
指针生成网络(Pointer-Generator-Network)原理与实战
指针生成网络(Pointer-Generator-Network)原理与实战
0 前言
本文主要内容:介绍Pointer-Generator-Network在文本摘要任务中的背景,模型架构与原理、在中英文数据集上实战效果与评估,最后得出结论。参考的《Get To The Point: Summarization with Pointer-Generator Networks》以及多篇博客均在文末给出连接,文中使用数据集已上传百度网盘,代码已传至GitHub,读者可以在文中找到相应连接,实际操作过程中确实遇到很多坑,并未在文中一一指明,有兴趣的读者可以留言一起交流。由于水平有限,请读者多多指正。
随着互联网飞速发展,产生了越来越多的文本数据,文本信息过载问题日益严重,对各类文本进行一个“降 维”处理显得非常必要,文本摘要便是其中一个重要的手段。文本摘要旨在将文本或文本集合转换为包含关键信息的简短摘要。按照输出类型可分为抽取式摘要和生成式摘要。抽取式摘要从源文档中抽取关键句和关键词组成摘要,摘要全部来源于原文。生成式摘要根据原文,允许生成新的词语、原文本中没有的短语来组成摘要。
指针生成网络属于生成式模型。
仅用Neural sequence-to-sequence模型可以实现生成式摘要,但存在两个问题:
1. 可能不准确地再现细节, 无法处理词汇不足(OOV)单词;
2. 倾向于重复自己。
原文是(they are liable to reproducefactual details inaccurately, and they tendto repeat themselves.)
指针生成网络(Pointer-Generator-Network)从两个方面进行了改进:
1. 该网络通过指向(pointer)从源文本中复制单词,有助于准确地复制信息,同时保留通过生成器产生新单词的能力;
2. 使用coverage机制来跟踪已总结的内容,防止重复。
接下来从下面几个部分介绍Pointer-Generator-Network原理:
1. Baseline sequence-to-sequence;
2. Pointer-Generator-Network;
3. Coverage Mechanism。
1 Baseline sequence-to-sequence
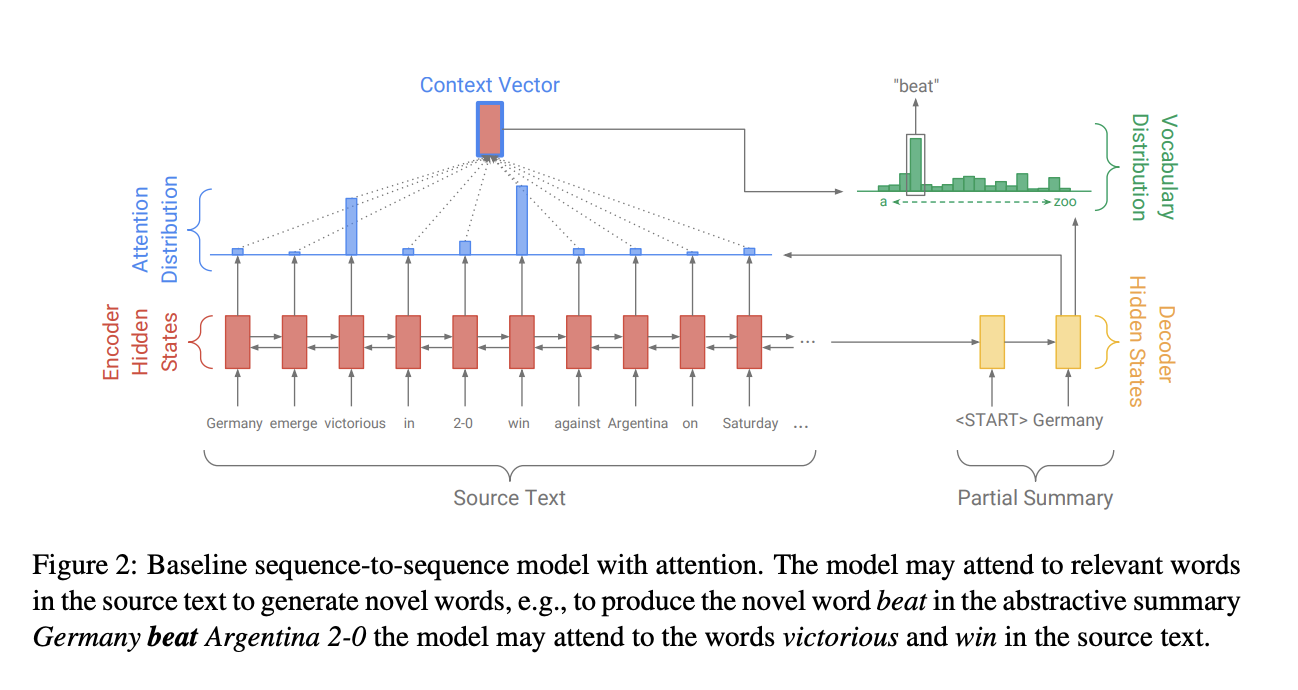
Seq2Seq的模型结构是经典的Encoder-Decoder模型,即先用Encoder将原文本编码成一个中间层的隐藏状态,然后用Decoder来将该隐藏状态解码成为另一个文本。Baseline Seq2Seq在Encoder端是一个双向的LSTM,这个双向的LSTM可以捕捉原文本的长距离依赖关系以及位置信息,编码时词嵌入经过双向LSTM后得到编码状态 hihi 。在Decoder端,解码器是一个单向的LSTM,训练阶段时参考摘要词依次输入(测试阶段时是上一步的生成词),在时间步 tt得到解码状态 stst 。使用hihi和stst得到该时间步原文第 ii个词注意力权重。
