

hadoop进阶
Java 多线程安全机制
1、操作系统有两个容易混淆的概念,进程和线程。
进程:一个计算机程序的运行实例,包含了需要执行的指令;有自己的独立地址空间,包含程序内容和数据;不同进程的地址空间是互相隔离的;进程拥有各种资源和状态信息,包括打开的文件、子进程和信号处理。
线程:表示程序的执行流程,是CPU调度执行的基本单位;线程有自己的程序计数器、寄存器、堆栈和帧。同一进程中的线程共用相同的地址空间,同时共享进进程锁拥有的内存和其他资源。
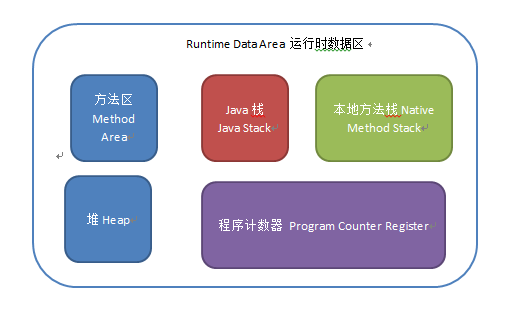
在开始讨论java多线程安全机制之前,首先从内存模型来了解一下什么是多线程的安全性。
我们都知道java的内存模型中有主内存和线程的工作内存之分,主内存上存放的是线程共享的变量(实例字段,静态字段和构成数组的元素),线程的工作内存是线程私有的空间,存放的是线程私有的变量(方法参数与局部变量)。线程在工作的时候如果要操作主内存上的共享变量,为了获得更好的执行性能并不是直接去修改主内存而是会在线程私有的工作内存中创建一份变量的拷贝(缓存),在工作内存上对变量的拷贝修改之后再把修改的值刷回到主内存的变量中去,JVM提供了8中原子操作来完成这一过程:lock, unlock, read, load, use, assign, store, write。深入理解java虚拟机-jvm最高特性与实践这本书中有一个图很好的表示了线程,主内存和工作内存之间的关系:
如果只有一个线程当然不会有什么问题,但是如果有多个线程同时在操作主内存中的变量,因为8种操作的非连续性和线程抢占cpu执行的机制就会带来冲突的问题,也就是多线程的安全问题。线程安全的定义就是:如果线程执行过程中不会产生共享资源的冲突就是线程安全的。
Java里面一般用以下几种机制保证线程安全:
1.互斥同步锁(悲观锁)
1)Synchorized
2)ReentrantLock
互斥同步锁也叫做阻塞同步锁,特征是会对没有获取锁的线程进行阻塞。
要理解互斥同步锁,首选要明白什么是互斥什么是同步。简单的说互斥就是非你即我,同步就是顺序访问。互斥同步锁就是以互斥的手段达到顺序访问的目的。操作系统提供了很多互斥机制比如信号量,互斥量,临界区资源等来控制在某一个时刻只能有一个或者一组线程访问同一个资源。
Java里面的互斥同步锁就是Synchorized和ReentrantLock,前者是由语言级别实现的互斥同步锁,理解和写法简单但是机制笨拙,在JDK6之后性能优化大幅提升,即使在竞争激烈的情况下也能保持一个和ReentrantLock相差不多的性能,所以JDK6之后的程序选择不应该再因为性能问题而放弃synchorized。ReentrantLock是API层面的互斥同步锁,需要程序自己打开并在finally中关闭锁,和synchorized相比更加的灵活,体现在三个方面:等待可中断,公平锁以及绑定多个条件。但是如果程序猿对ReentrantLock理解不够深刻,或者忘记释放lock,那么不仅不会提升性能反而会带来额外的问题。另外synchorized是JVM实现的,可以通过监控工具来监控锁的状态,遇到异常JVM会自动释放掉锁。而ReentrantLock必须由程序主动的释放锁。
互斥同步锁都是可重入锁,好处是可以保证不会死锁。但是因为涉及到核心态和用户态的切换,因此比较消耗性能。JVM开发团队在JDK5-JDK6升级过程中采用了很多锁优化机制来优化同步无竞争情况下锁的性能。比如:自旋锁和适应性自旋锁,轻量级锁,偏向锁,锁粗化和锁消除。
2.非阻塞同步锁
1) 原子类(CAS)
