QBXT Day2主要是数据结构
简单数据结构
本节课可能用到的一些复杂度:
O(log n).
1/1+1/1/.....1/N+O(n log
n)
在我们初学OI的时候,总会遇到这么一道题。
给出N次操作,每次加入一个数,或者询问当前所有数的最大值。
维护一个最大值Max,每次加入和最大值进行比较。(这其实就是一个冒泡排序)
简单的代码实现一下
for(int i=1;i<=n;++i)
{
MAX=max(MAX,a[i]);
}
时间复杂度是O(N)
EX:入门题
给出N次操作,每次加入一个数,删除一个之前加入过的数Ai,或者询问当前所有数的最大值。
N ≤ 100000.
这个怎么做呢?
我们可以想到用二叉搜索树这种东西
他其实就是让你找到某个数的位置并且删除,或者是找到树当中权值最大的那个点,我们可以用二叉搜索树啦
这个题吧,关键是在于有多组询问,如果是只有一组的话,我们直接sort一下就行,但是多组数据的话,因为他要动态维护,如果你每次删掉一个数,都得进行一次sort,就会变慢好多,有的人可能会想到用堆,但是这样就不能删除一个数了啊,因为你弹出之后就没法继续维护了
二叉搜索树
二叉搜索树(BST)是用有根二叉树来存储的一种数据结构,
在二叉树中每个节点代表一个数据。
每个节点包含一个指向父亲的指针,和两个指向儿子的指针。如果没有则为空。每个节点还包含一个key值,代表他本身这个点的权值。(这里我们用struct存)
BST是一种支持对权值进行查询的数据结构,它兹磁:
插入一个数,删除一个数,询问最大/最小值,询问第k大值。
当然,在所有操作结束后,它还能把剩下的数从小到大输出来。
如何查询最大/最小值?
我们注意到BST左边的值都比右边要小,所以我们从树根开始,优先找左儿子,直到没有左儿子的时候,输出key值(权值)
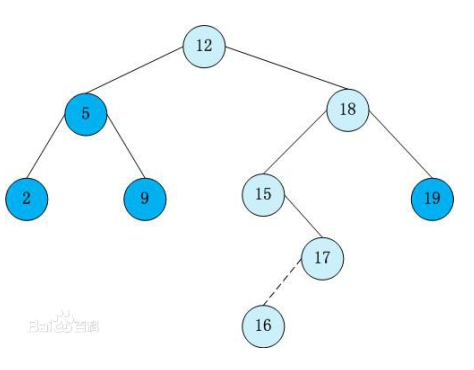
上面这张图的最小值就是一直找左儿子找到2的,找最大值也是一直往右找找到19
代码
int FindMin()
{
intx = root;
while (ls[x]) x = ls[x];
return key[x];
}
这里和维护一个堆是比较像的,无非就是我们要保证左儿子比他爹要小,右儿子比他爹要大
那么我们如何删掉一个点呢?
插入一个值
现在我们要插入一个权值为x的节点。
为了方便,我们插入的方式要能不改变之前整棵树的形态。首先找到根,比较一下key[root]和x,如果key[root] < x,节点应该插在root右侧,否则在左侧。
看看root有没有右儿子,如果没有,那么直接把root的右儿子赋成x就完事了。否则,为了不改变树的形态,我们要去右儿子所在的子树里继续这一操作,直到可以插入为止
下面是代码
void insert(intval)
{
key[+ + tot] = val; ls[tot] = rs[tot] = 0;
int now = root;//当前访问的节点为now.
