
oracle数据去重
oracle数据去重
一、创建测试表
-- Create table
create table TEST3
(
id NUMBER,
name VARCHAR2(20),
card VARCHAR2(20),
address VARCHAR2(20),
zone VARCHAR2(20)
);
二、插入测试数据
insert into test3 values(1,'张三','132111111111111111','中国','河南');
insert into test3 values(2,'李四','132111122222222211','美国','纽约');
insert into test3 values(3,'王五','132111122222222211','英国','伦敦');
insert into test3 values(4,'赵六','132111111111111111','法国','巴黎');
insert into test3 values(5,'严七','132111111333331111','中国','河北');
commit;
三、distinct去重
select distinct t.card from test3 t;
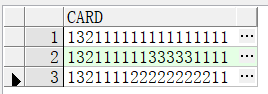
distinct去重局限性很大,结果中只能有去重列。
四、row_number()函数去重
以card字段分组,然后在分组内部按id号排序,序号从1开始递增,没有重复。只取序号为1的记录,即完成去重。
查询去重后的数据
select *
from (select t1.*,
row_number() over(partition by t1.card order by t1.id) as nu
from test3 t1) t1
where t1.nu = 1

row_number() over(partition by t1.card order by t1.id desc) as nu,这条语句为使用t1.card字段进行分组,然后按t1.id在分组内部排序,序号从1开始,最后将排序后的序号赋值给nu字段。
测试发现,如果没有唯一字段如ID字段,将ID字段替换成一个数字也行:
select *
from (select t1.*,
row_number() over(partition by t1.card order by 1 desc) as nu
from test3 t1) t1
where t1.nu = 1

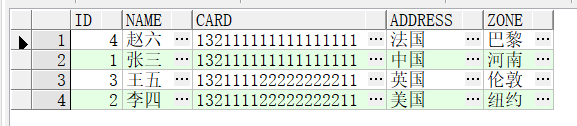
五、查询出所有重复的数据
group by方式:
select *
from test3 t1
where t1.card in
(select t2.card from test3 t2 group by t2.card having count(1) > 1)
over分组方式:
select *
from (select t1.*, count(1) over(partition by t1.card order by 1) as nu
from test3 t1) t1
where t1.nu > 1

六、删除重复数据只保留一条
over分组方式:
delete from test3 t1
where t1.rowid in (select t2.rowid
from (select t2.rowid,
count(1) over(partition by t2.card order by t2.id) nu
from test3 t2) t2
where t2.nu > 1)

group by方式:
delete from test3 t1
where t1.rowid not in
(select max(t2.rowid) from test3 t2 group by t2.card)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号