非阻塞同步锁也叫乐观锁,相比悲观锁来说,它会先进行资源在工作内存中的更新,然后根据与主存中旧值的对比来确定在此期间是否有其他线程对共享资源进行了更新,如果旧值与期望值相同,就认为没有更新,可以把新值写回内存,否则就一直重试直到成功。它的实现方式依赖于处理器的机器指令:CAS(Compare And Swap)
CAS 指的是现代 CPU 广泛支持的一种对内存中的共享数据进行操作的一种特殊指令。这个指令会对内存中的共享数据做原子的读写操作
JUC中提供了几个Automic类以及每个类上的原子操作就是乐观锁机制。
不激烈情况下,性能比synchronized略逊,而激烈的时候,也能维持常态。激烈的时候,Atomic的性能会优于ReentrantLock一倍左右。但是其有一个缺点,就是只能同步一个值,一段代码中只能出现一个Atomic的变量,多于一个同步无效。因为他不能在多个Atomic之间同步。
非阻塞锁是不可重入的,否则会造成死锁。
3.无同步方案
1)可重入代码
在执行的任何时刻都可以中断-重入执行而不会产生冲突。特点就是不会依赖堆上的共享资源
2)ThreadLocal/Volaitile
线程本地的变量,每个线程获取一份共享变量的拷贝,单独进行处理。
3) 线程本地存储
如果一个共享资源一定要被多线程共享,可以尽量让一个线程完成所有的处理操作,比如生产者消费者模式中,一般会让一个消费者完成对队列上资源的消费。典型的应用是基于请求-应答模式的web服务器的设计
三:解决机制
1. 加锁。
(1) 锁能使其保护的代码以串行的形式来访问,当给一个复合操作加锁后,能使其成为原子操作。一种错误的思想是只要对写数据的方法加锁,其实这是错的,对数据进行操作的所有方法都需加锁,不管是读还是写。
(2) 加锁时需要考虑性能问题,不能总是一味地给整个方法加锁synchronized就了事了,应该将方法中不影响共享状态且执行时间比较长的代码分离出去。
(3) 加锁的含义不仅仅局限于互斥,还包括可见性。为了确保所有线程都能看见最新值,读操作和写操作必须使用同样的锁对象。
2. 不共享状态
(1) 无状态对象: 无状态对象一定是线程安全的,因为不会影响到其他线程。
(2) 线程关闭: 仅在单线程环境下使用。
3. 不可变对象
可以使用final修饰的对象保证线程安全,由于final修饰的引用型变量(除String外)不可变是指引用不可变,但其指向的对象是可变的,所以此类必须安全发布,也即不能对外提供可以修改final对象的接口。
mapreduce的原理
下面这幅图就是mapreduce的工作原理
1)首先文档的数据记录(如文本中的行,或数据表格中的行)是以“键值对”的形式传入map 函数,然后map函数对这些键值对进行处理(如统计词频),然后输出到中间结果。
2)在键值对进入reduce进行处理之前,必须等到所有的map函数都做完,所以既为了达到这种同步又提高运行效率,在mapreduce中间的过程引入了barrier(同步障)
在负责同步的同时完成对map的中间结果的统计,包括 a. 对同一个map节点的相同key的value值进行合并,b. 之后将来自不同map的具有相同的key的键值对送到同一个reduce进行处理。
3)在reduce阶段,每个reduce节点得到的是从所有map节点传过来的具有相同的key的键值对。reduce节点对这些键值进行合并。
1)Combiner 节点负责完成上面提到的将同一个map中相同的key进行合并,避免重复传输,从而减少传输中的通信开销。
2)Partitioner节点负责将map产生的中间结果进行划分,确保相同的key到达同一个reduce节点.