for(; ; )
{
if (val < key[now])
if (!ls[now]) ls[now] = x, fa[x] = now, break; else now =
ls[now];
else if (!rs[now]) rs[now] = x, fa[x] =
now, break; else now = rs[now];
}
其实插入BST很随意啊,是不需要强制要求到底是先插入的数大还是后插入的数大,你可以<=放在左边,>放在右边,也可以<放在左边,>=放在右边,都是无所谓的
删除一个值
现在我们要删除一个权值为x的点
之前增加一个点我们能够不改变之前的形态。
那删除可以吗?(当然可以啊)
要想删除一个数,我们肯定得先找到他在哪,所以我们从root开始遍历这棵树
代码
int Find(int x)
{
int now = root;
while(key[now]! = x)
if (key[now] < x) now = rs[now]; else now = ls[now];
return now;
}
好了现在我们找到这个点了,那么你怎么删也是个问题
当然你可以把它直接置为空,但是查询起来十分麻烦,所以我们就换个方式
考虑这哥们的孩子
如果他没孩子(真悲催)就直接删掉就行了。
如果他有一个孩子,那就让他孩子接上他原来的位置(子承父业嘛)
要是这哥们比较幸福,俩孩子(我们就很不幸福了。。。。。。。。。)
这里我们定义x的后继y,y必须是x的右子树所有的点里头权值最小的点
为了找这个点,x可以先走一次右儿子,之后一直走左儿子。
如果y是x的右儿子,那么我们直接把y的左儿子变成原本x的左儿子就行然后就用y来代替x(别忘了x是要被删掉的QWQ)
看看图吧
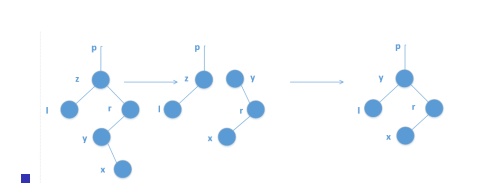
这里有一个非常精妙的构造,
(超级长啊)
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<iostream>
#include<cstring>
#include<string>
#include<cmath>
#include<ctime>
#include<set>
#include<vector>
#include<map>
#include<queue>
#define N 300005
#define M 8000005
#define ls (t<<1)
#define rs ((t<<1)|1)
#define mid ((l+r)>>1)
#define mk make_pair
#define pb push_back
#define fi first
#define se second
using namespace std;
int i,j,m,n,p,k,a[N];
int FindMin()
{
return a[1];
}
void build1()
{
sort(a+1,a+n+1);
}
void up(int now)
{
while (now&&a[now]<a[now/2]) swap(a[now],a[now/2]),now/=2;
}
void ins(int x)
{
a[++n]=x; up(n);
}
void down(int now)
{
while (now*2<=n)
{
if (now*2==n)
{
if (a[now]>a[now*2]) swap(a[now],a[now*2]),now*=2;
}
else
{
if (a[now]<=a[now*2]&&a[now]<=a[now*2+1]) break;
if (a[now*2]<a[now*2+1]) swap(a[now],a[now*2]),now*=2;
else swap(a[now],a[now*2+1]),now=now*2+1;
}
}
}
void del(int x)
{
swap(a[x],a[n]); --n;
up(x);
down(x);
}
void change(int x,int val)
{
if (a[x]>val)
{
a[x]=val;
up(x);
}
else
{
a[x]=val;
down(x);
}
}
void build2()
{
for (i=n/2;i>=1;--i) down(i);
}
int main()
{
scanf("%d",&n);
for (i=1;i<=n;++i) scanf("%d",&a[i]);
build2();
}
但是我们看了这么多,感觉这货并不咋地啊,完全用堆就能解决了QWQ,这个时候我们祭出真正的大杀器
求解第k大值(小扩展)
对于每一个节点,我们在它的结构体里多加一个size,表示这个节点里头字树的个数(包括其本身)
这样的话,我们就能二分地找到第k大的值了
对于根节点的两个儿子,我们看两边子树的size
如果右子树的size>k,那么第k大的数肯定在右子树里头,我们递归求解
如果右子树size+1==K,那么说明右子树就是第K大值
否则,我们就把k-(右子树的size+1),然后递归到左子树去
代码实现
int Findkth(int now, int k)
{
if (size[rs[now]] >= k) return Findkth(rs[now], k);
else if (size[rs[now]] + 1 == k) return key[now];
else return Findkth(ls[now], k - size[rs[now]] - 1);
}
如何遍历二叉搜索树呢?
