

将迁移学习用于文本分类 《 Universal Language Model Fine-tuning for Text Classification》
将迁移学习用于文本分类 《 Universal Language Model Fine-tuning for Text Classification》
本文发表于自然语言处理领域顶级会议 ACL 2018
原文链接
特别说明:笔记掺杂了本人大量的个人理解,以及口语化的语言,由于本人水平有限,极有可能曲解原文的意思,各位看官随意看看,切莫当真~
摘要
迁移学习在图像领域大放异彩,可是在NLP领域却用途寥寥,这是因为现有的NLP模型都与迁移学习不兼容,每次更新任务都需要重头开始训练模型,否则就会导致模型习得的语言特征灾难性地丢失。本文深知迁移学习才是NLP研究的新方向,故本文提出了一个新型的可以用于所有NLP任务的“超级模型”——ULMFiT !!!!!!! 经过严密实验,本文提出的ULMFiT模型吊打一切现有NLP分类模型,牛得一批!!!!!
模型介绍
假设我们有源任务TsTs,我们想把它迁移到任意一个目标任务TtTt上去,并且我们希望这种迁移效果尽可能的要好,最好我们只要针对源任务TsTs训练一次模型,然后一辈子就靠这个模型打天下,它能适用于全世界所有NLP任务,人们就一劳永逸啦,哈哈哈哈!
有了上述的宏伟理想,我们就要开始朝它努力了啊!
所以我们的模型必须要考虑到NLP任务的方方面面,这样才能打遍天下无敌手,所谓的“长文本语义依赖问题”,“各种粒度的语义分析”啊等等问题,都得考虑到,都是小菜一碟!
我们的模型分为两部分,其一就是一个语言模型。该模型是在一个大型的通用语料库上训练的,因为我们致力于做出一个通用的模型,所以我们的语料库大到你无法想象,反正就是超级大就对了,能够胜任NLP的所有任务! 等该模型训练好之后,我们再对其进行微调就可以让其去解决不同的特定领域的问题啦!哈哈哈!!
说了那么多,我们的模型是啥呢? 没错!当然是目前最先进的AWD-LSTM模型啦!(什么?不知道这模型是啥?百度啊?还指望我解释?!吔屎啦你!)
用通用的大到你无法想象的语料库训练完最先进的AWD-LSTM模型之后,我们接下来该做啥呢?没错!就是对该通用模型进行微调,然后让其适应于特定任务!那么该怎么微调呢? 我们有两个独门秘笈:
-
Discriminative fine-tuning(为了让秘笈看上去更神秘就不翻译了)
具体而言, 就是为我们的模型的每一层分配不同的学习率, 参数更新时, 各层按照各自的学习率进行更新. 此处作者提出了一个技巧, 先通过只调整最后一层的参数确定一个合适的学习率, 然后往前的每一层都使用后一层学习率的2.6分之一倍.
(我也不知道为啥这么做效果会变好,原文也没说,看来独门秘笈果然是高深莫测我也不知道为啥这么做效果会变好,原文也没说,看来独门秘笈果然是高深莫测) -