MapReduce shuffle阶段详解
在Mapreduce中,Shuffle过程是Mapreduce的核心,它分布在Mapreduce的map阶段和reduce阶段,共可分为6个详细的阶段:
1).Collect阶段:将MapTask的结果输出到默认大小为100M的MapOutputBuffer内部环形内存缓冲区,保存
的是key/value,Partition分区
2).Spill阶段:当内存中的数据量达到一定的阀值的时候,就会将数据写入本地磁盘,在将数据写入磁盘
之前需要对数据进行一次排序的操作,先是对partition分区号进行排序,再对key排序,如果配置了
combiner,还会将有相同分区号和key的数据进行排序,如果有压缩设置,则还会对数据进行压缩操作。
3).Combiner阶段:等MapTask任务的数据处理完成之后,会对所有map产生的数据结果进行一次合并操作,
以确保一个MapTask最终只产生一个中间数据文件。
4).Copy阶段:当整个MapReduce作业的MapTask所完成的任务数据占到MapTask总数的5%时,JobTracker就会
调用ReduceTask启动,此时ReduceTask就会默认的启动5个线程到已经完成MapTask的节点上复制一份属于自
己的数据,这些数据默认会保存在内存的缓冲区中,当内存的缓冲区达到一定的阀值的时候,就会将数据写
到磁盘之上。
5).Merge阶段:在ReduceTask远程复制数据的同时,会在后台开启两个线程对内存中和本地中的数据文件进行
合并操作。
6).Sort阶段:在对数据进行合并的同时,会进行排序操作,由于MapTask阶段已经对数据进行了局部的排序,
ReduceTask只需做一次归并排序就可以保证Copy的数据的整体有效性。
Spark Shuffle进化史
先以图为例简单描述一下Spark中shuffle的整一个流程:

- 首先每一个Mapper会根据Reducer的数量创建出相应的bucket,bucket的数量是M×RM×R,其中MM是Map的个数,RR是Reduce的个数。
- 其次Mapper产生的结果会根据设置的partition算法填充到每个bucket中去。这里的partition算法是可以自定义的,当然默认的算法是根据key哈希到不同的bucket中去。
- 当Reducer启动时,它会根据自己task的id和所依赖的Mapper的id从远端或是本地的block manager中取得相应的bucket作为Reducer的输入进行处理。
这里的bucket是一个抽象概念,在实现中每个bucket可以对应一个文件,可以对应文件的一部分或是其他等。
Apache Spark 的 Shuffle 过程与 Apache Hadoop 的 Shuffle 过程有着诸多类似,一些概念可直接套用,例如,Shuffle 过程中,提供数据的一端,被称作 Map 端,Map 端每个生成数据的任务称为 Mapper,对应的,接收数据的一端,被称作 Reduce 端,Reduce 端每个拉取数据的任务称为 Reducer,Shuffle 过程本质上都是将 Map 端获得的数据使用分区器进行划分,并将数据发送给对应的 Reducer 的过程。
2.OOM咋办
首先,要搞清OOM的分类:
OMM主要三类: permgen OOM , heap OOM, stack overflow
permgen OOM: 这个主要是由于加载的类太多,或者反射的类太多, 还有 调用 String.intend(jdk7之前)也会造成这个问题。所以出现了这个问题,就检查这三个方面;
heap OOM: 基本是按照 1楼的方式就可以解决了,主要是因为一些无用对象没有及时释放造成的,检查代码加上 heap dump 去分析吧
stack overflow: 这个主要是由于调用层数,或者递归深度太大造成的,看异常信息,基本上就能定位得出来了
什么情况下会出现OOM?
(1)内存泄漏(连接未关闭,单例类中不正确引用了对象)
(2)代码中存在死循环或循环产生过多重复的对象实体
(3)Space(空间)大小设置不正确
(4)内存中加载的数据量过于庞大,如一次从数据库取出过多数据
(5)集合类中有对对象的引用,使用完后未清空,使得JVM不能回收
Spark面对OOM问题的解决方法及优化总结
- map执行中内存溢出
- shuffle后内存溢出
- execution内存是执行内存,文档中说join,aggregate都在这部分内存中执行,shuffle的数据也会先缓存在这个内存中,满了再写入磁盘,能够减少IO。其实map过程也是在这个内存中执行的。
- storage内存是存储broadcast,cache,persist数据的地方。
- other内存是程序执行时预留给自己的内存。
1. map过程产生大量对象导致内存溢出:
conf.registerKryoClasses(Array(classOf[MyClass1],classOf[MyClass2]))
valsc =newSparkContext(conf)
spark streaming流量控制
随着计算机机硬件的快速发展,机器的内存大小也从原来的以兆为单位到现在的上百G,这也推动了分布式计算从原来的基于硬盘存储发展到现在的基于内存存储,spark作为实时计算的佼佼者也逐渐的走上了大规模商业应用的道路,spark streaming常常用在实时流计算的各个领域,在这一章节我们主要讲解一下streaming处理过程中的流量控制,在我们平时的streaming程序开发过程中应该注意哪些方面以提高程序的吞吐量
流控的目标
系统进行流控的主要目的是维护系统的稳定性,避免大流量数据的处理造成系统的扰动,最终导致系统宕机;流式处理平台系统在进行流控设计时,需要综合考虑稳定性、吞吐量、端到端的延迟,流控经常是在这三者之间做选择;
spark streaming流控
spark streaming程序通常是以指定时间间隔(batch interval)周期性的处理这个时间片内的批量数据,在这种场景下,稳定性指定的是这批数据必须在当前这个周期内处理完毕,系统最大吞吐量为处理时间等于时间间隔时的数据流量;由于spark streaming的周期在系统启动的时候就已经确定了,其流控退化为调整数据的流入速率以最大的提高系统的吞吐量;线上的streaming程序的处理时间和数据的批量大小并没有固定的规律可循,同时一个其他的突发因素(如发生GC)也会影响到数据的处理速率;spark streaming的流控需要做的是基于过去一段时间内的已经处理完成的批量数据来推算出下一个周期内应该处理的数据量,另外,一个好的流控算法需要更敏捷、更准确、更通用。
PID流控算法
上述篇幅已经讨论了流控的目标以及好的流控算法的标准,工程实践中广泛应用的流控算法有很多,spark采用了PID控制算法(spark.streaming.backpressure.rateEstimator参数指定),细节请参考WIKI,