我们可以注意到,由于二叉搜索树的左右儿子有严格的规定,所以我们就来一次中序排列就能把整个树给排好啦
中序遍历的方式:
每一次都先选左儿子走完之后再去访问根节点的信息,再去访问右儿子的信息,这里其实就是一个类似于DFS的操作,所谓中序排列就是左中右
这是代码
int dfs(int now)
{
if (ls[now]) dfs(ls[now]);
print(key[now]);
if (rs[now]) dfs(rs[now]);
}
我们让数列变成有序数列,然后取(right-left)/2作为root,这样就使得树高为logn
插入BST的时候,是不需要强制要求到底是先插入的数大还是后插入的数大,你可以<=放在左边,>放在右边,也可以<放在左边,>=放在右边,都是无所谓的
那么我们为什么要学习BST呢,
首先这是第一个能够利用树的中序遍历的性质的数据结构
而且二叉搜索树是很多重要数据结构的基础,比如之后我们要学到的splay ,treap或者SGT都是基于二叉搜索的
堆
堆是一种特殊的二叉树(完全二叉树)定义
也就是说我们不需要存孩子他爹是谁,对于节点i,他的父亲就一定是i/2,他的两个孩子就是i*2和i*2+1;
PS:二叉搜索树需要保持树的中序遍历不变,而堆则要保证每个点比两个儿子的权值都小,这就导致了堆既可以左中右也可以右中左,这样的话就无法求数的顺序,唯一的方法只有一个一个弹出,也就是说堆只能求最小值或者最大值,是不能求第k大的数的
我们如何建堆呢?
首先是要建出这么一个堆,最快捷的方法就是直接O(N log N)排一下序。(因为通过快排的一个有序数列本身就是一个堆)
反正堆的所有操作几乎都是O(log N)的。之后可以对这个建堆进行优化。
但是对于一个已知多少数据的数列,还有一种神奇的方法,就是倒序建堆,它的时间复杂度是O(n)的
具体是怎么实现的呢?
我们把一个乱序的数组当做一个堆,然后从最后一个数开始,对每一个数进行一次down(),这样就能把一个堆给排好了
我们可以发现每个点都比两个儿子要小(小根堆),所以最小值肯定就是Heap[1],那么为了维护堆的形态,所以我们只换权值,而不对位置进行改变
下面来讲一讲堆的一些基本操作步骤
插入(大雾
我们要对堆插入一个元素,但是并不是扔进去,让尾指针++就完事了,我们还得对堆的正确性进行维护。
来说一下思想,对于添加进来的元素,设其位置为now,那么他爹就是now/2(now>>1 位运算更快哦)
只要比较二者大小,如果新元素更小,那么就交换即可,否则意味着合法,我们直接退出循环就可以,循环的终止条件就是now!=1(因为当now==1时,它已经是堆首元素,没爹。。。。多苦的一孩子(大雾)
来看代码
inline void add(int x)
{
Heap[++cnt] = x;//这里小小的压了一下行
int now = cnt;
while (now!=1)
{
if (Heap[now] < Heap[now >> 1])
swap(Heap[now], Heap[now >> 1]),now>>=1;
else
break;
}
}
弹出
这个也要分为两种,一种是弹出堆首元素,另一种是弹出任意位置的元素(这种一般与寻找元素相结合,考察对DFS,BFS之类的搜索方法的能力)
先看弹出堆首元素,
想要弹出的话,我们就把最小值修改为INF(我比较喜欢1e9),然后和之前相反,向下比较直到找到合适为止为止。
具体讲一讲
因为小根堆的要求是所有根节点都得比他孩子小,所以我们定义首节点的位置为root=1,因为已经置成INF了,所以我们向下开始比较;
先让两个孩子比,最小的那个再和root比,如果比root小,那么就交换二者,否则符合条件就直接退出循环,这里的循环终止条件是 root << 1 <= cnt,也就是说root的儿子已经比当前的堆的长度大了,也就是不存在儿子了
但是这种方法其实不是很好啊,因为你排到最后,最底下就一大堆INF,难看的要死还占空间,倒不如直接交换首元素和尾元素,然后直接把尾指针减一就可以,这样的话最小值就被删除了,之后进行一下动态维护就可以。
来看代码
inline void pop()
{
Heap[1] = Heap[cnt--];