得到的注意力权重和 hihi加权求和得到重要的上下文向量 h∗t(contextvector)ht∗(contextvector):
h∗tht∗可以看成是该时间步通读了原文的固定尺寸的表征。然后将 stst和 h∗tht∗ 经过两层线性层得到单词表分布 PvocabPvocab:
其中 [st,h∗t][st,ht∗]是拼接。这样再通过sofmaxsofmax得到了一个概率分布,就可以预测需要生成的词:
在训练阶段,时间步 tt 时的损失为:
那么原输入序列的整体损失为:
2 Pointer-Generator-Network
原文中的Pointer-Generator Networks是一个混合了 Baseline seq2seq和PointerNetwork的网络,它具有Baseline seq2seq的生成能力和PointerNetwork的Copy能力。该网络的结构如下:
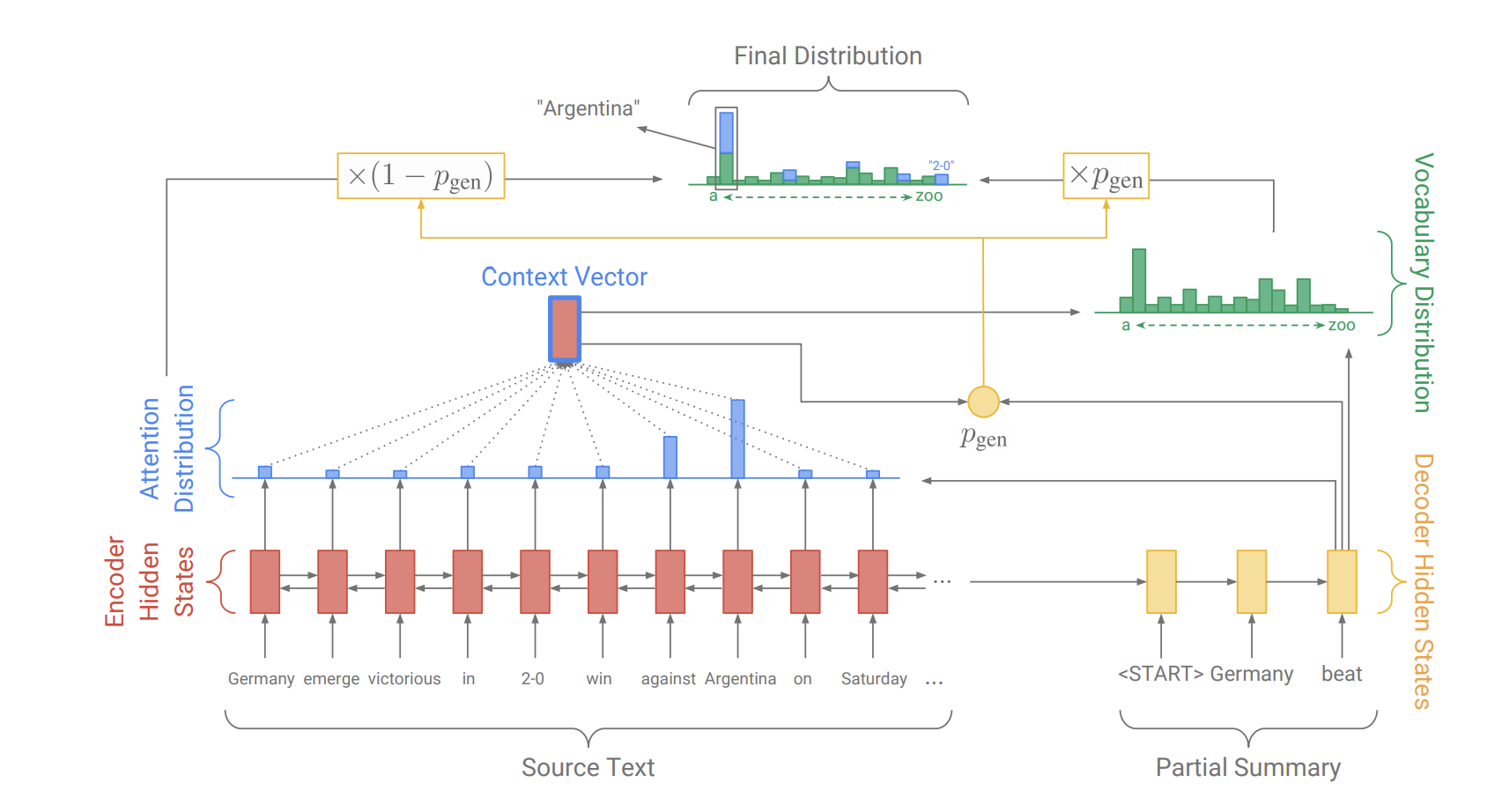
如何权衡一个词应该是生成的还是复制的?
原文中引入了一个权重 pgenpgen 。
从Baseline seq2seq的模型结构中得到了stst 和h∗tht∗,和解码器输入 xtxt 一起来计算 pgenpgen :
这时,会扩充单词表形成一个更大的单词表--扩充单词表(将原文当中的单词也加入到其中),该时间步的预测词概率为:
其中 atiait 表示的是原文档中的词。我们可以看到解码器一个词的输出概率有其是否拷贝是否生成的概率和决定。当一个词不出现在常规的单词表上时 Pvocab(w)Pvocab(w) 为0,当该词不出现在文档中∑i:wi=wati∑i:wi=wait为0。
3 Coverage mechanism
原文的特色是运用了Coverage Mechanism来解决重复生成文本的问题,下图反映了前两个模型与添加了Coverage Mechanism生成摘要的结果:

蓝色的字体表示的是参考摘要,三个模型的生成摘要的结果差别挺大;
红色字体表明了不准确的摘要细节生成(UNK未登录词,无法解决OOV问题);
绿色的字体表明了模型生成了重复文本。
为了解决此问题--Repitition,原文使用了在机器翻译中解决“过翻译”和“漏翻译”的机制--Coverage Mechanism。
具体实现上,就是将先前时间步的注意力权重加到一起得到所谓的覆盖向量 ct(coveragevector)ct(coveragevector),用先前的注意力权重决策来影响当前注意力权重的决策,这样就避免在同一位置重复,从而避免重复生成文本。计算上,先计算coverage vector ctct:
然后添加到注意力权重的计算过程中,ctct用来计算 etieit:
同时,为coverage vector添加损失是必要的,coverage loss计算方式为:
这样coverage loss是一个有界的量 covlosst≤∑iati=1covlosst≤∑iait=1 。因此最终的LOSS为:
4 实战部分
4.1 DataSet
英文数据集: cnn dailymail数据集,地址:https://github.com/becxer/cnn-dailymail/。
中文数据集:新浪微博摘要数据集,这是中文数据集,有679898条文本及摘要。
中英文数据集均可从这里下载,链接:https://pan.baidu.com/s/18ykewFUrTLzW8R84bF42pg 密码:9yqt。
4.2 Experiments
试验环境:centos7.4/python3.6/tensorflow1.12.0 GPU:Tesla-K40m-12G*4 代码参考:python3 tensorflow版本。调试时候各种报错,所以需要debug。
改动后的代码已上传至GitHub:https://github.com/zingp/NLP/tree/master/P007PytorchPointerGeneratorNetwork。
中文数据集预处理代码:
第一部分是对原始数据进行分词,划分训练集测试集,并保存文件。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
|
import osimport sysimport timeimport jiebaARTICLE_FILE = "./data/weibo_news/train_text.txt"SUMMARRY_FILE = "./data/weibo_news/train_label.txt"TRAIN_FILE = "./data/weibo_news/train_art_summ_prep.txt"VAL_FILE = "./data/weibo_news/val_art_summ_prep.txt"def timer(func): def wrapper(*args, **kwargs): start = time.time() r = func(*args, **kwargs) end = time.time() cost = end - start print(f"Cost time: {cost} s") return r return wrapper@timerdef load_data(filename): """加载数据文件,对文本进行分词""" data_list = [] with open(filename, 'r', encoding= 'utf-8') as f: for line in f: # jieba.enable_parallel() words = jieba.cut(line.strip()) word_list = list(words) # jieba.disable_parallel() data_list.append(' '.join(word_list).strip()) return data_listdef