

Active Learning 主动学习
Active Learning 主动学习
最近读了一篇paper,题目是An MRF Model-Based Active Learning Framework for the Spectral-Spatial Classification of Hyperspectral Imagery。(题目这么长我也不想的......)这篇文章主要说了马尔科夫随机场还有active learning (AL)结合的问题。刚开始让给我学习AL的时候我是拒绝的,因为网上根本很少资料好吗?!居然还有一大堆关于如何教育孩子的相关结果......所以我就决定为我们机器学习领域的AL正名,它可不是教育孩子的方法哦~~
PS:如果你把机器学习算法看作自己的孩子,上面那句话当我没说....另外,请收下我的膝盖...
絮絮叨叨一大堆,让我们进入正题吧~~关于AL的定义,似乎一直没有很确切的定论,那么首先让我们看看维基百科是怎么说的:
主动学习是半监督机器学习的一个特例,在主动学习中,一个学习算法可以交互式的询问用户(或其他信息源)来获得在新的数据点所期望的输出。
Active learning is a special case of semi-supervised machine learning in which a learning algorithm is able to interactively query the user (or some other information source) to obtain the desired outputs at new data points.
不知道大家感觉怎么样,反正我感觉这个解释很差强人意。根据维基百科的描述,主动学习算法的一部分训练样本的标签是在算法运行的过程中主动询问用户才得到的。那么我认为这并不算是一种半监督的学习方法。众所周知,半监督学习方法是在不需要人工干预的条件下由算法自行完成对无标记数据的利用,这明显与上面的说明相悖。
鉴于维基百科上给出的定义让我很不满意(画外音:卧槽,你以为你是谁啊!!!),所以我根据论文中对主动学习的描述以及自身的理解从AL适用范围的角度做出下面的定义:
在某些情况下,没有类标签的数据相当丰富而有类标签的数据相当稀少,并且人工对数据进行标记的成本又相当高昂。在这种情况下,我们可以让学习算法主动地提出要对哪些数据进行标注,之后我们要将这些数据送到砖家那里让他们进行标注,再将这些数据加入到训练样本集中对算法进行训练。这一过程叫做主动学习。
简直通俗易懂有木有~~从我给出的定义上我们可以看出来,主动学习最重要的部分就是选择策略,即选择哪些数据提出标注请求。当然,通常我们对这种策略的要求是迭代次数尽量少并且结果尽量更加精确。
另外,由于是学习算法自己对样本提出要求,那么用来训练的样本数量一般是远远低于普通的学习方法的。这个道理很好理解啊,因为只有算法自己最了解自己吗~~就像女人最了解女人一样,所以女生的心思不要去猜,猜也猜不到,说不定还会付出比她真正需要的多很多倍的努力,结果却不一定很完美,这真是个悲伤的故事~~跑题了,跑题了....sorry!!!
下面我们就来建立以下主动学习(AL)的模型吧~~
首先当然是notation啦~我们定义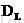
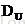
我们不妨形象的比喻一下,从前有个白富美叫做学习算法,她的目标就是经历众多的男人从而完善自身。在她出生时,她的父亲算法工程师给她安排了一个男人列表,也就是
从上面的故事可以看出,主动学习这个过程最重要的就是两点:一、由学习算法主动提出对未标记的样本的标记需求;二、选择策略相当重要。另外,我从论文中的数据看出,主动学习过程的收敛也是很快的。
下面我想说说选择策略的问题,论文中提到了三种策略,分别是RS,LC和BT。为了一般化,我在这里只对多分类(也就是有很多种类标签)的情况进行说明。
RS:
即random selected,随机选择。顾名思义,这种方法是在
LC:
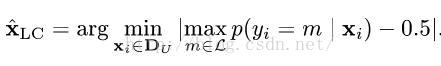
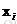
BT:
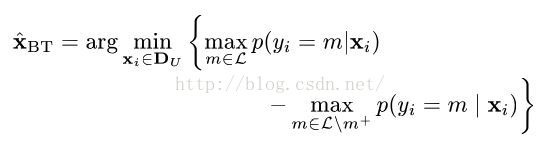
选择策略也说完了,关于选择策略可能有些地方说的不清楚,如果大家不满意的话,可以直接去看我最开始提到的那篇论文,说得更加明白。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号