int root = 1;
while (root << 1 <= cnt)
{
int son;
if ((root << 1) + 1 > cnt ||
Heap[root << 1] < Heap[(root << 1) + 1])
{
son = root << 1;
}
else
son = (root << 1) + 1;
if (Heap[son] > Heap[root])
break;
swap(Heap[root], Heap[son]);
root = son;
}
}
输出堆首元素
这东西其实没啥好讲的,因为堆首元素就肯定是Heap[1]嘛,知道就行,然后就可以输出了,因为不对堆中元素进行移动和修改,是不影响堆的合法性的。
来看看插入
首先我们把一个数插入到堆尾,然后就循环着和他爹比,以小根堆为例,他如果比他爹小,那么就交换二者的权值, 然后对now进行一次赋值,否者直接退出循环就好了,while循环的条件是now!=1
再来看看删除,想要删除的话,我们就把最小值修改为无穷,然后和之前相反,向下比较直到找到合适为止为止,还是看看代码吧
但是这种方法其实不是很好啊,因为你排到最后,最底下就一大堆INF,难看的要死还占空间,倒不如直接交换首元素和尾元素,然后直接把尾指针减一就可以,这样的话最小值就被删除了,之后进行一下动态维护就可以了。
那么我们如何定位一个权值为x的值,并且对他进行操作呢?
一般来说,堆的写法不同,操作之后堆的形态不同,所以一般给的都是改变一个权值为多少的点.那么我们假设权值两两不同,再记录一下某个权值现在哪个位置。在交换权值的时候顺便交换位置信息。
还有就是删除一个值,这个吧和一开始我们说弹出堆首元素是不大一样的,因为虽然都是用最后一个元素和Heap[n]进行交换,但是因为元素n没有什么特殊性质,所以我们就不能只down,而是应该看看这货能上还是能下。
堆排的话就很水啊,把所有的数输进去然后边输边维护,最后直接把堆顶元素输出之后维护就行了,可以看一下我那个总结,当然也可以看看ych大佬的
有一个例题
丑数(也是真的够丑了)
丑数指的是质因子中仅包含2,
3, 5, 7的数,最小的丑数
是1,求前k个丑数。
K ≤ 6000.
打表大法好!没有什么是打表解决不了的.
算了说正经的。
考虑递增的来构造序列.
x被选中之后,接下来塞进去x * 2, x * 3, x * 5, x * 7.
如果当前最小的数和上一次选的一样,就跳过.
复杂度O(K log N)
下面看一看STL,手写堆真的很慢啊。
每次都要写堆太麻烦了有没有什么方便的。
在C + +的include
< queue >里有一个叫priority_queue的东西。(这玩意是优先队列,大根堆,你如果想用小根堆就得加一个greater)
是这样写的
priority_queue <int,vector<int>,less<int> > q;
priority_queue <int,vector<int>,greater<int> >q;
要注意不要忘掉最后的一个空格,不然编译的时候会当成>>右移
主要就这几种用法
Q.push()
Q.top()
Q.pop()
Q.clear()直接全清空
Q.empty()判是否为空,空返回1
看英文意思就好啦
但是堆还是太蒻了,我们来看个吊一点的
在C + +的include < set >里有一个叫set的东西。
这玩意的底层实现是一颗红黑树(一个高级一点的二叉搜索树)
st.insert()
st.erase()
st.fnd()
st.lower/upper bound() lower是>=,upper是>(也就是严格大于)
st.begin()/st.end()
其中,最后四个函数返回的值都是一个迭代器,(就是一个类似于指针的东西),迭代器是有值的,可以(而且是只能)++或--,但是其本身又能指向一个数组的值,直接加个*取值就行
比如int x=*a
堆有啥用
我也不知道它有啥用(大雾
其实也算是了解一种数据结构,为将来学习可并堆,斐波那契堆打下坚实基础(政治课即视感
关键是比STL快。(要不是题目卡时间我才不会手写堆 呕呕呕)
能优化dijkstra(图论).