build_train_val(article_data, summary_data, train_num=600_000): """划分训练和验证数据""" train_list = [] val_list = [] n = 0 for text, summ in zip(article_data, summary_data): n += 1 if n <= train_num: train_list.append(text) train_list.append(summ) else: val_list.append(text) val_list.append(summ) return train_list, val_listdef save_file(filename, li): """预处理后的数据保存到文件""" with open(filename, 'w+', encoding='utf-8') as f: for item in li: f.write(item + '\n') print(f"Save {filename} ok.")if __name__ == '__main__': article_data = load_data(ARTICLE_FILE) # 大概耗时10分钟 summary_data = load_data(SUMMARRY_FILE) TRAIN_SPLIT = 600_000 train_list, val_list = build_train_val(article_data, summary_data, train_num=TRAIN_SPLIT) save_file(TRAIN_FILE, train_list) save_file(VAL_FILE, val_list) |
第二部分是将文件打包,生成模型能够加载的二进制文件。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
|
import osimport structimport collectionsfrom tensorflow.core.example import example_pb2# 经过分词处理后的训练数据与测试数据文件TRAIN_FILE = "./data/weibo_news/train_art_summ_prep.txt"VAL_FILE = "./data/weibo_news/val_art_summ_prep.txt"# 文本起始与结束标志SENTENCE_START = '<s>'SENTENCE_END = '</s>'VOCAB_SIZE = 50_000 # 词汇表大小CHUNK_SIZE = 1000 # 每个分块example的数量,用于分块的数据# tf模型数据文件存放目录FINISHED_FILE_DIR = './data/weibo_news/finished_files'CHUNKS_DIR = os.path.join(FINISHED_FILE_DIR, 