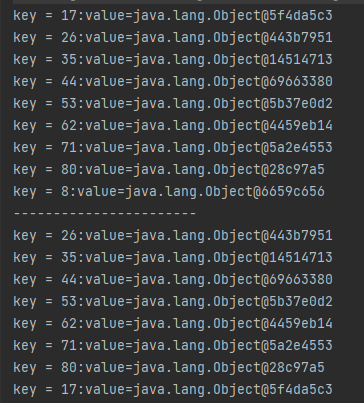
符合我前面画的图片。
但是,我要说明的是,我的代码进行了微调:
如果不做任何修改,输出应该是这样的:
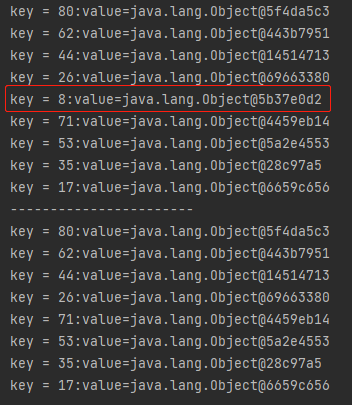
key=8 并不在最后一个,因为在这个过程里面涉及到 rehash 的操作,如果在解释 “compaction” 的时候加上 reHash ,就复杂了,会影响你对于 “compaction” 的理解。
另外在 removeAt 方法的注释里面提到了这个东西:

这个算法,其实就是我前面解释的 “compaction”。
我全局搜索关键字,发现在 IdentityHashMap 和 ThreadLocal 里面都提到了:
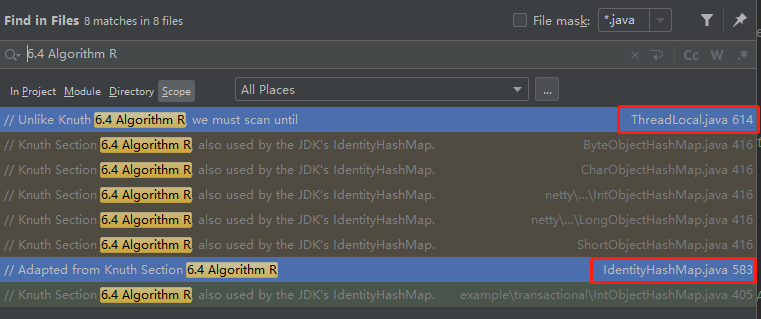
但是,你注意这个但是啊。
在 ThreadLocal 里面,用的是“unlike”。
ThreadLocal 针对 hash 冲突也用的是线性探测,但是细节处还是有点不一样。
不细说了,有兴趣的同学自己去探索一下,我只是想表达这部分可以对比学习。