Slanted triangular learning rates(不翻译,理由同上)
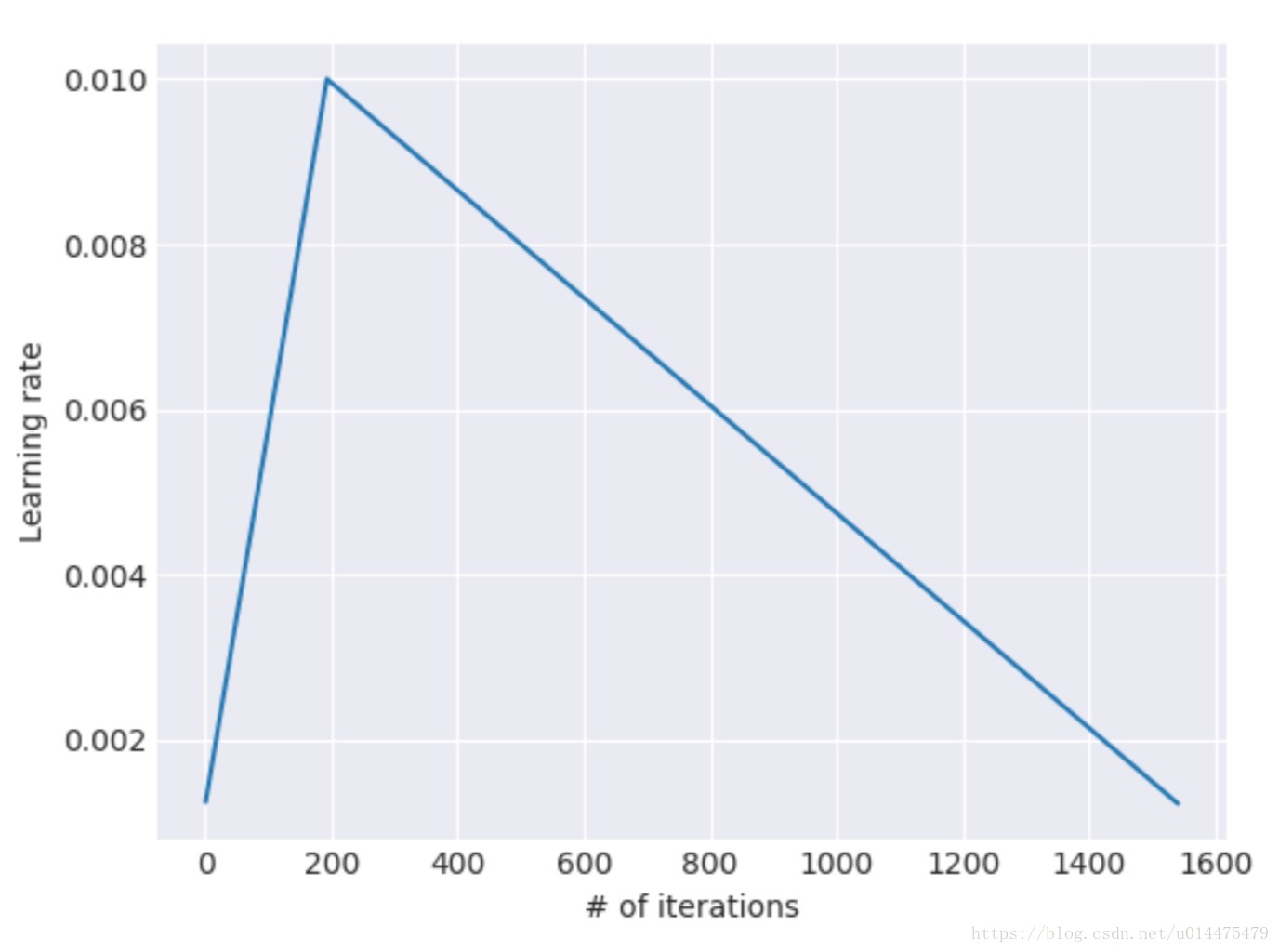
具体而言,是一种新型的学习率更新方式,由于采用该方式学习率的变化图形会像一个“三角形”一样,所以该秘笈的名字里也带了“triangular”。如图所示:
其中横轴是模型的迭代次数,纵轴是学习率。具体公式如下:
其中TT是模型的迭代次数
cut_frac=学习率增长的迭代次数迭代的总次数cut_frac=学习率增长的迭代次数迭代的总次数(上图中为2001600=0.1252001600=0.125)
cutcut是学习率增长和下降的分界点(上图中为200)
ratioratio为学习率最大值和最小值的差值
ηmaxηmax为学习率的最大值
ηtηt为模型迭代到第t次时的学习率(注:这些公式的数值是我根据上图方便读者理解从图中用肉眼读出来的,与原文实验无关)。
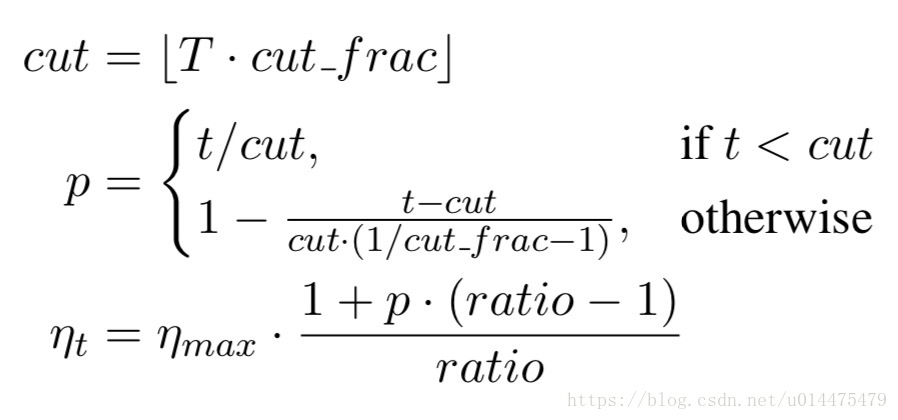
使用独门秘笈调整完咱们的通用模型之后是不是就万事大吉了呢?当然没有这么简单,要知道,本文的模型,牛逼到你无法想象!
我们接下来要将通用模型应用到特定的分类任务上,那么我们还得针对特定任务对模型增加两个全连接层,这俩全连接层都进行了normalization和dropout,激活函数采用Relu。最后再将这俩层接一个softmax的输出层,输出各个类别的概率就OK啦!
最后注意! 咱们的整个流程中,只有最后的俩全连接层和输出层的参数是从零开始学习的!
还有一个问题,咱们的牛逼模型(AWD-LSTM)与最后俩全连接层咋连接呢?
考虑到文本分类问题中,每个句子内真正对分类有帮助的词语只有极少部分,所以我们必须充分的提取文本的信息才能达到比较好的效果,所以我们将牛逼模型(AWD-LSTM)的隐含层最终状态的输出hThT作为我们全连接层的输入,这样就够了吗?
当然不够!
小小的hThT当然不能充分提取出句子的所有信息,我们要对其进行充分的提取,所以我们将其进行各种pool操作,max_pool,mean_pool,一起上!怎么凶猛怎么操作!直到把GPU的显存全部塞满为止!最后将这些pool操作提取的向量和hThT一起给concat起来,就得到了我们全连接层的输入:
对最后全连接层的调参将极大的影响到我们的最终效果
因为如果调参过于狂野的话, 会导致我们牛逼模型(AWD-LSTM)习得的特征被灾难性地遗忘, 相当于前功尽弃。而如果我们过于调参过于细致的话, 算法的收敛速度又会大幅下降。这可咋办呢?别慌!我们还有秘笈!
Gradual unfreezing(不翻译,理由同上)
具体而言, 就是开始调参的时候,将除最后一层以外所有层的参数都给冻结 (就是设置参数不可更新), 然后再一步步向前一层解冻.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号