RMQ
区间RMQ问题是指这样一类问题。
给出一个长度为N的序列,我们会在区间上干的什么(比如单点加,区间加,区间覆盖),并且询问一些区间有关的信息(区间的和,区间的最大值)等。
最简单的问题(其实并不太简单)
给出一个序列,每次询问区间最大值.
N ≤ 100000, Q ≤ 1000000
然后我们就引入ST表啦,那这玩意是个啥?
ST表
ST表是一种处理静态区间可重复计算问题的数据结构,一般也就求求最大最小值,其实主要还是牛在能够重复计算问题
ST表的思想是先求出每个[i, i + 2^k)的最值。
注意到这样区间的总数是O(N log N)的.
PS:log N这一复杂度是OI最常用复杂度(因为很多算法用到二分思想),而sqrt(N)是OI最玄学的复杂度。
来看看预处理
不妨令Fi,j为[i, i + 2^j)的最小值。
那么首先fi,0的值都是它本身。
而Fi,j = min(fi,j-1, fi+2j-1,j-1)
这样在O(N log N)的时间内就处理好了整个ST表
询问
比如我们要询问[l, r]这个区间的最小值.
找到最大的k满足2k ≤ r - l + 1.
取[l, l +
2k), [r - 2k + 1, r + 1)这两个区间。我们注意到这两个区间完全覆盖了[l,
r],所以这两个区间最小值较小的一个就是[l, r]的最小值。
注意到每次询问只要找区间就行了,所以复杂度是O(1).
注意
ST表确实是一个询问O(1)的数据结构,但是它的功效相对也较弱.因为它的区间是有重叠的,例如每次求一个区间的和,利用前缀和可以做到O(N) - O(1).而ST却无法完成
看个问题
给出一个序列,支持对某个点的权值修改,或者询问某个区间的最大值.
N, Q ≤ 100000
此时我们就得做题四部曲了(大雾)

冷静分析一下:
刚学了ST表,只需要O(1)就能询问了,那咋实现呢???
构思一下思路啊,看看能不能强行维护ST表
如果改5这个点
j = 0 改了一个位置 ,嗯,完美.
j = 1 改了两个位置 4, 5,稳.
j = 2 改了四个位置 2, 3, 4, 5,还行.
but。。。。。。。
当j往上走的时候,要改的区间的个数是这个点的编号.
现在修改一次要修改O(N)个点.
一看就很不靠谱
但是为什么不靠谱???
有可能是选定的区间有问题,换方法吧,看看下面这个。
线段树
其实线段树被称为区间树比较合适(因为是把一条线段不断二分),它的本质是一棵不会改变形态的二叉树.
树上的每个节点对应于一个区间[a,
b](也称线段),a,b通常为整数.
这就是一棵很好的二叉树
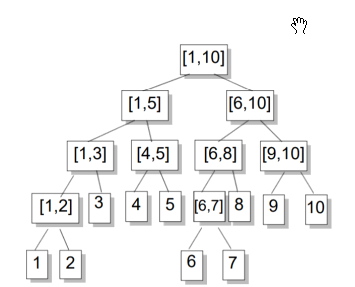
非叶节点就是区间长度不是1的线段
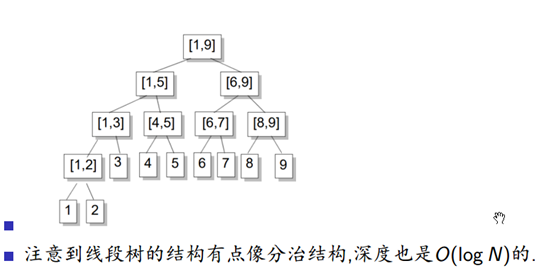
为了不让区间有重叠,我们采用区间拆分
区间拆分是线段树的核心操作,我们可以将一个区间[a, b]拆分成若干个节点,使得这些节点代表的区间加起来是[a, b],并
且相互之间不重叠.