'chunked')def chunk_file(finished_files_dir, chunks_dir, name, chunk_size): """构建二进制文件""" in_file = os.path.join(finished_files_dir, '%s.bin' % name) print(in_file) reader = open(in_file, "rb") chunk = 0 finished = False while not finished: chunk_fname = os.path.join(chunks_dir, '%s_%03d.bin' % (name, chunk)) # 新的分块 with open(chunk_fname, 'wb') as writer: for _ in range(chunk_size): len_bytes = reader.read(8) if not len_bytes: finished = True break str_len = struct.unpack('q', len_bytes)[0] example_str = struct.unpack('%ds' % str_len, reader.read(str_len))[0] writer.write(struct.pack('q', str_len)) writer.write(struct.pack('%ds' % str_len, example_str)) chunk += 1def chunk_all(): # 创建一个文件夹来保存分块 if not os.path.isdir(CHUNKS_DIR): os.mkdir(CHUNKS_DIR) # 将数据分块 for name in ['train', 'val']: print("Splitting %s data into chunks..." % name) chunk_file(FINISHED_FILE_DIR, CHUNKS_DIR, name, CHUNK_SIZE) print("Saved chunked data in %s" % CHUNKS_DIR)def read_text_file(text_file): """从预处理好的文件中加载数据""" lines = [] with open(text_file, "r", encoding='utf-8') as f: for line in f: lines.append(line.strip()) return linesdef write_to_bin(input_file, out_file, makevocab=False): """生成模型需要的文件""" if makevocab: vocab_counter = collections.Counter() with open(out_file, 'wb') as writer: # 