spark streaming中误差为lastestRate - currentRate,目标值也为lastestRate,积分部分为系统当前的积压消息速率,计算方式为schedulingDelay * processingRate / batchIntervalMillis,schdulingDelay为这批数据从开始执行时间减去提交时间,newRate = (latestRate - proportional * error - integral * historicalError - derivative * dError).max(minRate),dError为误差的微分,详细代码见PIDRateEstimator;
def compute(
time: Long, // in milliseconds
numElements: Long,
processingDelay: Long, // in milliseconds
schedulingDelay: Long // in milliseconds
): Option[Double] = {
logTrace(s"\ntime = $time, # records = $numElements, " +
s"processing time = $processingDelay, scheduling delay = $schedulingDelay")
this.synchronized {
if (time > latestTime && numElements > 0 && processingDelay > 0) {
// in seconds, should be close to batchDuration
val delaySinceUpdate = (time - latestTime).toDouble / 1000
// in elements/second
val processingRate = numElements.toDouble / processingDelay * 1000
// In our system `error` is the difference between the desired rate and the measured rate
// based on the latest batch information. We consider the desired rate to be latest rate,
// which is what this estimator calculated for the previous batch.
// in elements/second
val error = latestRate - processingRate
// The error integral, based on schedulingDelay as an indicator for accumulated errors.
// A scheduling delay s corresponds to s * processingRate overflowing elements. Those
// are elements that couldn't be processed in previous batches, leading to this delay.
// In the following, we assume the processingRate didn't change too much.
// From the number of overflowing elements we can calculate the rate at which they would be
// processed by dividing it by the batch interval. This rate is our "historical" error,
// or integral part, since if we subtracted this rate from the previous "calculated rate",
// there wouldn't have been any overflowing elements, and the scheduling delay would have
// been zero.
// (in elements/second)
val historicalError = schedulingDelay.toDouble * processingRate / batchIntervalMillis
// in elements/(second ^ 2)
val dError = (error - latestError) / delaySinceUpdate
val newRate = (latestRate - proportional * error -
integral * historicalError -
derivative * dError).max(minRate)
logTrace(s"""
| latestRate = $latestRate, error = $error
| latestError = $latestError, historicalError = $historicalError
| delaySinceUpdate = $delaySinceUpdate, dError = $dError
""".stripMargin)
latestTime = time
if (firstRun) {
latestRate = processingRate
latestError = 0
firstRun = false
logTrace("First run, rate estimation skipped")
None
} else {
latestRate = newRate
latestError = error
logTrace(s"New rate = $newRate")
Some(newRate)
}
} else {
logTrace("Rate estimation skipped")
None
}
}
提示:该处的所有时间均是以批量数据作为单位的,如一个streaming应用程序消费了三个数据源,其最终会生成一个Jobset,其总共包含三个Job,submitTime为JobSet的创建时间,processStartTime为第一个Job的处理时间,processEndTime为最后一个Job的处理完成的时间。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号