所有我们找到的这些节点就是”终止节点”
如果说你的区间和左边有交的,那么一定有一个终止端点在左边,同理,右边有相交也一定有终止端点在右边,看上面那个树,求【2,8】,他两边都相交,所以我们两边分别递归求终止区间。

存线段树的时候,就一定要开四倍的n(其实不开到4倍也行,但是口口相传嘛,就这么开了)
(其实真正的原因是这样的,我们画一下图就能发现,当对一个线段长度为10的线段进行拆分的时候就已经有20个节点,虽然我们不知道这个增长频率是什么,但是应该比较是2^logN吧)
、
T代表区间所代表的节点的编号,l,r是线段树上的区间,ll,rr是实际要分解的区间
如果区间被完全包含,那么直接return,否则就看左右端点的情况,继续递归拆分。
我们要充分利用区间分解的性质,思考在终止节点要存什么信息,如何快速维护这些信息,不要每次一变就到最底层.
例一
给一个数的序列A1, A2, ..., An.并且可能多次进行下列两个操作:
1.对序列里面的某个数进行加减
2.询问这个序列里面任意一个连续的子序列Ai, Ai+1...Aj的和是多少.
3.希望单个操作能在O(log N)的时间内完成.
题解
对于每个节点[L, R],我们记录AL + ... + AR.对于操作1:相当于我们对[i, i]这个区间做了一个区间分解.沿路我们在找到[i,i]时经过的所有祖先节点.
对于操作2:我们对[L, R]做一个区间分解,将每个区间对应的和累加起来就是想要知道的区间和.
[POJ 3264]Balanced Lineup
给定Q个数A1, ..., AQ,多次询问,每次求某一区间[L, R]中最大
值和最小值的差.
Q ≤ 50000
这个题我们只需要存一下每个区间的最大值和最小值,再对两个儿子进行合并就行,合并的时候要注意更新最大值和最小值就可以了
[POJ 3468]A Simple Problem with Integers
给定Q个数A1, ..., AQ,多次进行以下操作:
1.对区间[L, R]中的每个数都加n.
2.求某个区间[L, R]中的和.
Q ≤ 100000
如果我们对l到r的每个数都加n的话,我们肯定至少是要走一遍O(n)的,但是这样很慢啊,考虑我们对于区间的结构体里头加一个inc这个变量,用来记录增加了多少,等到我们最终需要输出的时候,再把inc加上就好了
这就是一个非常重要的思想
延迟更新:
信息更新时,未必要真的做彻底的更新,可以只是将应该如何更新记录下来,等到真正需要查询准确信息时,才去更新查询的部分。
在区间增加时,如果要加的区间正好覆盖一个节点,则增加
其节 点的inc值和sum值,不再往下走
举个例子
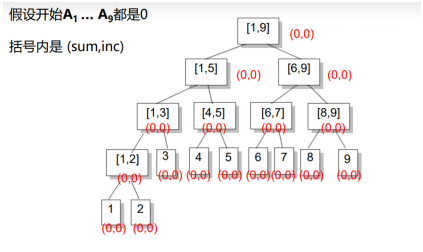
这里用一个down函数来一步步把inc传递给其子区间
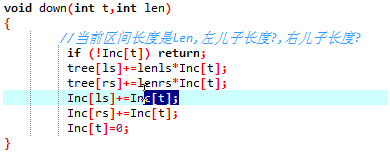
Inc先看看是不是整个区间,如果是就直接打上标记,否则就再次递归
对于区间和,只要有一个字树改变,那么这个子树所有的祖宗都要加a,叶节点的inc标记因为没有儿子,所以他的inc是不可能下传的
看一下代码吧
int i,j,m,n,p,k,lazy[N*4],sum[N*4],a[N],ans,x,c,l,r; void build(int l,int r,int t) { if (l==r) sum[t]=a[l]; else { build(l,mid,ls); build(mid+1,r,rs); sum[t]=sum[ls]+sum[rs]; } } void down(int t,int len) //对lazy标记进行下传 { if (!lazy[t]) return; sum[ls]+=lazy[t]*(len-len/2); sum[rs]+=lazy[t]*(len/2); lazy[ls]+=lazy[t]; lazy[rs]+=lazy[t]; lazy[t]=0; } void modify(int