读取输入的文本文件,使偶数行成为article,奇数行成为abstract(行号从0开始) lines = read_text_file(input_file) for i, new_line in enumerate(lines): if i % 2 == 0: article = lines[i] if i % 2 != 0: abstract = "%s %s %s" % (SENTENCE_START, lines[i], SENTENCE_END) # 写入tf.Example tf_example = example_pb2.Example() tf_example.features.feature['article'].bytes_list.value.extend([bytes(article, encoding='utf-8')]) tf_example.features.feature['abstract'].bytes_list.value.extend([bytes(abstract, encoding='utf-8')]) tf_example_str = tf_example.SerializeToString() str_len = len(tf_example_str) writer.write(struct.pack('q', str_len)) writer.write(struct.pack('%ds' % str_len, tf_example_str)) # 如果可以,将词典写入文件 if makevocab: art_tokens = article.split(' ') abs_tokens = abstract.split(' ') abs_tokens = [t for t in abs_tokens if t not in [SENTENCE_START, SENTENCE_END]] # 从词典中删除这些符号 tokens = art_tokens + abs_tokens tokens = [t.strip() for t in tokens] # 去掉句子开头结尾的空字符 tokens = [t for t in tokens if t != ""] # 删除空行 vocab_counter.update(tokens) print("Finished writing file %s\n" % out_file) # 将词典写入文件 if makevocab: print("Writing vocab file...") with open(os.path.join(FINISHED_FILE_DIR, "vocab"), 'w', encoding='utf-8') as writer: for word, count in vocab_counter.most_common(VOCAB_SIZE): writer.write(word + ' ' + str(count) + '\n') print("Finished writing