这一部分的标题叫做“额外一个点”。因为我本来计划中是没有这部分内容的,但是我在翻提交记录的时候看到了这个:
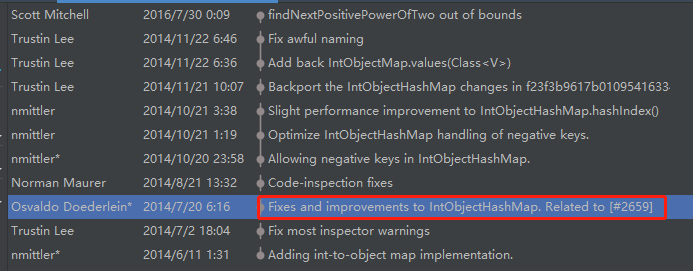
https://github.com/netty/netty/issues/2659
这个 issues 里面有很多讨论,基于这次讨论,相当于对 IntObjectHashMap 进行了一次很大的改造。
比如从这次提交记录我可以知道,在之前 IntObjectHashMap 针对 hash 冲突用的是“双重散列(Double hashing)”策略,之后才改成线性探测的。
包括使用较小的 loadFactor 这个建议、removeAt 里面采用的算法,都是基于这次改造出来的:
引用这个 issues 里面的一个对话:
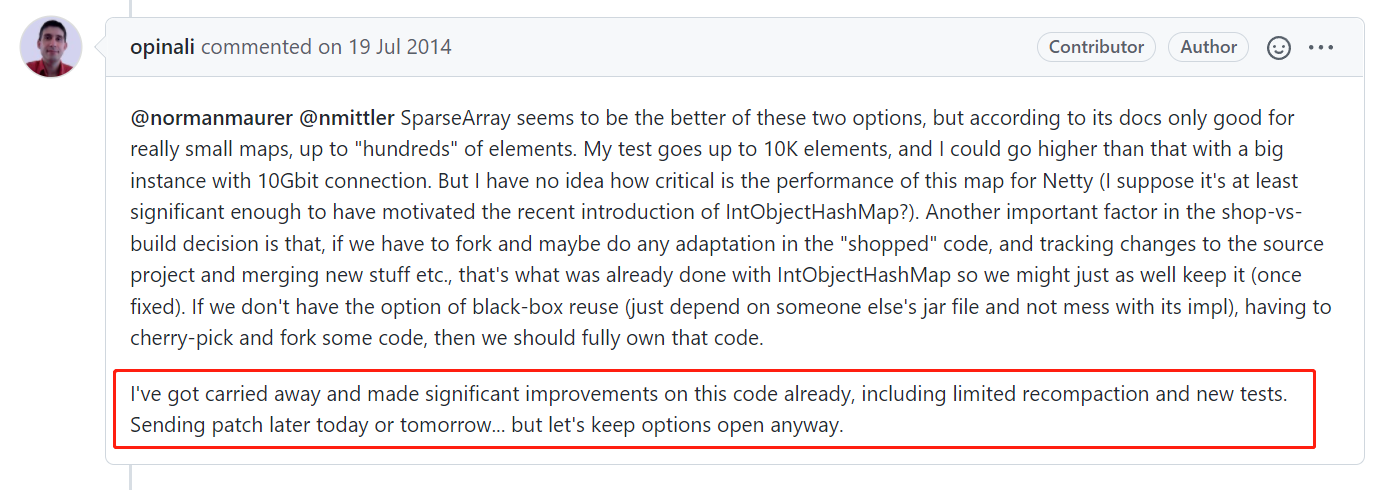
这个哥们说:I've got carried away,我对这段代码进行了重大改进。
在我看来,这都不算是“重大改进”了,这已经算是推翻重写了。
另外,这个“I've got carried away”啥意思?
英语教学,虽迟但到:

这个短语要记住,托福口语考试的时候可能会考。

Netty 4.1
文章开始的地方,我说在 Netty 4.1 里面,我没有找到 IntObjectHashMap 这个东西。
其实我是骗你的,我找到了,只是藏的有点深。
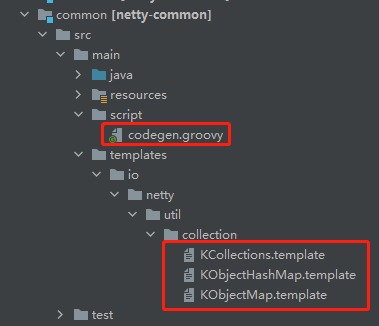
其实我这篇文章只写了 int,但是其实基本类型都可以基于这个思想去改造,且它们的代码都应该是大同小异的。
所以在 4.1 里面用了一个骚操作,基于 groovy 封装了一次:
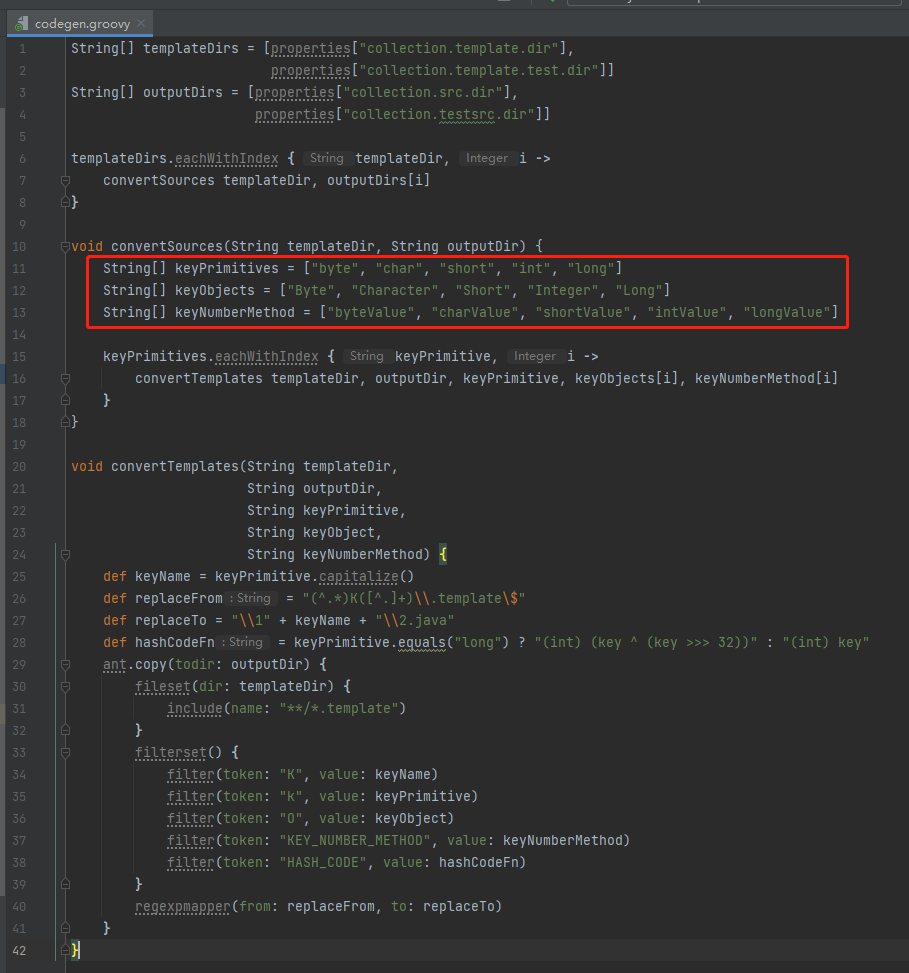
要编译这个模板之后:
才会在 target 目录里面看到我们想找的东西:
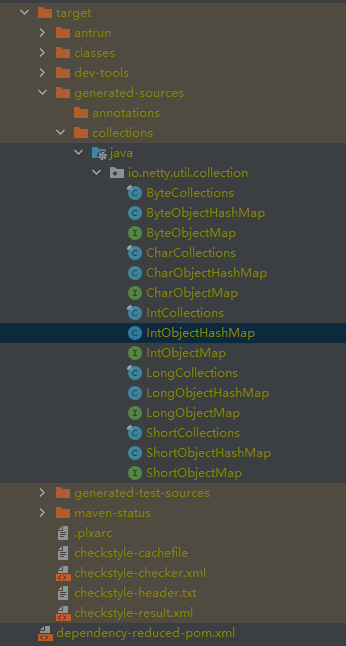
但是,你仔细看编译出来的 IntObjectHashMap,又会发现一点不一样的地方。
比如构造方法里面调整 capacity 的方法变成了这样:
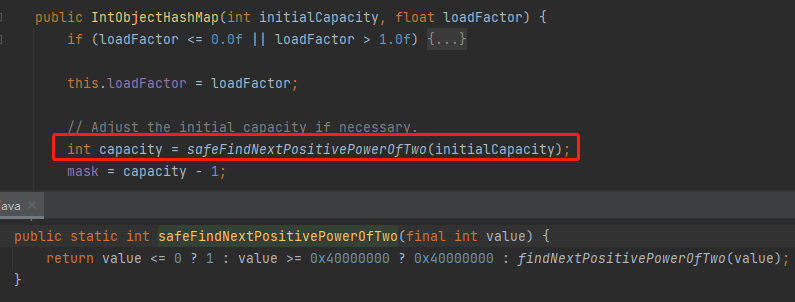
从方法名称我们也知道这里是找一个当前 value 的最近的 2 的倍数。
等等,2 的倍数,不是一个偶数吗?
在 4.0 分支的代码里面,调整容量还非得要个奇数:

还记得我前面提到的一个问题吗:我并没有考虑明白为什么偶数的容量会破坏线性探测?
但是从这里有可以看出其实偶数的容量也是可以的嘛。
这就把我给搞懵了。
要是在 4.0 分支的代码中,adjustCapacity 方法上没有这一行特意写下的注释:
Adjusts the given capacity value to ensure that it's odd. Even capacities can break probing.
我会毫不犹豫的觉得这个地方奇偶都可以。但是他刻意强调了要“奇数”,就让我有点拿不住了。
算了,学不动了,存疑存疑!

文章首发于公众号[why技术],欢迎大家关注,第一时间看到最新文章。