ll,int rr,int c,int l,int r,int t) //[ll,rr]整体加上c { if (ll<=l&&r<=rr) { sum[t]+=(r-l+1)*c; //对[l,r]区间的影响就是加上了(r-l+1)*c lazy[t]+=c; } else { down(t,r-l+1); if (ll<=mid) modify(ll,rr,c,l,mid,ls); if (rr>mid) modify(ll,rr,c,mid+1,r,rs); sum[t]=sum[ls]+sum[rs]; } } void ask(int ll,int rr,int l,int r,int t) //对于区间[l,r]进行询问 { if (ll<=l&&r<=rr) ans+=sum[t]; //代表着找到了完全被包含在内的一个区间 else { down(t,r-l+1); if (ll<=mid) ask(ll,rr,l,mid,ls); if (rr>mid) ask(ll,rr,mid+1,r,rs); } } int main() { scanf("%d%d",&n,&m); for (i=1;i<=n;++i) scanf("%d",&a[i]); build(1,n,1); }
来看看这个例题
[POJ2528]Mayor’s posters

我们得先对数据进行一些处理,你得让在1kw的砖块数量减少啊,我们将海报的所有的端点都拿出来,排序去之后去重。
对于两个端点之间的部分,每块砖要么完全经过它们,要么完全不经过它们,我们把它们当成一块砖,然后就可以把砖块数量减低到4w个了,一共2w个端点,相邻两个端点之间生成一个砖块
算上端点在内,一共不超过4w块砖,而且两个端点中间还不一定有砖
那么我们从最底层的海报开始,一张一张往上贴.
对于一个区间[L, R],我们记录的信息是这个区间整体被第几张海报覆盖了,初始值设为-1,对于一张包含[L, R]的海报i,我们就只需要把[L, R]里面所有的位置都赋成i就可以了
这里有一个思考性的问题,会不会出现后来的标记被之前的标记覆盖呢?
其实想一想的话是不会的,因为我只要打了标记就一定向下传递,而此时新的标记还没有打,就没问题啦
ZYB 画画
给出长度为N的序列A,
Q次操作,两种类型:
(1 x v),将Ax改成v.
(2 l r) 询问区间[l,
r]中有多少段不同数。例如2 2 2 3 1 1 4,就是4段。
N, Q ≤ 100000
线段树上的每个节点都维护三个信息:这段区间有多少段不同的数,最右边的数,最左边的数.(每个节点其实是一个区间(或一个点))
这段区间有多少段不同的数,最右边的数,最左边的数,合并的时候,如果中间接上的地方相同,则段数-1.
非常简单的线段树合并操作.时间复杂度O((N + Q) log N)
树状数组
我们其实就可以开一个结构体,里面存sum,l,r,合并的时候我们看左儿子最右边的数是不是等于右儿子最左边的数,如果相等,那么不同的段数就-1
我们就这么递归着来求
树状数组
讲了RMQ问题,再来讲讲树状数组.
树状数组是一种用来求前缀和的数据结构.
记lowbit(x)为x的二进制最低位.
就是最低位的1所代表的数
例子:lowbit(8)
= 8, lowbit(6) = 2
对于原始数组A,我们设一个数组C.
C[i]=a[i-lowbit(i)+1]+...+a[i]
i > 0的时候C[i]才有用.C就是树状数组
LCA
在一棵有根树中,树上两点x, y的LCA指的是x, y向根方向遇
到到第一个相同的点.
我们记每一个点到根的距离为deepx
在一棵有根树中,树上两点x, y的LCA指的是x, y向根方向遇
到到第一个相同的点.
我们记每一个点到根的距离为deepx.
注意到x, y之间的路径长度就是deepx
+ deepy - 2 * deepLCA.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号