vocab file")if __name__ == '__main__': if not os.path.exists(FINISHED_FILE_DIR): os.makedirs(FINISHED_FILE_DIR) write_to_bin(VAL_FILE, os.path.join(FINISHED_FILE_DIR, "val.bin")) write_to_bin(TRAIN_FILE, os.path.join(FINISHED_FILE_DIR, "train.bin"), makevocab=True) chunk_all() |
在训练中文数据集的时候,设置的hidden_dim为 256 ,词向量维度emb_dim为126,词汇表数目vocab_size为50K,batch_size设为16。这里由于我们的模型有处理OOV能力,因此词汇表不用设置过大;在batch_size的选择上,显存小的同学建议设为8,否则会出现内存不够,难以训练。
在batch_size=16时,训练了27k step, 出现loss震荡很难收敛的情况,train阶段loss如下:


可以看到当step在10k之后,loss在3.0-5.0之间来回剧烈震荡,并没有下降趋势。前面我们为了省显存,将batch_size设置成16,可能有点小了,梯度下降方向不太明确,显得有点盲目,因此将batch_size设成了32后重新开始训练。注意:在一定范围内,batchsize越大,计算得到的梯度下降方向就越准,引起训练震荡越小。增大batch_size后训练的loss曲线如下:
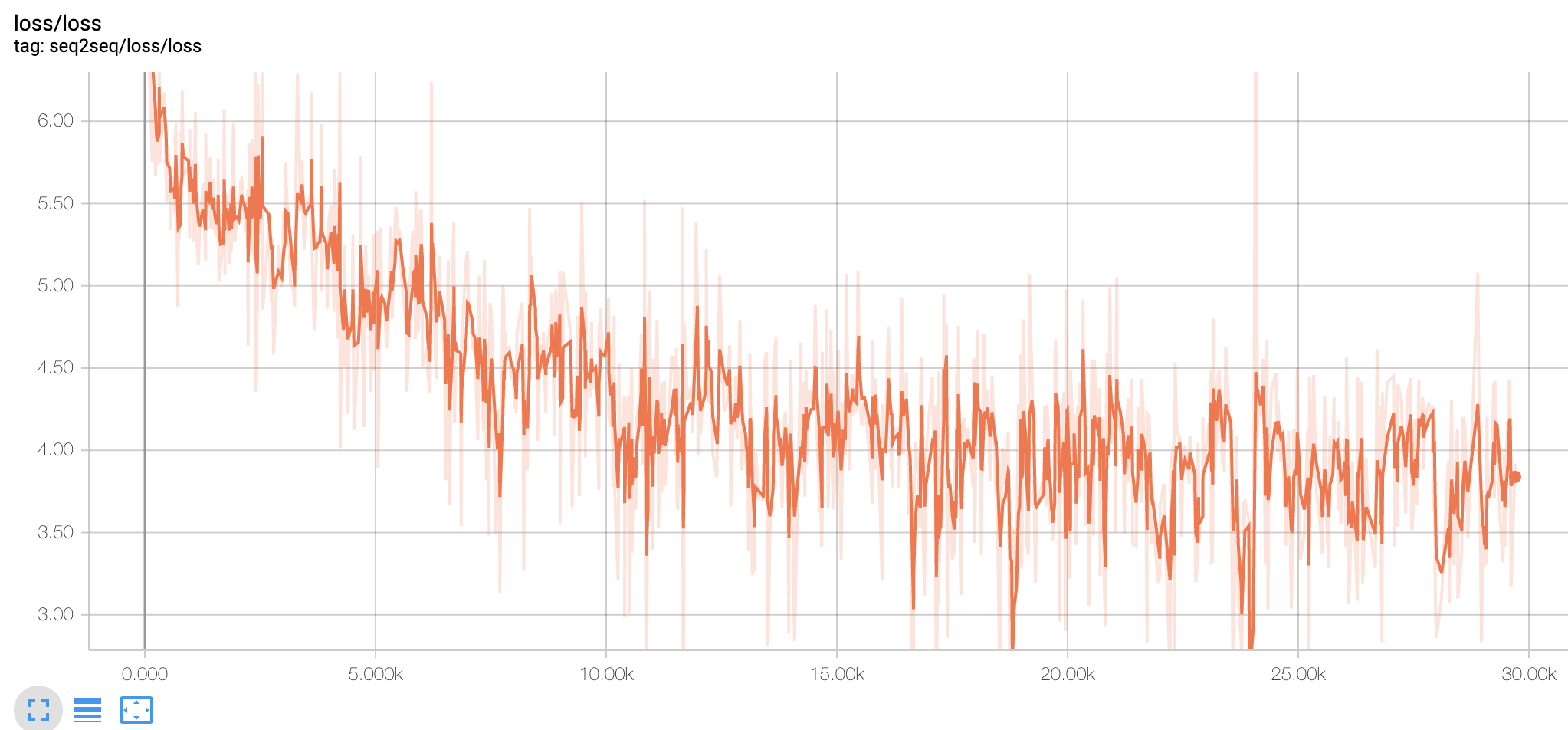
val loss曲线如下:

看起来loss还是比较震荡的,但是相比bathc_size=16时有所改善。一开始的前10K steps里loss下降还是很明显的基本上能从6降到4左右的区间,10k steps之后开始震荡,但还是能看到在缓慢下降:从4左右,开始在2-4之间震荡下降。这可能是目前的steps还比较少,只要val loss没有一直升高,可以继续观擦,如果500K steps都还是如此,可以考虑在一个合适的实机early stop。
4.3 Evaluation
摘要质量评价需要考虑一下三点:
(1) 决定原始文本最重要的、需要保留的部分;
(2) 在自动文本摘要中识别出1中的部分;
(3) 基于语法和连贯性(coherence)评价摘要的可读性(readability)。
从这三点出发有人工评价和自动评价,本文只讨论一下更值得关注的自动评价。自动文档摘要评价方法分为两类:
内部评价方法(Intrinsic Methods):提供参考摘要,以参考摘要为基准评价系统摘要的质量。系统摘要与参考摘要越吻合, 质量越高。
外部评价方法(Extrinsic Methods):不提供参考摘要,利用文档摘要代替原文档执行某个文档相关的应用。
内部评价方法是最常使用的文摘评价方法,将系统生成的自动摘要与参考摘要采用一定的方法进行比较是目前最为常见的文摘评价模式。下面介绍内部评价方法是ROUGE(Recall-Oriented Understudy for Gisting Evaluation)。
ROUGE是2004年由ISI的Chin-Yew Lin提出的一种自动摘要评价方法,现被广泛应用于DUC(Document Understanding Conference)的摘要评测任务中。ROUGE基于摘要中n元词(n-gram)的共现信息来评价摘要,是一种面向n元词召回率的评价方法。基本思想为由多个专家分别生成人工摘要,构成标准摘要集,将系统生成的自动摘要与人工生成的标准摘要相对比,通过统计二者之间重叠的基本单元(n元语法、词序列和词对)的数目,来评价摘要的质量。通过与专家人工摘要的对比,提高评价系统的稳定性和健壮性。该方法现已成为摘要评价技术的通用标注之一。 ROUGE准则由一系列的评价方法组成,包括ROUGE-N(N=1、2、3、4,分别代表基于1元词到4元词的模型),ROUGE-L,ROUGE-S, ROUGE-W,ROUGE-SU等。在自动文摘相关研究中,一般根据自己的具体研究内容选择合适的ROUGE方法。公式如下:
其中,n−gramn−gram表示n元词,RefSummariesRefSummaries表示参考摘要(标准摘要),Countmatch(n−gram)Countmatch(n−gram)表示生成摘要和参考摘要中同时出现n−gramn−gram的个数,Count(n−gram)Count(n−gram)则表示参考摘要中出现的n−gramn−gram个数。ROUGE公式是由召回率的计算公式演变而来的,分子可以看作“检出的相关文档数目”,即系统生成摘要与标准摘要相匹配的n−gramn−gram个数,分母可以看作“相关文档数目”,即参考摘要中所有的n−gramn−gram个数。
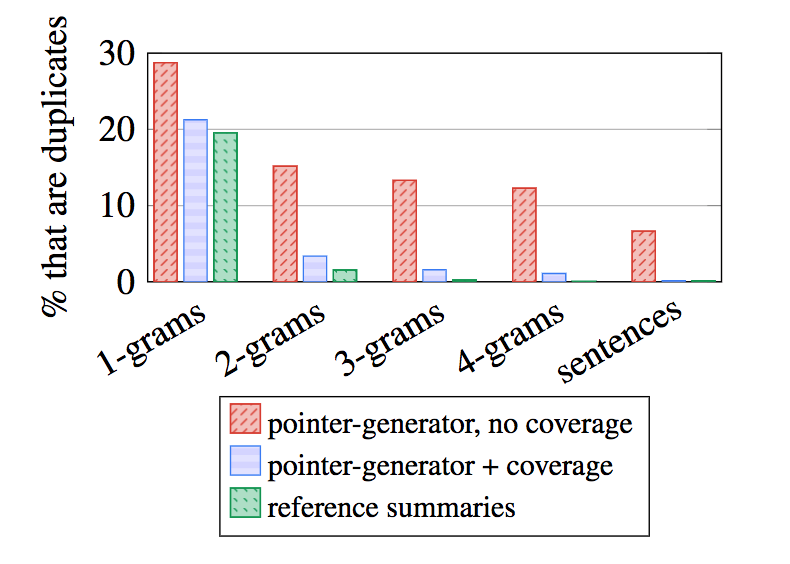
来看原文试验结果:
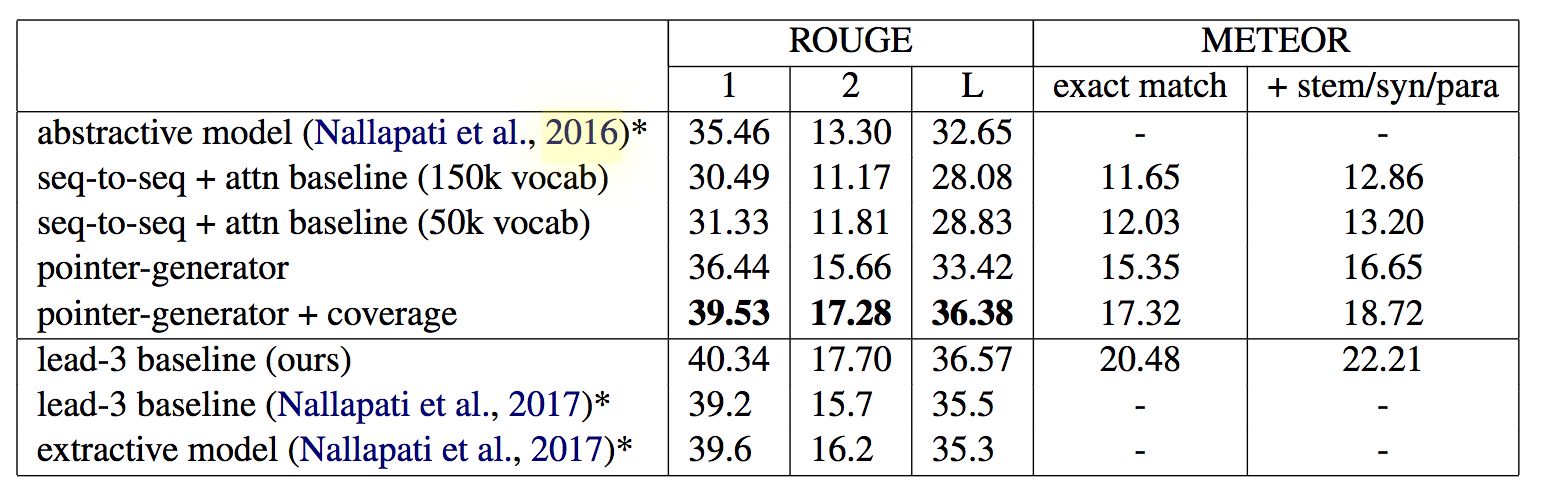
在上表中,上半部分是模型生成的的摘要评估,而下半部分的是提取摘要评估。可以看出抽象生成的效果接近了抽取效果。再来看重复情况:

例子二:

直观上效果还是不错的。可以看出,预测的摘要中已经基本没有不断重复自身的现象;像“[话筒] [思考] [吃惊] ”这种文本,应该是原文本中的表情,在对文本的处理中我们并没有将这些清洗掉,因此依然出现在预测摘要中。不过例子二还是出现了句子不是很通顺的情况,在输出句子的语序连贯上还有待改进。
4.4 Results
1. 在复现原论文的基础上,将模型方法应用在中文数据集上,取得了一定效果。
2. 可以看出指针生成网络通过指针复制原文中的单词,可以生成新的单词,解决oov问题;其次使用了coverage机制,能够避免生成的词语不断重复。
3. 在语句的通顺和连贯上还有待加强。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号